布隆过滤器原理及实现
Posted 随心所向李先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了布隆过滤器原理及实现相关的知识,希望对你有一定的参考价值。
布隆过滤器原理及实现
前言
最近有朋友面试经常被问到redis缓存穿透怎么解决,什么是redis缓存穿透呢?就是客户端去访问一个缓存和数据库都不存在的 key这样的查询直接打到数据库上。解决办法很多。
1接口参数校验,
2在缓存中设置空值,
3布隆过滤器。
本章咱们就来看下布隆过滤器怎么解决的
什么是布隆过滤器
布隆过滤器可以快速的从海量中数据校验一个数据是否存在。
它内部结构由多个hash函数和一组bit数组成
每个bit位置默认是0
下面请看图
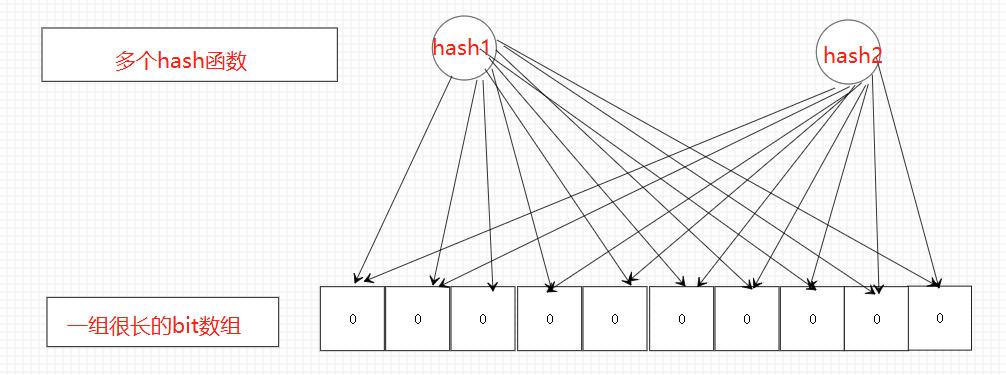
实现过程
1、把所有数据的位置信息添加到bit数组
每条数据经过hash函数运算,有几个函数就计算几次,
每次计算都会算出对应的位置信息,然后把该位置由0置为1,
2、校验单个数据是否存在布隆过滤器里
跟添加位置信息一样经过多个函数算出对应的值信息
如果每个位置信息都是1则布隆过滤器判断该数据存在
如果都为0或者有一个位置信息为0则判断数据不存在
优势:
1、仅仅保留保留数据的位置信息,空间效率极高
2、信息安全性较高,不能根据位置信息反算出来数据
3、查询效率极高,时间复杂度0(n)
缺点:
存在一定的误判:当一个不存在的数据经过hash运算算出的位置信息 都是1的时候,这时候就发生了hash冲突,布隆过滤器就会误判,hash冲突我们无法避免,所以误判无法避免,hash函数越多误判率越低,这个误判率我们可以手动配置,但是记住一点误判率越低bit数组越大,hash函数越多相应的性能就会降低。
数据删除困难:当我们要删除一个数据的时候不能仅把他对应的位置置为0,因为该位置可能还是别的数据的位置信息。所以不能物理删除。
看到这里,可能会有人问既然布隆过滤器没办法避免误判率,那么我们为什么要用它或者什么时候要用它呢?
它只会误判不存在的数据,不会误判存在的数据
首先回到我们前言说的redis缓存穿透的问题,当有人恶意攻击你的服务器缓存,每秒上万的用不存在的k来访问我们缓存时候,我们在缓存前面加上布隆过滤器,当有真实存在的数据一定不会误判,这样经过布隆过滤器后可能只有很少的非法数据访问到我们的服务器,服务器也可以承受。
经典应用场景
1、字处理软件,需要检查一个英语单词是否正确
2、网站非法url过滤
3、订单物流单号查询
4、FBI,查询一个嫌疑人是否存在嫌疑名单上
最后来下看demo
所需依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
代码实现
package com.teamer.servicetm.controller;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
public class BloomFilterTest {
private static final int num=1000000;
public static void main(String[] args) {
/**
创建一个存储string的布隆过滤器,初始化大小为num,默认误判率为0.03,如果我们想把误判率可以这样写
BloomFilter<String> bloomFilter=BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),num,0.01D);
*/
BloomFilter<String> bloomFilter=BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),num);
//创建两个list容器 用来验证过滤器、以及他的误判率
List<String> list=new ArrayList<>(num);
List<String> list1=new ArrayList<>(num);
for(int i=0;i<num;i++){
String uuid= UUID.randomUUID().toString();
bloomFilter.put(uuid);
list.add(uuid);
list1.add(uuid);
}
int nums=0;
int trueNum=0;//正确的个数
int wrongNum=0;//错误的个数
for(int i=0;i<10000;i++){
String str=i%100==0?list.get(i):UUID.randomUUID().toString();
//布隆过滤器判断如果为true证明布隆过滤器认为存在
if(bloomFilter.mightContain(str)){
nums++;
//再用list1判断下如果list1也认为存在则证明布隆过滤器判断正确,反之判断错误
if(list1.contains(str)){
trueNum++;
}else{
wrongNum++;
}
}
}
System.out.println("布隆过滤器校验的个数为"+nums);
System.out.println("正确的个数为"+trueNum);
System.out.println("误判的个数为"+wrongNum);
}
}
这里只是讲下大致原理过程,真正实现时候我们要多个线程去一块初始化数据,需要用到线程池化技术、锁(因为布隆过滤器是线程不安全的)、线程协作等。有兴趣的可以了解下Fork/Join。
以上是关于布隆过滤器原理及实现的主要内容,如果未能解决你的问题,请参考以下文章