2021年大数据常用语言Scala(二十六):函数式编程 分组 groupBy
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据常用语言Scala(二十六):函数式编程 分组 groupBy相关的知识,希望对你有一定的参考价值。
目录
分组 groupBy
我们如果要将数据按照分组来进行统计分析,就需要使用到分组方法
等同于SQL中的 group by的概念, 就是给数据按照指定的列进行分组用。
定义
groupBy表示按照函数将列表分成不同的组
方法签名
def groupBy[K](f: (A) ⇒ K): Map[K, List[A]]
方法解析
| groupBy方法 | API | 说明 |
| 泛型 | [K] | 分组字段的类型 |
| 参数 | f: (A) ⇒ K | 传入一个函数对象<br />接收集合元素类型的参数<br />返回一个K类型的key,这个key会用来进行分组,相同的key放在一组中 |
| 返回值 | Map[K, List[A]] | 返回一个映射,K为分组字段,List为这个分组字段对应的一组数据 |
groupBy执行过程分析
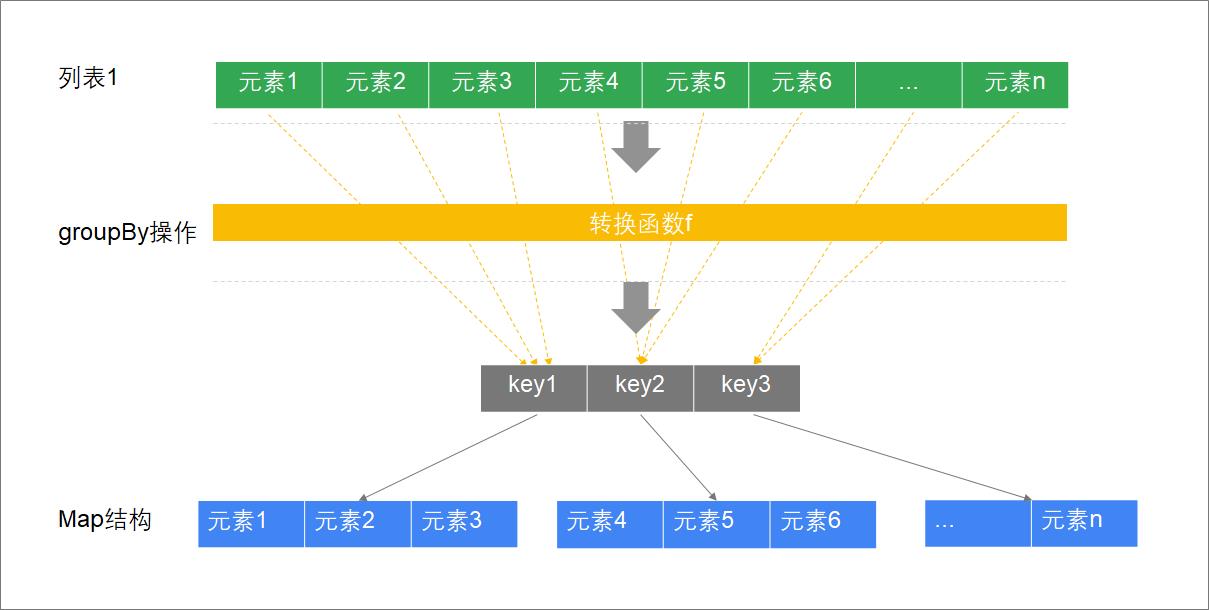
示例
有一个列表,包含了学生的姓名和性别:
"张三", "男"
"李四", "女"
"王五", "男"
请按照性别进行分组,统计不同性别的学生人数
步骤
定义一个元组列表来保存学生姓名和性别
按照性别进行分组
将分组后的Map转换为列表:List(("男" -> 2), ("女" -> 1))
参考代码
scala> val a = List("张三"->"男", "李四"->"女", "王五"->"男")
a: List[(String, String)] = List((张三,男), (李四,女), (王五,男))
// 按照性别分组
scala> a.groupBy(_._2)
res0: scala.collection.immutable.Map[String,List[(String, String)]] = Map(男 -> List((张三,男), (王五,男)),
女 -> List((李四,女)))
// 将分组后的映射转换为性别/人数元组列表
scala> res0.map(x => x._1 -> x._2.size)
res3: scala.collection.immutable.Map[String,Int] = Map(男 -> 2, 女 -> 1)
以上是关于2021年大数据常用语言Scala(二十六):函数式编程 分组 groupBy的主要内容,如果未能解决你的问题,请参考以下文章