python爬虫日记01
Posted 大树的困惑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫日记01相关的知识,希望对你有一定的参考价值。
PYTHON爬虫日记01
记录自己的学习爬虫日记
选用python作为编程语言
1.环境准备
python3.6+
pycharm
2.思路
以爬取猫眼top100为目标
1.分析url的规律
https://maoyan.com/board/4?offset=10 发现他们的url通过url参数offset作为分页的偏移参数
后续我们可以通过循环遍历自动爬取所有的分页
2.根据url爬取对应的html
爬取html有可能会触发反爬机制,可以通过配置headers进行避免(解决了,但是没完全解决)
3.解析html页面
通过引入python的解析包,将html解析成一颗树,然后根据树结构进行解析,解析的方法有很多种
可以通过包内提供的api,也可以通过正则,最好是能结合起来灵活使用
4.保存数据
将解析html页面之后的数据,封装起来,保存到mysql
5.将数据在可视化界面进行展示
3.开干
1.新建python项目
选择自己喜欢的目录,新建项目
2.引入包
from time import sleep #延时访问,避免过于频繁导致封ip
import pymysql #连接mysql,将数据存储
from bs4 import BeautifulSoup #解析html
import re # 正则表达式
import urllib.request, urllib.error # 定制url 获取网页数据
3.功能测试
urllib.request 请求页面
import urllib.request
url = 'https://maoyan.com/board/4?offset=' # 请求url
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
pymysql 连接mysql
import pymysql
#打开数据库连接
conn = pymysql.connect(
host='xxx.xx.xx.xx',# host
port = 3306, # 默认端口,根据实际修改
user='root',# 用户名
passwd='123456', # 密码
db ='luke_db', # DB name
)
cur = conn.cursor()
print(conn,cur)
cur.close()
conn.close()

能够成功输出,说明和mysql已经成功连接
mysql可以选择本地搭建,也可以远程连接,这里是我自己在linux搭建了一个mysql,通过远程连接实现的
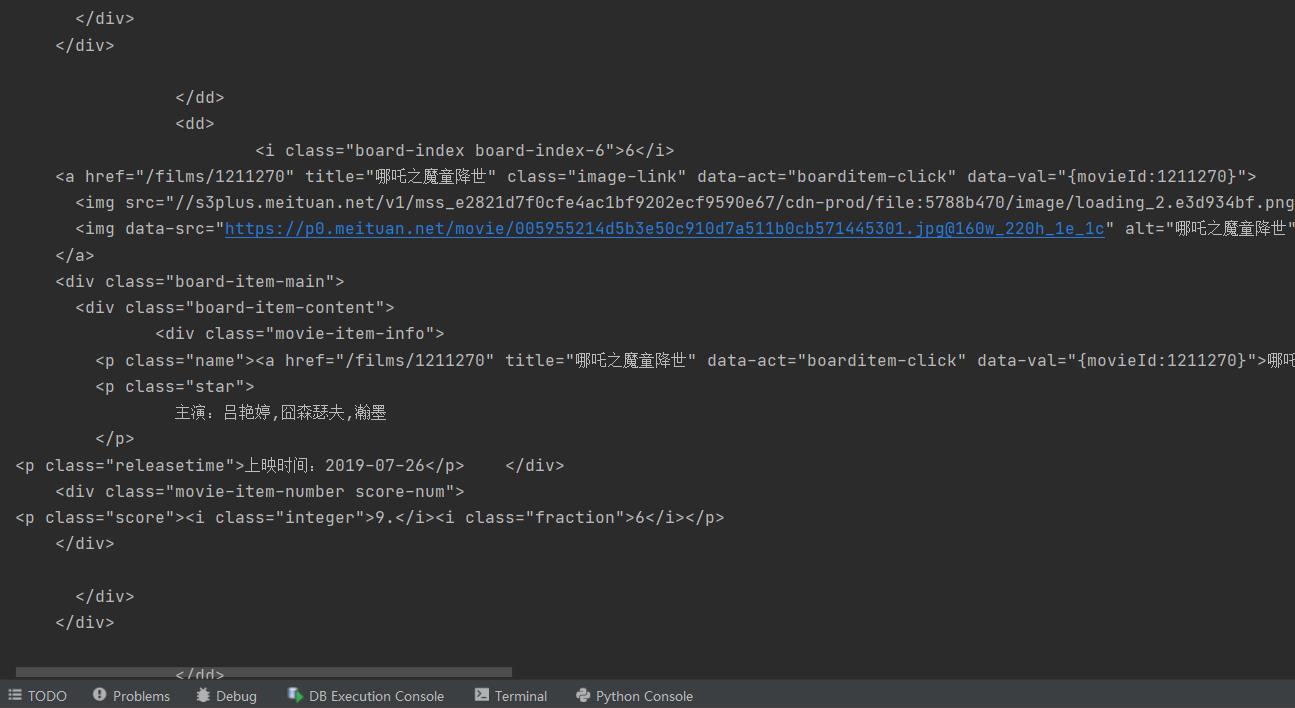
bs4.BeautifulSoup 解析html页面
import urllib.request
from bs4 import BeautifulSoup
url = 'https://maoyan.com/board/4?offset=' # 请求url
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# print(response.read().decode('utf-8'))
html = response.read().decode('utf-8')
html_parser = BeautifulSoup(html, "html.parser") #将请求返回的html进行解析,指定html.parser 解析器
html_a = html_parser.find_all("a") #抽取a标签
print(html_a)
可以看到输出的结果全是a标签
记录BeautifulSoup的一些常用方法
#1.Tag 标签及其内容;拿到它所找到的第一个内容
# print(bs.title.string)
#
# print(type(bs.title.string))
#2.NavigableString 标签里的内容(字符串)
#print(bs.a.attrs)
#print(type(bs))
#3.BeautifulSoup 表示整个文档
#print(bs.name)
#print(bs)
# print(bs.a.string)
# print(type(bs.a.string))
#4.Comment 是一个特殊的NavigableString ,输出的内容不包含注释符号
#-------------------------------
#文档的遍历
#print(bs.head.contents)
#print(bs.head.contents[1])
解析html还常用正则表达式,引入re包
import urllib.request
from bs4 import BeautifulSoup
import re
url = 'https://maoyan.com/board/4?offset=' # 请求url
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# print(response.read().decode('utf-8'))
html = response.read().decode('utf-8')
html_parser = BeautifulSoup(html, "html.parser")
html_a = html_parser.find_all("a") #取出A标签
html_a=str(html_a)#转字符串
find_maoyan_link = re.compile(r'.*?href="(.*?)"')#正则规则
html_href = re.findall(find_maoyan_link,html_a)#正则匹配
for item in html_href :#遍历打印
print(item)
# print(html_href)
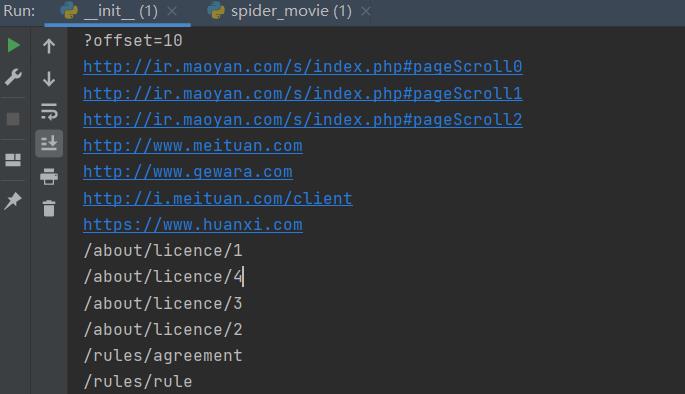
大致功能已经测试ok
4.完整的代码
import random
from time import sleep
import pymysql
from bs4 import BeautifulSoup
import re # 正则表达式
import urllib.request, urllib.error # 定制url 获取网页数据
def main():
parser_url_save()
def parser_url_save():
print("doing parser url ....")
# 猫眼https://maoyan.com/board/4?offset=10
# 豆瓣https://movie.douban.com/top250?start=25
urls = ['https://maoyan.com/board/4?offset=','https://movie.douban.com/top250?start=']
for url in urls:
if url.find('https://maoyan.com') !=-1 :
datalist = parser_html(url)
# datalist = getData_maoyan(html)
# print(datalist)
saveData_maoyan(datalist)
else :
# parser_DOUBAN(url)
print("parser douban ...")
# 正则列表
# 猫眼标题
find_maoyan_title = re.compile(r'.*?title="(.*?)"')
# 猫眼链接
find_maoyan_link = re.compile(r'.*?href="(.*?)"')
# 猫眼图片
find_maoyan_pic = re.compile(r'.*?<img.*?data-src="(.*?)"')
# 猫眼评分
find_maoyan_score1 = re.compile(r'<p class="score"><i class="integer">(.*?)<')
find_maoyan_score2 = re.compile(r'</i><i class="fraction">(.*?)<')
# 主演
find_maoyan_star = re.compile(r'.*主演:(.*)')
# 上映时间
find_maoyan_date = re.compile(r'上映时间:(.*)<')
def parser_html (url):
cookie = '###'
# agent=random.choice(user_agent)
agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
data_maoyan_list=[]
for i in range (0,10) :
sleep(3)
url_tmp = url+str(i*10)
headers = {
"User-Agent":agent
,"Cookie":cookie
}
req = urllib.request.Request(url_tmp, headers=headers)
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
data_maoyan_list = getData_maoyan(html,data_maoyan_list)
return data_maoyan_list
def getData_maoyan (html,data_maoyan_list):
html_parser = BeautifulSoup(html, "html.parser")
base_url = 'https://maoyan.com/'
item_list = html_parser.find_all('dd')
for item in item_list:
sleep(1) # 延时访问
# 单个电影的数据集
data = []
item_a = str(item.a)
# 取标题
title = re.findall(find_maoyan_title, item_a)[0]
# 取链接
curr_url = base_url + str(re.findall(find_maoyan_link, item_a)[0])
# 取图片链接
pic = re.findall(find_maoyan_pic, item_a)[0]
# 评分
item_p = item.select("p[class='score']")
# if i * 10 == 20:
# print(item_p)
score = "0.0" # 存在没有评分的重置0.0
if len(re.findall(find_maoyan_score1, str(item_p))) > 0:
score = float(str(re.findall(find_maoyan_score1, str(item_p))[0]) + str(
re.findall(find_maoyan_score2, str(item_p))[0]))
# 主演
# ’<p class="star">‘
item_star = item.select("p[class='star']")
# print(str(item_star))
star = re.findall(find_maoyan_star, str(item_star))[0]
# 上映时间 <p class="releasetime">
item_releasetime = item.select("p[class='releasetime']")
releasetime = re.findall(find_maoyan_date, str(item_releasetime))[0]
# 添加到数据集中,title,curr_url,pic,score,star,releasetime
data.append(title)
data.append(curr_url)
data.append(pic)
data.append(score)
data.append(star)
data.append(releasetime)
data_maoyan_list.append(data)
return data_maoyan_list
def saveData_maoyan(data_list):
conn = pymysql.connect(
host='xxx.xx.xx.xx',# host
port = 80, # 默认端口,根据实际修改
user='root',# 用户名
passwd='123456', # 密码
db ='luke_db', # DB name
)
cur=conn.cursor()
print(conn)
# 获取了数据列表
for id in range(0,len(data_list)):
# 取得字段
ind_id = str(id);
title = '"'+str(data_list[id][0])+'"' # 标题
link = '"'+str(data_list[id][1])+'"' # 连接
pic_link = '"'+str(data_list[id][2])+'"' # 图片连接
score = str(data_list[id][3]) # 评分
actor = '"'+str(data_list[id][4])+'"' # 主演
pub_date = '"'+str(data_list[id][5])+'"' # 上映时间
arr=[ind_id,title,link,pic_link,score,actor,pub_date]
sql='''
insert into luke_db.t_movie_top100_maoyan (xh,m_title,m_link,m_pic,m_score,m_actor,m_pubdate)
values(%s)'''%",".join(arr)
print(sql)
print(cur.execute(sql))
conn.commit() # 插入数据
cur.close()
conn.close()
if __name__== '__main__':
main()
这样一个简单的爬虫就实现了
查看一下数据库
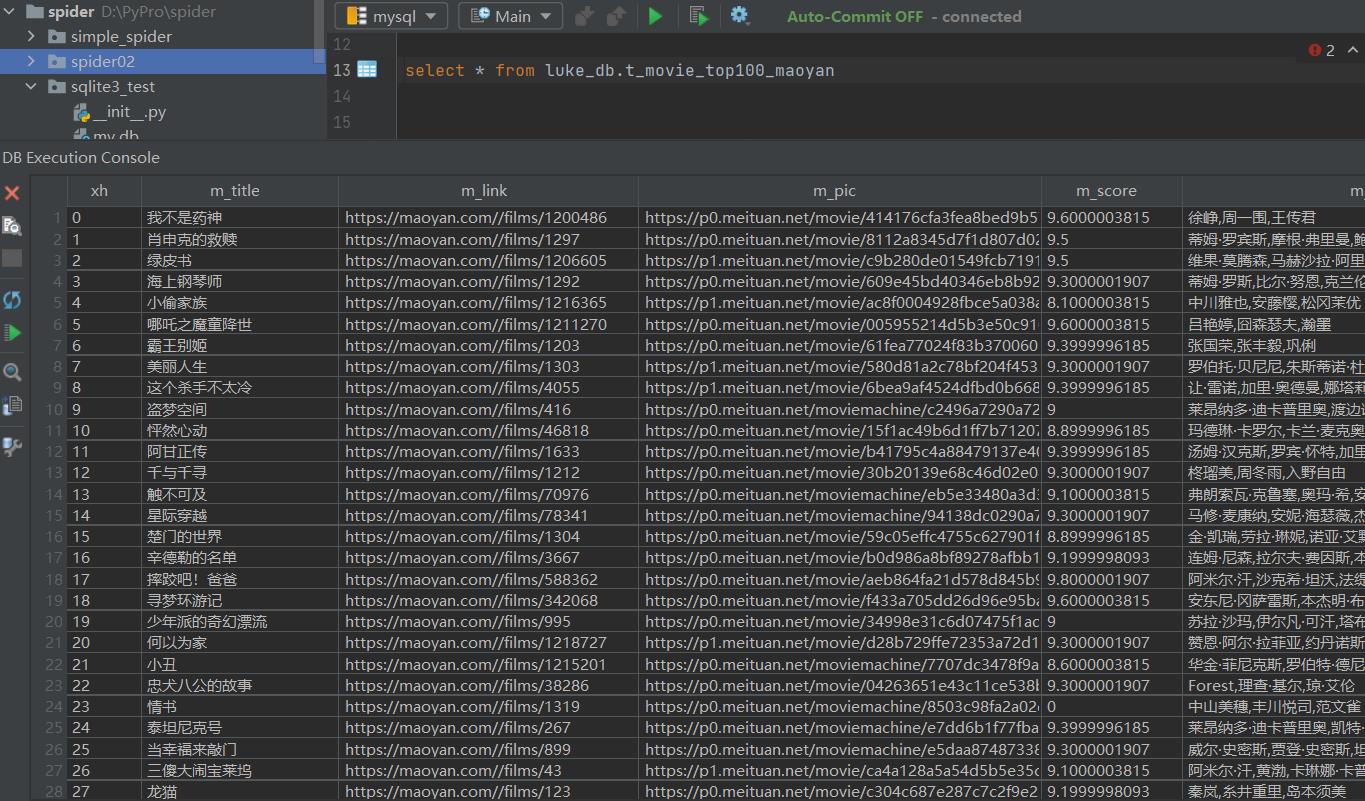
可以看到数据已经导入数据库中了
后续就可以根据数据库的数据,进行可视化搭建了
以上是关于python爬虫日记01的主要内容,如果未能解决你的问题,请参考以下文章