spark协同过滤算法-附scala代码
Posted BJUT赵亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark协同过滤算法-附scala代码相关的知识,希望对你有一定的参考价值。
本文记录了在spark上协同过滤算法的相关内容,如果有做相关工作的同学,可以邮件与我联系 zhaoliang19960421@outlook.com
本文参考了spark协同过滤,在此表示感谢
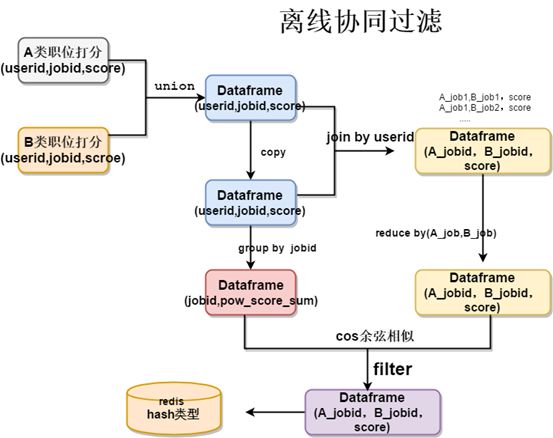
协同过滤算法的本质是在全局范围内统计用户的行为,对每个行为进行打分记录,找到行为最相似的两人或者所有人的行为最相似的两个物品。具体的协同过滤的过程如下图所示
其中cos距离的计算方式如下图所示
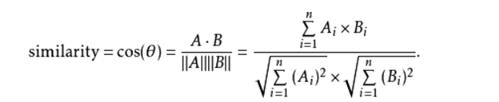
具体的操作方式如下( 以用户的协同过滤为例):
- 在全局范围对,每个用户对每个商品进行打分(对于不同的行为可以给与不同的分值,代表不同的权重)
- 每一个用户用一个向量来表示,向量长度是商品个数,然后对于用户而言两两计算cos距离
- 分母是每个向量的模长, 每个用户的向量模长,依次计算即可
- 在计算cos的分子时,当且仅当两个向量在对应位置上都有值时才有结果
- 那么仅计算每个商品都有打分的商品即可,即对于每个用户而言,以商品为主键进行join,得到两两用户之间都有行为的商品,依次相乘求和后,即可得到cos的分子(做上三角取值,因为用户两两join会出现,AB、BA 两行数据)
- 在获得两两用户之间的cos分子,分别join每个用户的向量模型,做除法得到两个用户之间的cos距离
- 得到的两个用户之间的距离的dataframe保存在hdfs中后续使用
package analysis.theme
import breeze.numerics.{pow, sqrt}
import conf.CreateSparkSession
import conf.DateUtil.getFrontDay
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.functions._
/**
* @author zhaoliang6@xiaomi.com on 20210506
* 基于用户行为的协同过滤算法
*/
object UserItemCF {
def main(args: Array[String]): Unit = {
val spark: SparkSession = CreateSparkSession.createSparkSession(this.getClass.getSimpleName)
var startDate = getFrontDay(2);if (args.length > 0) startDate = args(0)
var endDate = getFrontDay(1);if (args.length > 1) endDate = args(1)
val userItemScoreDf = getUserItemScoreDf(spark, startDate, endDate)
val itemCFDf = calcuate(spark, userItemScoreDf, Array("imei", "product_id", "score"), "item")
itemCFDf.write.mode(SaveMode.Overwrite).save("hdfs://****/itemCF")
val simItemDf = exp_itemCF(spark)
}
/**
* 获得用户-商品-得分 矩阵,其中不同的动作获得得分不同
*
* @param sparkSession
* @param startDate 统计开始时间
* @param endDate 统计结束时间
* @return uid-itemid-score dataframe
*/
def getUserItemScoreDf(sparkSession: SparkSession, startDate: String, endDate: String): DataFrame = {
val scoreMap = Map(
"click" -> 1, "download" -> 2, "apply" -> 3,
"like" -> 4, "comment" -> 4, "share" -> 4, "community" -> 4, "favorate" -> 4, "buy_success" -> 5,
"dis_like" -> -4, "dis_favorate" -> -4
)
// uid,itemid,action,...
val orgDf = sparkSession.read.parquet(s"")
.where(s"date between $startDate and $endDate")
.where("imei is not null and product_id is not null")
.cache()
var resultDf: DataFrame = null
scoreMap.keys.toArray.foreach(action => {
val temp = orgDf.where(s"action = '$action'")
.withColumn("score", lit(scoreMap(s"$action")))
.selectExpr("imei", "product_id", "score")
if (resultDf == null) {
resultDf = temp
} else {
resultDf = resultDf.union(temp)
}
})
resultDf.groupBy("imei", "product_id").agg(sum("score").as("score")).cache()
}
/*
* 基于物品和基于用户的协同过滤计算逻辑相同,以基于物品的为例解释
* 由原始的 uid-itemid-score 矩阵获得基于物品的协同过滤矩阵dataframe
* 计算两个商品之间的相似度,需要分别获得两个商品A、商品B 对于所有用户的得分向量,然后对着两个向量计算cos距离
* A·B 求和 A_i * B_i
* cos_distance = ——————— = ———————————————————————————————————— 其中A_i 是A向量中的第i个元素
* |A|*|B| 开平方(求和A_i) * 开平方(求和B_i)
* 有关cos距离详见 https://blog.csdn.net/m0_37192554/article/details/107359291
* 对于商品A而言,所有用户的得分向量是item1ScoreList = [ 1,0,1,1,0....]
* 对于商品B而言,所有用户的得分向量是item2ScoreList = [ 0,0,1,0,0....]
* 从数据中可以看到,只有当一个商品同时有两个商品的行为得分时,计算cos距离时才有意义,
* 否则在分子的计算中,对应位置在分子和分母的计算结果中都是0
* 所以在计算两个商品的相似度时,仅计算对两个商品都有行为的用户即可
* 由原始的uid-itemid-score 矩阵通过join uid的方式获得两个用户之间都有过行为的商品列表
* 然后在两个用户都有行为的商品中计算cos距离的分子,
* 每个用户分别计算各自的模长做分母,最后得到cons距离
* 基于用户的协同过滤计算方式是一样的
*
* @param orgDf 原始的 uid-itemid-score 矩阵
* @param column 原始的df中的列名,依次对应userid ,itemid,score
* @param dfType user或item,代表基于用户或者基于商品的协同过滤
* @return uid1 uid2 similarity 的dataframe
*/
def calcuate(spark: SparkSession, orgDf: DataFrame, column: Array[String], dfType: String): DataFrame = {
assert(Array("user", "item").contains(dfType))
val type2type = Map("user" -> "item", "item" -> "user")
import spark.implicits._
val userItemDf = orgDf.selectExpr(s"${column(0)} as user_id", s"${column(1)} as item_id", s"${column(2)} as rating")
val userItemDf2 = orgDf.selectExpr(s"${column(0)} as user_id2", s"${column(1)} as item_id2", s"${column(2)} as rating2")
// 计算cos距离的分子
val elementMulitplyDf = userItemDf
.join(userItemDf2, userItemDf(s"${type2type(dfType)}_id") === userItemDf2(s"${type2type(dfType)}_id2"))
.filter(s"${dfType}_id < ${dfType}_id2") // 上三角取值
.withColumn("rating_product", multiply2ColumnUDF(col("rating"), col("rating2")))
.groupBy(s"${dfType}_id", s"${dfType}_id2").agg(sum("rating_product"))
.withColumnRenamed("sum(rating_product)", "rating_sum_pro")
.cache()
elementMulitplyDf.show()
// 商品或用户向量的模长
val itemVectorLengthDf = userItemDf
.rdd
.map(x => {
dfType match {
case "user" => (x(0).toString, x(2).toString)
case "item" => (x(1).toString, x(2).toString)
}
})
.groupByKey()
.mapValues(x => sqrt(x.toArray.map(line => pow(line.toDouble, 2)).sum))
.toDF(s"${dfType}_id_sum", "rating_sqrt_sum")
itemVectorLengthDf.show()
// 对于计算 uid1 uid2 相似度得到的分子
// 依次join得到uid1的向量模长,join得到uid2的向量模长
// 计算最终的cos距离
val resultDf = elementMulitplyDf
.join(itemVectorLengthDf, elementMulitplyDf(s"${dfType}_id") === itemVectorLengthDf(s"${dfType}_id_sum"))
.drop(s"${dfType}_id_sum")
.withColumnRenamed("rating_sqrt_sum", s"rating_sqrt_${dfType}_id_sum")
.join(itemVectorLengthDf, elementMulitplyDf(s"${dfType}_id2") === itemVectorLengthDf(s"${dfType}_id_sum"))
.drop(s"${dfType}_id_sum")
.withColumnRenamed("rating_sqrt_sum", s"rating_sqrt_${dfType}_id2_sum")
.withColumn("sim", divide2ColumnUDF(col("rating_sum_pro"), col(s"rating_sqrt_${dfType}_id_sum"), col(s"rating_sqrt_${dfType}_id2_sum")))
.select(s"${dfType}_id", s"${dfType}_id2", "sim")
.na.fill(0.0)
resultDf.show()
resultDf
}
// udf 对输入的两列进行相乘
val multiply2ColumnUDF: UserDefinedFunction = udf((s1: Double, s2: Double) => s1 * s2)
// udf 对输入的三列 a,b,c 进行 a/(b*c)
val divide2ColumnUDF: UserDefinedFunction = udf((pro: Double, s1: Double, s2: Double) => pro / (s1 * s2))
/**
* 基于物品的协同过滤
*/
def exp_itemCF(sparkSession: SparkSession): DataFrame = {
val orgDf = sparkSession.read.parquet("hdfs://****/itemCF")
.na.fill(0.0)
import sparkSession.implicits._
val selectNum = 50
val result = orgDf
.rdd
.map(r => (r.getString(0), (r.getString(1), r.getDouble(2))))
.groupByKey()
.map(row => {
val id = row._1
val struct = row._2.toArray.sortBy(-_._2).slice(0, selectNum)
val json = new JsonObject()
struct.foreach(s => json.addProperty(s._1, s._2))
(id, json.toString)
})
.toDF("id", "similaryItemByCF")
result
}
}
以上是关于spark协同过滤算法-附scala代码的主要内容,如果未能解决你的问题,请参考以下文章