从源码和日志文件结构中分析Kafka重启失败事件
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从源码和日志文件结构中分析Kafka重启失败事件相关的知识,希望对你有一定的参考价值。
从源码中定位到问题的根源
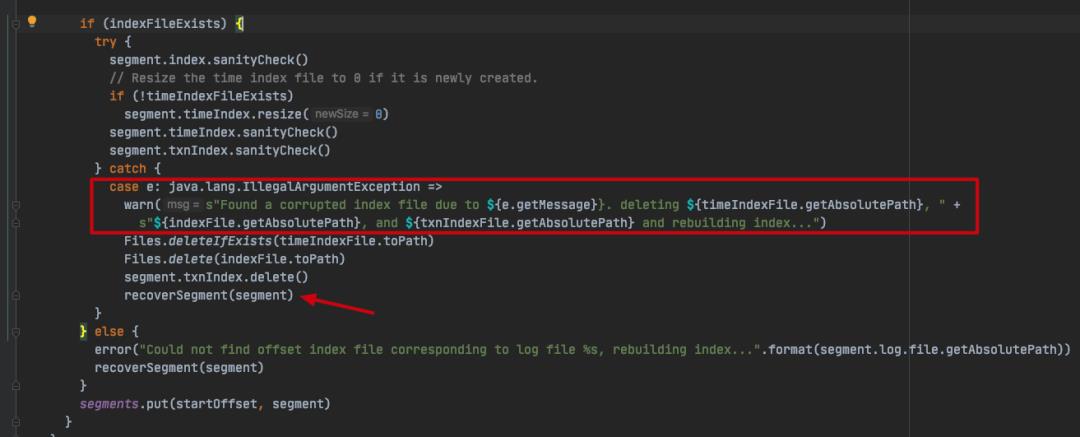
-
log:当前日志 Segment 文件的对象; -
batchs:一个 log segment 的消息压缩批次; -
batch:消息压缩批次; -
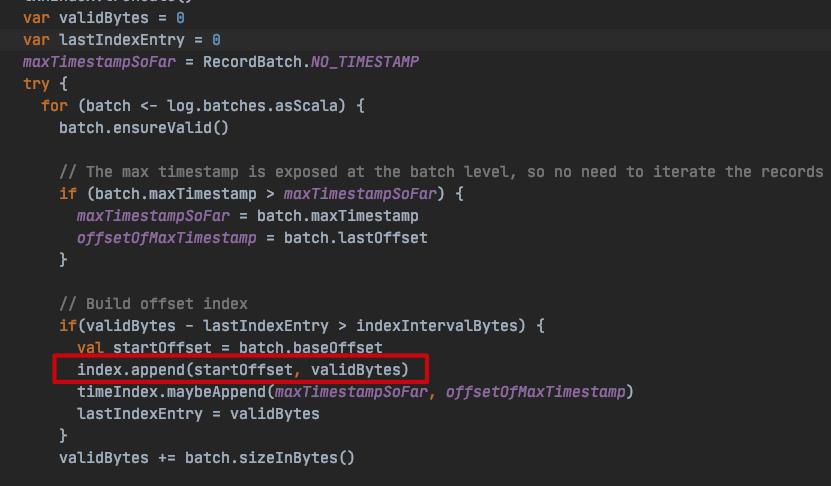
indexIntervalBytes:该参数决定了索引文件稀疏间隔打底有多大,由 broker 端参数 log.index.interval.bytes 决定,默认值为 4 KB,即表示当前分区 log 文件写入了 4 KB 数据后才会在索引文件中增加一个索引项(entry); -
validBytes:当前消息批次在 log 文件中的物理地址。
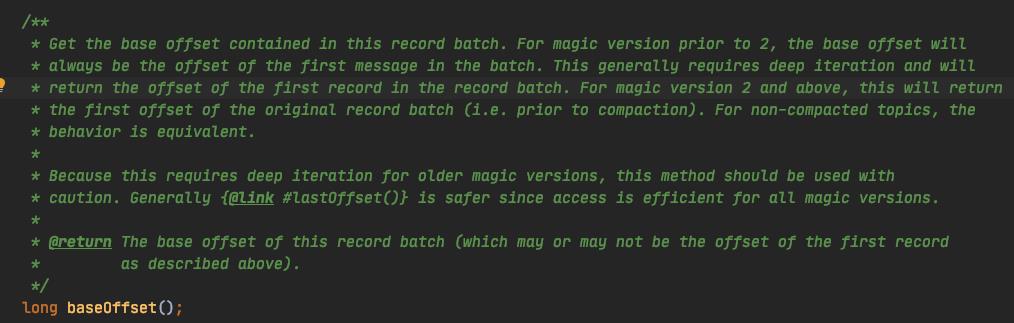
其中最关键的描述是:它可以是也可以不是第一条记录的偏移量。
kafka.log.OffsetIndex#append
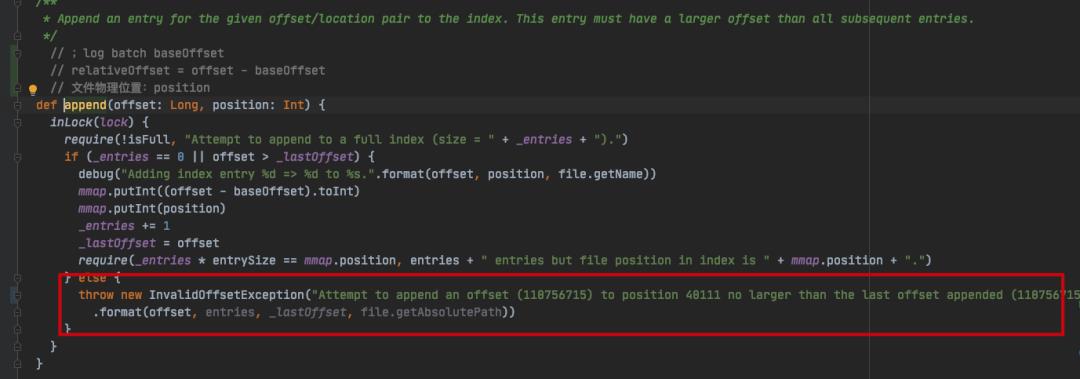
以上是追加索引块核心方法,在这里可以看到 Kafka 异常栈的详细信息,Kafka 进程也就是在这里被异常中断退出的(这里吐槽一下,为什么一个分区有损坏,要整个 broker 挂掉?宁错过,不放过?就不能标记该分区不能用,然后让 broker 正常启动以提供服务给其他分区吗?建议 Kafka 在日志恢复期间加强异常处理,不知道后续版本有没有优化,后面等我拿 2.x 版本源码分析一波),退出的条件是:
_entries == 0 || offset > _lastOffset = false
也就是说,假设索引文件中的索引条目为 0,说明索引文件内容为空,那么直接可以追加索引,而如果索引文件中有索引条目了,需要消息批次中的 baseOffset 大于索引文件最后一个条目中的位移,因为索引文件是递增的,因此不允许比最后一个条目的索引还小的消息位移。
现在也就很好理解了,产生这个异常报错的根本原因,是因为后面的消息批次中,有位移比最后索引位移还要小(或者等于)。
前面也说过了,消息批次中的 baseOffset 不一定是第一条记录的偏移量,那么问题是不是出在这里?我的理解是这里有可能会造成两个消息批次获取到的 baseOffset 有相交的值?对此我并没有继续研究下去了,但我确定的是,在 kafka 2.2.1 版本中,append() 方法中的 offset 已经改成 消息批次中的 lastOffset 了:
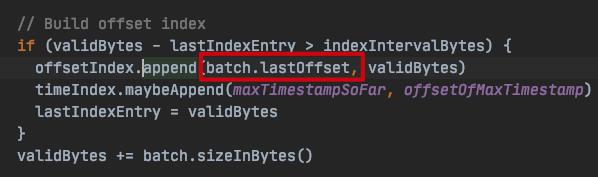
这里我也需要吐槽一下,**如果出现这个 bug,意味着这个问题除非是将这些故障的日志文件和索引文件删除,否则该节点永远启动不了,这也太暴力了吧?**我花了非常多时间去专门看了很多相关 issue,目前还没看到有解决这个问题的方案?或者我需要继续寻找?我把相关 issue 贴出来:
https://issues.apache.org/jira/browse/KAFKA-1211
https://issues.apache.org/jira/browse/KAFKA-3919
https://issues.apache.org/jira/browse/KAFKA-3955
严重建议各位尽快把 Kafka 版本升级到 2.x 版本,旧版本太多问题了,后面我着重研究 2.x 版本的源码。
下面我从日志文件结构中继续分析。
从日志文件结构中看到问题的本质
我们用 Kafka 提供的 DumpLogSegments 工具打开 log 和 index 文件:
$ ~/kafka_2.11-0.11.0.2/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /dfs5/kafka/data/secLog-2/00000000000110325000.log > secLog.log
$ ~/kafka_2.11-0.11.0.2/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /dfs5/kafka/data/secLog-2/00000000000110325000.index > secLog-index.log
用 less -Nm 命令查看,log 和 index 对比:
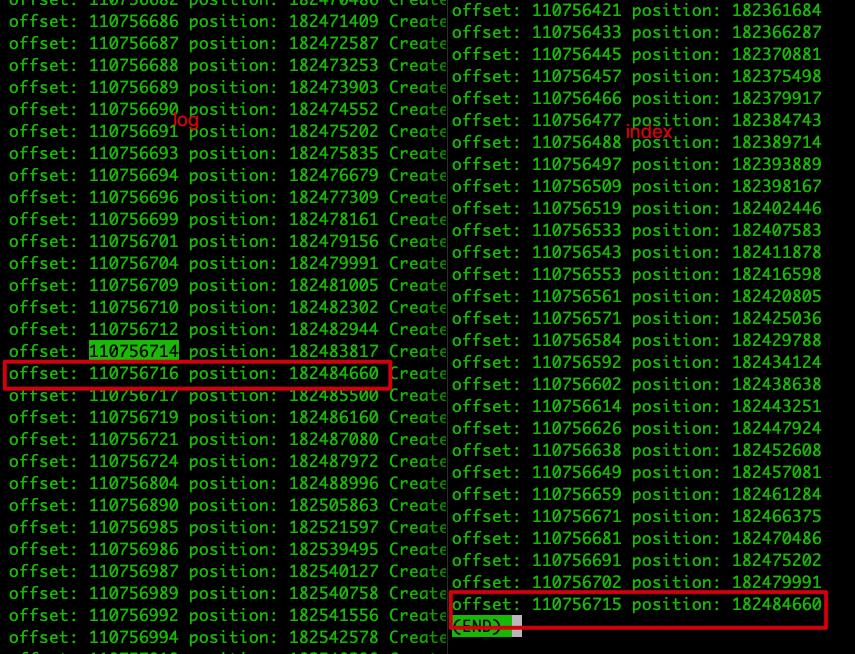
如上图所示,index最后记录的 offset = 110756715,positioin=182484660,与异常栈显示的一样,说明在进行追加下一个索引块的时候,发现下一个索引块的 offset 索引不大于最后一个索引块的 offset,因此不允许追加,报异常并退出进程,那么问题就出现在下一个消息批次的 baseOffset,根据 log.index.interval.bytes 默认值大小为 4 KB(4096),而追加的条件前面也说了,需要大于 log.index.interval.bytes,因此我们 DumpLogSegments 工具查询:
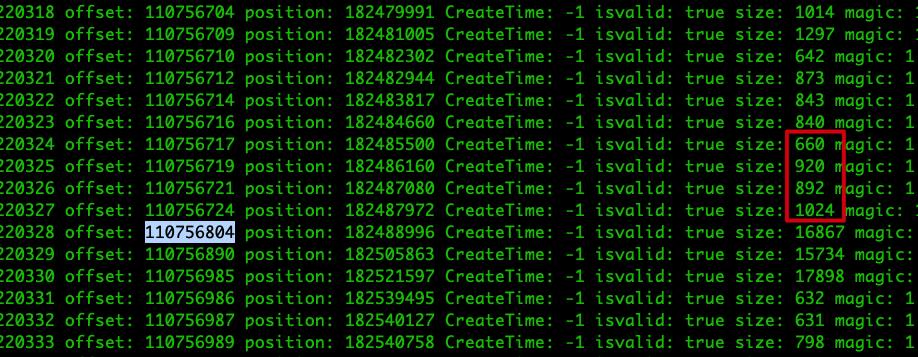
从 dump 信息中可知,在 positioin=182484660 往后的几个消息批次中,它们的大小加起来大于 4096 的消息批次的 offset=110756804,postion=182488996,它的 baseOffset 很可能就是 110756715,与索引文件最后一个索引块的 Offset 相同,因此出现错误。
接着我们继续用 DumpLogSegments 工具查看消息批次内容:
我们先查看 offset = 110756715,positioin=182484660 的消息块详情:

接着寻找 offset = 110756715,的消息批次块:

终于找到你了,跟我预测的一样!postion=182488996,在将该消息批次追加到索引文件中,发生 offset 混乱了。
总结
如果还是没找到官方的处理方案,就只能删除这些错误日志文件和索引文件,然后重启节点?非常遗憾,我在查看了相关的 issue 之后,貌似还没看到官方的解决办法,所幸的是该集群是日志集群,数据丢失也没有太大问题。
我也尝试发送邮件给 Kafka 维护者,期待大佬的回应:
不过呢,0.11.0.2 版本属于很旧的版本了,因此,升级 Kafka 版本才是长久之计啊!我已经迫不及待地想撸 kafka 源码了!
在这个过程中,我学到了很多,同时也意识到想要继续深入研究 Kafka,必须要学会 Scala,才能从源码中一探 Kafka 的各种细节。

觉得不错,请点个在看呀
以上是关于从源码和日志文件结构中分析Kafka重启失败事件的主要内容,如果未能解决你的问题,请参考以下文章
从FFmpeg输出日志中分析问题原因——记一次输出流顺序异常
从FFmpeg输出日志中分析问题原因——记一次输出流顺序异常
从FFmpeg输出日志中分析问题原因——记一次输出流顺序异常
从FFmpeg输出日志中分析问题原因——记一次输出流顺序异常