双层flume,中间件kafka,采集到hdfs并按日期分文件夹
Posted desperado0726
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了双层flume,中间件kafka,采集到hdfs并按日期分文件夹相关的知识,希望对你有一定的参考价值。
1.架构
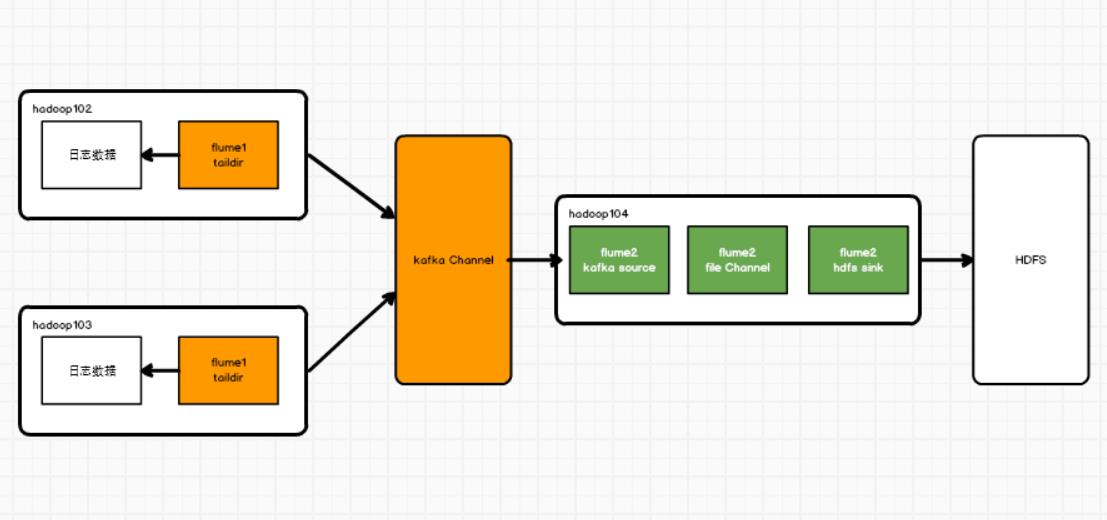
要采集的日志位于hadoop102和hadoop103两个节点上,采集数据到kafka中,这是第一层flume。
再从Kafka采集到hdfs中,这是第二层flume。
2.第一层flume
自定义拦截器,过滤非json数据
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.Iterator;
import java.util.List;
public class JsonInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
String bodyString = new String(event.getBody());
try {
JSONObject jsonObject = JSON.parseObject(bodyString);
} catch (Exception e) {
return null;
}
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iter = list.iterator();
while (iter.hasNext()) {
Event next = iter.next();
if (intercept(next) == null){
iter.remove();
}
}
return list;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new JsonInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
编写flume配置文件
#1、定义agent、source、channel名称
a1.sources = r1
a1.channels = c1
#2、描述source<taildir>
a1.sources.r1.type = TAILDIR
#指定文件组的名称
a1.sources.r1.filegroups = f1
#指定组监控的目录
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
#指定断点续传文件
a1.sources.r1.positionFile = /opt/module/flume/position.json
#指定一个批次采集多少数据
a1.sources.r1.batchSize = 100
#3、描述拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.interceptor.JsonInterceptor$Builder
#4、描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
#指定kafka集群地址
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
#指定数据写入的topic名称
a1.channels.c1.kafka.topic = applog
#数据写入kafka的时候是否以event格式写入: true=是 false: 不是,只写body数据
a1.channels.c1.parseAsFlumeEvent = false
#5、关联source->channel
a1.sources.r1.channels = c1
3.第二层flume
自定义拦截器,将时间戳写到请求头里,届时hdfs会自动读取head里的时间戳
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.List;
public class MyTimestampInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
JSONObject jsonObject = JSON.parseObject(new String(body));
Long ts = jsonObject.getLong("ts");
event.getHeaders().put("timestamp",ts+"");
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
for (Event event : list) {
intercept(event);
}
return list;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new MyTimestampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
编写第二层flume配置文件
#1、定义agent、channel、source、sink名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#2、描述source
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
#指定kafka集群地址
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
#指定从哪个topic读取数据
a1.sources.r1.kafka.topics = applog
#指定消费者组的id
a1.sources.r1.kafka.consumer.group.id = g1
#指定source从kafka一个批次拉取多少条消息: batchSize<=事务容量<=channel容量
a1.sources.r1.batchSize = 100
#指定消费者组第一个消费topic的数据的时候从哪里开始消费
a1.sources.r1.kafka.consumer.auto.offset.reset = earliest
#3、描述拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.interceptor.MyTimestampInterceptor$Builder
#4、描述channel
a1.channels.c1.type = file
#指定数据保存在本地磁盘哪个目录
a1.channels.c1.dataDirs = /opt/module/flume/datas
#指定channel内存中event的指针数据
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint
#指定checkpoint的持久化的间隔时间
a1.channels.c1.checkpointInterval = 5000
#指定channel容量
a1.channels.c1.capacity = 1000000
#5、描述sink
a1.sinks.k1.type = hdfs
#指定数据存储目录,%Y%m%d会根据时间戳创建该目录
a1.sinks.k1.hdfs.path = hdfs://hadoop102:9820/applog/%Y%m%d
#指定文件的前缀
a1.sinks.k1.hdfs.filePrefix = log-
#指定滚动生成文件的时间间隔
a1.sinks.k1.hdfs.rollInterval = 30
#指定滚动生成文件的大小
a1.sinks.k1.hdfs.rollSize = 132120576
#指定写入多少个event之后滚动生成新文件<一般禁用>
a1.sinks.k1.hdfs.rollCount = 0
#指定sink每个批次从channel拉取多少数据
a1.sinks.k1.hdfs.batchSize = 100
#指定写入hdfs的时候压缩格式
#a1.sinks.k1.hdfs.codeC = lzop
#指定文件写入的是格式 SequenceFile-序列化文件, DataStream-文本文件, CompressedStream-压缩文件
#a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.fileType = DataStream
#6、关联source->channel->sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
4.打jar包,放到flume下的lib目录下
5.启动flume
bin/flume-ng agent --name a1 --conf-file kafka_to_hdfs.conf
bin/flume-ng agent --name a1 --conf-file tail_to_kafka.conf
以上是关于双层flume,中间件kafka,采集到hdfs并按日期分文件夹的主要内容,如果未能解决你的问题,请参考以下文章
如何在Kerberos环境使用Flume采集Kafka数据并写入HDFS
实战系列Flume + kafka + HDFS构建日志采集系统