linkis与SQL中间件(跨数据源混查)结合实践分享
Posted WeDataSphere
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linkis与SQL中间件(跨数据源混查)结合实践分享相关的知识,希望对你有一定的参考价值。
【我与WeDataSphere的故事】征文大赛获奖文章分享(一)
作者简介|PROFILE
李宏伟
资深大数据开发专家
长期奋斗在一线的码农,目前在360技术中台数据平台部参加数据中台建设工作,多年大数据领域技术架构与开发经验以及多年CDN领域技术栈开发经验。
01 背景需求
-业务需求:
在公司有很多运营、数据分析的童鞋,虽然自有的BI产品功能丰富,有各式各样的定制化分析报表、各种维度的图表。
但是有时需要临时查询数据,发现数据是分布在不同数据源里的,也有可能数据来自不同业务的不同集群。
比如查询hive表的数据,但是维度映射数据在mysql里。还有要两个mysql数据库(不同服务器)关联查询等情况,
平时这些需求都需要程序猿大神们写程序实现。
-技术迭代:
一直想找个替代组件, 后来发现功能强大的linkis。至于Linkis跟Apache Livy的对比,可以查看官方相关文档。
02 SQL中间件介绍
SQL中间件是基于公司目前开源的XSQL和Quicksql两款SQL中间件,两种都支持跨数据源混查,两个都很优秀,
至于大家选择集成哪个可以根据自身情况决定。因为之前使用过XSQL,所以是在linkis增加了xsql查询引擎。
以下分别简单介绍下两款开源组件:
XSQL:
XSQL是一款低门槛、更稳定的分布式查询引擎。它允许你快速、近实时地查询大量数据。对于一些数据源(例如:Elasticsearch、MongoDB、Druid等),他可以大幅地降低学习曲线,并节省人力成本。除Hive外,每种数据源都支持除子查询外的下推执行优化。用户有时希望将位于不同数据源上的数据关联起来进行查询,但是由于各种数据源是异构的且一些数据源不支持SQL或者支持的SQL语法非常有限,因此传统互联网公司的做法是,将不同的数据同步到统一的存储介质中,再进行OLAP的查询。数据同步的过程中可能面临数据迁移、主从同步、网络带宽等诸多困难和挑战,而且需要浪费大量的人力、物力及时间,无法满足大数据产品当前阶段对于近实时甚至准实时的场景。通过XSQL你将可以避免数据迁移和时间浪费,更加专注于业务本身。XSQL可以通过下推、并行计算、迭代计算等底层支撑技术,对各种数据源的查询加速。
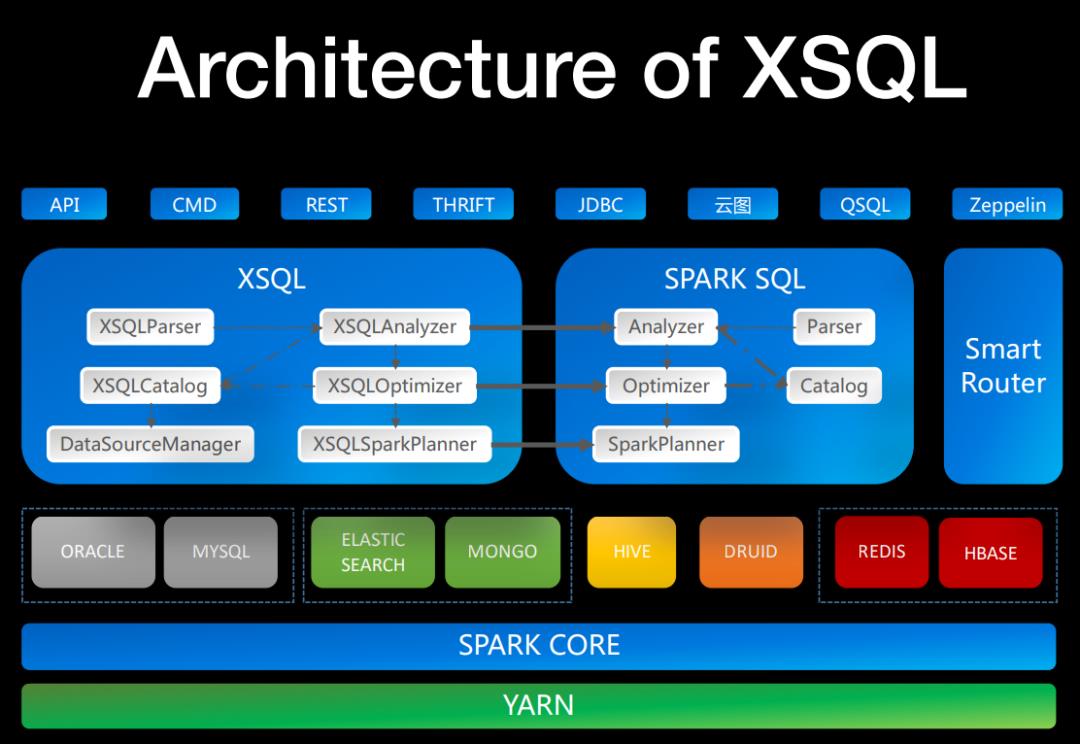
Quicksql:
Quicksql是一款跨计算引擎的统一联邦查询中间件,用户可以使用标准SQL语法对各类数据源进行联合分析查询。其目标是构建实时\离线全数据源统一的数据处理范式,屏蔽底层物理存储和计算层,最大化业务处理数据的效率。同时能够提供给开发人员可插拔接口,由开发人员自行对接新数据源。
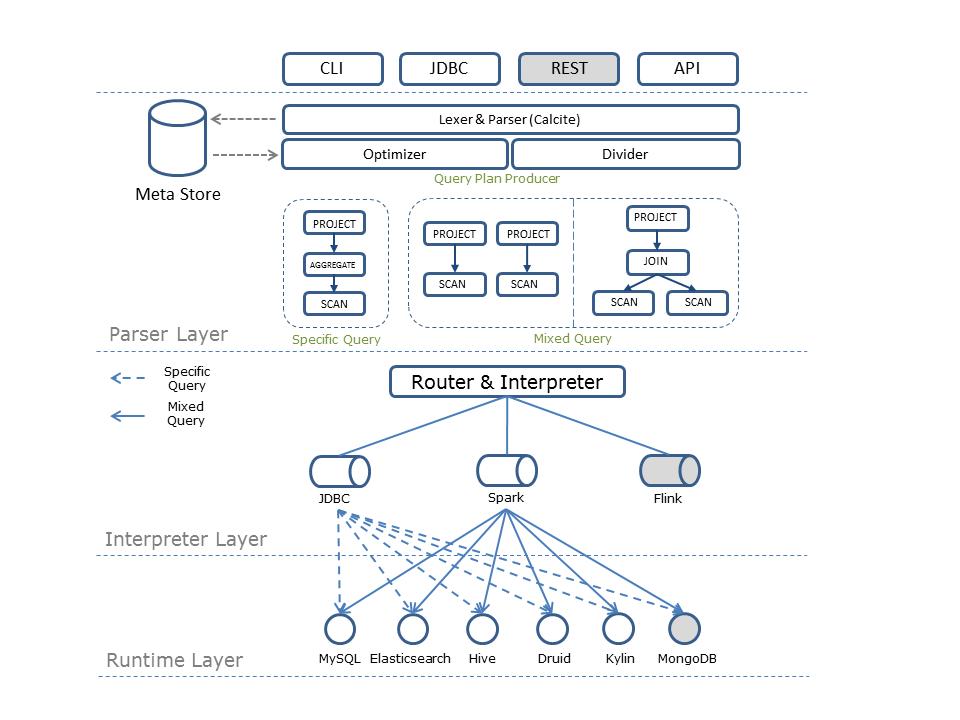
03 执行流程图
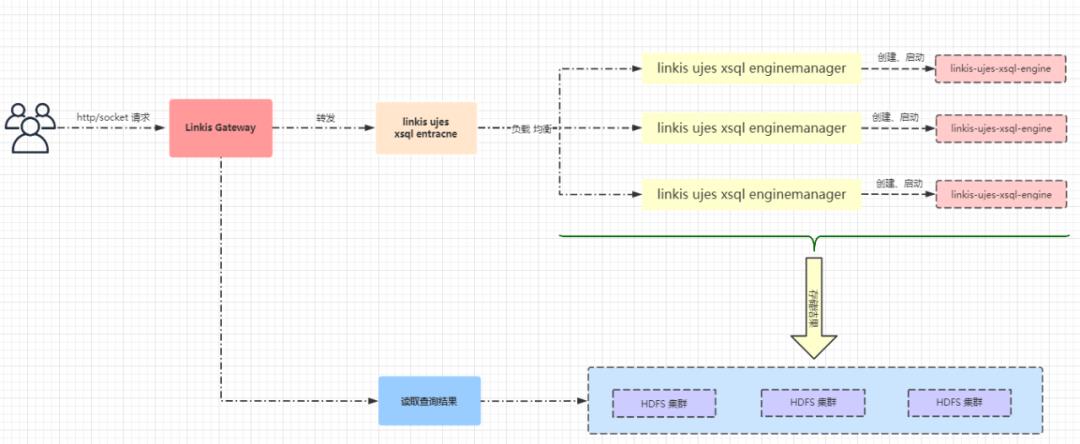
04 实践过程
功能点:
05 实现过程简述
目前是将用到的集群配置文件放到linkis-hadoop-conf文件夹下,用于在启动引擎时以及己启动的执行引擎里进入动态加载。
├── client-viewfs.xml├── core-site-cluster1.xml├── hbase-site-cluster1.xml├── hdfs-site.xml├── hive-default.xml├── hive-exec-log4j.properties├── hive-log4j.properties├── hive-site-cluster1.xml├── ivysettings.xml├── mapred-site-cluster1.xml├── spark-defaults-cluster1.conf├── xsql-spark-defaults-cluster1.conf└── yarn-site-cluster1.xml
ws://gateway.linkis.net:9001/ws/api/entrance/connect?Token-User=xxxx&Token-Code=BML-AUTH//这个地址也需要增加token参数"method":"/api/rest_j/v1/entrance/execute?Token-User=xxx&Token-Code=BML-AUTH","data":{"params": {"variable":{},"configuration":{"special":{},"runtime":{},"startup":{}}},"executeApplicationName":"xsql","executionCode":"SELECT * FROM abc limit 5;","runType":"sql"}}
而且是想根据每次请求中参数动态来设置是否需要Limit,而不是通过全局配置统一禁用还是开启。
业务需要自定义存储结果路径,比如跨集群跨账号存储查询结果。
-
目录结构
pom.xml
<!--<spark.version>2.4.3</spark.version> --><!--把2.4.3修改为2.4.3.xsql-0.6.0 --><spark.version>2.4.3.xsql-0.6.0</spark.version>,2.4.3.xsql-0.6.0这个版本请根据从开源xsql编译时获取,由于适配了公司内部,所以版本号可能略有不同。SparkEngineExecutorFactory 类override def createExecutor(options: JMap[String, String]): SparkEngineExecutor = {val confFile = Paths.get(configPath, "xsql-spark-defaults-" + clusterName + ".conf").toAbsolutePath.toFile.getAbsolutePathSparkUtils.getPropertiesFromFile(confFile).filter { case (k, v) =>k.startsWith("spark.")}.foreach { case (k, v) =>conf.set(k, v)sys.props.getOrElseUpdate(k, v)}}def createSparkSession(outputDir: File, conf: SparkConf, addPythonSupport: Boolean = false): SparkSession = {//val builder = SparkSession.builder.config(conf)//builder.enableHiveSupport().getOrCreate()//划重点:将enableHiveSupport改成enableXSQLSupport()val builder = SparkSession.builder.config(conf)builder.enableXSQLSupport().getOrCreate()}
override protected def executeLine(engineExecutorContext: EngineExecutorContext, code: String): ExecuteResponse = Utils.tryFinally {//同样要增加加载配置代码段val confFile = Paths.get(configPath, "xsql-spark-defaults-" + clusterName + ".conf").toAbsolutePath.toFile.getAbsolutePathSparkUtils.getPropertiesFromFile(confFile).filter { case (k, v) =>k.startsWith("spark.")}.foreach { case (k, v) =>sc.getConf.set(k, v)sys.props.getOrElseUpdate(k, v)}}
06 如何使用
提交参数如下:
{"params":{"variable":{},"configuration":{"special":{},"runtime":{"clusterName":"cluster1","configPath":"/usr/local/dss/linkis/linkis-hadoop-conf","userName":"hadoop","wds.linkis.yarnqueue":"hadoop",//可以传入绝对路径,跨集群写,前提执行账号是对目的路径有写权限"resultPath":"hdfs://namenode.hadoop.net:9000/home/hadoop/dwc/lihongwei"//如果不想linkis进行limit限制,则需要传入"allowNoLimit" : true,//否则不需要传这个参数,linkis则默认会进行limit 5000限制//"allowNoLimit" : true},"startup":{"clusterName":"cluster1","configPath":"/usr/local/dss/linkis/linkis-hadoop-conf","userName":"hadoop","wds.linkis.yarnqueue":"hadoop",//可以传入绝对路径,跨集群写,前提执行账号是对目的路径有写权限"resultPath":"hdfs://namenode.hadoop.net:9000/home/hadoop/dwc/lihongwei"//如果不想linkis进行limit限制,则需要传入"allowNoLimit" : true,//否则不需要传这个参数,linkis则默认会进行limit 5000限制//"allowNoLimit" : true}}},"executeApplicationName":"xsql","executionCode":"REMOVE DATASOURCE IF EXISTS mysql_connect_name;ADD DATASOURCE mysql_connect_name(type='mysql',url='jdbc:mysql://10.22.22.22:3306',user='root',password='123456',pushdown='false',useSSL='false',version='5.7.28');REMOVE DATASOURCE IF EXISTS hive_cluster1;ADD DATASOURCE hive_cluster1(type='hive',metastore.url='thrift://10.222.222.222:9083',user='test',password='test',version='1.2.1');SELECT t1.id,t1.name,t1.title,t2.time,t2.url,t2.partner,t2.m2 FROM (SELECT id,name,title,ip FROM mysql_connect_name.database_name.mysql_tables) t1 JOIN(SELECT m,time,url,partner,ip FROM hive_cluster1.database_name.hive_tablse WHERE day = 20200903) t2ON t1.ip=t2.ip order by t2.time;","runType":"sql"}
相关版本
hive 1.2.1
spark 2.4.3
linkis 0.9.3
xsql 0.6.0
java 1.8+
hadoop 2.7.2
相关资源
更多惊喜,请点击阅读原文
更多 Linkis的相关介绍请访问:
https://github.com/WeBankFinTech/Linkis/blob/master/docs/zh_CN/README.md
https://github.com/WeBankFinTech/Linkis
https://gitee.com/WeBank/Linkis
相关推荐
以上是关于linkis与SQL中间件(跨数据源混查)结合实践分享的主要内容,如果未能解决你的问题,请参考以下文章