log4j2解密:初探插件模式及其应用
Posted TLTP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了log4j2解密:初探插件模式及其应用相关的知识,希望对你有一定的参考价值。
每个技术人都会经常和日志打交道,作为最有效记录运行现场的手段之一,查问题时往往第一个线索就是看日志。看似简单的日志背后,日志框架做了哪些事,java最强日志框架log4j2是怎么炼成的,让我们来逐一解密
在java开发技术栈中,log4j2是目前最强大也是更新最活跃的一款日志框架,目前共有2273个类和29万行代码,作为比较spring-boot共有5396个类和53万行代码,可见log4j2并不是一个简单项目;而logback和slf4j的最新稳定版还停留在4年前,有点凉凉的意思,也侧面说明了log4j2背后维护者的技术实力。
那么log4j2在技术上强在哪里,有哪些特性值得深入研究呢,这里从log4j2官方文档截取了一部分主要特性
Log4j2设计为可用作审核日志记录框架。重新配置时,Log4j 1.x和Logback都将丢失事件,Log4j2不会丢失日志。
Log4j2包含基于LMAX Disruptor库的下一代异步记录器。在多线程方案中,与Log4j1.x和Logback相比,异步Logger的吞吐量高10倍,延迟降低了几个数量级。
Log4j2在单机应用是“无垃圾”模式运行,在稳态记录期间的Web应用程序也只有少量内存垃圾。这样可以减少垃圾收集器上的压力,并可以提供更好的响应时间性能。
Log4j2设计了一套Plugin系统,通过添加新的Appenders, Filters,Layouts,Lookups和Pattern Converters,而无需对Log4j进行任何更改,可以非常轻松地扩展框架。
支持lambda表达式。只有在启用了请求的日志级别的情况下才会执行,在Java8之后可以使用lambda表达式来延迟构造日志消息。不需要显式级别检查,从而使代码更整洁。
支持Message对象。消息允许通过日志系统传递复杂结构,并对其进行特定的操作。用户可以创建自己的消息类型,并编写自定义Layouts,Filters和 Lookups来进行操作。
今天主要从整体架构设计说起,来介绍下log4j2的插件系统背后的运行原理,并结合实战案例来解析
log4j2的整体架构设计
引用官方类图来说明
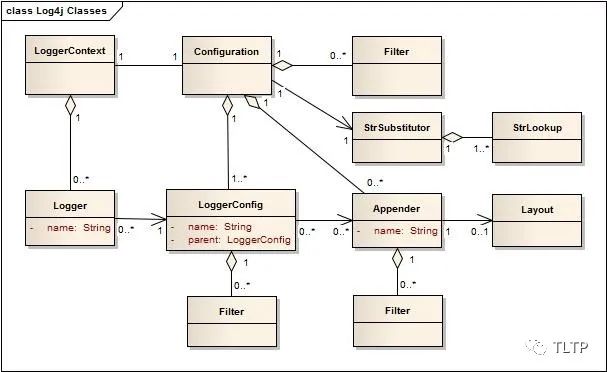
LoggerContext 的角色是整个日志系统的根节点,会在第一次调用getLogger时被创建,每个LoggerContext有一个有效的Configuration. Configuration 包含所有的Appenders,context层面的Filters和控制日志级别的LoggerConfigs。当log4j2.xml配置修改后,Configuration会被定时更新。
LoggerConfigs 是用来构造logger的层级关系,例如cn.sun是cn.sun.com的父层级,logger level和additive都是在这里配置。
Loggers 是通过调用 LogManager.getLogger 创建出来. logger本身没有任何逻辑定义,只是有个名称和关联对于的LoggerConfig. 如果configuration改变了 Loggers可以和新的LoggerConfig关联上, 从而实现控制level、additive等行为变化.
Appender 在log4j里用来定义输出目标. 目前支持console, files, remote socket servers, Apache Flume, JMS, remote UNIX Syslog daemons 和各种database APIs.
Filter 用来控制日志是否要打印,可以返回Accept, Deny or Neutral三种结果
log4j2的插件系统
先来看看插件模式的定义 https://en.wikipedia.org/wiki/Plug-in_(computing)
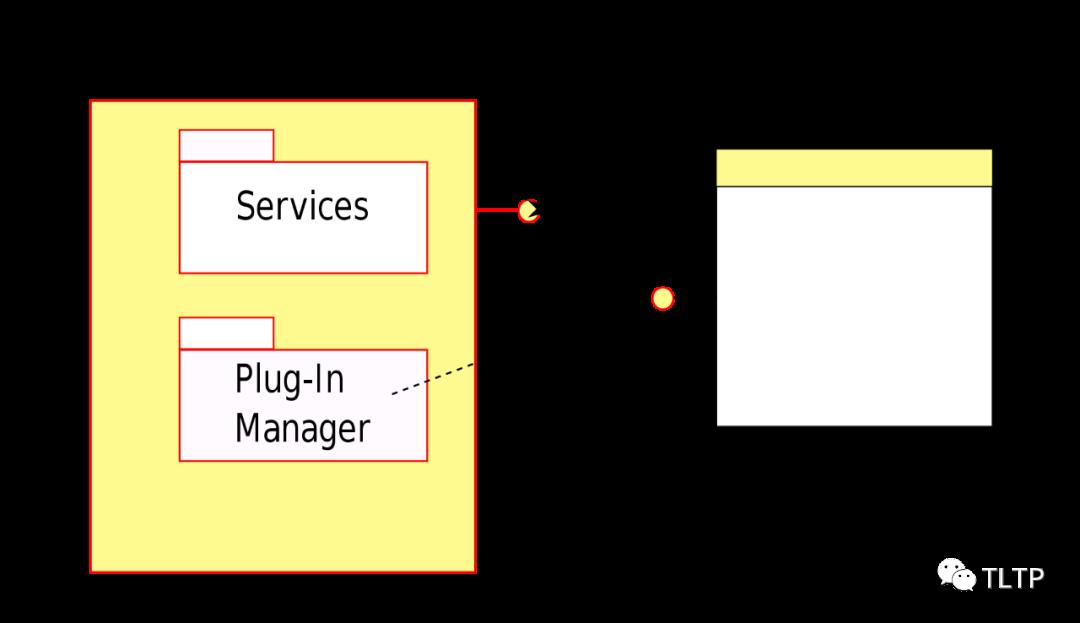
这个定义抽象出实现一套插件系统必须有两部分:一组服务接口 (Service Interface),提供(约束)了插件对主体可操作的边界。定义一种扩展契约 (Plug-In Interface),描述了插件可以扩展的能力,以及如何被主体发现。至于主体是否能独立运行,个人理解不是必要条件,比如插卡式游戏机是一套插件系统,但本身不能独立运行。
插件模式的核心是面向接口编程,同时加入了可插拔替换的设计理念。基于插件模式的理念,业内有很多具体场景的延申:例如微核心设计思想、jdk spi扩展机制、spring容器的IOC理念、OSGI、JNDI等。那么log4j2的插件系统是怎么实现的呢,让我们来一步步剖析。
log4j2常用Plugin
Appender :定义日志记录方式
RewritePolicy :定义日志重写策略
RollingPolicy :定义日志切分策略
Filter :定义日志过滤策略
Layout :定义日志格式
Plugin的定义方式
定义一个Plugin的方式也很简单,只需要继承特定的类并加上@Plugin注解,以log4j2自带的RollingFileAppender为例
/*** An appender that writes to files and can roll over at intervals.*/(name = RollingFileAppender.PLUGIN_NAME, category = Core.CATEGORY_NAME, elementType = Appender.ELEMENT_TYPE, printObject = true)public final class RollingFileAppender extends AbstractOutputStreamAppender<RollingFileManager> {public static final String PLUGIN_NAME = "RollingFile";...}
Plugin的使用方式
log4j2的plugin都可以在配置文件里声明式使用,例如定义一个每天切分、每500MB切分、最大切分1000个文件的appender
<!-- 使用RollingFile plugin --><Appender type="RollingFile" name="app" fileName="test.log" filePattern = "test.log.%d{yyyy-MM-dd}_%i"><Policies><!-- 使用TimeBasedTriggeringPolicy plugin --><TimeBasedTriggeringPolicy/><!-- 使用SizeBasedTriggeringPolicy plugin --><SizeBasedTriggeringPolicy size="500 MB"/></Policies><!-- 使用DefaultRolloverStrategy plugin --><DefaultRolloverStrategy max="1000" /><!-- 使用PatternLayout plugin --><Layout type="PatternLayout"><Charset>UTF-8</Charset><Pattern>${app.log.layout}</Pattern></Layout></Appender>
Plugin的发现机制
重点来了,如果我们定义了自己的plugin,log4j2是如何发现并加载这些plugin的呢?
祭出google大法,搜到的大部分文章都会介绍log4j2会读取从类路径下的所有Log4j2Plugins.dat文件,由PluginManager调用PluginRegister解析所有@Plugin类全称并完成plugin的注册。眼见为实,查看log4j2源码找到了Log4j2Plugins.dat和PluginManager加载插件的逻辑
log4j-core-2.13.3.jarMETA-INForg.apache.logging.log4j.core.config.pluginsLog4j2Plugins.dat
public class PluginManager {...public void collectPlugins(final List<String> packages) {final String categoryLowerCase = category.toLowerCase();final Map<String, PluginType>> newPlugins = new LinkedHashMap<>();// 步骤1, iterate the Log4j2Plugin.dat files found in the main CLASSPATHMap<String, List<PluginType>>> builtInPlugins = PluginRegistry.getInstance().loadFromMainClassLoader();if (builtInPlugins.isEmpty()) {builtInPlugins = PluginRegistry.getInstance().loadFromPackage(LOG4J_PACKAGES);}mergeByName(newPlugins, builtInPlugins.get(categoryLowerCase));// 步骤2, iterate any Log4j2Plugin.dat files from OSGi Bundlesfor (final Map<String, List<PluginType>>> pluginsByCategory : PluginRegistry.getInstance().getPluginsByCategoryByBundleId().values()) {mergeByName(newPlugins, pluginsByCategory.get(categoryLowerCase));}// 步骤3 iterate any packages passed to the static addPackage method.for (final String pkg : PACKAGES) {mergeByName(newPlugins, PluginRegistry.getInstance().loadFromPackage(pkg).get(categoryLowerCase));}...}...}
可以看出PluginRegistry 中和加载扫描插件相关的方法
loadFromMainClassLoader,从classpath下的Log4j2Plugin.dat加载插件 (核心plugin和自定义plugin通常都从这里加载)
loadFromBundle,从osgi的Log4j2Plugin.dat加载插件
loadFromPackage,加载指定 package(包)中的插件
但这只是答案的一半,另一半问题是Log4j2Plugins.dat是怎么生成的,在实际开发自定义plugin时,我们并没有手工创建这个文件。从官方文档的一句描述我们找到了线索
Serialized plugin listing files are generated by an annotation processor contained in the log4j-core artifact which will automatically scan your code for Log4j 2 plugins and output a metadata file in your processed classes.
http://logging.apache.org/log4j/2.x/manual/plugins.html
简单总结就是log4j-core帮我们自动创建了Log4j2Plugins.dat这个文件,创建者是一个叫annotation processor的东西。
我们继续挖掘下去,annotation processor首先出现在Java 5中,是一种在编译阶段根据注解来生成附加源文件的技术。生成的文件可以是java类、资源文件、元数据文件等所有类型,但有一个限制就是只能新增文件,不能修改已经存在的。这个技术被用在lombok,QueryDSL 和 JPA等技术中,详细介绍可以参考 https://www.baeldung.com/java-annotation-processing-builder 。
log4j2的用法是在编译阶段扫描我们代码包里有@Plugin注解的类,自动帮我们生成Log4j2Plugins.dat,生成路径就在我们打包的resources中,第三方应用引入我们包依赖,PluginRegistry 就能从classpath里加载到。话不多说了,直接上源码看看log4j2是怎么实现annotation processor的
// 实现annotation processor必须继承jdk基类AbstractProcessor,并且只有org.apache.logging.log4j.core.config.plugins.*的注解才会处理("org.apache.logging.log4j.core.config.plugins.*")public class PluginProcessor extends AbstractProcessor {...public boolean process(final Set<? extends TypeElement> annotations, final RoundEnvironment roundEnv) {Messager messager = processingEnv.getMessager();messager.printMessage(Kind.NOTE, "Processing Log4j annotations");try {// 获取所有@Plugin的类final Set<? extends Element> elements = roundEnv.getElementsAnnotatedWith(Plugin.class);if (elements.isEmpty()) {messager.printMessage(Kind.NOTE, "No elements to process");return false;}collectPlugins(elements);// 将收集到的plugin写到当前打包target下的Log4j2Plugins.datwriteCacheFile(elements.toArray(new Element[elements.size()]));messager.printMessage(Kind.NOTE, "Annotations processed");return true;} catch (final IOException e) {...}}...}
至此,log4j2插件系统的背后原理已经浮出水面,通过巧妙使用annotation processor技术,log4j2优雅的实现了一套对开发非常友好的插件系统。开发者只需要实现一个Plugin类,即可在log4j2配置文件里直接使用,真正做到了使用者开发最小化。
好了,原理篇就介绍这么多,下面让我们来看看具体的实战案例。
实战案例:日志脱敏
背景:金融行业的业务场景需要保护客户隐私信息,在日志中不能记录客户的身份证、手机号、银行卡等信息明文。
日志脱敏整体设计:
通过正则表达式识别日志参数里的敏感信息
正则会导致日志性能明显降低,因此使用异步日志策略
交易量如果达到异步日志的处理瓶颈,会导致异步队列里消息堆积,甚至有oom风险;这里采取的策略是当异步队列堆积到一定程度,降级为同步日志,当异步队列堆积情况缓解,再自动恢复为异步日志
正则表达式会有一定比例误判,支持配置白名单
具体实现和代码:
定义LogMaskRewritePolicy插件,实现正则表达式识别敏感信息并重写日志内容,支持配置脱敏白名单
定义AsyncFallback的appender插件,实现异步日志降级为同步日志脱敏,支持配置异步队列长度的降级阈值
LogMaskRewritePolicy.java
@Plugin(name = "LogMaskPolicy", category = "Core", elementType = "rewritePolicy", printObject = true)public final class LogMaskRewritePolicy implements RewritePolicy {private Logger logger = LoggerFactory.getLogger(this.getClass());/*** 掩码开关*/boolean enableMask = true;/*** 只掩码参数,设置为false则掩码整个日志(NOTE: 掩码整个日志会明显增加误掩码的概率)*/boolean onlyMaskParams = true;/*** 日志掩码上下文,可以设置白名单等信息*/MaskingUtil.MaskContext maskContext = new MaskingUtil.MaskContext();/*** 跳过脱敏的日志关键字*/private Set<String> skipLogKeywords = new HashSet<>();...@Overridepublic LogEvent rewrite(final LogEvent event) {Message msg = event.getMessage();String format = msg.getFormat();if (StringUtils.isNotBlank(format) ) {try {String maskedMessage = msg.getFormattedMessage();// 关键字跳过掩码for (String skipKeywords : skipLogKeywords) {if (maskedMessage.contains(skipKeywords)) {return event;}}if (onlyMaskParams) {// 只掩码参数if (ArrayUtils.isNotEmpty(msg.getParameters())) {Object[] params = msg.getParameters();// 针对参数掩码for (int i = 0; i < params.length; i++) {Object param = params[i];if (param instanceof String) {param = MaskingUtil.maskStrSenseInfo((String) param, maskContext);}params[i] = param;}maskedMessage = ParameterizedMessage.format(format, params);}} else {// 针对整个日志掩码maskedMessage = MaskingUtil.maskStrSenseInfo("{" + maskedMessage);maskedMessage = maskedMessage.substring(1, maskedMessage.length());}SimpleMessage simpleMessage = new SimpleMessage(maskedMessage);Log4jLogEvent.Builder builder = new Log4jLogEvent.Builder();StringMap contextData = ContextDataFactory.createContextData();if (event.getMarker() != null) {contextData.putValue("_marker", event.getMarker().getName());}contextData.putAll(event.getContextData());builder.setContextData(contextData);... 省略builder构造过程return builder.build();} catch (Throwable e) {logger.warn("日志脱敏失败", e);return event;}}return event;}...}
AsyncFallback.java
(name = "AsyncFallback", category = Core.CATEGORY_NAME, elementType = Appender.ELEMENT_TYPE, printObject = true)public class AsyncFallbackAppender extends AbstractAppender {boolean isFallback = false;Configuration configuration;/*** 异步appender和同步appender*/AppenderRef[] appenderRefs;boolean printError = true;/*** 异步队列降级为同步的阈值*/int limitQueueSize = 10000;protected AsyncFallbackAppender(String name, Filter filter, Layout<? extends Serializable> layout, boolean ignoreExceptions, Property[] properties) {super(name, filter, layout, ignoreExceptions, properties);}public void append(LogEvent event) {final Map<String, Appender> map = configuration.getAppenders();AsyncAppender asyncAppender = null;Appender rewriteAppender = null;for (final AppenderRef appenderRef : appenderRefs) {Appender refAppender = map.get(appenderRef.getRef());if (refAppender == null) {if (printError) {LOGGER.error("No appender named {} was configured", appenderRef);}} else {if (refAppender instanceof AsyncAppender) {asyncAppender = (AsyncAppender)refAppender;} else if (refAppender instanceof RewriteAppender) {rewriteAppender = refAppender;}}}int queueSize = asyncAppender.getQueueSize();if (asyncAppender != null && queueSize <= limitQueueSize) {// 异步日志isFallback = false;asyncAppender.append(event);} else if (rewriteAppender != null) {// 降级为同步日志,第一次降级打印日志if (isFallback == false) {if (printError) {LOGGER.error("降级为同步日志,异步队列长度为[{}]超过上限[{}]", queueSize, limitQueueSize);}isFallback = true;rewriteAppender.append(event);} else {rewriteAppender.append(event);}} else {if (printError) {LOGGER.error("No appender named {} was configured");}}}...}
接入方法也很简单,只需要在log4j2配置里直接使用
<Appenders><Rewrite name="Rewrite">// 定义脱敏策略<LogMaskPolicy whiteListPatterns="8000.*#450303.*"/><AppenderRef ref="app" /></Rewrite><Async name="Async">// 将Rewrite配置为异步日志<AppenderRef ref="Rewrite"/><LinkedTransferQueue/></Async><AsyncFallback name="AsyncFallback" limitQueueSize="1000">// 构建最终使用的appender, 同时支持异步和同步的脱敏<AppenderRef ref="Async"/><AppenderRef ref="Rewrite"/></AsyncFallback></Appenders><Loggers><Root level="info"><AppenderRef ref="AsyncFallback" /></Root></Loggers>
写个案例实验一下,
logger.info("test[{}][{}][{}][{}][{}][{}]", "45030319900214101X", "张三", "13823232999","minganziduan@qq.com", "中国广东省深圳市南山区科技生态园7栋11楼");
[INFO][2021-04-30 14:06:10.277][][] test[4****************X][张*][138******99][m***********@qq.com][中国广东省深圳市************楼][{}]
脱敏结果基本符合预期,当然如果要在生产环境使用,还需要进行性能压测等工作,项目中的单机压测经验是当异步日志低于12000tps时基本不影响交易耗时,高于则会降级为同步日志。
好啦,以上就是关于log4j2插件系统的个人实践总结,希望对我们日常框架的设计有所启发。欢迎大家留言聊聊对于插件模式的理解,以及你哪些优秀的插件系统实现。
以上是关于log4j2解密:初探插件模式及其应用的主要内容,如果未能解决你的问题,请参考以下文章