命名实体识别常用算法及工程实现
Posted 小贤算法屋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了命名实体识别常用算法及工程实现相关的知识,希望对你有一定的参考价值。



这篇文章将会记录一个作者在很久之前在Github写的一个开源项目:分别使用BiLSTM-CRF和Bert-BiLSTM-CRF这两种传统的模型做命名实体识别(Named Entity Recognition, NER)。
《 Bidirectional LSTM -CRF models for sequence ta gging》
长短期记忆网络
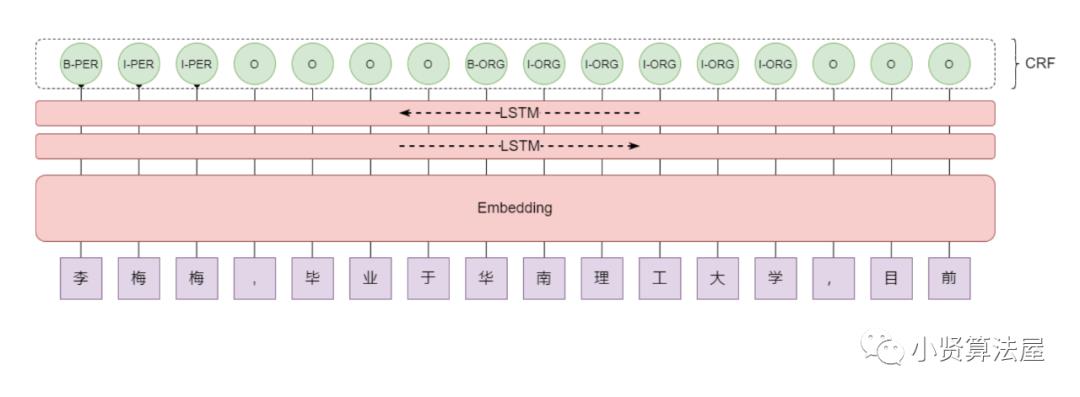
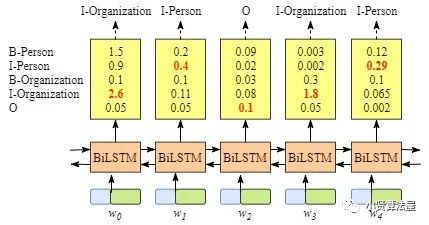
项目中我自己画的BiLSTM-CRF示意图以上,这是比较通用的NER模型方案,它由一个Embedding层,一个双向LSTM和一个条件随机场(CRF)组成,Embedding层可以是通过词表在模型里面初始化也可以外接词/句向量,两个LSTM分别从左至右和从右至左的“理解”句子的上下文语义,而CRF用来限定和预测最终合理的序列标签输出。这里先说说LSTM。
 ),这里主要写写LSTM的原理。为了解决梯度问题,LSTM将信息的流动用三个门进行控制,分别是遗忘门、输入门和输出门,分别对应下图的
),这里主要写写LSTM的原理。为了解决梯度问题,LSTM将信息的流动用三个门进行控制,分别是遗忘门、输入门和输出门,分别对应下图的
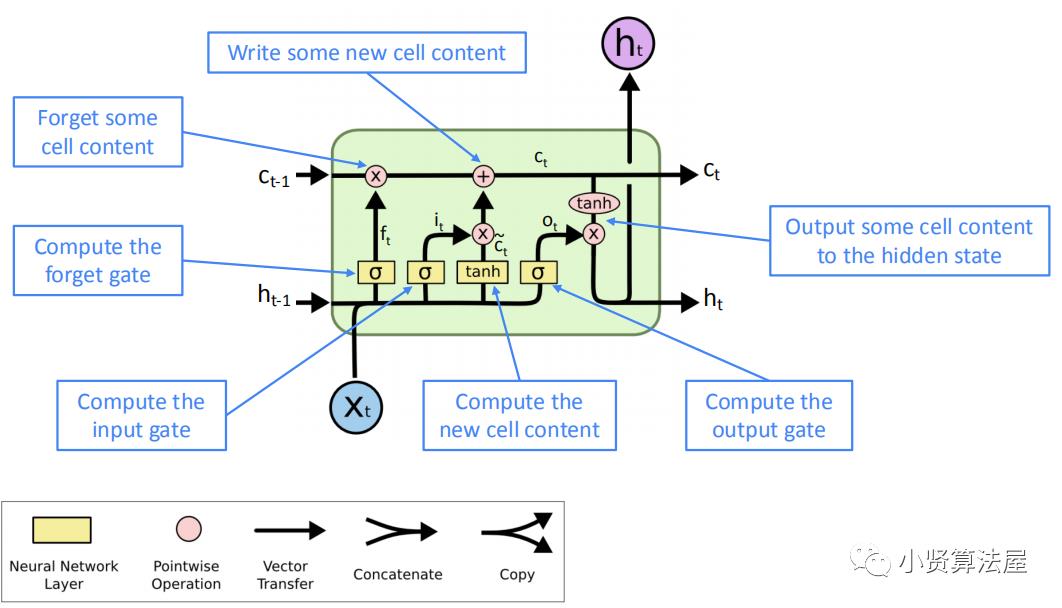
 )
)

命名实体识别
早期刚引入循环神经网络做NER的时候,LSTM就可以直接拿来做这项任务了,但是直接由BiLSTM进行NER任务会有一些不可避免的问题。所以引入了CRF来加到模型后面。
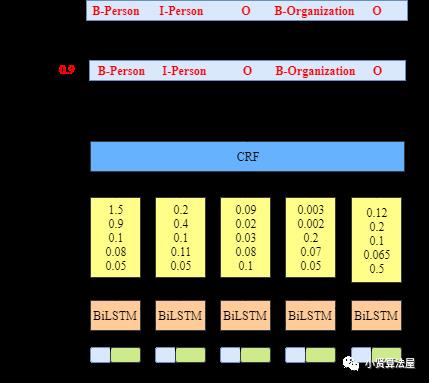
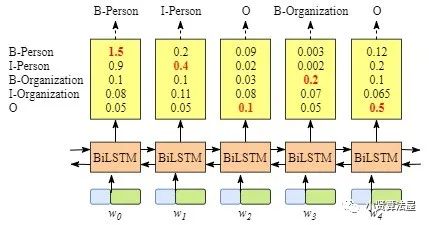
2.2 Bert-BiLSTM-CRF

提升NER性能的方法往往不是直接堆砌⼀个Bert+CRF,这样做不仅性能不一定会好,推断速度也非常堪忧;就算直接使用BERT+CRF进行finetune,BERT和CRF层的学习率也不要设成一样,让CRF层学习率要更大一些(一般是BERT的5~10倍),要让CRF层快速学习。
在NER任务上,也不要试图对BERT进⾏蒸馏压缩,很可能吃⼒不讨好。
NER任务是⼀个重底层的任务,上层模型再深、性能提升往往也是有限的(甚至是下降的);因此,不要盲目搭建很深的网络,也不要痴迷于各种attention了。
NER任务不同的解码方式(CRF/指针网络/Biaffine)之间的差异其实也是有限的,不要过分拘泥于解码⽅式。
通过QA阅读理解的方式进行NER任务,效果也许会提升,但计算复杂度上来了,你需要对同一个文本进行多次编码(对同⼀文本会构造多个question)。
设计NER任务时,尽量不要引入嵌套实体,不好做,这往往是一个长尾问题。
不要直接拿Transformer做NER,这是不合适的。
建立丰富的实体字典,融入更多的规则,在实体数据的丰富度和标注上多下功夫。
把精力集中在Eembedding层,引入丰富的特征,比如char、bigram、词典特征、词性特征等等,还有更多业务相关的特征,在这个文章项目中,只用到了char级别的特征,有兴趣的朋友可以尝试融合以上更多特征。
我们知道中文NER通常是基于字符进行标注的,这是由于基于词汇标注存在分词误差问题。但词汇边界对于实体边界是很有用的,我们该怎么把蕴藏词汇信息的词向量“恰当”地引入到模型中呢?一种行之有效的方法就是信息无损的、引入词汇信息的NER方法,我们可以做词汇增强。参考《中文NER的正确打开方式: 词汇增强方法总结 (从Lattice LSTM到FLAT)》
工程代码及使用
from abc import ABCimport tensorflow as tffrom tensorflow_addons.text.crf import crf_log_likelihoodclass BiLSTM_CRFModel(tf.keras.Model, ABC):def __init__(self, configs, vocab_size, num_classes, use_bert=False):super(BiLSTM_CRFModel, self).__init__()# 是否是使用Bert做Embeddingself.use_bert = use_bert# Embedding层self.embedding = tf.keras.layers.Embedding(vocab_size, configs.embedding_dim, mask_zero=True)# LSTM隐藏层维度self.hidden_dim = configs.hidden_dim# 神经网络的遗忘率self.dropout_rate = configs.dropoutself.dropout = tf.keras.layers.Dropout(self.dropout_rate)# 定义双向的LSTM层self.bilstm = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(self.hidden_dim, return_sequences=True))# 定义全连接层self.dense = tf.keras.layers.Dense(num_classes)# 定义CRF的转移状态矩阵self.transition_params = tf.Variable(tf.random.uniform(shape=(num_classes, num_classes)))@tf.functiondef call(self, inputs, inputs_length, targets, training=None):if self.use_bert:embedding_inputs = inputselse:# 如果不使用Bert,则就使用模型自己初始化的Embedding层embedding_inputs = self.embedding(inputs)dropout_inputs = self.dropout(embedding_inputs, training)bilstm_outputs = self.bilstm(dropout_inputs)logits = self.dense(bilstm_outputs)tensor_targets = tf.convert_to_tensor(targets, dtype=tf.int32)# 将BiLSTM的结果输入到CRF层,得到每个位置对应的对数似然和转移矩阵log_likelihood, self.transition_params = crf_log_likelihood(logits, tensor_targets, inputs_length, transition_params=self.transition_params)return logits, log_likelihood, self.transition_params
for i in range(epoch):start_time = time.time():{}/{}'.format(i + 1, epoch))for step, batch in tqdm(train_dataset.shuffle(len(train_dataset)).batch(batch_size).enumerate()):if configs.use_bert:y_train_batch, att_mask_batch = batch# 计算没有加入pad之前的句子的长度inputs_length = tf.math.count_nonzero(X_train_batch, 1)# 获得bert的模型输出model_inputs = bert_model(X_train_batch, attention_mask=att_mask_batch)[0]else:y_train_batch = batch# 计算没有加入pad之前的句子的长度inputs_length = tf.math.count_nonzero(X_train_batch, 1)model_inputs = X_train_batchwith tf.GradientTape() as tape:log_likelihood, transition_params = bilstm_crf_model(inputs=model_inputs, inputs_length=inputs_length, targets=y_train_batch, training=1)loss = -tf.reduce_mean(log_likelihood)# 定义好参加梯度的参数gradients = tape.gradient(loss, bilstm_crf_model.trainable_variables)# 反向传播,自动微分计算bilstm_crf_model.trainable_variables))
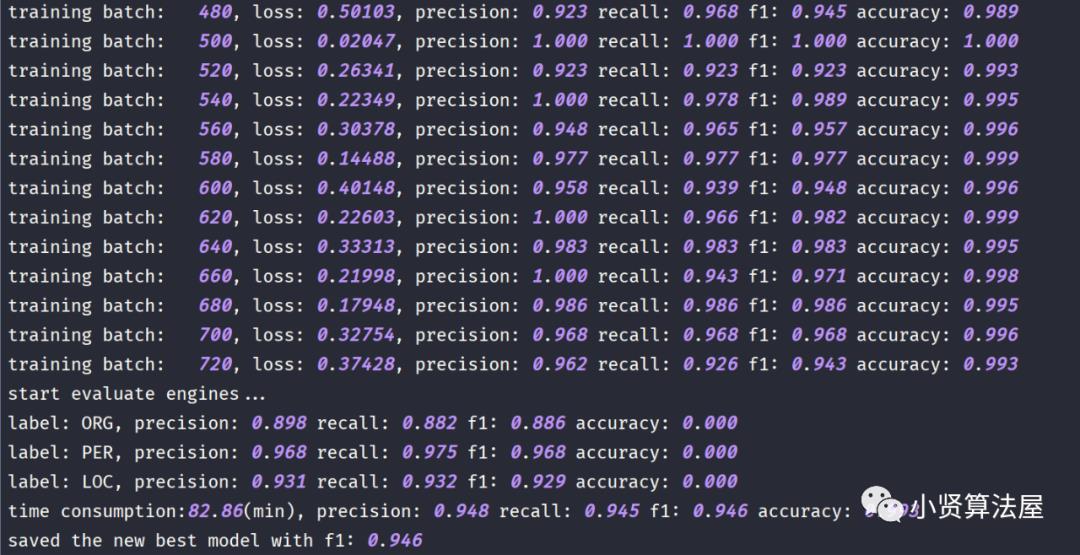

参考及引用
https://createmomo.github.io/2017/09/12/CRF_Layer_on_the_Top_of_BiLSTM_1/
工业界求解NER问题的12条黄金法则
JayLou娄杰,公众号:夕小瑶的卖萌屋
中文NER的正确打开方式: 词汇增强方法总结 (从Lattice LSTM到FLAT)
公众号:机器学习算法与自然语言处理
https://github.com/StanleyLsx/entity_extractor_by_ner

扫描二维码
小贤算法屋
以上是关于命名实体识别常用算法及工程实现的主要内容,如果未能解决你的问题,请参考以下文章