二叉树遍历-力扣题解
Posted 落风的落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二叉树遍历-力扣题解相关的知识,希望对你有一定的参考价值。
二叉树
[1]部分代码思想参考了开源项目github.com/greyireland/algorithm-pattern
[2]题目基本来源力扣学习小卡片《二叉树》https://leetcode-cn.com/leetbook/detail/data-structure-binary-tree/
原创警告...
1 二叉树的遍历
二叉树的增删改查的前提都是遍历找到某一个结点,所以遍历是二叉树的基本功(至少想要做的了题是这样),遍历分为三类:
-
二叉树的递归遍历 -
二叉树的非递归遍历(借用栈) -
二叉树BFS的层次遍历(借用队列)
先建一个结点类,搭建二叉树的环境,类中含一个按结点值大小插入成二叉搜索树的函数insertIntoBST
import java.util.*;
public class ListNode {
ListNode left;
ListNode right;
int val;
public ListNode(int val){
this.val=val;
left=null;
right=null;
}
public ListNode insertIntoBST(ListNode root, int val){
if (root==null) return new ListNode(val);
if (root.val>=val){
if(root.left==null) root.left = new ListNode(val);
else this.insertIntoBST(root.left,val);
}else{
if(root.right==null) root.right = new ListNode(val);
else this.insertIntoBST(root.right,val);
}
return root;
}
//统一的二叉树例子
public static void main(String[] args) {
// 中序遍历 2 3 null 4 5 6 7
// 层序遍历 4 3 6 2 null 5 7
// 前序遍历 4 3 2 null 6 5 7
// 后序遍历 2 null 3 5 7 6 4
ListNode root = new ListNode(4);
root.insertIntoBST(root,3);
root.insertIntoBST(root,6);
root.insertIntoBST(root,7);
root.insertIntoBST(root,2);
root.insertIntoBST(root,5);
levelOrderTraversal(root);
}
}
1.1 递归遍历
为更具一般性,我这里遍历时统一将元素放在list数组中。想要存入数组中,需要在调用前新建res集合,每次调用时作为参数传递
//前序遍历
List<Integer> resPre = new ArrayList<>();
preorderTraversal(root,resPre);
//中序遍历
List<Integer> resIn = new ArrayList<>();
inorderTraversal(root,resIn);
//后序遍历
List<Integer> resPost = new ArrayList<>();
postorderTraversal(root,resPost);
1前序遍历
// 递归 前序遍历
private static void preorderTraversal(ListNode root,List<Integer> res){
if(root == null) return;
res.add(root.val);
preorderTraversal(root.left,res);
preorderTraversal(root.right,res);
}
2中序遍历
// 递归 中序遍历
private static void inorderTraversal(ListNode root,List<Integer> res){
if(root == null) return;
inorderTraversal(root.left,res);
res.add(root.val);
inorderTraversal(root.right,res);
}
3后续遍历
// 递归 后序遍历
private static void postorderTraversal(ListNode root,List<Integer> res){
if(root == null) return;
postorderTraversal(root.left,res);
postorderTraversal(root.right,res);
res.add(root.val);
}
1.2 非递归遍历(stark)
List<Integer> res1 = preorderTraversal(root);
List<Integer> res2 = inorderTraversal(root);
List<Integer> res3 = postorderTraversal(root);
1前序遍历
我画了一下迭代过程,过程有点像深度优先搜索,跟下面这个经典的回溯很像、只是选择集合变成了二叉树。
-
先把所有的 left结点存入结果集, 根结点先进结果集、同时也存入栈中, -
然后一个一个的出栈,看出栈的结点有没有 right结点, -
有的话以该结点为 root,同样的方式进行搜索、进结果集。
//非递归 前序遍历stack
private static List<Integer> preorderTraversal(ListNode root){
if(root == null) return new ArrayList<>(0);
List<Integer> res = new ArrayList<>();
Deque<ListNode> stack = new LinkedList<>();
while(root!=null || !stack.isEmpty()){
while(root!=null){
res.add(root.val);
stack.push(root);
root = root.left;
}
//stack弹出 最后进入也就是最左子结点
ListNode tempNode = stack.pop();
root = tempNode.right;
}
return res;
}
2中序遍历
中序遍历与前序遍历的差别就是:先把元素存入栈中,元素从栈中弹出后再加入到结果集res中,也就是先把最左边的加入结果集
//非递归 中序遍历stack
private static List<Integer> inorderTraversal(ListNode root){
if(root==null) return new ArrayList<>(0);
List<Integer> res = new ArrayList<>();
Deque<ListNode> stack = new LinkedList<>();
while(root!=null || !stack.isEmpty()){
while(root!=null){
stack.push(root);
root = root.left;
}
ListNode tempNode = stack.pop();
res.add(tempNode.val);
root = tempNode.right;
}
return res;
}
3后序遍历
因为栈中的元素始终是先左再右的,对后序遍历麻烦一些。要保证根节点必须要在右结点弹出之后再弹出,所以通过设置lastVisit结点来标识右子节点是否已经弹出,即弹出之前多加一层判断,看当前结点的right是否为空或者是否上次已弹出
//非递归 后续遍历stack root必须要在right弹出之后再弹出
// 通过lastVisit标识右子节点是否已经弹出
private static List<Integer> postorderTraversal(ListNode root){
if(root == null) return null;
ListNode lastVisited = null;
List<Integer> res = new ArrayList<>();
Deque<ListNode> stack = new LinkedList<>();
while(root!=null ||!stack.isEmpty()){
while(root!=null) {
stack.push(root);
root = root.left;
}
//先看看能不能弹出
ListNode tempNode = stack.peek();
//多一层判断
if(tempNode.right==null||tempNode.right==lastVisited){
stack.pop();
res.add(tempNode.val);
lastVisited = tempNode; //标记已经加入结果
}else{
root = tempNode.right;
}
}
return res;
}
1.3 层序遍历
层序遍历利用队列的先进先出的特性,队列一次存入每一层的所有元素、然后一次循环一次性弹出该层的所有元素加入临时list集合中,弹出的过程中、顺手将下一次的元素入队,每次循环结束、将临时list集合加入二维结果集res中。
层序遍历的考察点挺多的,比较重要,是基本功。
//层序遍历
private static List<List<Integer>> levelOrderTraversal(ListNode root){
if(root==null) return null;
List<List<Integer>> res = new ArrayList<>();
ArrayDeque<ListNode> deque = new ArrayDeque<>();
deque.add(root);
while(!deque.isEmpty()){
//取队列的长度 也就是当前层有多少的元素、便于循环
int length = deque.size();
List<Integer> leverList = new ArrayList<>(); //保存每层元素的集合
for(int i=0;i<length;++i){
ListNode leverNode = deque.poll();
leverList.add(leverNode.val);
//下一次元素入队
if(leverNode.left!=null) deque.offer(leverNode.left);
if(leverNode.right!=null) deque.offer(leverNode.right);
}
res.add(leverList);
}
return res;
}
2 二叉树力扣题解
分治算法应用[1]
思路:先分别处理局部,再合并结果。二叉树的大部分题解思想都用到了分治算法、快排和归并排序也是分治算法的经典应用。
分治法模板:1递归结束条件 2分段处理 3合并结果
public ResultType traversal(ListNode root){
//1递归结束条件
if(root==null){
// do something and return
}
//2分治处理
ResultType left = traversal(root.Left);
ResultType right = traversal(root.Right);
//3合并结果
ResultType result = Merge from left and right;
return result;
}
遍历都学会了、又学了分治算法的思想,就可以莽力扣题了~
2.1 104.二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
示例: 给定二叉树 [3,9,20,null,null,15,7],返回它的最大深度 3 。
3
/ \
9 20
/ \
15 7
思路:二叉树的最大深度等于 其左子树和右子树最大深度的大值 +1
代码:直接套分治法模板
class Solution {
public int maxDepth(TreeNode root) {
//二叉树的最大深度 为左右子树的最大深度+1
if(root==null) return 0;
int left = maxDepth(root.left);
int right = maxDepth(root.right);
return Math.max(left,right)+1;
}
}
2.2 110.平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
思路:平衡二叉树的条件是左右子树都是平衡二叉树且左右子树高差不超过1
代码:先写一个算最大深度的函数,三个判断条件同时满足时为平衡
class Solution {
public boolean isBalanced(TreeNode root) {
if(root==null) return true;
boolean left = isBalanced(root.left);
boolean right = isBalanced(root.right);
return left && right&& (Math.abs(maxDepth(root.left)-maxDepth(root.right))<2);
}
//写一个计算最大深度的函数
private int maxDepth(TreeNode root){
if(root==null) return 0;
int left = maxDepth(root.left);
int right = maxDepth(root.right);
return Math.max(left,right)+1;
}
}
还可以优化一下maxdepth函数,当不是平衡二叉树的时候返回-1,如果暂且还是平衡才返回最大深度。
class Solution {
public boolean isBalanced(TreeNode root) {
return maxDepth(root)==-1? false:true;
}
//写一个计算最大深度的函数 判断过程出现不平衡直接返回-1
private int maxDepth(TreeNode root){
if(root==null) return 0;
int left = maxDepth(root.left);
int right = maxDepth(root.right);
if(left==-1||right==-1 || Math.abs(left-right)>1) return -1;
return Math.max(left,right)+1;
}
}
2.3 对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
方法一:自下而上的分治算法解题
思路:要想本节点对称,需要他的左右节点对称。所以要想树的根节点对称,我们可以自底向上的递归判断,只有底层节点对称了、才推出其上一层对称、最后推之根节点对称。直接套用分治法模板:1递归结束条件 2分段处理 3合并结果
-
递归结束条件 -
当节点左右子节点都为空,则当前节点对称返回true -
当左右子节点只有一个为空,或者两者都非空但值不等,则返回false -
分段处理:如果两节点都非空且值相等,就要继续分段考察这两个子节点的对称情况 -
递归调用 判断左子节点的左子节点 和 右子节点的右子节点 是不是对称 -
递归调用 判断 左子节点的右子节点 和 右子节点的左子节点 是不是对称 -
合并结果 -
如果递归出来都是真 就返回true
代码比较简单
class Solution {
public boolean isSymmetric(TreeNode root) {
//分治的思想 本节点对称 需要左右子节点对称
if(root ==null) return true;
return helper(root.left, root.right);
}
private boolean helper(TreeNode left, TreeNode right){
//都为空表示父节点是叶子节点 返回真
if(left==null && right==null) return true;
//如果只有一个为空 或者都不空但值不相等 返回假
if(left==null||right==null ||left.val!=right.val) return false;
// 上面是出口 这里是递归调用
return helper(left.right,right.left) && helper(left.left , right.right);
}
}
方法二:自顶而下的迭代方法
思路:和层序遍历的想法一样利用队列来实现二叉树的迭代遍历,不同的是为了验证二叉树的对称属性,每次出队入队两个节点元素。如果出现两个都为空的情况注意continue进入下一次循环直到队列为空。
代码:细节处要注意,运算速度比分治稍慢
class Solution {
public boolean isSymmetric(TreeNode root) {
// 方法二 非递归的解决 利用队列 每次同时入队两个出队两个
if(root==null) return true;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root.left);
queue.offer(root.right);
while(!queue.isEmpty()){
//出队两个
TreeNode left = queue.poll();
TreeNode right = queue.poll();
if(left==null&&right==null) continue;
if(left==null||right==null||left.val!=right.val) return false;
//子节点入队 注意顺序
queue.offer(left.left);
queue.offer(right.right);
queue.offer(left.right);
queue.offer(right.left);
}
return true;
}
}
2.4 112路径总和/ 剑指34和为某一值的路径
112 路径总和
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum ,判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。叶子节点 是指没有子节点的节点。
示例 1:
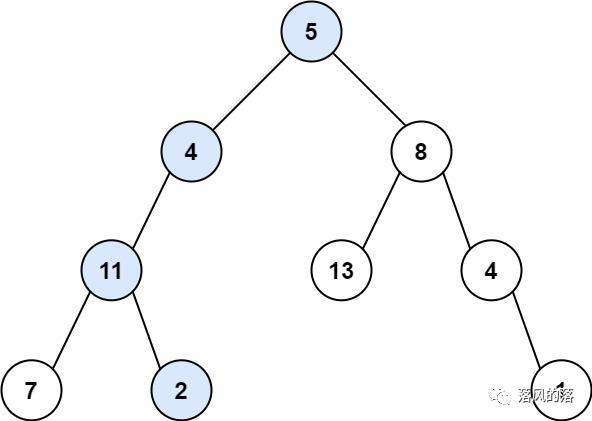
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
思路:
分治算法:如果想要root下的某条路径和为target,需要先判断其子节点下是否存在某条路径的和为target-root.val,(向下细分、下层的结果影响上层的结果)
分治算法的三个步骤:1递归结束条件 2分段处理 3合并结果。递归结束条件是已经找到叶子节点、
代码
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
//还是分治算法 递归出口就是root为空 或者root为叶子节点
// 分段处理 就是要判断其左右子节点 是否等满足值等于targetSum-root.val
if(root == null) return false; //为空false
//叶子节点出口
if(root.left==null&&root.right==null && root.val==targetSum) return true;
//分段处理
boolean left = hasPathSum(root.left, targetSum-root.val);
boolean right = hasPathSum(root.right, targetSum-root.val);
return left||right; //有一个的和满足就行
}
}
剑指34和为某一值的路径
输入一棵二叉树和一个整数,打印出二叉树中节点值的和为输入整数的所有路径。从树的根节点开始往下一直到叶节点所经过的节点形成一条路径。
示例: 给定如下二叉树,以及目标和 target = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1返回:
[
[5,4,11,2],
[5,8,4,5]
]
思路一:分治算法
与判断是否存在不同,这里需要找到所有和为target的路径。但分治算法的思想仍然是一致的。
-
递归出口就是已经找到叶子节点 -
注意list集合的深拷贝
class Solution {
List<List<Integer>> res;
public List<List<Integer>> pathSum(TreeNode root, int target) {
res = new ArrayList<>();
findPathSum(root,target,new ArrayList<Integer>());
return res;
}
private void findPathSum(TreeNode root, int target, List<Integer> list){
if(root==null) return;
//这里注意 传递过来的list不能用 直接新建一个list
ArrayList<Integer> subList = new ArrayList<>(list);
subList.add(root.val);
//如果时叶子结点并与target相等 就加入结果集中
if(root.left==null && root.right==null &&root.val ==target){
res.add( subList );
return;
}
//不是的的话就递归往左右子树继续找
findPathSum(root.left,target-root.val,subList);
findPathSum(root.right,target-root.val,subList);
}
}
思路二:回溯算法
每次选择完之后撤销选择、、效率就变高了、反正我没看懂。
class Solution {
List<List<Integer>> res;
public List<List<Integer>> pathSum(TreeNode root, int target) {
res = new ArrayList<>();
findPathSum(root,target,new ArrayList<Integer>());
return res;
}
private void findPathSum(TreeNode root, int target, List<Integer> subList){
if(root==null) return;
subList.add(root.val);
if(root.left==null&&root.right==null&&root.val==target){
res.add(new ArrayList<>(subList));
//回溯 撤回选择
subList.remove(subList.size()-1);
return;
}
//如果不是叶子节点或者不满足sum条件 就向子节点继续找
findPathSum(root.left,target-root.val, subList);
findPathSum(root.right, target-root.val, subList);
//撤回选择
subList.remove(subList.size()-1);
}
}
2.5 106从中序与后序遍历序列构造二叉树
根据一棵树的中序遍历与后序遍历构造二叉树。
注意: 你可以假设树中没有重复的元素。
例如,给出
中序遍历 inorder = [9,3,15,20,7] 后序遍历 postorder = [9,15,7,20,3] 返回如下的二叉树:
3
/ \
9 20
/ \
15 7
思路:
-
仍然是分治的思想: 1递归出口为后序数组已经遍历完成 -
2分段处理 由后序遍历找到根节点 由中序遍历找到左右子树的节点个数 -
分段处理中序数组中根节点 左边子树部分 和 右边的子树部分 -
3合并结果将root指向递归得到的两个子树 -
要用一个map集合存中序数组,键是node值 值是索引 方便找左右子树的元素个数
代码
class Solution {
int[] inorder;
int[] postorder;
public TreeNode buildTree(int[] inorder, int[] postorder) {
this.inorder = inorder;
this.postorder = postorder;
//要用一个map集合存中序数组,键是node值 值是索引 方便找左右子树的元素个数
int n = postorder.length;
if(n==0) return null;
Map<Integer,Integer> map = new HashMap<>();
for(int i=0;i<n;i++){
map.put(inorder[i],i);
}
//递归调用
return hepler(0,n-1,0,n-1,map);
}
private TreeNode hepler(int inoLeft, int inoRight, int postLeft, int postRight, Map<Integer,Integer> map){
//递归出口
if(postLeft>postRight) return null;
if(postLeft == postRight) return new TreeNode(postorder[postRight]);
//分段处理 由后序遍历找到根节点 由中序遍历找到左右子树的节点个数
int rootVal = postorder[postRight];s
TreeNode root = new TreeNode(rootVal);
int rootIndex = map.get(rootVal);
int leftNums = rootIndex-inoLeft;
int rightNums = inoRight-rootIndex;
//分别递归获得左右子树
TreeNode left = hepler(inoLeft,inoLeft+leftNums-1, postLeft, postLeft+leftNums-1, map);
TreeNode right = hepler(rootIndex+1,inoRight, postRight-1-rightNums+1, postRight-1,map);
root.left = left;
root.right =right;
return root;
}
}
2.6 105从前序遍历和中序遍历序列构造二叉树
思路:分治思想,注意用map集合保存中序遍历的数组、方便找root的索引和计算左右子树的节点个数
代码:
class Solution {
int[] preorder;
int[] inorder;
public TreeNode buildTree(int[] preorder, int[] inorder) {
this.preorder = preorder;
this.inorder = inorder;
//保存中序至map中
int n = inorder.length;
Map<Integer,Integer> map = new HashMap<>();
for(int i=0;i<n;++i){
map.put(inorder[i],i);
}
//调用递归函数获得树
return helper(0,n-1,0,n-1,map);
}
private TreeNode helper(int preLeft, int preRight, int inoLeft, int inoRight, Map<Integer,Integer> map){
//递归出口 叶子节点
if(preLeft>preRight) return null;
if(preLeft==preRight) return new TreeNode(preorder[preLeft]);
//由前序遍历找根节点 由中序遍历找左右子树的节点个数
int rootVal = preorder[preLeft];
int rootIndex = map.get(rootVal);
int leftNums = rootIndex-inoLeft;
int rightNums = inoRight - rootIndex;
TreeNode root = new TreeNode(rootVal);
//分段迭代
TreeNode left = helper(preLeft+1, preLeft+1+leftNums-1, inoLeft, rootIndex-1 , map);
TreeNode right = helper(preRight-rightNums+1, preRight, rootIndex+1,inoRight, map);
root.left = left;
root.right = right;
return root;
}
}
2.7 116. 填充每个节点的下一个右侧节点指针
给定一个 完美二叉树 ,其所有叶子节点都在同一层,每个父节点都有两个子节点。
填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
示例:
输入:root = [1,2,3,4,5,6,7] 输出:[1,#,2,3,#,4,5,6,7,#]
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,'#' 标志着每一层的结束。
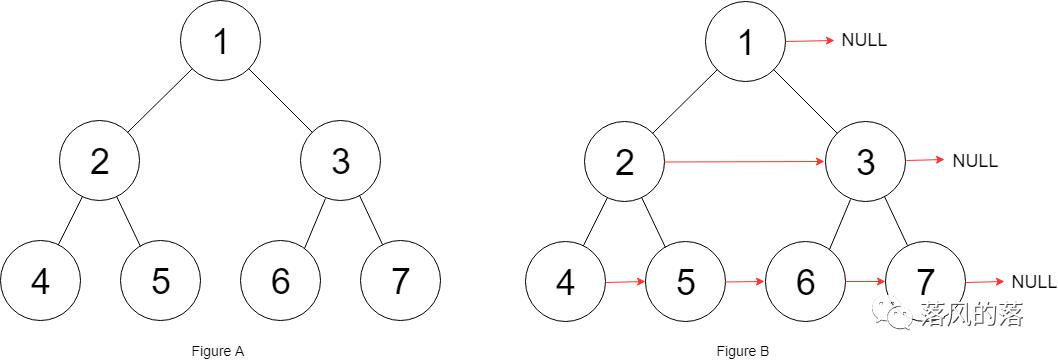
思路:直接层序遍历,队列中存每一层的元素,遍历时给next指针赋值
代码:
class Solution {
public Node connect(Node root) {
//菜鸡我的直白想法其实也是层序遍历
if(root == null) return null;
Queue<Node> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()){
int length = queue.size();
for(int i=0;i<length;++i){
Node temp = queue.poll();
//如果不是最后一个元素就指向下一个元素,否则指向空
if(i==length-1) temp.next=null;
else temp.next = queue.peek();
if(temp.left!=null) queue.offer(temp.left);
if(temp.right!=null) queue.offer(temp.right);
}
}
return root;
}
}
2.8 236. 二叉树的最近公共祖先
236 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
示例 1:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 输出:3 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
思路:注意p,q必然存在树内, 且所有节点的值唯一。 递归思想, 对以root为根的(子)树进行查找p和q, 如果root==p||root=q 直接返回root 表示对于当前树的查找已经完毕, 否则对左右子树进行查找, 根据左右子树的返回值判断:
-
1**. 左右子树的返回值都不为null, 由于值唯一左右子树的返回值就是p和q, 此时root为LCA** -
2.如果左右子树返回值只有一个不为null, 说明只有p和q存在于左或右子树中, 最先找到的那个节点为LCA -
3.左右子树返回值均为null, p和q均不在树中, 返回null
代码
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root==null) return null;
if(root==p|| root==q) return root;
TreeNode left = lowestCommonAncestor(root.left,p,q);
TreeNode right = lowestCommonAncestor(root.right,p,q);
//左右子节点分别是p q
if(left!=null&&right!=null) return root;
//p q 都在左子树内 或者都在右子树内
if(left!=null || right!=null) return left==null? right:left;
return null; //p q不存在与树中
}
}
剑指68 二叉搜索树的最近公共祖先
如果p q在同一边继续向那一边往下找,如果位于两边则此时的root就是最近祖先。
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
TreeNode res = root;
while(true){
if(p.val<res.val&&q.val<res.val){
res=res.left;
}else if(p.val>res.val&&q.val>res.val){
res=res.right;
}else{
break;
}
}
return res;
}
}
2.9 297. 二叉树的序列化与反序列化
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
示例 1:
输入:root = [1,2,3,null,null,4,5]
输出:[1,2,3,null,null,4,5]
方法一:层序遍历迭代的方式
1、将二叉树序列化为字符串,比较容易,直接套用层序遍历过程,并用StringBuilder存结果就好、只需至于空节点也要保留,用字符#代替
2、将字符串反序列化为二叉树:
-
先将字符串分隔尾字符数组 遍历数组 -
每次遍历 出队一个 为该节点指定两个子节点 并将这两个子节点进队 -
当所有的元素都进队完毕时表示二叉树已经建立完成
代码:
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
//层序遍历 取出字符存为sb
if(root==null) return "#";
StringBuilder sb = new StringBuilder();
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()){
TreeNode temp = queue.poll();
if(temp==null) {
sb.append("#,");
continue;
}
sb.append(temp.val+",");
//无论是否为空都加入队列
queue.offer(temp.left);
queue.offer(temp.right);
}
return sb.toString();
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
//当所有的元素都进队完毕时表示二叉树已经建立完成
if(data=="#") return null;
String[] arr = data.split(",");
Queue<TreeNode> queue = new LinkedList<>();
TreeNode root = new TreeNode(Integer.parseInt(arr[0]));
queue.offer(root);
for(int i=1;i<arr.length;++i){
//每次出队一个 入队两个
TreeNode temp = queue.poll();
//指定左右子节点
if(!arr[i].equals("#")){
TreeNode left = new TreeNode( Integer.parseInt(arr[i]));
temp.left = left;
queue.offer(left);//入队第一个
}
if(!arr[++i].equals("#")){
TreeNode right = new TreeNode( Integer.parseInt(arr[i]) );
temp.right = right;
queue.offer(right); //入队第二个
}
}
return root;
}
}
方法二:前序遍历递归实现(更容易实现)
1、序列化也容易,前序遍历
2、反序列化:
-
将字符串分隔为数组并转换为队列(方便一个一个的按顺序出队列) -
递归函数:出口为#表示的空节点,分别处理左子树和右子树,返回根节点
代码
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
if(root==null) return "#";
String left = serialize(root.left);
String right = serialize(root.right);
return root.val+","+left+","+right; //直接拼接返回 递归yyds
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
List<String> dataList = Arrays.asList(data.split(","));
Queue<String> queue = new LinkedList(dataList);
return helper(queue);
}
private TreeNode helper(Queue<String> queue){
String nodeVal = queue.poll(); //先出根结点
if(nodeVal.equals("#")) return null;
TreeNode root = new TreeNode(Integer.parseInt(nodeVal));
root.left = helper(queue); //再出左子结点
root.right = helper(queue); //再出右子结点
return root;
}
}
3 剑指offer闭眼题
3.1 剑指26. 树的子结构
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。
例如: 给定的树 A:
3
/ \
4 5
/ \
1 2给定的树 B:
4
/
1返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
思路:很巧妙的两层递归
-
第一层递归找到A中与B树根节点相同的那个结点,用或运算递归调用A树的左右子节点 -
第二层递归 逐个判断B树和A树的一个子结构是否相同 直到B树为空
代码:
class Solution {
public boolean isSubStructure(TreeNode A, TreeNode B) {
if(A==null||B==null) return false; //空节点不是任何树的子结构
//第一层递归A树调用子函数 存在即可 找第一个节点
return isSubTree(A,B) || isSubStructure(A.left,B) || isSubStructure(A.right,B);
}
private boolean isSubTree(TreeNode A, TreeNode B){
if(B==null) return true; //B先遍历完 表示B是子结构
if(A==null||A.val!=B.val) return false; //A先为空 或者A B值不等,表示不匹配
//向下递归A B的子节点
return isSubTree(A.left,B.left)&&isSubTree(A.right,B.right);
}
}
3.2 剑指27. 二叉树的镜像
思路:每个结点的左右子树交换位置即可、怎么操作呢? 选一种方式遍历二叉树、对每个结点 交换其左右结点的位置
代码:
class Solution {
public TreeNode mirrorTree(TreeNode root) {
//被鹰啄了眼 只需要交换每一个结点的左右子节点 就自然的完成镜像了
//任选一种遍历方式均可
return traversal(root);
}
private TreeNode traversal(TreeNode root){
if(root==null) return null;
TreeNode left = traversal(root.left);
TreeNode right = traversal(root.right);
//交换root的左右子节点
root.left = right;
root.right = left;
return root;
}
}
3.3 剑指32. 从上到下打印二叉树 III
请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。例如: 给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7返回其层次遍历结果:
[ [3], [20,9], [15,7] ]
思路:和层序遍历一样,内部循环保存一层的所有结点。区别是 设置一个flag标识,交替从集合头部或尾部进入集合。因为链表适合插入所以这里用LinkedList而不是ArrayList集合。注意每循环一次也就是每处理完一层需要将改变flag的值
代码
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
//拿手菜 唯一的区别是进list时交替 一个逆序一个顺序 用linkedList 加入头加入尾
List<List<Integer>> res = new ArrayList<>();
if(root==null) return res;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
boolean flag = true;
while(!queue.isEmpty()){
int length = queue.size();
List<Integer> levelList = new LinkedList<>();
for(int i=0;i<length;i++){
TreeNode tempNode = queue.poll();
if(flag){
levelList.add(tempNode.val);
}else{
levelList.add(0,tempNode.val);
}
if(tempNode.left!=null) queue.offer(tempNode.left);
if(tempNode.right!=null) queue.offer(tempNode.right);
}
flag = !flag;
res.add(levelList);
}
return res;
}
}
3.4 剑指54. 二叉搜索树的第k大节点
给定一棵二叉搜索树,请找出其中第k大的节点。
示例 1:
输入: root = [3,1,4,null,2], k = 1
3
/ \
1 4
\
2输出: 4
思路:二叉搜索树一般用前序遍历,可以直接前序遍历出来数组再找倒数第K个。也可以直接逆选取遍历、设置一个计数标识,找到了第k个自动跳出。
-
计数标识count 和 结果res 都需要定义为全局变量方便储存 -
明明这么简单、我为什么还是做不出来,,
class Solution {
int k;
int res = -1;
int count =0;
public int kthLargest(TreeNode root, int k) {
this.k = k;
//递归调用
findK(root);
return res;
}
private void findK(TreeNode root){
if(root==null) return;
findK(root.right);
count++;
if(count==k) {
res=root.val;
return;
}
findK(root.left);
}
}
4 总结
有一说一,当我把递归遍历和层次遍历基本能够默写之后、还是不能做题;又学了自下而上的分治算法(常用且实现简单)和自上而下的迭代算法,这时候做题也不能一次到位,可能是递归的流程的确称的上是千变万化。
递归的代码确实简单,但很多小细节只有总结了记住了才能迅速AC,不然也会很难办。总结如下吧,愿能常看常新:
二叉树的最大深度等于 其左子树和右子树最大深度的大值 +1
平衡二叉树的条件是左右子树都是平衡二叉树且左右子树高差不超过1(两层递归)
对称二叉树:只有底层节点对称了、才推出其上一层对称、最后推之根节点对称
-
递归出口 叶子节点或者左右子节点不对称 -
递归调用检查左右子节点是否对称,左左右右 左右右左
路径总和为target:
-
递归出口: 当前节点为空 或者 找到叶子节点 -
递归调用左子树是否存在路径 或者 右子树是否存在路径 target-root.val -
如果要存所有路径进集合中,用list集合,思路一样(回溯提高效率)
中序和前序构造二叉树一般右前序找根节点、由中序的map找索引进而得到左右子树的元素个数
-
递归出口:后序数组已经遍历完成 -
分段处理 由后序遍历找到根节点 由中序遍历找到左右子树的节点个数,分别递归获得左右子树
填充每个节点的下一个右侧节点指针:层序遍历是直接给next指针赋值,注意最后一个赋值null
二叉树的最近公共祖先
-
递归出口: root为空 或者 当前root为最近祖先 -
左右分别递归调用。根据返回的结果、判断返回 root或者left或者right或者null
二叉树的序列化与反序列化:推荐递归方式
-
序列化也容易,前序遍历直接拼接返回 递归 yyds -
反序列化:先将所有元素存入 String的队列中,按前序的方法一个一个的取出来。如果为#返回null节点,否则返回有val的节点
树的子结构:很巧妙的两层递归 (和平衡树相似)
-
第一层递归找到A中与B树根节点相同的那个结点,用 或运算 递归调用A树的左右子节点 -
第二层递归 逐个判断B树和A树的一个子结构是否相同 直到B树为空
二叉树的镜像:选一种方式遍历二叉树、对每个结点 交换其左右结点的位置
Z字形从上到下打印二叉树:和层序遍历一致,就是进list集合时分别从尾部进、从头部进,所以注意用LinkedList哦
二叉搜索树的第k大节点:建立全局变量的计数标识count 和 结果res,前序遍历模板把输出变成了一个判断,注意count++
All in all, 我是菜鸡。
以上是关于二叉树遍历-力扣题解的主要内容,如果未能解决你的问题,请参考以下文章