Hive基础知识 02
Posted Xiao Miao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive基础知识 02相关的知识,希望对你有一定的参考价值。
文章目录
Hive基础知识
一、Hive表结构
创建表的格式:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(
col1Name col1Type [COMMENT col_comment],
co21Name col2Type [COMMENT col_comment],
co31Name col3Type [COMMENT col_comment],
co41Name col4Type [COMMENT col_comment],
co51Name col5Type [COMMENT col_comment],
……
coN1Name colNType [COMMENT col_comment]
)
[PARTITIONED BY (col_name data_type ...)] --分区表结构
[CLUSTERED BY (col_name...) [SORTED BY (col_name ...)] INTO N BUCKETS] --分桶表结构
[ROW FORMAT row_format] -- 指定数据文件的分隔符
row format delimited fields terminated by '列的分隔符' -- 列的分隔符,默认为\\001
lines terminated by '行的分隔符' --行的分隔符,默认\\n
[STORED AS file_format] -- 指定文件的存储格式
[LOCATION hdfs_path] -- 用于指定表的目录所在位置,默认表的目录在数据库的目录下面
1.普通表结构
MapReduce处理的规则:
step1:检索元数据,找到表对应的HDFS目录
step2:将表的最后一级目录作为MapReduce程序的输入
结构:
Hive数据仓库目录/数据库目录/表的目录/数据文件
特点:
表的最后一级的目录是表的目录
问题:如果是一张普通表的结构,手动将文件通过HDFS命令放入表的目录下,在表中能否读到?
可以,由于表的最后一级目录是普通目录,所以在表中可以读取到
应用:
默认创建的表都是普通表结构的
一般用于将原始的数据文件构建成表的结构
2.分区表结构
普通表结构的问题?
Map阶段要做大量无意义的过滤操作,导致浪费大量资源
2.1分区表结构的设计
设计思想:
将数据按照一定规则条件划分不同的目录进行分区存储
在查询时,可以根据查询条件在目录层次进行过滤,直接由MapReduce加载需要处理的数据的目录
本质:
提前将数据划分到不同的目录中存储
通过查询条件减少底层的MapReduce的输入的数据量,避免无用的过滤,提高性能
结构:
数据仓库目录/数据库目录/表的目录/分区目录/分区数据文件
特点:
表的最后一级目录就是分区目录
应用:
最常用的表:分区外部表
分区的划分:一般都是按照时间划分的
2.2分区表结构的实现:
1.静态分区
数据文件本身就是就是按照分区规划好的,直接创建分区表,加载每个分区的数据即可
step1:直接创建分区表
step2:加载每一个文件到对应的分区中即可
创建分区表:
create table tb_emp_part1(
empno string,
ename string,
job string,
managerno string,
hiredate string,
salary double,
jiangjin double,
deptno string
)
partitioned by (department int)
row format delimited fields terminated by '\\t';
加载对应数据文件到对应的分区
load data local inpath '/export/data/emp10.txt' into table tb_emp_part1 partition (department=10);
load data local inpath '/export/data/emp10.txt' into table tb_emp_part1 partition (department=20);
load data local inpath '/export/data/emp10.txt' into table tb_emp_part1 partition (department=30);
测试SQL的执行计划:explain
普通表:
explain extended select count(*) as numb from tb_emp where deptno = 20;
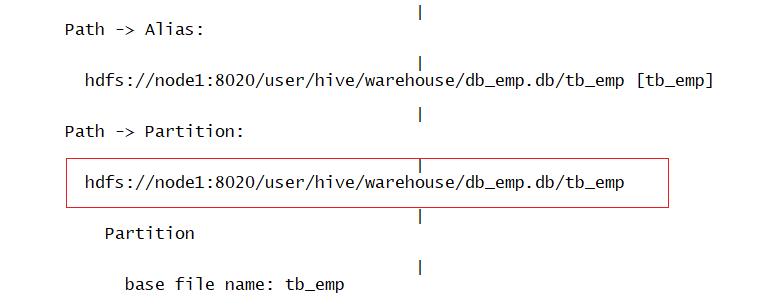
分区表:
explain extended select count(*) as numb from tb_emp_part1 where department = 20;

查看元数据:
PARTITIONS

SDS

2.动态分区
数据本身没有按照分区的规则划分,需要通过程序实现自动动态划分
步骤:
step1:先创建一个普通表,加载整体的数据
tb_emp:普通表,所有部门的员工信息都在一个目录文件中
#1.创建员工表
create database db_emp;
use db_emp;
create table tb_emp(
empno string,
ename string,
job string,
managerid string,
hiredate string,
salary double,
jiangjin double,
deptno string
) row format delimited fields terminated by '\\t';
#2.加载数据
load data local inpath '/export/data/emp.txt' into table tb_emp;
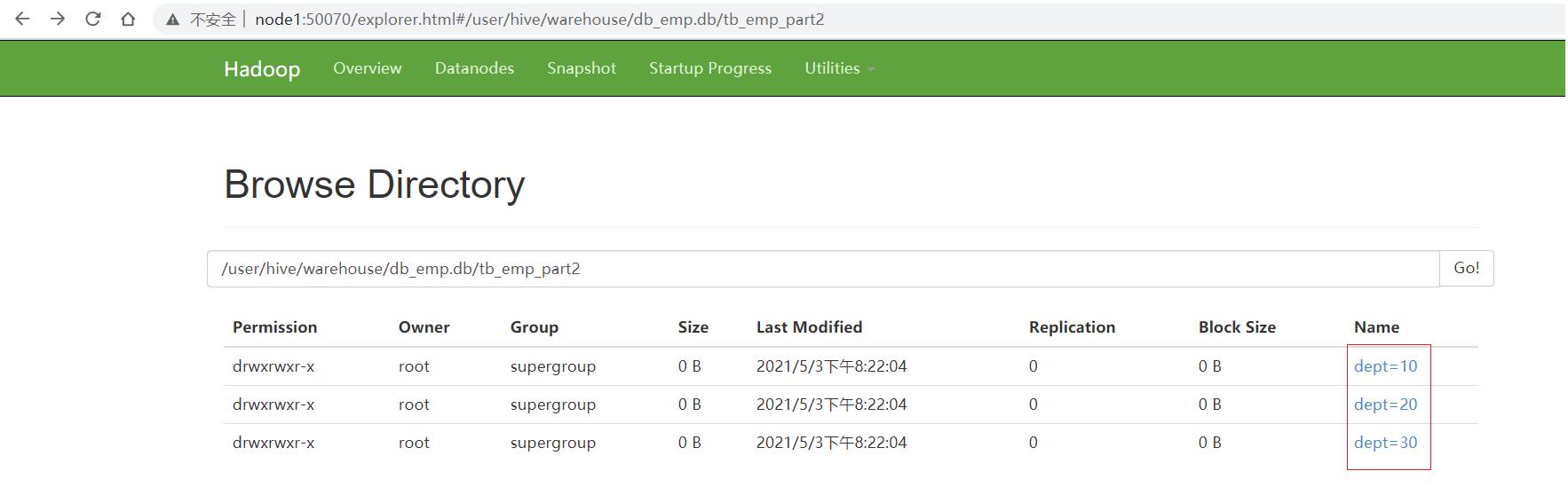
step2:创建分区表
create table tb_emp_part2(
empno string,
ename string,
job string,
managerno string,
hiredate string,
salary double,
jiangjin double
)
partitioned by (dept string)
row format delimited fields terminated by '\\t';
开启动态分区:
set hive.exec.dynamic.partition.mode=nonstrict;
step3:将普通表的数据写入分区表,实现动态分区
insert into table tb_emp_part2 partition(dept)
select ……,deptno from tb_emp ;

要求:查询语句一般不用select *,强制要求查询语句的最后一个字段作为分区字段的
3.多级分区
创建多级分区表
create table tb_ds_source(
id string,
url string,
referer string,
keyword string,
type string,
guid string,
pageId string,
moduleId string,
linkId string,
attachedInfo string,
sessionId string,
trackerU string,
trackerType string,
ip string,
trackerSrc string,
cookie string,
orderCode string,
trackTime string,
endUserId string,
firstLink string,
sessionViewNo string,
productId string,
curMerchantId string,
provinceId string,
cityId string,
fee string,
edmActivity string,
edmEmail string,
edmJobId string,
ieVersion string,
platform string,
internalKeyword string,
resultSum string,
currentPage string,
linkPosition string,
buttonPosition string
)
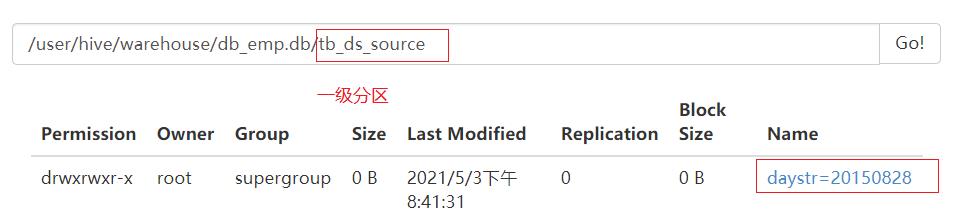
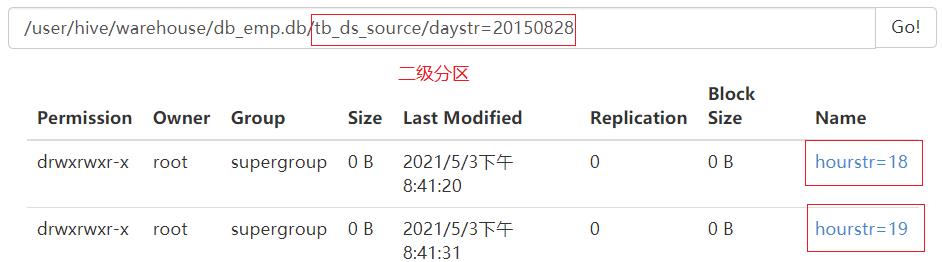
partitioned by (daystr string,hourstr string)
row format delimited fields terminated by '\\t';
加载多级分区数据
load data local inpath '/export/data/2015082818' into table tb_ds_source partition (daystr='20150828',hourstr='18');
load data local inpath '/export/data/2015082819' into table tb_ds_source partition (daystr='20150828',hourstr='19');
查看分区目录:
show partitions tb_ds_source;
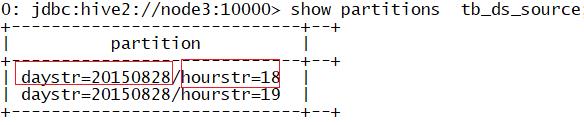
分区是目录级别的,一个目录代表一个分区
目录的名称:分区字段 = 分区的值
分区的字段是逻辑的
3.分桶表结构
1.Join的问题
Map Join:性能比较好,适合于小表join大表
Reduce Join:通过Shuffle的分组来实现的,适合于大表join大表
2.分桶的设计
思想:将大的数据按照规则划分为多份小数据,每份小的数据都走Map Join,减少每条数据的比较次数,提高性能
功能:优化大表join大表的问题,分桶采样
本质:通过MapReduce底层的分区【Reduce的划分规则】将数据划分到多个文件中
每个文件 = 每个桶 = 每个Reduce
划分规则:Hash取余
分桶表字段是物理的
分桶表是文件级别的设计
分桶表的数据不能用load加载
结构:
数据仓库目录/数据库目录/表的目录/分桶的文件数据
将两张大表按照相同的规则进行分桶,实现分桶Join,桶与桶之间直接进行Map Join,减少比较次数,提高性能
流程:
step1:将两张表进行分桶
step2:实现Bucket Join
Hive会自动判断是否满足分桶Join的条件,如果满足就自动实现分桶Join
3.分桶的实现
语法:
clustered by col [sorted by col] into N buckets
clustered by :按照哪一列分桶
sorted by:每个桶的内部按照哪一列进行排序
N:分几个桶,代表底层写入数据就有几个reduce
开启配置
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
创建分桶表
create table tb_emp_bucket(
empno string,
ename string,
job string,
managerno string,
hiredate string,
salary double,
jiangjin double,
deptno string
)
clustered by (deptno) into 3 BUCKETS
row format delimited fields terminated by '\\t';
写入分桶表
insert overwrite table tb_emp_bucket
select * from tb_emp cluster by (deptno);
二、Hive中的Join
1.inner join:内连接
select
a.empno,
a.ename,
b.deptno,
b.dname
from
tb_emp a join tb_dept b on a.deptno = b.deptno;
特点:两边都有结果才有
2.left outer join:左外连接
select
a.empno,
a.ename,
b.deptno,
b.dname
from
tb_emp a left join tb_dept b on a.deptno = b.deptno;
特点:左边有,结果就有
3.right outer join:右外连接
select
a.empno,
a.ename,
b.deptno,
b.dname
from
tb_emp a right join tb_dept b on a.deptno = b.deptno;
特点:右边有,结果就有
4.full join:全连接
select
a.empno,
a.ename,
b.deptno,
b.dname
from
tb_emp a full join tb_dept b on a.deptno = b.deptno;
5.map join
特点:将小表的数据放入分布式缓存,与大表的每个部分进行Join,发生在Map端,不用经过shuffle
场景:小表 join 小表 ,小表 join 大表
要求:必须有一张表是小表
实现规则:
Hive中默认会优先判断是否满足Map Join的条件
判断表的文件大小:小于25MB
如果满足,就自动走Map Join
如果不符合,自动走Reduce Join
6.Reduce Join
特点:利用Shuffle的分组来实现Join过程,发生在Reduce端,需要经过Shuffle
场景:大表join大表
要求:Hive中默认如果不满足Map Join,就自动走Reduce Join
7.Bucket Join
特点:将大的数据划分成多份小的数据,每个小数据就是一个桶,实现分桶join
场景:大表join大表,优化这个过程,如果你的Join多次
要求:
Bucket Map Join:普通的分桶join
两张表都是桶表,桶的个数成倍数,Join字段 = 分桶的字段
Bucket Sort Merge Map Join:基于排序的分桶Join
两张表都是桶表
桶的个数成倍数
Join字段 = 分桶的字段 = 排序的字段
三、Select语法:order by与sort by
1.Hive中ReduceTask个数
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):\\
#每个Reduce处理的数据量大小
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
#最多允许启动的reduce的个数
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
#设置reduce的个数
set mapreduce.job.reduces=<number>
#指定reduce个数为2
set mapreduce.job.reduces=2;
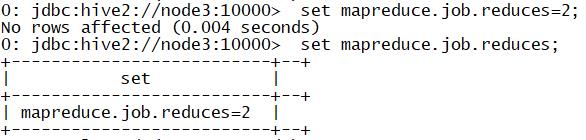
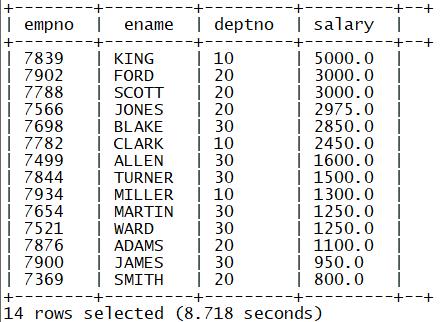
2.order by
功能:全局排序
select empno,ename,deptno,salary from tb_emp order by salary desc;
问题:如果Reduce有多个,能否实现全局排序?
不能有多个Reduce,使用了order by,只会启动一个reduce
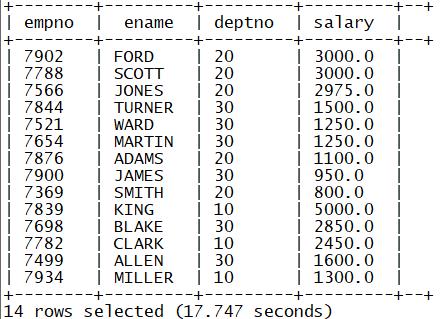
3.sort by
功能:局部排序
多个reduce场景下,每个reduce内部有序
select empno,ename,deptno,salary from tb_emp sort by salary desc;
将sql结果放入文件中
insert overwrite local directory '/export/data/sort' row format delimited fields terminated by '\\t'
select empno,ename,deptno,salary from tb_emp sort by salary desc;

4.order by与sort by的功能与区别是?
order by:全局排序,只能有1个reduce
sort by:局部排序,多个reduce每个reduce局部排序
四、Select语法:distribute by 与 cluster by
1.distribute by
功能:由于干预底层的MapReduce,指定某个字段作为k2
#指定reduce个数为3
set mapreduce.job.reduces=3;
insert overwrite local directory '/export/data/distby' row format delimited fields terminated by '\\t'
select empno,ename,deptno,salary from tb_emp distribute by deptno;
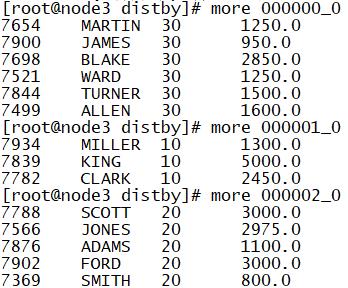
2.distribute by和sort by一块使用
insert overwrite local directory '/export/data/distby' row format delimited fields terminated by '\\t'
select empno,ename,deptno,salary from tb_emp distribute by deptno sort by salary desc;
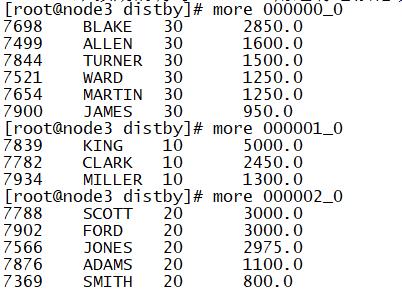
应用:
distribute by 1 => 用于将所有数据进入一个Reduce中
distribute by rand() => 实现随机分区,避免数据倾斜
3.cluster by
功能:如果distribute by与sort by是同一个字段,可以使用cluster by代替
五、数据类型:Array
1.生成数据
#1.创建一个array.txt
vim /export/data/array.txt
#2.添加数据
zhangsan beijing,shanghai,tianjin
wangwu shanghai,chengdu,wuhan,haerbin
2.创建表
#1.创建db_complex数据库
create database db_complex;
use db_complex;
#2.创建complex_array表
create table if not exists complex_array(
name string,
work_locations array<string>
)
row format delimited fields terminated by '\\t'
COLLECTION ITEMS TERMINATED BY ',';
COLLECTION ITEMS TERMINATED BY ‘,’ ; 用于指定数组中每个元素的分隔符
3.加载数据
load data local inpath '/export/data/array.txt' into table complex_array;
4.取出需要的数据
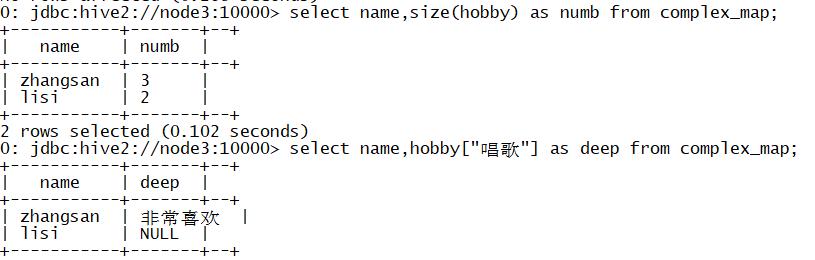
#1.统计每个用户工作过的城市个数
select name,size(work_locations) as numb from complex_array;
#2.取出数组中单独的元素
select name,work_locations[0],work_locations[1] from complex_array;

六、数据类型:Map
1.生成数据
#1.创建一个amp.txt
vim /export/data/map.txt
#2.添加数据
1,zhangsan,唱歌:非常喜欢-跳舞:喜欢-游泳:一般般
2,lisi,打游戏:非常喜欢-篮球:不喜欢
2.创建表
create table if not exists complex_map(
id int,
name string,
hobby map<string,string>
)
row format delimited fields terminated by ','
COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':';
COLLECTION ITEMS TERMINATED BY ‘-’
用于划分每个KV对
MAP KEYS TERMINATED BY ‘:’;
用户划分K和V的
3.加载数据
load data local inpath '/export/data/map.txt' into table complex_map;
4.取出需要的数据
#1.统计每个人有几个兴趣爱好
select name,size(hobby) as numb from complex_map;
#2.取出每个人对唱歌的喜好程度
select name,hobby["唱歌"] as deep from complex_map;
七、正则加载
Hive不支持多字节分隔符
1.分隔符的问题
数据中的列的分隔符||
数据中每列的分隔符不一致
数据字段中包含了分隔符
2.处理方案
方案一:先做ETL,需要先开发一个程序来实现数据的处理,将处理的结果再加载到Hive表中
通过程序替换分隔符
方案二:Hive官方提供了正则加载的方式
通过正则表达式来匹配每一条数据中的每一列
3.正则加载
生成数据
#1.创建一个regex.txt
vim /export/data/regex.txt
#2.添加数据
2019-08-28 00:03:00 tom
2019-08-28 10:00:00 frank
2019-08-28 11:00:00 jack
2019-08-29 00:13:23 tom
2019-08-29 10:00:00 frank
2019-08-30 10:00:00 tom
2019-08-30 12:00:00 jack
创建表
正常创建
#1.创建表regex1
create table regex1(
timestr string,
name string
) row format delimited fields terminated by ' ';
#2.加载数据
load data local inpath '/export/data/regex.txt' into table regex1;
正则加载
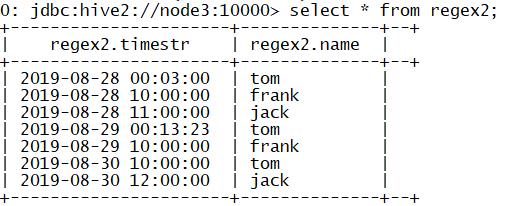
#1.创建表regex2
create table regex2(
timestr string,
name string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^}]*) ([^ ]*)"
)
STORED AS TEXTFILE;
#2.加载数据
load data local inpath '/export/data/regex.txt' into table regex2;
八、Hive中的函数:内置函数
#1.查看函数
show functions;
#2.查看函数的用法
desc function [extended] funName;
#3.常用函数
#3.1聚合函数
count、sum、avg、max、min
#3.2条件函数
if、case when
#3.3字符串函数
截取:substring,substr
拼接:concat、concat_ws
分割:split
查找:instr
替换:regex_replace
长度:length
#3.4日期函数
转换:unix_timestamp、from_unixtime
日期:current_date,date_sub,date_add
获取:year、month、day、hour
#4.特殊函数
JSON:json_tuple,get_json_object
URL:parse_url,parse_url_tuple
窗口函数:
聚合窗口:sum、count……
位置窗口:lag、lead、first_value,last_value
分析函数:row_number、rank、dense_rank
九、Hive中的函数:自定义函数
1.函数分类
UDF:一对一函数,类似于substr
UDAF:多对一函数,类似于聚合函数:count
UDTF:一对多函数,explode将一行中的每个元素变成一行
2.自定义UDF函数
需求:24/Dec/2019:15:55:01 -> 2019-12-24 15:55:01
step1:自定义一个类,继承UDF类
step2:在类中至少实现一个evaluate方法定义处理数据的逻辑
step3:打成jar包,添加到hive的环境变量中
add jar /export/data/udf.jar;
step4:将类注册为函数
create temporary function transFDate as 'com.miao.hive.udf.UserUDF';
step5:调用函数
select transFDate("24/Dec/2019:15:55:01");
3.自定义UDAF与UDTF
UDAF
step1:将类注册为函数
create temporary function userMax as 'com.miao.hive.udaf.UserUDAF';
step2:调用函数
select userMax(cast(deptno as int)) from db_emp.tb_dept;
cast:强制类型转换函数
cast(列 as 类型)
UDTF
step1:将类注册为函数
create temporary function transMap as 'com.miao.hive.udtf.UserUDTF';
step2:调用函数
select transMap("uuid=root&url=www.taobao.com") as (userCol1,userCol2);
十、Hive中的函数:parse_url_tuple
#1.创建lateral.txt文件
vim /export/data/lateral.txt
#2.添加数据
1 http://facebook.com/path/p1.php?query=1
2 http://www.baidu.com/news/index.jsp?uuid=frank
3 http://www.jd.com/index?source=baidu
#3.创建表
create table tb_url(
id int,
url string
) row format delimited fields terminated by '\\t';
#4.加载数据
load data local inpath '/export/data/lateral.txt' into table tb_url;
1.parse_url:用于解析URL,每次只能解析一个元素
2.parse_url_tuple:用于解析URL,是一个UDTF函数,一次解析多个元素
3.语法:
select parse_url(url,'HOST') from tb_url;
select parse_url(url,'PATH') from tb_url;
select parse_url(url,'QUERY') from tb_url;
select parse_url_tuple(url,'HOST','PATH','QUERY') from tb_url;
十一、Hive中的函数:lateral view
1.UDTF函数的问题
udtf只能直接select中使用,不可以添加其他字段使用,不可以嵌套调用,不可以和group by/cluster by/distribute by/sort by一起使用
2.lateral view
搭配UDTF函数使用,将UDTF函数的结果变成类似于视图的表,方便与原表进行操作
语法:
select …… from tabelA lateral view UDTF(xxx) 别名 as col1,col2,col3……
十二、Hive中的函数:explode
1.explode功能
将集合类型中集合的每个元素变成一行
语法:
explode( Map | Array)
2.用法
单独使用
select explode(work_locations) as loc from complex_array;
select explode(hobby) from complex_map;
侧视图连用
select
a.id,
a.name,
b.*
from complex_map a lateral view explode(hobby) b as hobby,deep;
以上是关于Hive基础知识 02的主要内容,如果未能解决你的问题,请参考以下文章