python中必须要会的四大高级数据类型(字符,元组,列表,字典)
Posted 神的孩子都在歌唱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python中必须要会的四大高级数据类型(字符,元组,列表,字典)相关的知识,希望对你有一定的参考价值。
前言
作者:神的孩子都在跳舞
关注我的csdn博客,更多python知识还在更新
一. 字符串
生活中我们经常坐大巴车,每个座位一个编号,一个位置对应一个下标。 字符串中也有下标,要取出字符串中的部分数据,可以用下标取。

-
python中使用切片来截取字符串其中的一段内容,切片截取的内容不包含结束下标对应的数据。
-
切片使用语法:[起始下标:结束下标:步长] ,步长指的是隔几个下标获取一个字符。
注意:下标会越界,切片不会
- 常用函数

- 练习:
Test='rodma '
print(type(Test))
print('Test的一个字符串%s'%Test[0])#跟数组差不多
#循环输出
for i in Test:
print(i,end=" ")#也可以用‘ ’
print('\\n')
# count():统计出现的次数
print(Test.count('r'))
# join():循环取出所有值用xx去连
str='-'
print(str.join(Test))
#去除两边空格strip(),去除右边空格:lstrip(),去除右边空格:rstrip
print(Test.strip())
#复制字符串,id函数可以查看对象的内存地址
print('Test的内存地址%d'%id(Test))
b=Test #在此只是把a对象的内存地址赋给了b
print('Test的内存地址%d'%id(Test))
print(b)
#定义一个数接下来用
datastr='i love Python'
#find函数:可以查找目标对象在序列对象中的为值,如果没找到就返回-1
print(datastr.find('M'))
# index()函数:检测字符串中是否包含子字符串 返回的是下标值
print(datastr.index('i'))
#find 和 index 的区别:如果index没有找到对象就会报错,find输出-1,找到输出0
#starswith()函数:判断开头,如果是就true
#endswith()函数是判断结尾
print(datastr.startswith('i'))
# capitalize():首字母转换为大写
# isalnum():判断是否是字母和数字,全部是字母就输出true,有空格也不行
# isalpha() :判断是否是字母
# isdigit():判断是否全部是数字
# swapcase():大写变小写,小写变大写
# title() :把每个单词的首字母变成大写
# lower():装换为小写。
# upper():转换为大写
a='tsx'
print(type(a))
print(datastr.capitalize())
print(a.isalnum())
print(datastr.isalpha())
print('abc123'.isdigit())
print(datastr.swapcase())
print(datastr.title())
print(datastr.lower())
print(datastr.upper())
# 切片:是指截取字符串中的其中一段内容。
# 切片使用语法:[起始下标:结束下标:步长]
# 切片截取的内容不包含结束下标对应的数据,步长指的是隔几个下标获取一个字符。
# slice [start:end:step] 左闭右开 start<=value<end 范围
# 下标会越界,切片不会
#记住左闭右开的原则
# 定义一个对象
strmgs='Never give up'
# 1——8之间的数据
print(strmgs[1:8])
# 第3个字符到最后
print(strmgs[2:])
# 第1个字符到第3个 温馨提示:记住左闭右开的原则
print(strmgs[:3])
# 步长是什么?比如定义2,就是从当前开始到2个下标获取一个字符,在通俗点就是隔一个获取下一个
print(strmgs[::2])
# 负方向是倒序输出,如果步长选为-1,则反方向输出
print(strmgs[::-1])
# 同理,如果步长是-2,则反方向隔两个下标获取一个字符
print(strmgs[::-2])
# 共有方法有三种 + * in
# +:两个对象相加操作,会合并两个对象
# *:对象自身按指定次数进行 + 操作
# in:判断指定元素是否存在于对象中,输出的是bool值
strA='I love'
strB='Python'
print(strA+strB)
print(strA*3)
print('I' in strA)
'''输出
<class 'str'>
Test的一个字符串r
r o d m a
1
r-o-d-m-a- -
rodma
Test的内存地址1863907131504
Test的内存地址1863907131504
rodma
-1
0
True
<class 'str'>
I love python
True
False
False
I LOVE pYTHON
I Love Python
i love python
I LOVE PYTHON
ever gi
ver give up
Nev
Nvrgv p
pu evig reveN
p vgrvN
I lovePython
I loveI loveI love
True
'''
二. 列表
list是一种有序的集合[],可以随时添加和删除其中的元素。
列表的下标取值/切片/是否越界与字符串一致,区别就是列表是获取元素。
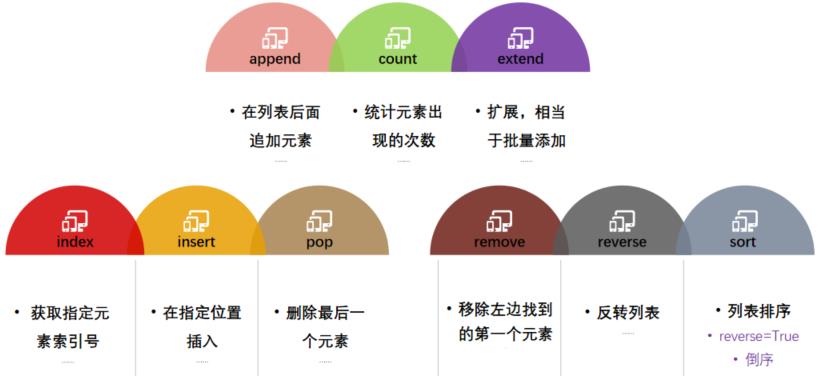
练习
li=[] # 空列表
li=[1,2,3,4,'python',True]
print(type(li))
# #len函数可以获取到列表对象中的数据个数
print(len(li))
# append();在列表后面追加元素
# count(): 统计元素出现的次数
# extend(): 扩展,相当于批量添加
# index(): 获取指定元素索引号
# insert(): 在指定位置插入
# pop(): 删除后面一个元素
# remove():移除左边找到的第一个元素
# reverse(): 反转列表
# sort():列表排序 reverse=True为倒序
listA=['abcd',785,12.23,'qiuzhi',True]
# print('--------------增加-----------------------')
print('追加之前',listA)
listA.append(['fff','ddd']) #追加操作
listA.append(8888)
print('追加之后',listA)
listA.insert(1,'这是我刚插入的数据') #插入操作 需要执行一个位置插入
print(listA)
rsData=list(range(10)) #强制转换为list对象
print(type(rsData))
listA.extend(rsData) #拓展 等于批量添加
listA.extend([11,22,33,44])
print(listA)
# print('-----------------修改------------------------')
# print('修改之前',listA)
# listA[0]=333.6
# print('修改之后',listA)
listB=list(range(10,50))
print(type(listB))
print('------------删除list数据项------------------')
print(listB)
# del listB[0] #删除列表中第一个元素
# del listB[1:3] #批量删除多项数据 slice
# listB.remove(20) #移除指定的元素 参数是具体的数据值
listB.pop(1) #移除制定的项 参数是索引值
print(listB)
#beg -- 开始索引,默认为0。
#end -- 结束索引,默认为字符串的长度。
print(listB.index(19)) #返回的是一个索引下标
# 查找,跟元祖有点不一样,这是左开右闭
print(type(listA))
print(listA) #输出完整的列表
print(listA[0]) #输出第一个元素
print(listA[1:3]) #从第二个开始到第三个元素
print(listA[2:]) #从第三个元素开始到最后所有的元素
print(listA[::-1]) #负数从右像左开始输出
print(listA*3) #输出多次列表中的数据【复制】
a=[21,45,66,78]
b=[1,2]
def add100(x):
i= 0
for item in x:
x[i]=item+100
i+=1
pass
return x
pass
print(add100(b))
def add100(x):
x+=100
return x
list2=list(map(add100,a))
print(list2)
a=[21,45,66,78]
print(list(map(lambda x:x+100,a)))
def Old(x):
if x>50:
return x
pass
print(list(filter(Old,a)))
'''输出
<class 'list'>
6
追加之前 ['abcd', 785, 12.23, 'qiuzhi', True]
追加之后 ['abcd', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888]
['abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888]
<class 'list'>
['abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44]
<class 'list'>
------------删除list数据项------------------
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49]
[10, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49]
8
<class 'list'>
['abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44]
abcd
['这是我刚插入的数据', 785]
[785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44]
[44, 33, 22, 11, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, 8888, ['fff', 'ddd'], True, 'qiuzhi', 12.23, 785, '这是我刚插入的数据', 'abcd']
['abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44, 'abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44, 'abcd', '这是我刚插入的数据', 785, 12.23, 'qiuzhi', True, ['fff', 'ddd'], 8888, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 22, 33, 44]
[101, 102]
[121, 145, 166, 178]
[121, 145, 166, 178]
[66, 78]
'''
三. 元组
-
元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,元组也是通过下标进行访问
-
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
-
元组的内置方法:
count:统计元素在元组中出现的次数
index:查找指定元素在元组中的下标索引 -
练习
#空元组
tupleA=()
print(type(tupleA))
#元组也可以用for语句查询
tupleA=(1,2,3,'cd','a')
for item in tupleA:
print(item,end=' ')
# 元组也可以使用切片,左闭右开
print(tupleA[-2:-1:])#倒着取下标 为-2 到 -1 区间的
#假设元组中放入队列
tupleA=(1,2,3,'cd','a',[11,22,33])
print(tupleA)
#可以对队列的值进行修改(原本元组是不可以修改的)
print(type(tupleA[5]))
tupleA[5][0]=5500
print(tupleA)
tupleA[5].append('chen')
print(tupleA)
'''输出
<class 'tuple'>
1 2 3 cd a ('cd',)
(1, 2, 3, 'cd', 'a', [11, 22, 33])
<class 'list'>
(1, 2, 3, 'cd', 'a', [5500, 22, 33])
(1, 2, 3, 'cd', 'a', [5500, 22, 33, 'chen'])
'''
四. 字典
- 字典是Python的中重要的一种数据类型,可以存储任意对像。
- 字典是以键值对的形式创建的
{'key':'value'}利用大括号包裹着。 - 访问值的安全方式get方法,在我们不确定字典中是否存在某个键而又想获取其值时,可以使用get方法,还可以设置默认值
注意:
- 字典的键(key)不能重复,值(value)可以重复。
- 字典的键(key)只能是不可变类型,如数字,字符串,元组。
- 常用方法

- 练习
# 空字典
dictA={}
print(type(dictA))
# 如何添加字典数据? key:value
dictA['name']='陈运智'
dictA['age']=30
print(dictA)
# 批量添加
dictA={"pro":'艺术','shcool':'北京电影学院','age':30,'pos':'xueshen'}
print(dictA)
# 通过键位修改值
dictA['pro']='学生'
print(dictA)
# 添加更多数据
dictA.update({'name':'陈运智'})
print(dictA)
# 获取所有键和值
print(dictA.keys(),dictA.values())
print(dictA.items())
for key,value in dictA.items():
print('%s==%s'%(key,value))
# 指定键删除
del dictA['name']
print(dictA)
# 按照key和value排序
print(sorted(dictA.keys()))
#print(sorted(dictA.values()))
#拷贝, copy,deepcopy 会拷贝复杂类型,如 list、dict
import copy
dictB=copy.copy(dictA)#浅拷贝
dictc=copy.deepcopy(dictA)#深拷贝
print(id(dictc))
print(id(dictA))
print(id(dictB))
dictB['age']='20'
dictc['age']='20'
print(dictB)
print(dictc)
print(dictA)
print(type(dictB))
print(type(dictc))
本人博客:https://blog.csdn.net/weixin_46654114
本人b站求关注:https://space.bilibili.com/391105864
转载说明:跟我说明,务必注明来源,附带本人博客连接。
请给我点个赞鼓励我吧

以上是关于python中必须要会的四大高级数据类型(字符,元组,列表,字典)的主要内容,如果未能解决你的问题,请参考以下文章