数据仓库设计要点
Posted 杀智勇双全杀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库设计要点相关的知识,希望对你有一定的参考价值。
数据仓库设计要点
联机处理
分为OLTP与OLAP。
OLTP联机事务处理
业务类系统主要供基层人员使用,进行一线业务操作(人事、财务管理等),或者是给用户使用(例如:注册、登录、订单等),通常被称为OLTP(On-Line Transaction Processing,联机事务处理)。
OLTP是为了实现业务性数据管理和存储,读写速度快,需要满足事务性的需求,数据量相对较小。一般使用关系型数据库mysql、Oracle即可实现。
OLAP联机分析处理
数据分析的目标则是探索并挖掘数据价值,作为企业进行运营决策的参考(使用人员一般是:运营、运维、领导层、数据分析师)。通常被称为OLAP(On-Line Analytical Processing,联机分析处理)。
OLAP是为了满足运营决策的需求,将公司各种数据实现数据分析的管理。故读写要求稍低(一般是按照一定的时间周期进行处理,例如离线数据仓库是T+1,也可能是每小时),数据量非常庞大,不需要事务性的要求。一般用专业数据仓库工具来实现(例如:Hive、GreepNum)。
数据仓库
功能
为了满足OLAP场景下的数据管理需求(存储是为了管理),将各种数据进行规范化的处理,提供给需求方。
本质上是一种分布式的、统一化的、规范化的数据管理的设计模型。
应用场景
满足企业中所有数据的统一化存储需求,通过规范化的数据处理来实现企业的数据分析应用。
特点
面向主题
不同于面向业务的数据库(各种部门各种系统有各种数据库),数据仓库是面向主题的。公司会把所有数据全部通过数据采集/数据同步存入数据仓库。
数据集市/主题域一般是按部门划分的,细化的数据主题则是各个应用对应的主题。
数据集成
存储整个公司所有数据,为公司所有数据的需求方提供数据。
数据仓库本身并不产生数据,也不使用数据。数据仓库会将整个公司采集到的所有数据源的数据进行存储,提供给各个数据的应用方。
非易失性/稳定性
数据仓库正常情况没有更新和删除的业务需求。
如果Update修改了数据,就是修改了数据的真实性,会导致分析的结果不正确。
如果delete数据,同样会导致分析结果有误。将已经用不到的老的历史数据封存移走是另一回事。
时变性/动态性
数据仓库中会按照时间记录随时间变化的数据的状态(数据仓库中的数据随着时间的变化会不断增加)。
核心流程
ETL
数据一般会经历数据生成、数据采集、数据存储、数据计算、数据应用的环节。数据采集与数据存储都可能需要ETL。
Extract、Transform、Load:抽取、转换、加载,将原始数据根据需求进行处理,再将处理好的数据再写入HDFS。
数据采集阶段
采集后的数据存放在HDFS上,数据不一定是标准的结构化格式。
这种情况就需要ETL进行过滤、补全、转换。ETL可以借助Kettle等专业工具,也可以通过代码开发(如:MapReduce、SparkCore)。ETL第一阶段发生在数据采集之后。
ETL完成后就可以入库:将ETL以后的每一天的数据作为Hive表的一个分区。
过滤
将不需要的数据、非法的数据进行过滤(例如:缺失重要字段,失去利用价值的数据)。
转换
将原始数据格式变成想要的数据格式(例如:存储密码的数据是加密的,需要ETL时解密)。
补全
原始数据中没有需要使用的数据,就需要通过各种方式(例如:换算、解析、设默认值等)补全。
数据存储阶段
第二个阶段发生在数据仓库中。
数据本身已经是结构化数据,可以通过SQL直接加载到Hive表中。
分层
规定数据在数据仓库中处理的步骤。每一层就是一个数据库,不同层的数据表在不同的数据库中。
建模
决定了数据表如何构建。建模常用的模型有ER建模、维度建模等。
指标设计
对数据统计分析得到的结果,就是指标,也称为指数。指标是通过数值来体现的,就像Tableau中的度量值。通过指标可以衡量事实的结果,反映事实的好坏。
例如:可以在CSDN后台看到自己的博文数据,这些数字都是指标(数字对应的项目叫维度)。
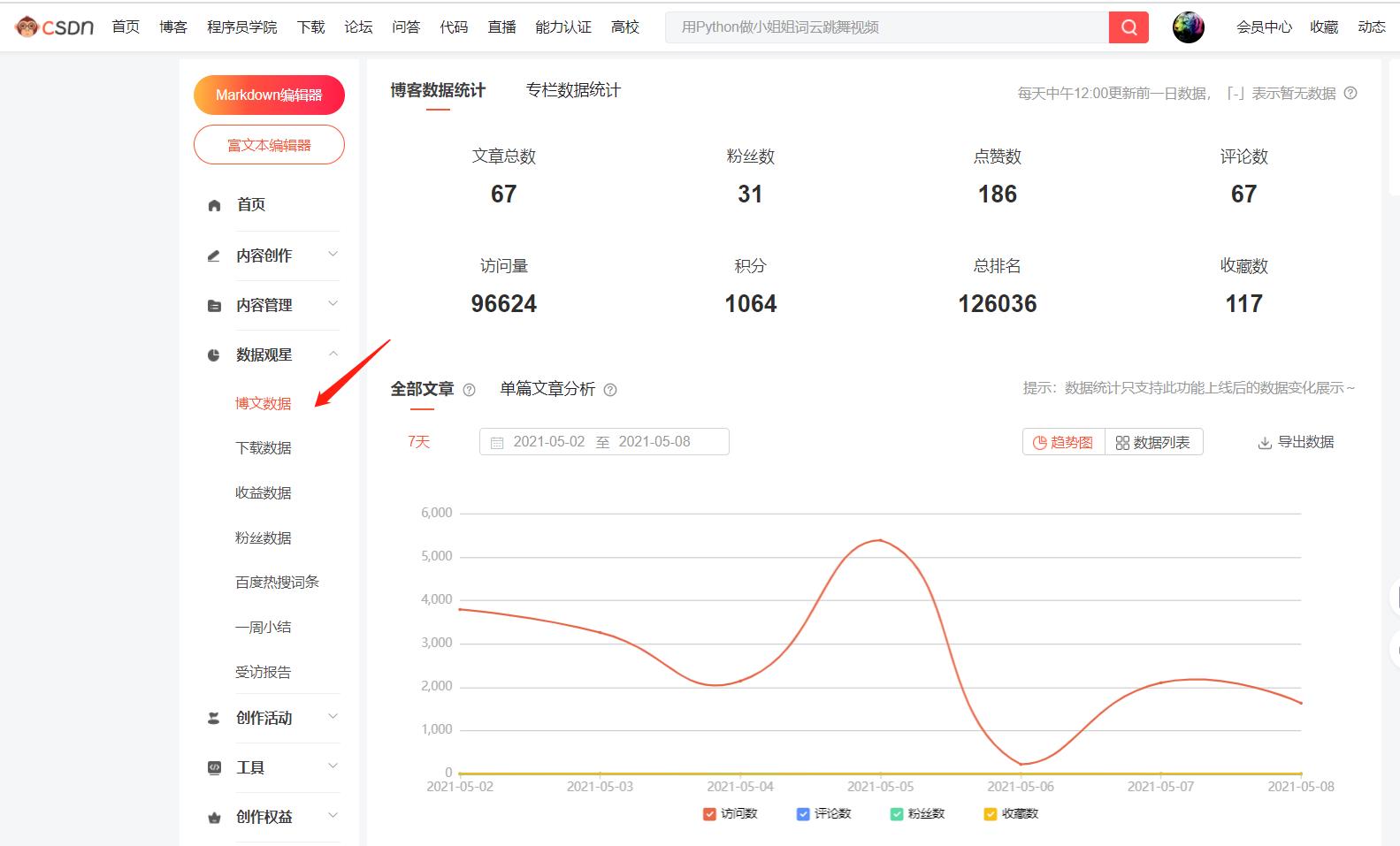
大数据分析的目的就是通过指标发现产品公司或者平台存在的问题,并指导解决问题。
常见指标
友盟这类网站都有DEMO。

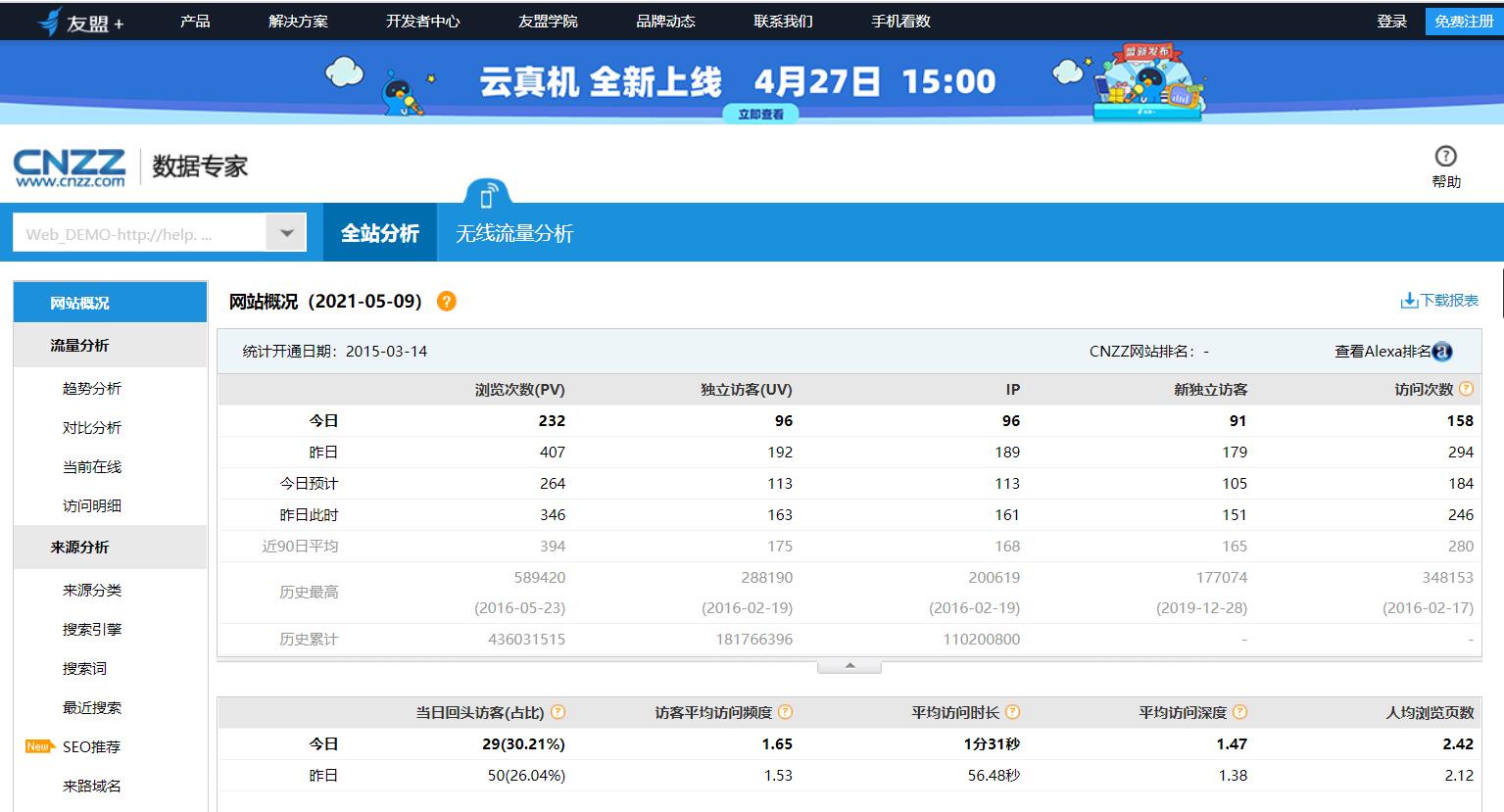
以此为例说明网站分析的一些指标。
PV:page view,用于反映网页的访问量。字段:url。统计:count(url)。
UV:unique view:用于反映网站的用户访问量。字段:访客id,userid、uuid、guid。访客id:只要访问了,就有这个id。 统计UV:统计访问人数。会员id:登陆了,就有会员id,用于统计登陆人数。会话id:与服务端构建了连接,服务端会分配Session Id。计算:count(distinct userid)。
IP:用于反映IP的个数,IP可以反映用户群体的分布。字段:ip。计算:count(distinct ip)。
跳出率:只访问了一个页面的会话个数 / 总的会话的个数。字段:sessionId。计算:PV等于1的Session个数 count(case when pv = 1 then sessionId else null) / 总的会话个数 count(distinct sessionId)。越低代表用户粘性越高,平台的运营就越好。
二跳率:访问了两个页面及以上的会话个数 / 总的会话个数。字段:sessionId。计算:PV等于1的Session个数 count(case pv > 1 else sessionId else null) / 总的会话个数 count(distinct sessionId)。
平均访问时长:总的Session访问时间 / 总的session个数。字段:time,sessionId。计算:sum(访问最后一个页面的时间 - 访问第一个页面时间) / count(distinct sessionId)。
其它指标
各个行业有不同的指标。。。难以全部列举。。。可以去类似神策DEMO的网站查看,或者依据自己行业的实际情况指定。
维度设计
维度在Tableau中可以决定能选用何种图表。维度的本质就是用于描述事物的角度。维度可以用于细化对指标事实的分析,帮助分析人员更加精确地发现问题。
select 天,地区,count(distinct userid) as uv from table
group by 天,地区;
从SQL角度理解,维度就是group by的分组字段。。。
常见维度
维度一般是固定的或者变化频率不高。
时间维度:年、季度、月、周、天、小时。
地区维度:国家、省份、城市。
平台维度:网站、APP、小程序、H5。
操作系统维度:Windows、Mac OS、android:ios。
这些都可以是维度。。。
下钻与上卷
下钻:当前基于一个大的维度进行分析,要下钻到一个更细的维度进行分析。例如:先按年分析,发现问题后再按小时分析。
上卷:当前分析是基于一个小的维度的进行分析,要上卷到一个大的维度来进行分析。例如:先按每个小时分析,再按照每天分析。
渐变维度
维度数据不可能始终不变。维度数据发生变化时,如果直接Update的方式更新维度记录直接覆盖已经存在的值,会导致统计之前情况时找不到之前的值致使统计结果不准确。如果是通过增加列的方式记录每个状态,又会导致数据不整齐,也不可取。
构建拉链表,根据不同的时间来标记这一列的不同状态是个比较合适的做法。例如:可以按时间来标记每次的状态变化情况,这样就可以指定时间来查询对应的状态。
建模
ER模型
这是实体关系模型,一般应用于OLTP的关系型数据库系统来实现业务数据库的建模,实现满足业务的数据存储。需要通过外键构建数据关联关系,这样就避免了冗余存储,主要是记录事件的产生。
ER模型建模流程
先找到所有实体,以及每个实体的属性。然后找到所有实体之间的关系。最后建表(每个实体单独建表。每个关系也单独建表,通过外键与多个实体表关联)。
这种做法符合数据库的设计规范,没有冗余数据,保证性能,业务的需求把握的比较全面。但是设计时非常复杂,必须找到所有实体和关系,才能构建。
维度模型
一般应用于大数据的数据仓库的模型构建,用于通过不同维度来实现统计分析各种指标事实,描述事实的结果(反映事情的好坏)。
维度模型建模流程
先构建所有维度,再基于维度分析事实。
这里的维度:基于不同维度下的指标的结果,看待指标的角度。
这里的事实:通过指标来反映事实。
维度表:一个维度可以有一张表,也可以有多张表。
事实表:多个事实放在一张表中。
维度表——雪花模型
事实表会通过外键先关联父维度表。父维度表再通过外键关联子维度表。这种做法可以减少数据冗余,但是每次要获取具体数据都必须关联每一张子表,性能较差。
外键的用途:约束,避免冗余(笛卡尔积等脏数据)。不是关联的作用(没有外键也可以关联)。
维度表——星型
事实表通过外键关联所有维度表,维度表不存在子表。这种做法查询时可以直接获取到对应的数据结果,不用关联其它子维度表,可以提升性能。但是数据冗余度比较高。云计算大数据分布式集群多,不缺性能与算力,青睐这种做法。
维度表——星座模型
基于星型模型的演变,多个事实表共同使用同一个维度表。
事实表的分类
事物事实表:存储的是原始的事物数据与业务数据(大数据中就是原始业务数据)。
周期快照事实表:基于事务事实表按照一定的周期进行聚合(大数据中就是统计分析的结果表)。
累积快照事实表:事实的结果随着时间的变化而不断完善(行数据逐渐补全)。
无事实事实表:特殊的事实表,无事实的事实表中没有度量值,只有多个维度外键,一般用于业务维度关联。常用于计算未发生的事实(通过字段,全部集合-发生事实的集合)。
事实指标值的分类
可累加类型:基于不同的维度和统计可以直接进行累加的值。例如:PV就是可以按天、月、年等维度累加的。
半可累加类型:在有一些维度下可以累加,在有一些维度下不可以累加。例如:不同形式的资产按照用户维度可以累加(基金+余额+余额宝),但是按照时间维度不可以累加。
不可累加类型:在任何维度下,指标的累加没有意义。例如:比例类型的数据大部分情况不应该累加(按分段累加出及格率新字段是另外一种情况)。
空值:不建议产生空值,事实表中不会出现空值(因为经过了ETL)。即使指标没有结果,也默认为0。
分层设计
分层设计决定了数据从进入到被应用,总共经过哪些步骤。
每一层在HIve中就是一个数据库而言,每一层的表放在对应的数据库中。
基本架构
原始数据层(ODS,原始数据层或者操作数据层),用于存储最原始的数据。
数据仓库层(DW:DWD、DWM、DWS,专门用于实现原始数据的处理和加工转换),实现原始数据的转换处理。
数据应用层(DA/APP/ADS,存储最终要被使用的数据),存储结果。
笔者之前做的数据分析体量不大,也就直接格式化后就拿来用了。。。但是生产环境数据量庞大,严禁ODS层直接到APP层。
常见分层
ODS层和APP层与上述基本架构一致,不再赘述。
DWD:详细数据层。一般用于将ODS的结果进行ETL处理,存储在DWD层中。
DWM:中间数据层。用于对DWD层的数据进行轻量级的通用性的处理和聚合的。一般看业务需求,如果简单的业务,一般不需要DWM层。
DWS/DM:汇总数据层/数据集市层。用于实现最终所有维度的指标的聚合分析,不同的部门需要的数据进行单独划分。
DIM:维度数据层。用于存储维度表的数据。有的公司的维度表时放在数据仓库Hive中,有的公司的维度表是在MySQL中。反正数据量不大,也都支持SQL操作,2种做法当然都可以。
TMP:临时数据层。一般用于存储一些临时数据表。
以上是关于数据仓库设计要点的主要内容,如果未能解决你的问题,请参考以下文章