手把手教你爬取清纯小姐姐私房照,小孩子别学,后篇
Posted 诗一样的代码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手教你爬取清纯小姐姐私房照,小孩子别学,后篇相关的知识,希望对你有一定的参考价值。
前篇:
传送门
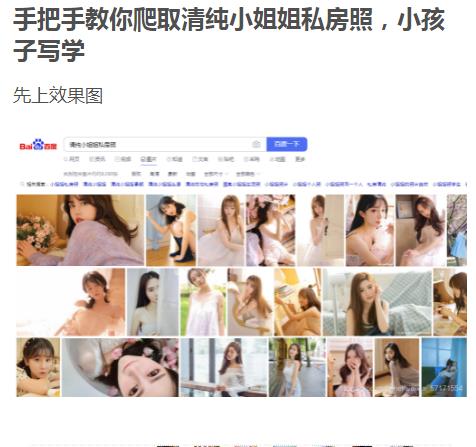
因为写了前一篇爬虫博客,看来挺火的。哈哈,第一篇阅读量破万的的博客,还是的庆幸的。
因为火热程度比较高,直接就进入了python热榜第一了。

来来来,这一篇除了炫耀下成绩以外,还来一些干货。
有挺多小伙伴在后台问我,甚至加我问的问题就是:为什么我的程序报错了?诶,奇怪的是,他们报错都是同一个问题。


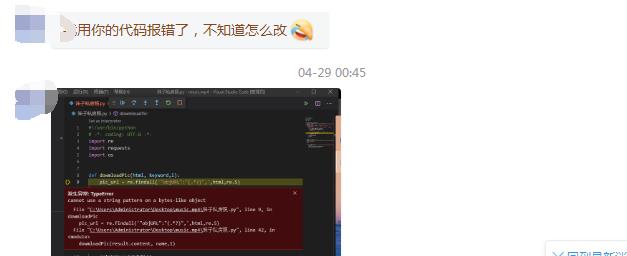
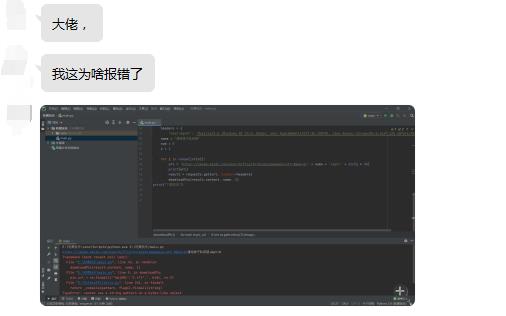
好家伙,起码有几十个小伙子问过这个问题。具体问题是:
TypeError: cannot use a string pattern on a bytes-like object
哎呀,这是为什么呢?是不是博主夹带了干货没放出来呢?实属冤枉 啊。大概率是我用的是py2,你用的是py3
python2和python3之间切换,难免会碰到一些问题,python3中Unicode字符串是默认格式(就是str类型),ASCII编码的字符串(就是bytes类型,bytes类型是包含字节值,其实不算是字符串,python3还有bytearray字节数组类型)要在前面加操作符b或B;python2中则是相反的,ASCII编码字符串是默认,Unicode字符串要在前面加操作符u或U
那怎么解决呢?转换一下不就行了吗。
import chardet #需要导入这个模块,检测编码格式
encode_type = chardet.detect(html)
html = html.decode(encode_type['encoding']) #进行相应解码,赋给原标识符(变量)
完整代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import chardet
import re
import requests
import os
def dowmloadPic(html, keyword,i):
encode_type = chardet.detect(html)
html = html.decode(encode_type['encoding']) #进行相应解码,赋给原标识符(变量)
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
abc=i*60
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
for each in pic_url:
print('正在下载第' + str(abc) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
dir = r'D:\\image\\i' + keyword + '_' + str(abc) + '.jpg'
if not os.path.exists('D:\\image'):
os.makedirs('D:\\image')
.......完整源码,请关注公众号,后台回复领取
更多干货内容,请移步到公众号:诗一样的代码

以上是关于手把手教你爬取清纯小姐姐私房照,小孩子别学,后篇的主要内容,如果未能解决你的问题,请参考以下文章