Dubbo 的基本应用
Posted Se7en的架构笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dubbo 的基本应用相关的知识,希望对你有一定的参考价值。
Dubbo 采用全 Spring 配置方式,透明化接入应用,对应用没有任何 API 侵入,只需用 Spring 加载 Dubbo 的配置即可。本文列举了 Dubbo 的一些常见的使用场景:例如负载均衡,集群容错,超时等。
配置文件
配置文件使用 properties 或者 yaml 格式都可以。
服务端配置文件
# Spring boot application
spring.application.name=dubbo-provider-demo
server.port=8081
# Base packages to scan Dubbo Component: @org.apache.dubbo.config.annotation.Service
dubbo.scan.base-packages=com.tuling.provider.service
dubbo.application.name=${spring.application.name}
## Dubbo Registry
dubbo.registry.address=zookeeper://127.0.0.1:2181
# Dubbo Protocol
dubbo.protocols.p1.id=dubbo1
dubbo.protocols.p1.name=dubbo
dubbo.protocols.p1.port=20881
dubbo.protocols.p1.host=0.0.0.0
dubbo.protocols.p2.id=dubbo2
dubbo.protocols.p2.name=dubbo
dubbo.protocols.p2.port=20882
dubbo.protocols.p2.host=0.0.0.0
dubbo.protocols.p3.id=dubbo3
dubbo.protocols.p3.name=dubbo
dubbo.protocols.p3.port=20883
dubbo.protocols.p3.host=0.0.0.0
# REST Protocol
dubbo.protocols.p4.id=rest1
dubbo.protocols.p4.name=rest
dubbo.protocols.p4.port=8083
dubbo.protocols.p4.host=0.0.0.0
消费端配置文件
spring:
application:
name: dubbo-consumer-demo
server:
port: 8082
dubbo:
registry:
address: zookeeper://127.0.0.1:2181
Zookeeper 配置
zookeeper 下载链接:https://zookeeper.apache.org/releases.html
解压后,进入目录,使用如下命令启动:
bin/zkServer.sh start
消费端服务注册
服务端有 6 个实现类实现了 DemoService 接口:
启动服务端,在 zookeeper 上可以看到服务端总共注册了 3 * 6 = 18 个服务。 3 是 在 application.properties 中配置了 3 个 dubbo 服务的端口,6是 Provider 有 6 个 DemoService 的实现类。
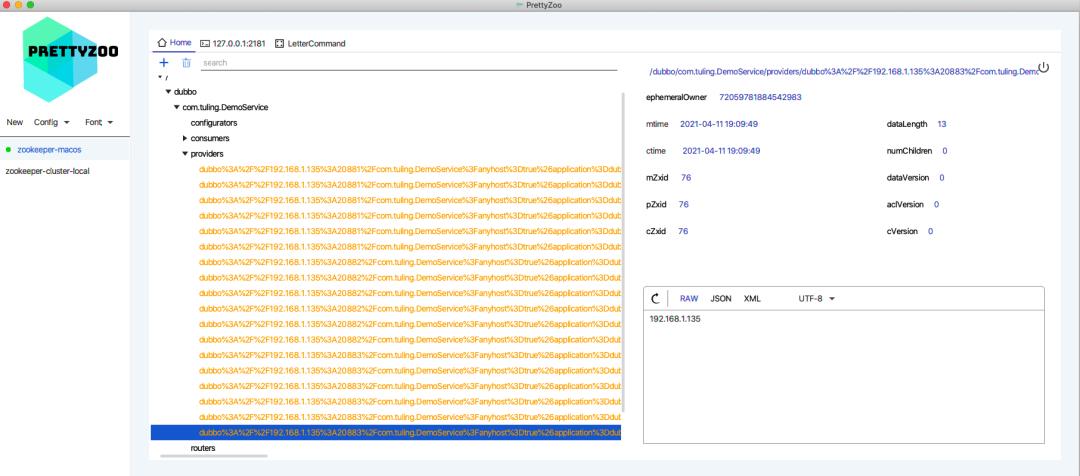
通过 URLDecode 可以看到注册的服务信息:
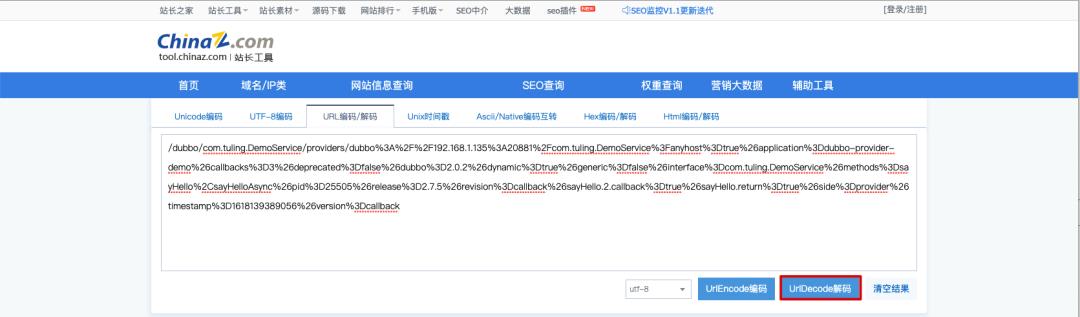
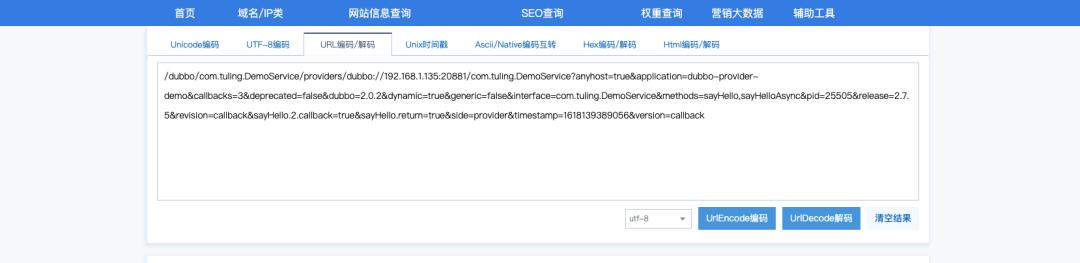
以下介绍的负载均衡,服务超时等特性既可以在服务端配置,也可以在消费端配置,如果两边都配置了,以消费端的为准。
负载均衡
在集群负载均衡时,Dubbo 提供了多种均衡策略,缺省为 random 随机调用。 Dubbo 支持以下负载均衡策略:
-
Random LoadBalance 随机,按权重设置随机概率。 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。 -
RoundRobin LoadBalance 轮询,按公约后的权重设置轮询比率。 存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。 -
LeastActive LoadBalance 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。 使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。 -
ConsistentHash LoadBalance 一致性 Hash,相同参数的请求总是发到同一提供者。 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
轮询算法
依次按顺序轮询请求后端服务。
package com.tuling.consumer;
import com.tuling.DemoService;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.ConfigurableApplicationContext;
import java.io.IOException;
/**
* 负载均衡示例消费端
*/
@EnableAutoConfiguration
public class LoadBalanceDubboConsumerDemo {
// 轮询算法测试
@Reference(version = "default", loadbalance = "roundrobin")
private DemoService demoService;
public static void main(String[] args) throws IOException {
ConfigurableApplicationContext context = SpringApplication.run(LoadBalanceDubboConsumerDemo.class);
DemoService demoService = context.getBean(DemoService.class);
// 轮询算法测试
for (int i = 0; i < 1000; i++) {
System.out.println((demoService.sayHello("chengzw")));
try {
Thread.sleep(1 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
请求结果,按顺序轮询请求每一个后端服务:
dubbo:20882, Hello, chengzw
dubbo:20881, Hello, chengzw
dubbo:20883, Hello, chengzw
dubbo:20882, Hello, chengzw
dubbo:20881, Hello, chengzw
dubbo:20883, Hello, chengzw
dubbo:20882, Hello, chengzw
dubbo:20881, Hello, chengzw
dubbo:20883, Hello, chengzw
一致性 Hash 算法
一致性 Hash,相同参数的请求总是发到同一提供者。 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
package com.tuling.consumer;
import com.tuling.DemoService;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.ConfigurableApplicationContext;
import java.io.IOException;
/**
* 负载均衡示例消费端
*/
@EnableAutoConfiguration
public class LoadBalanceDubboConsumerDemo {
// 一致性hash算法测试
@Reference(version = "default", loadbalance = "consistenthash")
private DemoService demoService;
public static void main(String[] args) throws IOException {
ConfigurableApplicationContext context = SpringApplication.run(LoadBalanceDubboConsumerDemo.class);
DemoService demoService = context.getBean(DemoService.class);
// 一致性hash算法测试
for (int i = 0; i < 1000; i++) {
System.out.println((demoService.sayHello(i%5+"chengzw")));
try {
Thread.sleep(1 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
请求结果,可以看到相同参数的请求都是发往同一个服务:
dubbo:20881, Hello, 0chengzw
dubbo:20882, Hello, 1chengzw
dubbo:20882, Hello, 2chengzw
dubbo:20883, Hello, 3chengzw
dubbo:20882, Hello, 4chengzw
dubbo:20881, Hello, 0chengzw
dubbo:20882, Hello, 1chengzw
dubbo:20882, Hello, 2chengzw
dubbo:20883, Hello, 3chengzw
dubbo:20882, Hello, 4chengzw
最小连接数
Dubbo 的最少活跃数是在消费者提供者端进行统计的,逻辑如下:
-
消费者会缓存所调用服务的所有提供者,比如记为 p1、p2、p3 三个服务提供者,每个提供者内都有一个属性记为 active,默认位 0。 -
消费者在调用次服务时,如果负载均衡策略是leastactive,消费者端会判断缓存的所有服务提供者的 active,选择最小的,如果都相同,则随机。 -
选出某一个服务提供者后,假设为 p2,Dubbo 就会对 p2.active+1 然后真正发出请求调用该服务。 -
消费端收到响应结果后,对 p2.active-1。 -
这样就完成了对某个服务提供者当前活跃调用数进行了统计,并且并不影响服务调用的性能。
超时
在服务提供者和服务消费者上都可以配置服务超时时间,这两者是不一样的。 消费者调用一个服务,分为三步:
-
消费者发送请求(网络传输) -
服务端执行服务 -
服务端返回响应(网络传输)
如果在服务端和消费端只在其中一方配置了 timeout,那么没有歧义,表示消费端和服务端的超时时间,消费端如果超过时间还没有收到响应结果,则消费端会抛超时异常,但是服务端不会抛异常,服务端在执行服务后,会检查执行该服务的时间,如果超过 timeout,则会打印一个超时日志,服务会正常的执行完。
如果在服务端和消费端各配了一个timeout,那就比较复杂了,假设
-
服务执行为5s -
消费端timeout=3s -
服务端timeout=6s
那么消费端调用服务时,消费端会收到超时异常(因为消费端超时了),服务端一切正常(服务端没有超时)。超时客户端默认会重试 2 次,加上第 1 次调用,总共会有 3 次请求。
服务端代码
package com.tuling.provider.service;
import com.tuling.DemoService;
import org.apache.dubbo.common.URL;
import org.apache.dubbo.config.annotation.Service;
import org.apache.dubbo.rpc.RpcContext;
import java.util.concurrent.TimeUnit;
/**
* 超时示例服务端
*/
@Service(version = "timeout", timeout = 6000, protocol = {"p1", "p2", "p3"})
public class TimeoutDemoService implements DemoService {
@Override
public String sayHello(String name) {
System.out.println("执行了timeout服务" + name);
// 服务执行5秒
// 服务超时时间为3秒,但是执行了5秒,服务端会把任务执行完的
// 服务的超时时间,是指如果服务执行时间超过了指定的超时时间则会抛一个warn(例如把修改timeout = 4000)
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("执行结束" + name);
URL url = RpcContext.getContext().getUrl();
return String.format("%s:%s, Hello, %s", url.getProtocol(), url.getPort(), name); // 正常访问
}
}
消费端代码
package com.tuling.consumer;
import com.tuling.DemoService;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.ConfigurableApplicationContext;
import java.io.IOException;
/**
* 超时示例消费端
*/
@EnableAutoConfiguration
public class TimeoutDubboConsumerDemo {
@Reference(version = "timeout", timeout = 3000)
private DemoService demoService;
public static void main(String[] args) throws IOException {
ConfigurableApplicationContext context = SpringApplication.run(TimeoutDubboConsumerDemo.class);
DemoService demoService = context.getBean(DemoService.class);
// 服务调用超时时间为1秒,默认为3秒
// 如果这1秒内没有收到服务结果,则会报错
System.out.println((demoService.sayHello("chengzw"))); //xxservestub
}
}
查看输出,客户端抛出了超时异常:
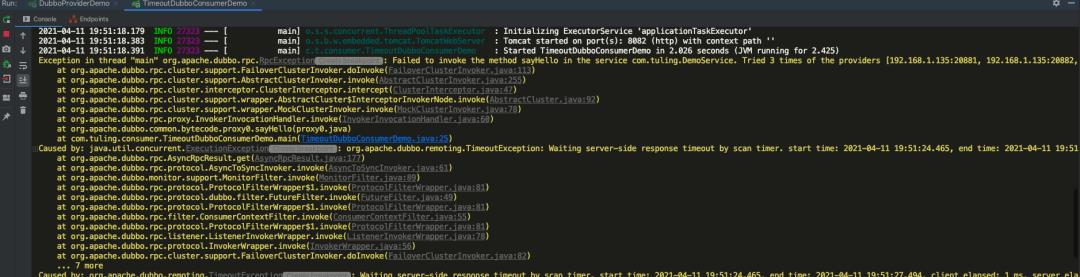
服务端正常执行:
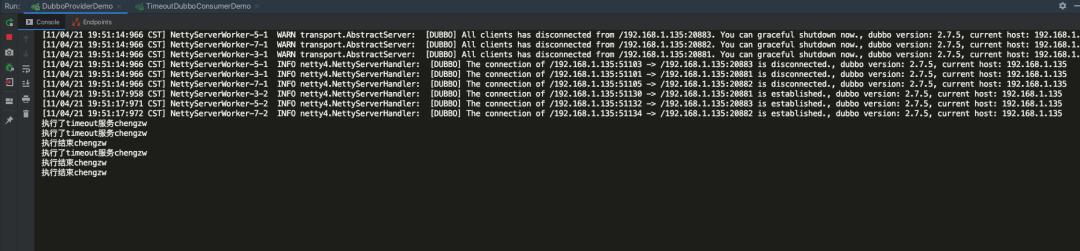
集群容错
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。 dubbo 集群容错策略如下:
-
Failover Cluster 失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)。 -
Failfast Cluster 快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。 -
Failsafe Cluster 失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。 -
Failback Cluster 失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。 -
Forking Cluster 并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。 -
Broadcast Cluster 广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
本例使用 Failfast Cluster 模式,只发起一次调用,失败立即报错。
package com.tuling.consumer;
import com.tuling.DemoService;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.ConfigurableApplicationContext;
import java.io.IOException;
/**
* 集群容错示例消费端
*/
@EnableAutoConfiguration
public class ClusterDubboConsumerDemo {
@Reference(version = "timeout", timeout = 1000, cluster = "failfast")
private DemoService demoService;
public static void main(String[] args) throws IOException {
ConfigurableApplicationContext context = SpringApplication.run(ClusterDubboConsumerDemo.class);
DemoService demoService = context.getBean(DemoService.class);
System.out.println((demoService.sayHello("chengzw")));
}
}
查看消费端日志,可以看到请求失败一次立即报错,而不是和前面超时的例子中一样还重试 2 次:
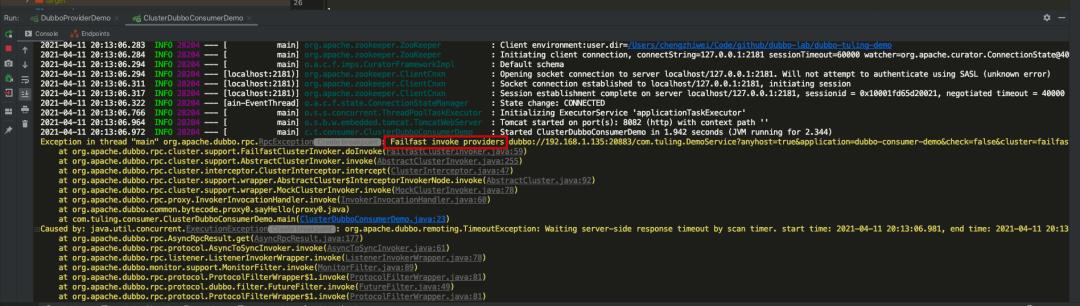
服务降级
服务降级表示:服务消费者在调用某个服务提供者时,如果该服务提供者报错了,所采取的措施。 集群容错和服务降级的区别在于:
-
集群容错是整个集群范围内的容错。 -
服务降级是单个服务提供者的自身容错。
可以通过服务降级功能临时屏蔽某个出错的非关键服务,并定义降级后的返回策略:
-
mock=force:return+null 表示消费方对该服务的方法调用都直接返回 null 值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。 -
还可以改为 mock=fail:return+null 表示消费方对该服务的方法调用在失败后,再返回 null 值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响。
package com.tuling.consumer;
import com.tuling.DemoService;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.ConfigurableApplicationContext;
import java.io.IOException;
/**
* 服务降级示例消费端
*/
@EnableAutoConfiguration
public class MockDubboConsumerDemo {
//如果消费者调用服务端失败,不抛出异常,而是返回 123
@Reference(version = "timeout", timeout = 1000, mock = "fail: return 123")
private DemoService demoService;
public static void main(String[] args) throws IOException {
ConfigurableApplicationContext context = SpringApplication.run(MockDubboConsumerDemo.class);
DemoService demoService = context.getBean(DemoService.class);
System.out.println((demoService.sayHello("chengzw")));
}
}
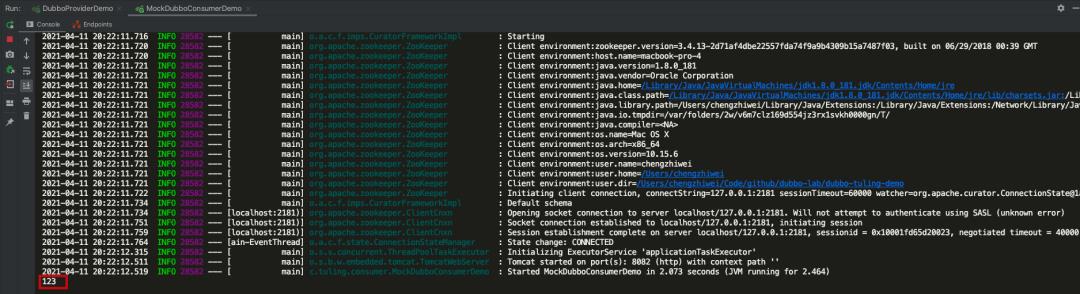
本地存根
本地存根,名字很抽象,但实际上不难理解,本地存根就是一段逻辑,这段逻辑是在服务消费端执行的,这段逻辑一般都是由服务提供者提供,服务提供者可以利用这种机制在服务消费者远程调用服务提供者之前或之后再做一些其他事情,比如结果缓存,请求参数验证,错误处理等等。
本地存根(Stub) 比 前面的 Mock(服务降级) 功能更强大。
下面示例在消费端调用 sayHello() 方法时,实际上是调用 DemoServiceStub 类的 sayHello() 方法。 消费端代码
package com.tuling.consumer;
import com.tuling.DemoService;
import org.apache.dubbo.config.annotation.Reference;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.context.ConfigurableApplicationContext;
import java.io.IOException;
/**
* 本地存根示例消费端
*/
@EnableAutoConfiguration
public class StubDubboConsumerDemo {
//写法一:
//@Reference(version = "timeout", timeout = 1000, stub = "com.tuling.DemoServiceStub")
//写法二:会用 demoService 的类全名 com.tuling.DemoService 拼接上 Stub,然后去找这个类
//只要这个类在消费端的classpath中能找到就行
@Reference(version = "timeout", timeout = 1000, stub = "true")
private DemoService demoService;
public static void main(String[] args) throws IOException {
ConfigurableApplicationContext context = SpringApplication.run(StubDubboConsumerDemo.class);
DemoService demoService = context.getBean(DemoService.class);
System.out.println((demoService.sayHello("chengzw")));
}
}
实现类代码
package com.tuling;
/**
* 本地存根示例真正的实现类
*/
public class DemoServiceStub implements DemoService {
private final DemoService demoService;
// 构造函数传入真正的远程代理对象
public DemoServiceStub(DemoService demoService){
this.demoService = demoService;
}
@Override
public String sayHello(String name) {
// 此代码在客户端执行, 你可以在客户端做ThreadLocal本地缓存,或预先验证参数是否合法,等等
try {
return demoService.sayHello(name); // safe null
} catch (Exception e) {
// 你可以容错,可以做任何AOP拦截事项
return "容错数据";
}
}
}
查看消费端日志,出现错误时会实行 try catch 的逻辑:
REST
Dubbo的REST也是Dubbo所支持的一种协议。
当我们用 Dubbo 提供了一个服务后,如果消费者没有使用 Dubbo 也想调用服务,那么这个时候我们就可以让我们的服务支持 REST 协议,这样消费者就可以通过 REST 形式调用我们的服务了。
package com.tuling.provider.service;
import com.tuling.DemoService;
import org.apache.dubbo.common.URL;
import org.apache.dubbo.config.annotation.Service;
import org.apache.dubbo.rpc.RpcContext;
import org.apache.dubbo.rpc.protocol.rest.support.ContentType;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.QueryParam;
/**
* REST示例服务端
*/
@Service(version = "rest")
@Path("demo")
public class RestDemoService implements DemoService {
@GET
@Path("say")
@Produces({ContentType.APPLICATION_JSON_UTF_8, ContentType.TEXT_XML_UTF_8})
@Override
public String sayHello(@QueryParam("name") String name) {
System.out.println("执行了rest服务" + name);
URL url = RpcContext.getContext().getUrl();
return String.format("%s: %s, Hello, %s", url.getProtocol(), url.getPort(), name); // 正常访问
}
}
以上是关于Dubbo 的基本应用的主要内容,如果未能解决你的问题,请参考以下文章