区块链学习笔记之以太坊
Posted Geek_bao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了区块链学习笔记之以太坊相关的知识,希望对你有一定的参考价值。
区块链学习笔记
二、以太坊
5. 以太坊(ETH)的共识机制——GHOST协议
5.1 引言
(1)以太坊把出块时间降到了十几秒,这有利于提高系统的througput以及降低了系统反应时间。和比特币的10分钟出块时间相比,以太坊的出快速度相当于提高了40倍。但是这样大幅度降低出块时间后,也带来了一些新的问题。
(2)前面我们介绍到,比特币和以太坊都是运行在应用层的共识协议,它底层是一个peer to peer 的over network。over network本身传输协议是比较长的,因为它的拓扑协议做flooding时候没有考虑实际的拓扑结构。
(3)这就带来一个问题,你发布一个区块后,区块在网络上传到其他节点,可能需要十几秒的时间。对于比特币来说,10分钟的出块时间相当于600秒,那么这个足够让新发布的区块传播到网络上的其他节点。
(4)但是即使这样,因为挖矿是一个概率的过程,所以仍然有可能是由两个矿工同时获得记账权,同时发布区块。前面介绍过这个情况,这会带来临时性的分叉。那么对于以太坊来说,这种临时性的分叉就会变成了常态,而且分岔的数目也会更多。因为十几秒的出块时间,很有可能别的节点其实还没来得及收到你发布的区块,还在沿着原来的区块链往下挖,等到他收到你发布的区块时候,可能他自己已经挖出来一个新的区块。那么这对共识协议来说有什么样的挑战呢?
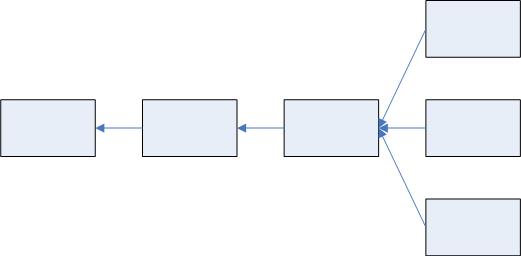
(5)比特币的情况是这样的:只有在最长合法链上的那些区块里面所包含的出块奖励才是真正有用的。其他的一些分叉的链上的出块奖励,其实最后是作废的。下面我们画一个例子如下:
-
上图中的区块链,在第三个块出现了分叉,分了三个叉,这三个差不多是同一时间取得了记账权,那么最后有一个会胜出,成为最长合法链。如果中间这个胜出了,那么像上面和下面这个区块我们称为orphan block或者 stale block。而挖到这个区块的矿工,在这个区块里面有一个铸币交易coinbase transaction,能够获得一定数量的比特币,但实际上最后是没用的,因为他不在最长合法链上,所以这里得到的出块奖励等于是作废了。对于比特币来说,因为出现这种临时性的分叉的情况不是很多,所以这么规定还是可以接受的。但是对于以太坊来说,如果也这样处理的话,那么这就意味着矿工挖到的区块有很大概率是白挖了。
-
你辛辛苦苦挖出一个区块,因为系统中有很多分叉,所以很有可能你挖出的这个区块,他最后没有成为最长合法链,这样你就白忙活了。这样对挖到矿的矿工来说,不是很公平,尤其是对于这种个体矿工,这种情况更为严重。我们前面介绍过,挖矿呈现出两个趋势,一个是挖矿设备的专业化,现在已经很少有人用我们的普通桌面机挖矿,服务器都很少,一般都是用的专门的设备,像ASIC芯片,或者对于以太坊来说用GPU挖矿。第二个趋势就是大型矿池的出现,个体矿工算力有限,有很多是组成了大型矿池,资本的运作下,有很多算力实际上是集中在大型矿池。不光是前面我们了解的比特币是这样,下面我们说的以太坊也如此,叫做mining pool。
-
这对个体矿工尤其是不公平的,正常情况下,我们希望的是,你矿池能够得到的收益应该和你的算力比例是一致的。比如,你矿池的算力占整个系统算力的30%。假设你是一个大矿池,那么你得到的挖矿收益也应该是整个系统的30%,这样才算公平。
(6)但是如果我们的共识协议设计不好的话,有可能大矿池得到了收益超过它的算力的比例。比如说,我们刚出现分叉的时候,假设上下两个区块是个体矿工挖出来的,中间区块是某个大型矿池挖出来的,那么下面怎么变化呢。大矿池肯定是沿着它自己的分叉往下面挖,因为他的算力很强,所以它挖出下一个区块的概率是比较大的,而上下这两个分叉,他们个体矿工的,他们主要寄希望于别的矿工会沿着他们这两个分叉往下挖,因为他自己的算力是微不足道的。他就是一个个体矿工,光靠他自己沿着这条链往下挖是比不过别人的。但是对于别的矿工,他其实没有什么理由倾向于这两个个体矿工的分叉去挖。换句话说你个体矿工,如果是作为一个整体的话,出现分叉后它的算力是分散的。这样就会造成一个结果。假设这个矿池挖到区块的概率是30%,但是他挖到区块后,成为最长合法链的概率很高。这样就会造成mining centralization(挖矿的集中化)。
(7)实际情况可能比这个更加糟糕,一般来说,大型矿池在这个区块链网络中占得位置是比较好的,有的可能是在网络中多个地方都有接口,所以大型矿池发布出去的区块,有可能更早的被其他节点所接收。所以说,就算这三个区块是同时被挖出来,那么中间的大型矿石发布的区块可能是别的节点最先收到的区块。而且从过去的历史经验来看,大型矿池所在的分叉更有可能成为最长合法链,这个也就促使别的矿工会沿着它的分叉去继续挖,因为你沿着其他分叉去挖的话,很有可能就白挖了。这就使得大型矿池出现了一个恶性循环,越是大型矿池得到的收益也就越大,mining centralization也就更加严重。有时候我们称作它centralization bias,即中心化带来的不成比例的优势。
(8)如果我们什么都不改,以太坊沿用比特币共识机制就会出现问题。为了解决这些问题,以太坊中采用了基于Ghost协议的共识机制。Ghost协议并不是以太坊发明的,就在以太坊以前就已经有了Ghost协议了。以太坊对这个协议做一些修改。这个协议的核心思想就是,你挖到了矿,发布了一个区块,最后这个区块作废了,你就很难受,我们给你一些出块奖励作为安慰。比如我们上图中的情况,上面那条链没有成为最长合法链,变成了orphan block或stale block,以太坊给他去了一个名字叫做uncle block,就是这个区块相对于最长合法链上的当前区块来说,它是它的叔父区块,它和它的父亲是一个辈分。这就得到了Ghost协议的最初版本如下。
5.2 GHOST协议最初版本
(1)如图,假定以太坊系统存在以下情况,A、B、C、D在四个分支上,最后,随着时间推移B所在链成为最长合法链,因此A、C、D区块都作废,但为了补偿这些区块所属矿工所作的工作,给这些区块一些“补偿”,并称其为"Uncle Block"(叔父区块)。
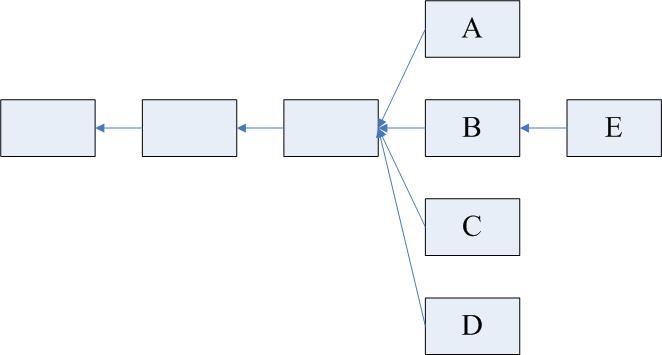
(2)规定E区块在发布时可以将A、C、D叔父区块包含进来,A、C、D叔父区块可以得到出块奖励的7/8,而为了激励E包含叔父区块,规定E每包含一个叔父区块可以额外得到1/32的出块奖励。为了防止E大量包含叔父区块,规定一个区块只能最多包含两个叔父区块,因此E在A、C、D中最多只能包含两个区块作为自己的出块奖励。
(3)假定一个矿工挖出了B,此时他沿着其所在链继续挖,而他知道A是和自己“同辈”,则可以将A包含进区块挖矿,若挖矿过程中又听到C也是“同辈”,则可以停止挖矿,将C包含进来重新组织成一个新区块重新挖矿,实际中,由于挖矿过程的无记忆性,这样并不会降低成功挖到矿的概率。
(4)最初版本缺陷:
- 1.因为叔父区块最多只能包含两个,如图出现3个怎么办?
- 2.矿工自私,故意不包含叔父区块,导致叔父区块7/8出块奖励没了,而自己仅仅损失1/32。如果甲、乙两个大型矿池存在竞争关系,那么他们可以采用故意不包含对方的叔父区块,因为这样对自己损失小而对对方损失大。
5.3 Ghost协议新的版本
(1)下图为对上面例子的补充,F为E后面一个新的区块。因为规定E最多只能包含两个叔父区块,所以假定E包含了C和D。此时,F也可以将A认为自己的的叔父区块(实际上并非叔父辈的,而是爷爷辈的)。如果继续往下挖,F后的新区块仍然可以包含B同辈的区块(假定E、F未包含完)。这样,就有效地解决了上面提到的最初Ghost协议版本存在的缺陷。但这样仍然存在一定的问题。
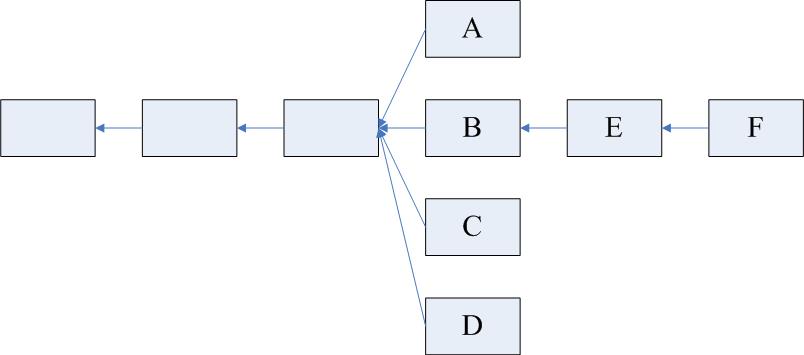
(2)我们将“叔父”这个概念进行扩展,但问题在于,“叔父”这一定义隔多少代才好呢?
如下图所示,M为该区块链上一个区块,F为其严格意义上的叔父,E为其严格意义上的“爷爷辈”。以太坊中规定,如果M包含F辈区块,则F获得7/8出块奖励;如果M包含E辈区块,则F获得6/8出块奖励,以此类推向前。直到包含A辈区块,A获得2/8出块奖励,再往前的“叔父区块”,对于M来说就不再认可其为M的"叔父"了。对于M来说,无论包含哪个辈分的“叔父”,得到的出块奖励都是1/32出块奖励。也就是说,叔父区块的定义是和当前区块在七代之内有共同祖先才可(合法的叔父只有6辈)。

(3)这样,就方便了全节点进行记录,此外,也从协议上鼓励一旦出现分叉马上进行合并。对于区块链当前状态产生了临时性的意见分歧,我们想办法把它合并。如果是别的原因,像我们前面说的比特币脚本时候,CHECKMULTISIG(这个操作是检查多重签名的合法性),这个操作的实现上有一个bug,它检查的时候会从堆栈里面多弹出一个元素,所以实际上如果你正常操作的话是检查不通过的,你得先往里面压一个多余的元素,就为了应付这个bug。为什么不能把这个bug改掉呢,这是因为你改完后版本不一样了,会出现硬分叉(这里不同于中心化的系统)。两条链如果不是因为对当前状态有意见分歧而是互相认为对方是非法的(认为对方的区块包含非法交易),那么用这种方法是合并不了的。
(4)以太坊中的奖励,如下
- BTC:静态奖励(出块奖励)+动态奖励(交易费,占据比例很小)
- ETH:静态奖励(出块奖励+包含叔父区块的奖励)+动态奖励(汽油费,占据比例很小,叔父区块没有)
- BTC中为了人为制造稀缺性,比特币每隔一段时间出块奖励会降低,最终当出块奖励趋于0后会主要依赖于交易费运作。而以太坊中并没有人为规定每隔一段时间降低出块奖励。
(5)以太坊中包含了叔父区块,要不要包含叔父区块中的交易?
答:不应该,叔父区块和同辈的主链上区块有可能包含有冲突的交易。而且我们前文也提到,叔父区块是没有动态奖励的。因此,一个节点在收到一个叔父区块的时候,只检查区块合法性(是否合法发布,是否符合挖矿难度)而不检查其中交易的合法性。假设我的一个交易被叔父区块包含了,也就是说我的交易并没有得到执行。这个问题中,矿工不吃亏,拿到了交易费,但是我的交易没有执行。主链节点收到你的交易后还会继续执行的,可能你要再等一个区块,但是还是会执行的,最终flooding到所有节点。
(6)它是怎么检测它前面链上有多少个叔父区块?
每个已发布的区块,你得说明你的父区块是哪个区块,所以可以检查你的父区块和当前区块是不是有共同祖先。
(7)那么对于分叉后的堂哥区块怎么办?
例如下图所示,A->F该链并非一个最长合法链,所以B->F这些区块怎么办?该给挖矿补偿吗?
如果规定将下面整条链作为一个整体,给予出块奖励,这一定程度上鼓励了分叉攻击(降低了分叉攻击的成本,因为即使攻击失败也有奖励获得)。因此,ETH系统中规定,只认可A区块为叔父区块,给予其补偿,而其后的区块全部作废。

(8)我们设计这个协议的主要目的是为了解决系统中出现的临时性分叉,包括我们说的比特币也好,以太坊也好,为什么规定最长合法链,为了防止篡改,使得交易不容易被篡改,其实也是为了解决临时性分叉。最长合法链提供了一个出现临时性分叉后进行运行合并的一种机制。
(9)我们一起看看以太坊的一些真实数据
- 如果想看最新数据,可以在https://cn.etherscan.com/网站进行查看。
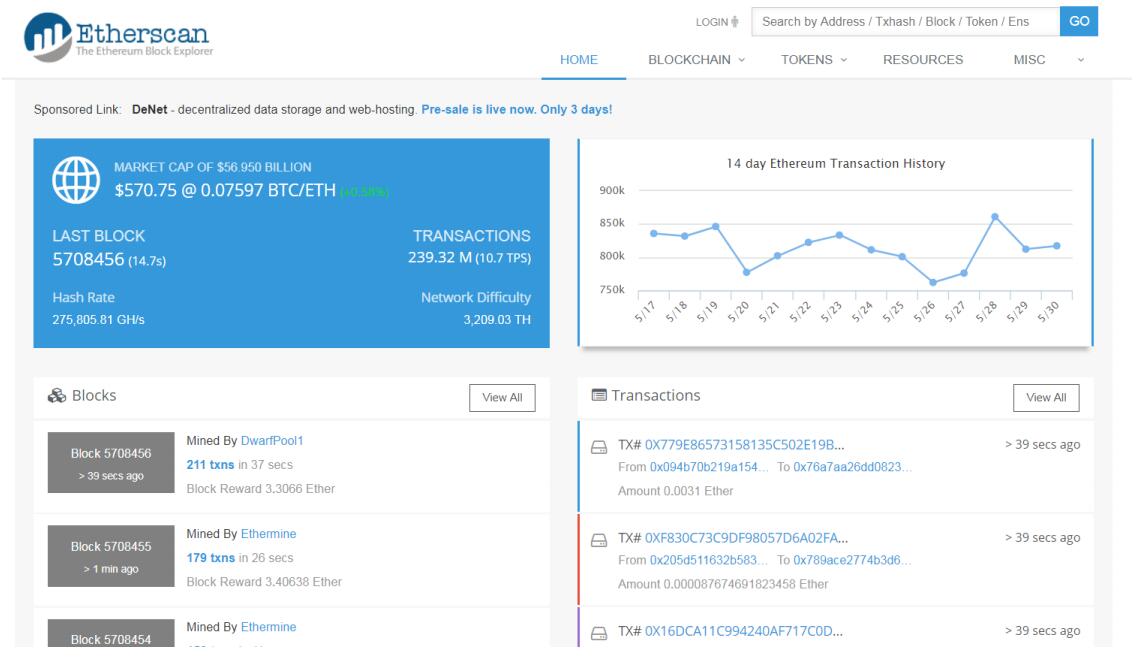
- 右边曲线显示的是过去两个星期的交易历史,左下方显示的是最新被挖出的区块,右下方显示的是最新的交易
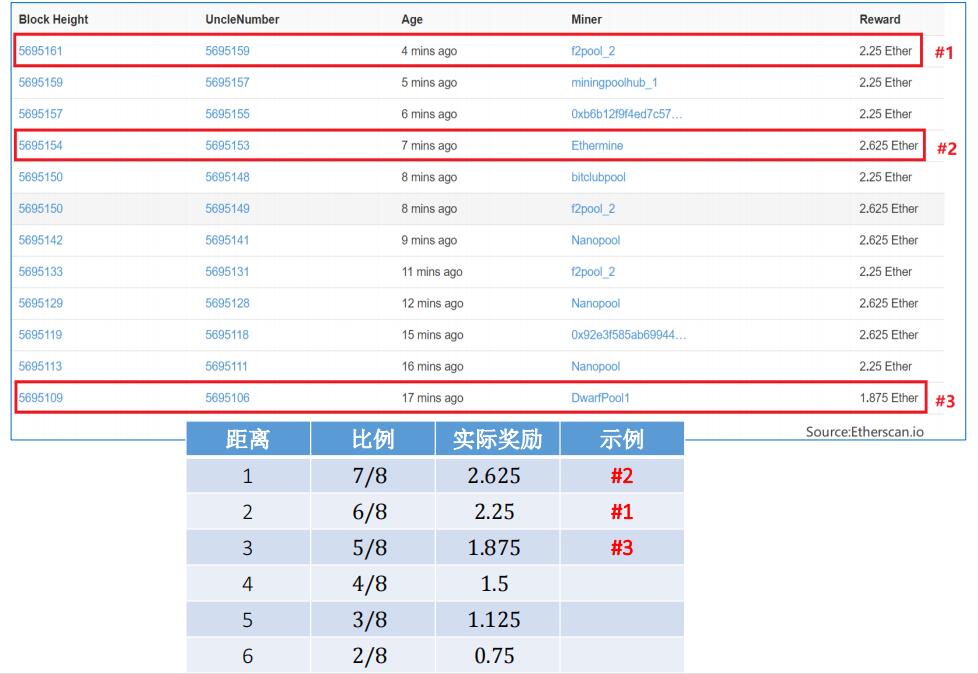
-
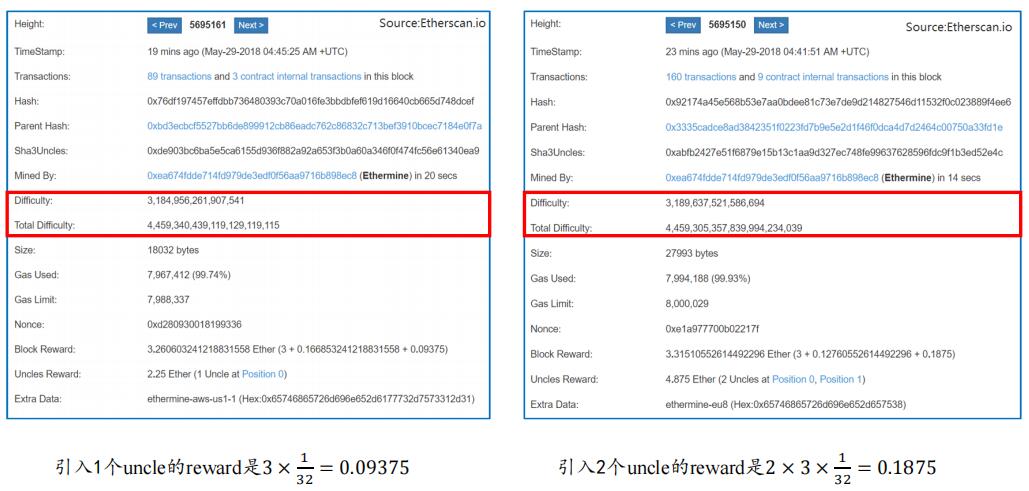
上图显示的是叔父区块的几种情况,这里每一行对应一个叔父区块,第一列的block height就是区块的序号也就是block number像第一行(第一个红框)的叔父区块的序号比这个区块本身要小两个,这个说明是一个距离为2的叔父区块,应该得到6/8的奖励也就是6/8 * 3 = 2.25个以太币。接下来·两行都属于这种情况的叔父区块。再往下面一行(第二个红框),叔父区块的序号只比它小一个,说明是当代叔父,应该得到7/8的奖励也就是7/8 * 3 =2.625个以太币,后面的可以此类推。说明系统中大多数分叉都很快得到了合并,最下面这一行的叔父区块的序号比这个区块小三个,那么应给得到5/8的奖励。下面表格给出的不同辈分的叔父得到的uncle reward的数。
-
我们再看看下面两个区块的例子,左边这个区块包含了一个叔父区块,我们可以看到倒数第二行的uncle reward 是2.25,可以判断这是一个距离为2的叔父。这个区块得到的奖励,就是他本身得到的reward(倒数第三行这部分内容),是由三块内容组成,出块奖励+汽油费+包含叔父区块得到的奖励。
-
我们再看一下右边的区块,包含了两个叔父区块,一个距离为1的当代叔父另一个是距离为2的上一代叔父。所以这里它倒数第二的uncle reward为2.25+2.625=4.875,这个区块的reward也是三部分内容。大家可以通过第一行的height来查一下,比如左边这个区块,它的height就是5695161,第一个红框对应点这一行。右边区块类似。

6. 以太坊(ETH)挖矿算法
6.1 挖矿概论
(1)对于基于工作量证明的区块链系统来说,挖矿是保障区块链安全的一个重要手段。所以有一句话叫做,block is secured by mining。比特币中用的挖矿算法,总体来说是比较成功的。经受了时间的检验,到目前为止没有人发现里面有什么大的漏洞。
(2)bug bounty(公司悬赏找软件漏洞,找到了就可以得到一笔赏金),比特币的挖矿算法是一个天然的bug bounty。如果你能找到里面的漏洞,或者是某一个挖矿的捷径,就能取得很大的利益。但是到目前为止,还没有人发现有什么捷径可以走,所以说比特币的挖矿算法总的来说是比较成功的,是经受了时间考验的。但是比特币的挖矿算法也有一些值得改进的的地方。其中一个饱受争议的问题就是挖矿设备的专业化,用普通计算机挖不到矿,只能用专门的设备,专门的ASIC芯片来挖矿很多人认为这种做法与去中心化的理念背道而驰。中本聪最早的比特币论文中提到了一个说法叫做,one CPU one vote。理想情况下,应该让普通人也能够参与挖矿的过程,就用自家的桌面机,笔记本电脑甚至手机来挖矿,这样也更安全。因为算力分散后,有恶意攻击者想要聚集到51%的算力发动攻击,难度也会大得多。
(3)所以比特币之后出现的很多加密货币,包括以太坊设计mining puzzle,一个目标就是要做到ASIC resistance。那么怎么才能够设计出一个队ASIC芯片不友好的mining puzzle呢?一个常用的做法就是增加这个puzzle对内存访问的需求,也就是所谓的memory hard mining puzzle。这是因为,ASIC芯片相对于普通计算机来说,它的主要优势就是算力强,但是在内存访问的性能上并没有那么大优势。ASIC矿机的计算能力可能是普通计算机的几千倍,因为它里面有很多核,能进行大量的并行计算,但是在内存访问上,性能差距并没有那么大。所以说,如果我们能设计出一个对内存要求很高的puzzle,那么就能够起到遏制ASIC芯片的作用。那么该如何设计呢?
6.2 莱特币挖矿算法
(1)在这方面一个早期的例子,LiteCoin(莱特币)。莱特币曾一度成为市值仅次于比特币的第二大货币。莱特币的puzzle基于Scrypt。Scrypt为一个对内存性能要求较高的哈希函数,之前多用于计算机安全密码学领域。
(2)莱特币挖矿算法基本思想:
-
1.设置一个很大的数组,按照顺序填充一些伪随机数。因为哈希函数的输出我们并不能提前预料,所以看上去就像是一大堆随机的数据,因此称其为“伪随机数”。实际上,我们不可能真的用随机数,真的用随机数的话,没办法验证。

Seed为种子节点,通过Seed进行一些运算获得一个数,放在数组第一个位置,之后每个数字都是通过前一个位置的值取哈希得到的。可以看到,这样的数组中取值存在前后依赖关系。 -
2.在需要求解Puzzle的时候,按照伪随机顺序,从数组中读取一些数,每次读取位置与前一个数相关。例如:第一次,从A位置读取其中数据,然后对A中的数值进行一些运算,获得下一次读取位置B;第二次,从B位置读取其中数据,根据B中数据计算获得下一次读取位置C;
(3)分析:
如果数组足够大,对于挖矿矿工来说,必须保存该数组以便查询。如果你没有这个数组的话,你还得从第一个数,依次算出A这个数的值。然后要读取第二个位置的数,你没有保存,那么得再算一遍,算到B这个位置的值,然后后面的C也一样。这对于矿工来说,计算复杂度大幅度上升。所以要想高效的挖矿,内存区域是需要保存的。当然,矿工可以选择只保存一部分数据,例如:只保存奇数位置数据,偶数位置需要时再根据前一个奇数位置数据计算即可,从而对内存空间大小减少了一半(计算复杂度提高一点,但内存减少一半),也称作time memory trade off。
- 核心思想:不能仅仅进行运算,增加其对内存的访问,从而实现对ASIC芯片不友好。
(4)这个设计有问题吗?
- 看似蛮不错的,使得ASIC矿机挖矿变得不友好,但该方法对Puzzle验证并不是很友好。想要验证该Puzzle,也需要存储该数组,因此对于轻节点来说,并不友好(系统中绝大多数节点为轻节点)。我们前面介绍比特币的时候提到过设计puzzle的一个原则:要求求解puzzle很难,验证很容易。但是采用这种设计后,验证puzzle需要的内存区域和求解puzzle需要的区域几乎一样大。你轻节点验证的时候,也得保存这个数据,不然它的计算复杂度也会大幅度提高。
(5)因此,莱特币真正应用来说,数组大小不敢设置太大。例如:对于计算机而言,1G毫无压力,而对于手机APP来说,1G占据空间就过大了。所以,实际中,莱特币系统设计的数组大小仅仅128K大小。起初莱特币发行时,不仅希望能够抗拒ASIC,还希望能抗拒GPU。但实际中,后来慢慢出现了GPU挖矿,再后来,ASIC芯片挖矿也出现了。实际应用中,莱特币的设计并未起到预期作用,也就是说,128k对于ASIC Resistance来说过小了。
(6)莱特币的这一设计是好事还是坏事?
- 从其并未起到预期作用来看,当然是一件坏事,但换个角度来思考,早期通过宣传这一设计目标,宣传这种更民主,让更多人参与的理念,有效吸引了大批矿工参与,解决了莱特币“能启动”问题,因此目前莱特币仍然是一个较为主流的加密货币。此外,莱特币和比特币另一区别为出块时间,莱特币为2.5min,为比特币的1/4。除了这些不同外,这两种货币基本一样。
(7)能启动问题:任何一个加密货币都存在能启动问题,包括比特币一开始的时候,没有人知道这个加密货币。这就有一个问题,对于基于工作量证明的加密货币来说,挖矿人太少,是不安全的,因为发动恶意攻击难度太低了。
6.3 以太坊挖矿算法
(1)让我们看看以太坊的设计,以太坊的理念与莱特币相同,都是Memory Hard Mining Puzzle,但具体设计上与莱特币不同。
(2)以太坊挖矿算法基本思想:
以太坊中,设计了两个数据集,一大一小。小的为16MB的cache,大的数据集为1G的dataset(DAG)。其关系为,1G的数据集是通过16MB数据集生成而来的。
(3)思考为何要设计一大一小两个数据集?
为了便于进行验证,轻节点保存16MB的Cache进行验证即可,而矿工为了挖矿更快,减少重复计算则需要存储1GB大小的大数据集。
(4)16MB的小Cache数据生成方式与莱特币中数组的生成方式较为类似,大致如下:
-
1.通过Seed进行一些运算获得第一个数,之后每个数字都是通过前一个位置的值取哈希获得的。这样把整个数组从前往后填充这些伪随机数就得到了一个cache。
-
2.区别如下:
莱特币:直接从数组中按照伪随机顺序读取一些数据进行运算。
以太坊:先生成一个更大的数组,这个大数组比小数组要大得多。(注:以太坊中这两个数组大小并不固定,因为考虑到计算机内存容量不断增大,因此该两个数组需要定期增大) -
3.大的DAG生成方式:
大的数组中每个元素都是从小数组中按照伪随机顺序读取一些元素,方法同莱特币中相同。如第一次读取A位置数据,对当前哈希值更新迭代算出下一次读取位置B,再进行哈希值更新迭代计算出C位置元素。如此来回迭代读取256次,最终算出一个数作为DAG中第一个元素,如此类推,DAG中每个元素生成方式都依次类推。
(5)分析:
轻节点只保存小的cache,验证时进行计算即可。但对于挖矿来说,如果这样则大部分算力都花费在了通过Cache计算DAG上面,因此,其必须保存大的数组DAG以便于更快挖矿。
(6)以太坊挖矿过程(求解puzzle过程):
根据区块block header和其中的Nonce值计算一个初始哈希,根据这个哈希映射到大数据集某个,例如位置A,读取A位置的数及其相邻的后一个位置A’上的数,根据该两个数进行运算,算得下一个位置B,读取B和B’位置上的数,依次类推,迭代读取64次,共读取128个数。最后,计算出一个哈希值与挖矿难度目标阈值比较,是否符合难度要求。若不符合就重新更换Nonce,重复以上操作直到最终计算哈希值符合难度要求或当前区块已经被挖出。
(7)从伪代码理解以太坊挖矿算法

- 看看这个函数mkcache(),这个函数是通过seed计算出来cache的伪代码。伪代码略去了原来代码中对cache元素进一步的处理,只展示原理,即cache中元素按序生成,每个元素产生时与上一个元素相关。每隔30000个块会重新生成一个seed(对原来的seed求哈希值),并且利用新的seed生成新的cache。同时cache的初始大小为16M,每隔30000个块重新生成时增大初始大小的1/128 ——128K。
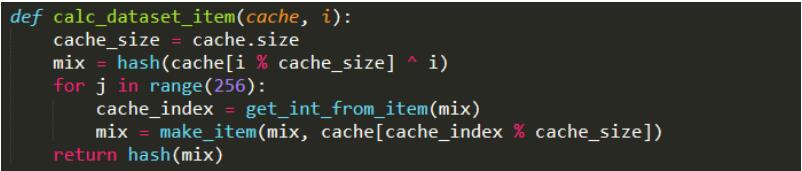
- 再看看这个函数calc_dataset_item(),这是通过cache来生成dataset中第i个元素的伪代码。这个dataset叫作DAG,初始大小是1G,也是每隔30000个块更新,同时增大初始大小的1/128——8M。伪代码省略了大部分细节,展示原理。先通过cache中的第i%cache_size个元素生成初始的mix,因为两个不同的dataset元素可能对应同一个cache中的元素,为了保证每个初始的mix都不同,注意到i也参与了哈希计算。随后循环256次,每次通过get_int_from_item来根据当前的mix值求得下一个要访问的cache元素的下标,用这个cache元素和mix通 过make_item求得新的mix值。注意到由于初始的mix值都不同,所以访问cache的序列也都是不同的。最终返回mix的哈希值,得到第i个dataset中的元素。多次调用这个函数,就可以得到完整dataset。

- calc_dataset()这个函数通过不断调用前边介绍的calc_dataset_item函数来依次生成dataset中全部full_size个元素。
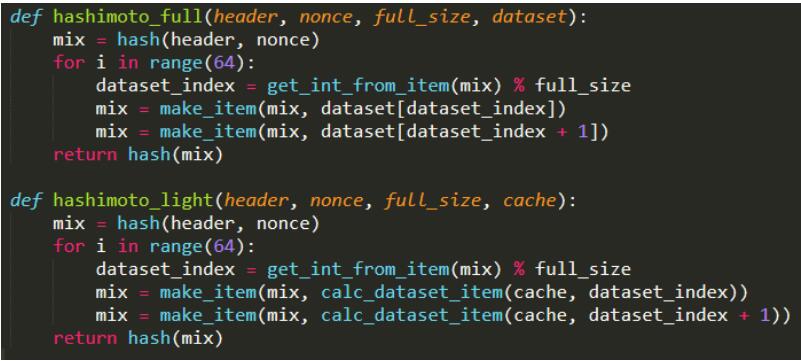
-
上面这两个函数分别是矿工用来挖矿的函数和轻节点用来验证的函数。我们来看一下第一个函数,第一个参数header是当前要生成的区块的块头,以太坊和比特币一样,挖矿只用到块头信息。第二个参数nonce是当前尝试的nonce值。第三个参数full_size,这是大数据集中元素的个数,这个元素的个数每3万个区块会增加一次,增加原大小的1/128。
-
挖矿过程如下:先通过header和当前nonce求出一个初始的哈希值,然后要经过64轮的循环,每一轮循环读取大数据集中两个相邻的数,读取的位置是由当前哈希值计算出来的,再根据这个位置上的数值来更新当前的哈希值,这个前面生成大数据集的方法是类似的。循环64次最后返回一个哈希值,用于和挖矿难度的目标阈值相比较。
-
思考题:这两个值相关吗?
答:是没有关系的,这两个值虽然位置上相邻,但是生成过程是独立的,都是由前面的16M的cache生成。 -
上图第二个函数是轻节点用来验证的函数,也是四个参数,但是含义和上面矿工用的函数有所不同。轻节点是不挖矿的,当它收到某个矿工发布的一个区块时,这里用来验证的这个函数的第一个参数header是这个区块的块头,第二个参数nonce是包含在块头里面的nonce,是发布区块的矿工选好的。轻节点的任务是验证nonce是否符合要求,验证用的是16M的cache,也就是最后一个参数cache。第三个参数full_size,和上面挖矿用到的函数里面的full_size含义相同,它并不是cache中元素个数,验证过程也是64轮循环,看上去和挖矿过程类似。
-
那么这两个函数有什么区别呢?
每次需要从大数据集中读取元素的时候,因为轻节点没有保存大数据集,所以要从cache中重新生成,其他地方的代码逻辑是一样的。大数据集中这个位置的元素,前面提到过,每个位置的元素都可以独立生成出来。

- 上图这个函数是矿工挖矿的主循环,其实就是不断尝试各个nonce的过程。这里的target,挖矿难度目标和比特币类似,也是可以动态调整的。nonce的取值可能是0到2的64次幂。对每个nonce用前面说的那个函数算出哈希值,看看是不是小于难度目标,如果不行的话那就再试试下一个,直到得到的值小于target。
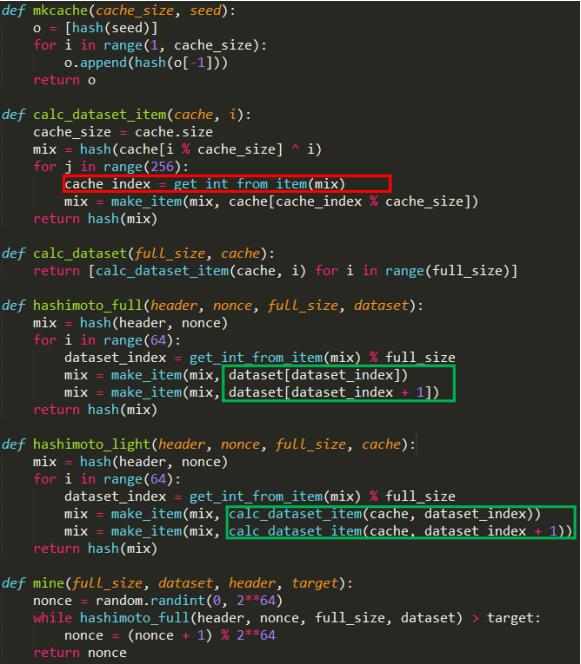
- 这里是整个流程的伪代码,同时分析矿工需要保存整个dataset的原因。红色框标出的代码表明通过cache生成dataset的元素时,下一个用到的cache中的元素的位置是通过当前用到的cache的元素的值计算得到的,这样具体的访问顺序事先不可预知,满足伪随机性。由于矿工需要验证非常多的nonce,如果每次都要从16M的cache中重新生成的话,那挖矿的效率就太低了,而且这里面有大量的重复计算:随机选取的dataset的元素中有很多是重复的,可能是之前尝试别的nonce时用过的。所以,矿工采取以空间换时间的策略,把整个dataset保存下来。轻节点由于只验证一个nonce,验证的时候就直接生成要用到的dataset中的元素就行了。
(8)目前以太坊挖矿以GPU为主,用ASIC矿机的很少,从这点来看它比莱特币要成功,起到了ASIC resistance的作用。这与以太坊设计的挖矿算法(Ethash)所需要的大内存具有很大关系。
- 矿工挖矿需要1G内存,1G的大数组与128k相比,差距8000多倍,即使是16MB与128K相比,也大了一百多倍,可见对内存需求的差距很大(况且两个数组大小是会不断增长的)。
- 当然,以太坊实现ASIC Resistance除了挖矿算法设计之外,还存在另外一个原因,即其很早就计划从工作量证明(POW)转向权益证明(POS)
(9)初识权益证明(POS: Proof of Stake),这个下文有一节专门讲这个,
- 权益证明:按照所占权益投票进行形成共识,类似于股份制公司按照股份多少投票,权益证明不需要挖矿。而这对于ASIC矿机厂商来说,是一个很大的威胁。因为ASIC芯片研发周期很长,成本很高,如果以太坊转入权益证明,这些投入的研发费用将全部白费(ASIC矿机只能用于挖特定的加密货币)
- 但实际上,以太坊目前仍然是POW挖矿共识机制。以太坊很早就说要从POW转向POS,但是转移的时间点一推再推,到现在也没转成。并为了防止有矿工不愿意转埋下了一颗“难度炸弹”。但截至目前,以太坊仍然基于POW共识机制。
- 其实很多时候,面对一些问题转换思路就能得到很好的解决方案。如这里,如果按照原本思想,通过不断改进挖矿算法来达成ASIC Resistance,无疑是比较难的。而这里通过不停宣传要转向POS来不断吓阻矿工,使得矿工不敢擅自转入ASIC挖矿,从而实现了ASIC Resistance。ASIC芯片设计周期至少一年,今年吓唬完了,第二年没转成POS那就接着再吓唬一年,宣称明年我肯定要转POS的。
(10)预挖矿(Pre-Mining)
- 以太坊中采用的预挖矿的机制。这里“预挖矿”并不挖矿,而是在开发以太坊时,给开发者预留了一部分货币。以太坊的早期开发者,目前就很有钱了。
- 而比特币并未采用这一模式,所有比特币都是通过挖矿产生的。但早期挖矿难度容易,所以中本聪本人本来就有很多币(但没花,不花给我啊!)
- 和Pre-Mining对应,还有Pre-Sale,Pre-Sale指的是将预留的货币出售来换取一些资产用于加密货币开发,类似于拉风投或众筹。目前,各类加密货币很多,存在一部分货币就在采用Pre-Sale来获取资金,如果此时买入,后续如果该货币取得成功,同样可以获得很大收益,但真正成功的货币只占少数,这就是其风险性。
(11)下面我们一起看看以太坊的一些统计数据
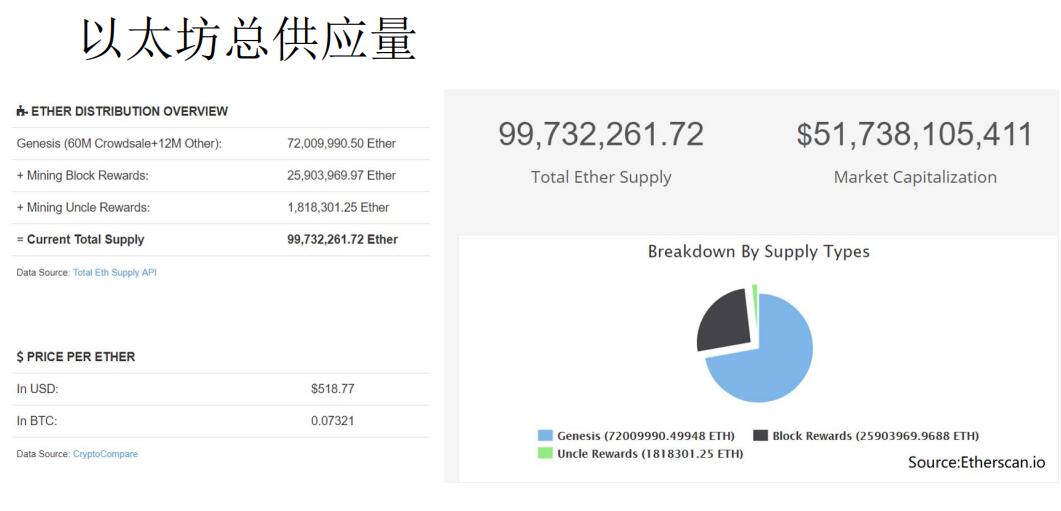
- 上图中,显示了以太坊中以太币供应量的分布情况(2018年)。总共大约一亿个以太币,每个以太币的市场价格是500多美元(最新数据自行去官网查看)。以太坊市值约500多亿美元,就问你香不香。饼状图中,蓝色部分都是Pre-Mining产生的(接近3/4),可见掌握技术有多么重要。黑色部分为出块奖励产生的以太币,绿色为叔父区块产生的奖励以太币。
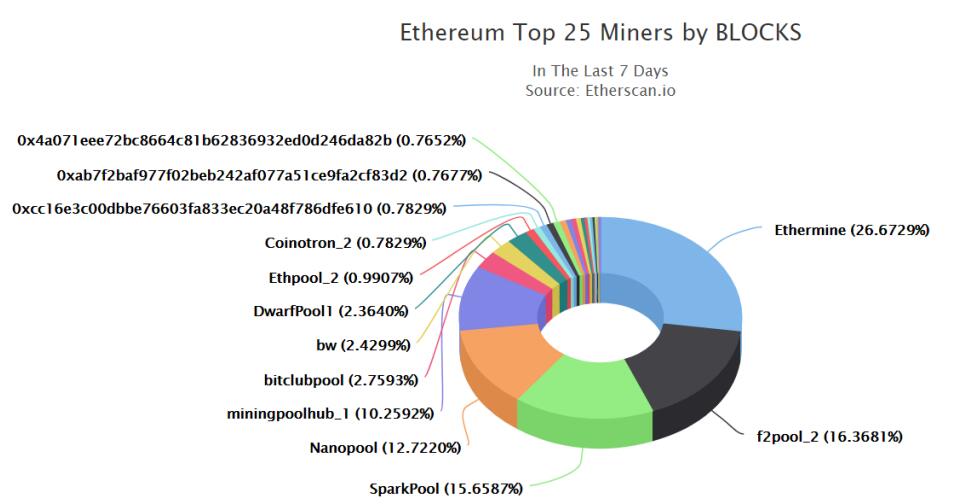
- 上图显示的是最大的25个以太坊矿池所占得算力比重(2018年)。可以看出挖矿的集中化程度也是很高的,尤其是最大的几个矿池,所占比例很高,与比特币情况类似。
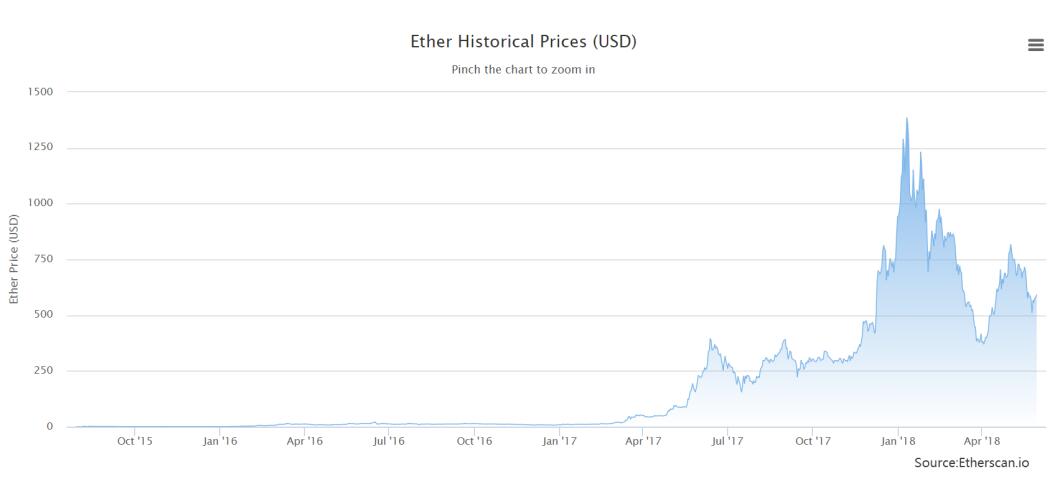
- 上图显示的是以太币价格随时间变化情况(至2018年)。我们可以看到在以太坊早期那几年价格基本没怎么涨。直到2017年以太坊才开始大涨,是否感觉错过1个亿?
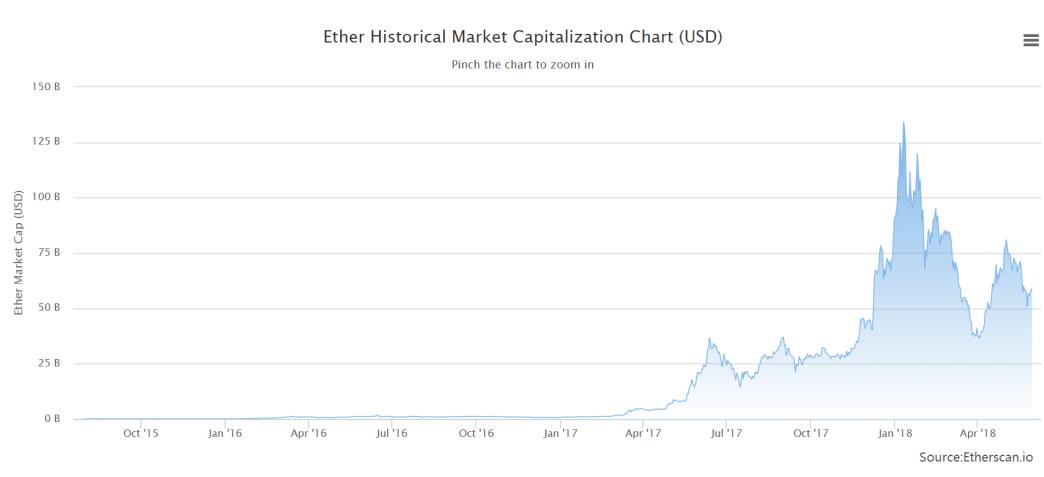
- 上图显示的是以太坊的市值(market capitallization),和前面一个图显示的以太币价格走势基本符合。
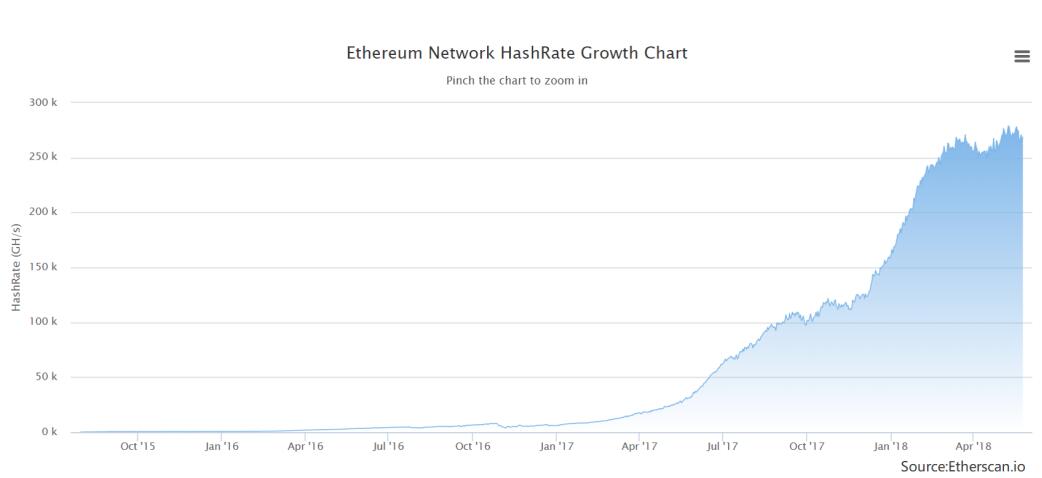
- 这个图显示的是以太坊的Hash Rate变化情况(至2018年)。Hash Rate是指系统中所有矿工加在一起,每秒钟计算哈希的次数,可以看到总体上处于上升趋势,而且也是从17年开始大幅度上升的。需要注意的是,不同的加密货币,如果用的mining puzzle不一样的话,那么它的Hash Rate是不可比的。比如以太坊和比特币的Hash Rate就不能直接比较,因为以太坊找中尝试一个nonce的工作量要比比特币大得多。
(12)其他观点:
- 本节中挖矿算法设计一直趋向于让大众参与,这一才是公平的。且由于参与人员的分散,算力分散,也进一步使得系统更安全。
- 但同样一件事物,从不同观点看就有不同的看法。也有人认为让普通计算机参与挖矿是不安全的,像比特币那样,让专业化设备参与挖矿才是安全的。为什么呢?
- 因为要攻击系统,需要购入大量只能进行特定货币挖矿的矿机通过算力进行强行51%攻击,而攻击成功后,必然导致该币种的价值跳水,攻击者投入的硬件成本将会全部打水漂。而如果让通用计算机也参与挖矿,发动攻击成本便大幅度降低,目前的大型互联网公司,将其服务器聚集起来进行攻击即可,而攻击完成后这些服务器仍然可以转而运行日常业务。因此,也有人认为,在挖矿上面,ASIC矿机“一统天下”才是最安全的方式。
7. 以太坊(ETH)难度调整
7.1 难度调整的公式
(1)前面文章中介绍了比特币难度调整是每隔2016个区块调整难度,从而达到维持出块时间10min的目标。而以太坊则与之不同,每个区块都有可能会进行难度调整。
(2)以太坊难度调整较为复杂,修改过好几个版本,网络上关于这方面介绍存在诸多不一致,包括以太坊的黄皮书和实际代码也有一些出入,我们这里遵循以代码为准的原则,从以太坊的代码中来分析以太坊难度调整算法。以太坊中区块难度调整公式如下图所示:
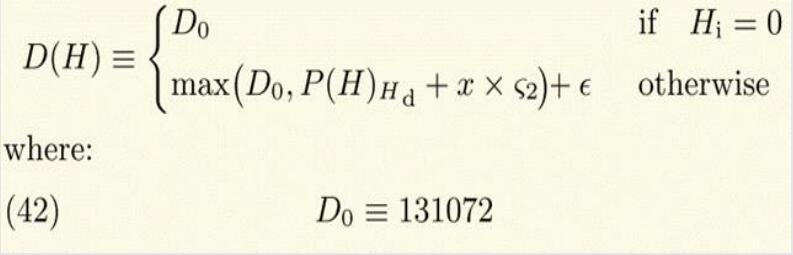
- 这里的H是指当前区块Hi就是这个区块的序号D(H)是这个区块的当前难度。
- 那么这个难度调整公式有两部分,max()是第一部分,有时也叫做基础部分,它的目的是为了维持出块时间,大概是15秒左右,后面跟的ε是第二部分,也称为难度炸弹,它的存在主要是为了向权益证明过度。将来的以太坊想把共识机制从工作量证明逐步转入权益证明。
(3)我们先看看第一部分,第一部分的调整方法是在父区块的难度基础上加上一些自调整的部分,P(H)hd就是父区块的难度。所谓的父区块就是当前区块链的最后一个区块,对于我们正在挖的区块来说,它是这个区块的父区块。第一部分的难度调整有一个下限,就这个D0=131072这部分,不论你怎么去调整,最小不能低于这个难度,这是为了保证挖矿有一个最低的难度。后面这个ε(epsilon)部分就是难度炸弹部分。

(4)继续观察第一部分,如上图,这里的x是调整力度,是父区块的难度除以2048,所以调整难度的时候,不论是上调还是下调,都是按照力度的整数倍进行调整,按照父区块的难度的1/2048作为一个调整单位。x后面那个符号是σ(sigma),它的计算如上图。σ的取值和两个因素有关,一个是出块时间,另一个是有没有叔父区块,就是父区块有没有叔父区块。那么问题来了,为什么要和叔父区块相关呢?
- 因为如果是当前区块链的最后一个区块,它包含有叔父区块的话,那么这个时候系统中的货币总供应量是增加的,因为叔父区块要获得出块奖励,那么包含叔父区块的父区块也要得到一定的奖励,所以这两个合在一起会使货币的总供应量增加。
- 那么为了维持系统的总供应量的稳定,保持一定的平衡,所以当前正在挖的区块的难度就要提高一个单位。后面的-99是说难度调整系数部分有一个下限,就max( ,)前面这部分(就是y减那部分)有可能是正的,也有可能是负的。如果是负的说明难度要下调,那么最多是一次性只能调整99个单位,每个单位就是前面说的父区块难度的1/2048,所以一次性下调难度最多是99/2048。
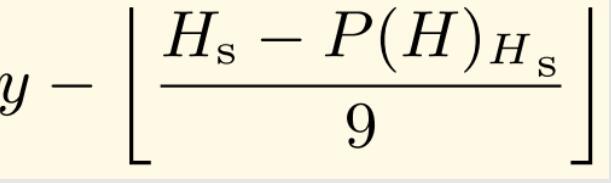
(5)我们仔细看一下上图的公式,这个y就是取决于有没有叔父区块,有叔父区块的话y=2,没有叔父区块的话y=1。不论哪种情况,它都是个常数,所以它实际上就是一个常数减去后面一个项,如果后面这个项比这个常数大的话,减出来是个负数,说明这个难度是要下调的;相反,如果后面一项比前面要小的话,减出来是正数,说明难度要上调。这个Hs是当前区块的时间戳,这个P(H)是父区块的时间戳,那么两项相减就是当前区块的出块间隔,然后出块间隔除以9再向下取整。那么为什么要这么设计?
- 比如我们当前区块的出块时间是在1秒到8秒之间,那么取整符号计算后的结果为0,y-0=1,我们假设没有叔父区块,即y=1,那么整个项的计算结果为1,在这种情况下,难度要上调一个单位,这个合理的。因为我们希望保持的出块时间是稳定在15秒,现在出块时间变成了1-8秒,说明出块速度太快了,我们把难度上调一个单位,维持一下平衡。
- 相反,如果出块时间是9到17秒之间,那么取整符号部分计算后结果为1,前面y=1,那么y-1=0,说明这时出块时间是符合要求的,我们希望的是15秒,它是9-17秒之间,这时可以不用调整,只考虑基础部分,不考虑后面的难度炸弹的话,这个可以不用调。
- 那么第三种情况,如果取整符号里面分子部分减完后是在18-26之间,那么经过取整符号后的计算结果是2,y=1,那么y-2=-1,说明难度要下调一个单位。我们希望的出块时间是稳定在15秒左右,现在已经超过18秒了,所以要下调难度。
- 如果出块时间更长了,超过了26秒,那么下调的幅度也会更大,但是别忘了,我们前面图中公式max()的第二项有一个-99。如果单次出块时间很长,通过y-()计算出了一个负的很大的一个数,但是你一次性下调也不能超过99个单位,这主要是为了防止一些系统中出现的异常情况,像一些黑天鹅事件,正常情况下,它不应该出现这么大幅度的下调。
(6)讲完了基础部分,下面我们介绍一下难度炸弹。
- 难度炸弹设计的初衷是这样的,以太坊的共识机制,要从工作量证明逐步转入权益证明,而权益证明是不挖矿的,那些已经在挖矿设备上,投入了大量资金的矿工会不会联合起来抵制转换。所以以太坊担心到时候大家都不愿意转入权益证明。本来从工作量证明转入权益证明要通过硬分叉来实现。相当于你改了共识协议,如果因为挖矿设备有些人不愿意转过来,造成社区的分裂,那么以太坊有可能分裂成两条平行的链,
- 那么如何避免这种情况的发生呢?
所以以太坊在设计这个难度调整公式的时候,就增加了一个难度炸弹。

(7)我们来看看难度炸弹有什么特点,如上图,当初设计难度炸弹时候没有这个第二行(就是减300万那一行),第一行直接用的Hi(当前区块的序号),没有Hi’这一项。观察一下这个公式有什么特点,很显然一个指数模型。也就是说难度炸弹这部分的取值是呈指数形式增长的。
(8)观察下图,可以看到,在以太坊早期时,区块号较小,难度炸弹计算所得值较小,基本可以忽略不计,难度调整主要还是上通过前面介绍的第一部分(基础部分)来决定,而随着越来越多区块被挖出,区块号变得越来越大,难度炸弹的威力开始显露出来,指数函数增长到后期速度是非常恐怖的。
- 所以当初设计的打算就是,等到难度炸弹的威力开始发挥出来的时候,也正好就是以太坊从工作量证明转入权益证明的时候,以为那时候挖矿变得越来越难,大家也就愿意转入权益证明了。
- 但是实际上基于权益证明的共识机制,实际设计出来有很多问题,远远没有当初想象的那么顺利,这就造成了转入权益证明的时间点一推再推。然后现在挖矿已经变得越来越困难了,难度炸弹的威力开始显现出来了,但是大家还得挖,因为目前没有别的办法可以达成共识(基于权益证明的共识机制还没有开发出来)。
- 这就导致了现在的出块时间越来越长,由原来的稳定在15s变成现在的16s,17s最后到30s左右,如果不采取措施,还会继续增长。以太坊最后在一个EIP当中,决定计算难度炸弹的时候,要把区块号回退300万个区块来计算,也就是公式中的Hi-3000000,算出Hi’。这个可以看作是一个假的区块号,然后算难度炸弹的时候,用假的区块号去算,这就给权益证明的上线争取了一些时间。这样做的结果会怎么样呢,看下图。
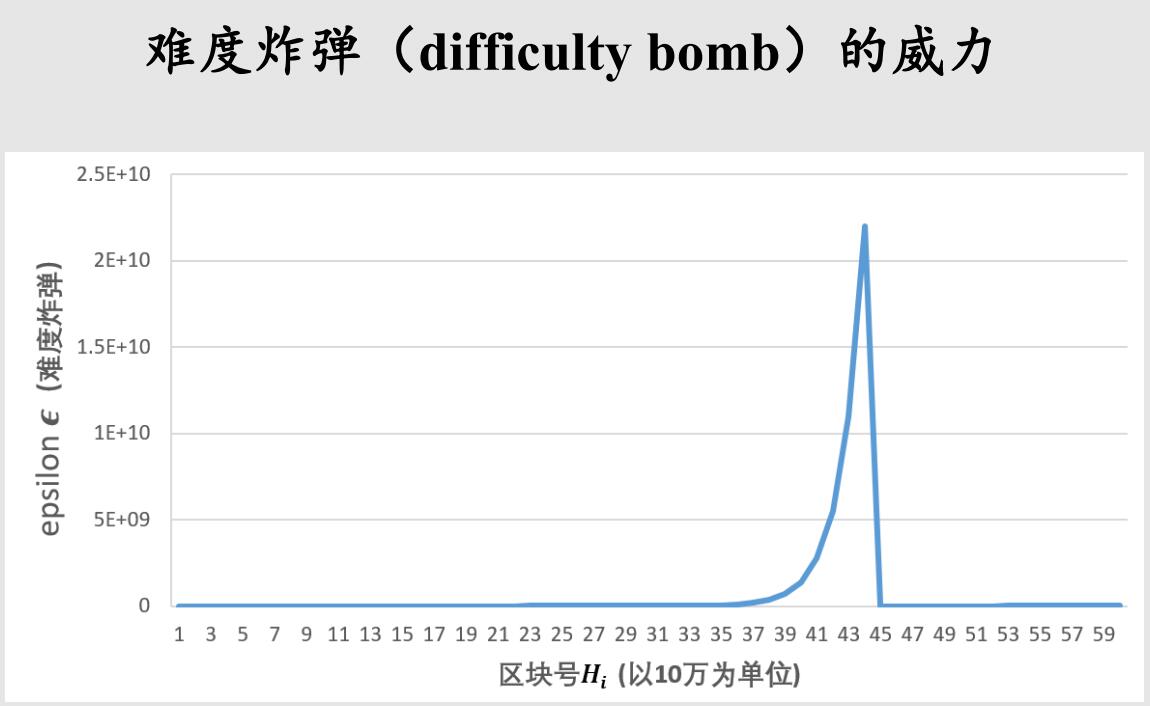
- 这个图显示按照前面那个公式计算的,y轴是难度炸弹(ε的取值),x轴是区块号,以10万为单位。我们可以看到早期的时候,区块号比较小的时候,难度炸弹作用不是很明显,难度调整主要是根据系统的出块时间进行调整。说明一下,这个图的前半部分(最高点前),是按照原来公式计算的(在决定回调300万之前)。大概到了430万个区块左右,到达尖峰位置,然后以太坊决定回调难度炸弹,减了300万个区块,所以难度炸弹取值一下就掉下来了,看上去好像一条平的直线,实际上还在增长。
7.2 难度调整的代码
(1)以太坊发展被分为四个阶段如下图,其中的metropolis又分为两个阶段,我们正处于第一个阶段,叫做拜占庭阶段。难度炸弹的回调就是在拜占庭阶段进行的。EIP叫做Ethereum Improvement Proposal。

(2)在难度回调的同时,把出块奖励从5个以太币降到了3个以太币。那么为什么会做出如此调整呢。因为如果不这么调的话,对于回调之前的矿工是不公平的。因为回调是突然进行的,比如昨天我辛辛苦苦挖矿得到了5个以太币,今天一夜之间难度降低了,另一个人挖矿也得到了5个以太币,这就对我很不公平。而且从这个系统中货币的总供应量来说,也要维护总供应量的稳定。现在挖矿容易了,相应的就把出块奖励减少一些。
(3)注意:比特币中那个每隔一段时间就把出块奖励减半的做法,以太坊中是没有的,像这种把5个以太币的出块奖励降为3个,这是一次性的,并非以后定期都会这么做。
(4)下面我们看一下具体的代码实现。如下图这是拜占庭阶段计算挖矿难度调整的代码,它的输入是父区块的时间戳和父区块的难度,从而计算出当前正在挖的这个区块难度。图中的注释给出了难度计算公式,和前面我们说的是一样的。它也是分成两部分,
- 第一个括号里面的是第一部分(难度调整的基础部分)。
- 后面加上2的次幂那个部分就是难度炸弹。再看下面几行代码,bigTime就是当前区块的时间戳,bigParentTime是父区块的时间戳。
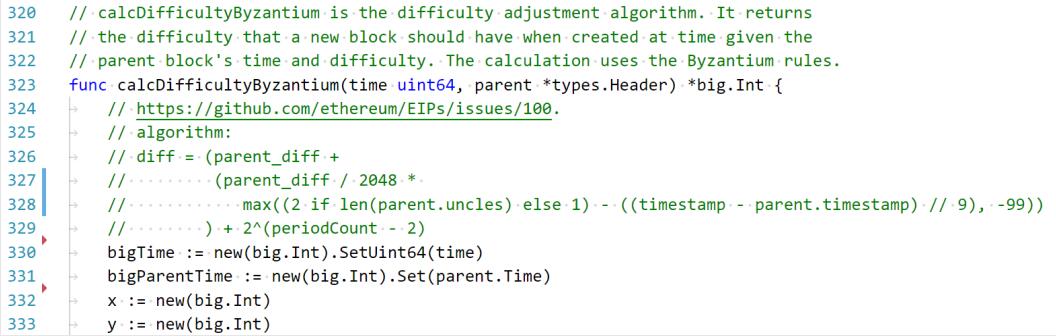
(5)基础部分计算,如下图,这段代码主要是计算基础部分的难度调整。
- 第一行就是把当前时间戳减去父区块的时间戳算出出块时间。
- 然后第二行除以9向下取整。再后面的if else 语句判断一下是不是有叔父区块,有的话就用2减去前面那个数,没有的话就用1来减(前面说过原理,忘了看看前面)。
- 接下来再和-99比较,因为难度调整下调有一个界限,不能比-99小。
- 再接下来计算的是难度调整力度,父区块难度除以这个difficultyBoundDivisor,实际上就是除以2048,然后再和前面算出的系数相乘再加到父区块的难度上去。
- 最后这个if是因为基础部分调整有一个下限,再小也不能小于D0(前面说过)也就是代码中MinimumDifficulty。(D0为131072)
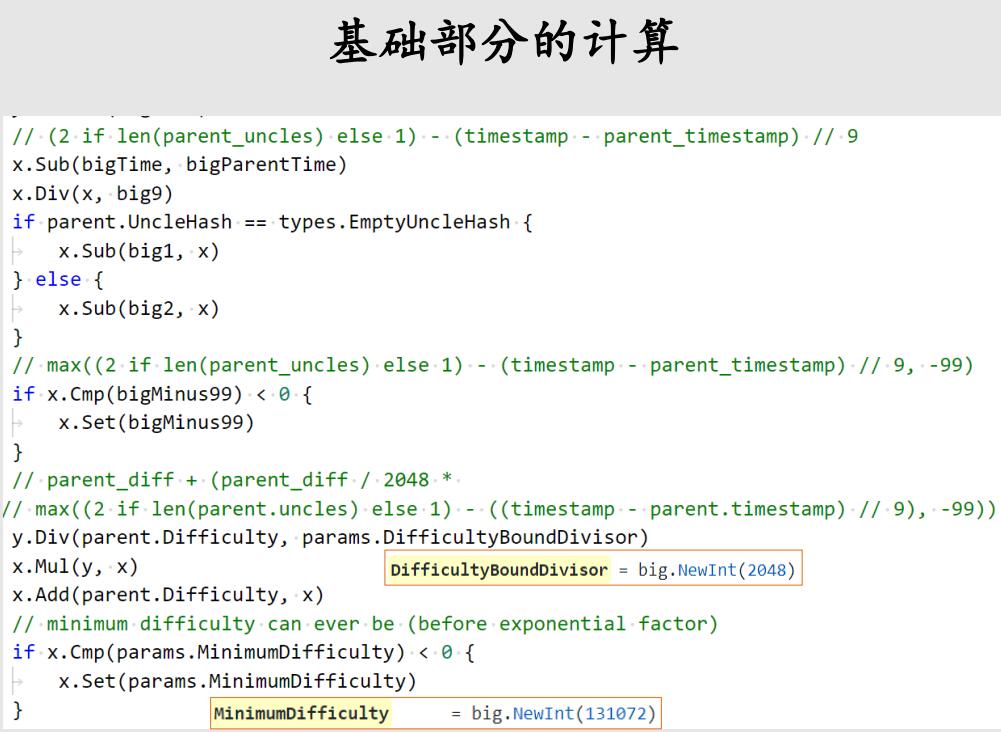
(6)难度炸弹计算
如下图为fake block number,也就是假的区块号,我们前面说的Hi’。
-
先看这个if判断,和2999999比较,比它大的话就要减掉2999999。
-
那么问题来了,为什么不减3000000,之前说的那个公式不应该减300万吗?
因为判断的是父区块的序号,而我当前挖的区块要比父区块的序号多一个,所以你得按照父区块的序号算的话,正好差一个。 -
再下面是把假的区块号除以expDiffPeriod,也就是除以10万,然后向下取整,再减去2,然后把这个结果当做2的指数部分,算出来的就是难度炸弹的取值。最后加到x上面,x就是前面代码中算出的基础部分难度x。

(7)下面我们一起来看看以太坊中的实际情况
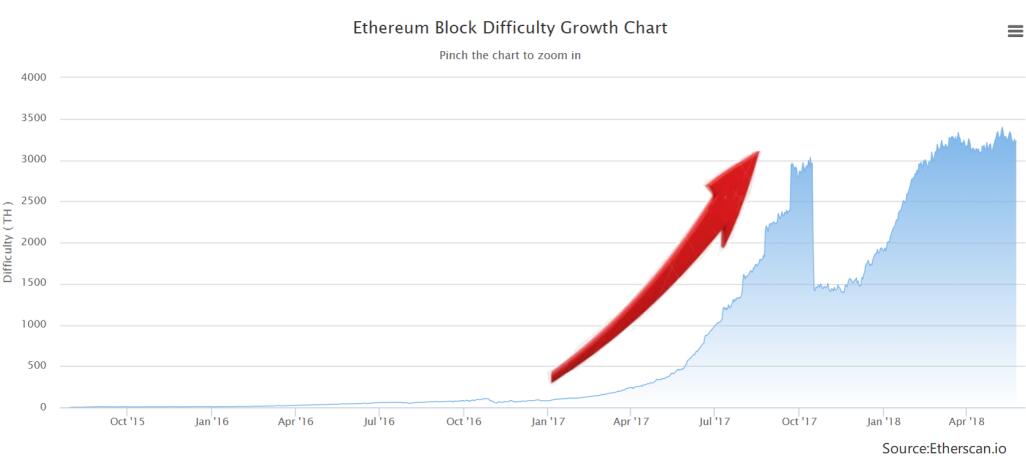
- 1.以太坊挖矿难度变化曲线,如下图。
可以看出以太坊早期,挖矿难度增长不是很明显的,增长是比较缓慢的,所以以太坊当时市值很小。图中断崖式下跌是由于下调难度炸弹300万个区块。下调后又震荡了一会,然后逐步上升,现在以太坊的挖矿难度已经恢复到以前水平,而且还有增加。从图中可以看出目前挖矿难度基本是趋于稳定的。
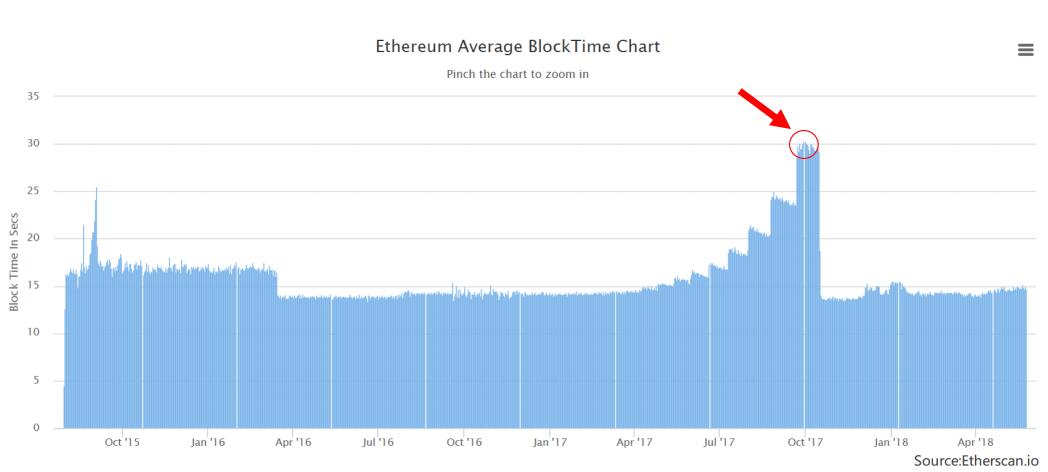
- 2.以太坊出块时间变化曲线图
如下图,这个图显示的出块时间变化。从图中可以看到,如果不考虑个别波动的话,总体来说,出块时间稳定在15秒上下的有很长时间。说明在早期时候,挖矿难度的调整主要是以稳定出块时间为主的,它达到了预期的效果。图中后面一部分,出块时间出现了大幅度增长,这就是难度炸弹的效应,这时出块时间已经达到了30秒左右。然后难度炸弹的回调,一下子断崖式下降,又恢复到了15秒,并维持稳定。
- 3 下图是之前Ghost协议章节看过的两个区块,我们这次主要看红框画出的两行。
difficulty为当前区块难度,total difficulty为当前区块链上所有区块难度相加,也就是这条链的总难度。可见,之前我们说的最长合法链对于以太坊来说,也就等同于最难合法链(难度最大合法链)。每个区块的难度反映的是挖出这个区块所需要的工作量,而总难度最大就是挖出这条链上所有区块需要的工作量最大。
8. 权益证明
8.1 工作量证明(POW)的耗能
之前的文章中,我们一直在提到权益证明(POS),本章节便专门讲述权益证明。
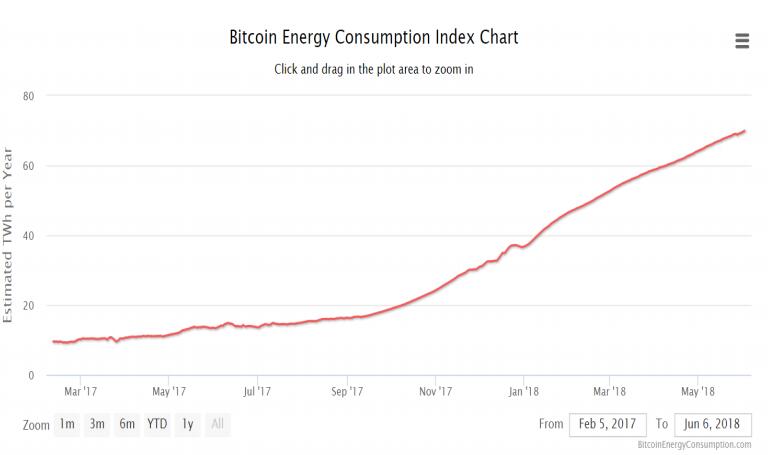
(1)比特币和以太坊目前采用的都是POW(工作量证明)机制,但这种方式受到一个普遍的批评,就是浪费电。如下图,我们这个图上显示了比特币能耗随时间变化的情况,y轴是TWh(Tera Watt Hour)是10的12次方。我们比较熟悉的是KWh(kiloWatt-hour),它是10的三次方,叫做千瓦时一度电。下图中,我们可以看出比特币的能耗随时间是不断增长的。
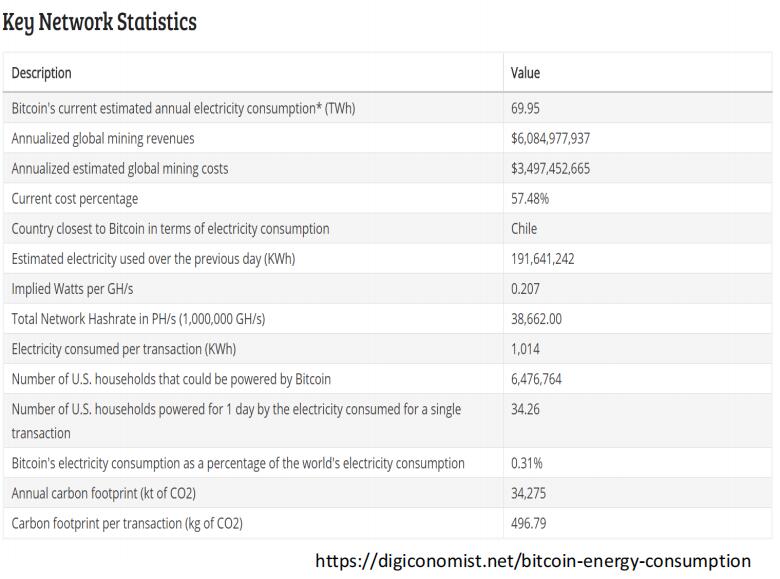
(2)下图给出了一些具体的统计数据。比特币每年的总能耗大概是70个TWh,相当于647万多个美国家庭的能耗,占世界总能耗的0.31%。具体到每个交易上来说,平均每个交易的能耗是1014千瓦时,相当于34.26个美国家庭一天的能耗,这是相当大的。一个交易要花1000度电,这听起来很吓人。信用卡公司处理一个交易的能耗,远远没这么大。比特币挖矿的每年总收入是60多亿美元,将近61亿美元,然后费用差不多35亿美元,占总收入的57.48%。说明挖矿的利润空间还是很大的。
(3)下面我们一起看看以太坊的数据,如下图。以太坊的能耗也是随时间增长的,中间有一些波动。
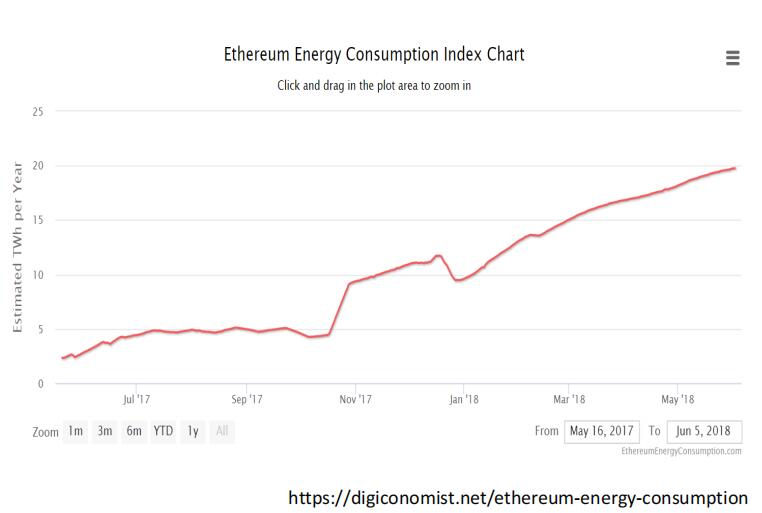
- 从具体数据上来看,以太坊一年的能耗大概是20个TWh,这和比特币的70多个TWh比起来还是少了不少,相当于冰岛这个国家的能耗,也相当于183万个美国家庭的能耗,能耗占全世界总能耗的0.09%。这平均到每个交易上,每个交易的能耗是67千瓦时,相当于2.25个美国家庭一天的能耗。
- 这和比特币的1000个千瓦时相比,实际上少了很多。大家
以上是关于区块链学习笔记之以太坊的主要内容,如果未能解决你的问题,请参考以下文章