分布式事务的前世今生(全篇)
Posted 大魏分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务的前世今生(全篇)相关的知识,希望对你有一定的参考价值。
分布式事务产生的原因
要搞清分布式事务,我们先想一个问题,分布式事务产生的原因是什么?
如图所示:
那么,我们如何实现分布式事务呢?根据分布式系统的CAP理论,要么是CP模式,要么是AP模式。三个无法同时实现。
CP是在保证数据强一致性前提下,尽量实现高可用(如过半写入)。
AP是在保证高可用的前提下,尽量实现数据一致性(如异步一致)。
在ACID里,I是最难实现的。Isolation包含四个层级,如下表所示。在XA中,一般可以做到RC就可以了。
| 事务隔离级别 | 事务隔离描述 | 解决的问题 | 不能解决的问题 |
| 最低1 | Read Uncommitted | 无 | 脏读 |
| 2 | Read Committed | 脏读 | 不可重复读 |
| 3 | Repeated Read | 脏读、不可重复读 | 幻读 |
| 最高4 | Serialization | 脏读、不可重复读、幻读 | 无 |
对于mysql而言,它是通过RC+MVCC实现RR的效果。但ACID整体上是不靠谱的,为啥?
因为ACID只是满足数据隔离性,但没有做法并发控制。
分布式事务真实使用场景
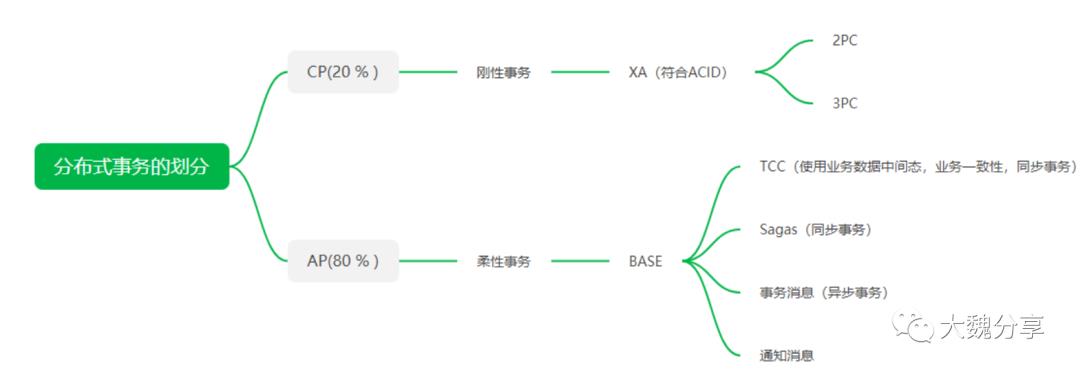
如果面向于实际使用场景,我们把上图分布式实现区分一下,结果如下:
也就是说,真实分布式场景中,80%是柔性事物,20%是刚性事务,即使在金融行业,也是这样。刚性事务通过2PC实现;柔性事物同步模式通过Sagas实现,异步模式通过事务消息实现。
分布式事务-刚性事务-2PC的实现原理
我们先看一下刚性事务的最终实现:2PC。如下图所示。在下图中,RM管理共享资源,如DB。TM负责管理全局事务,如分配事务唯一标识、监控事务的执行进度、并负责事务的提交、回滚、失败、恢复等。
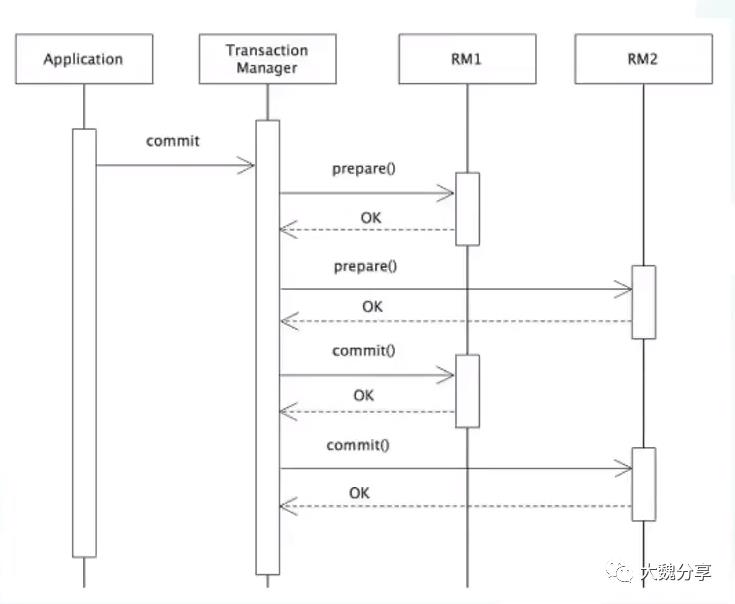
2PC的缺点在于:它是同步阻塞模型、数据库锁定时间过长、全局锁(隔离级别串行化)并发低、不适合长事务场景(RM特别多的情况)。
3PC没有安全解决2PC的问题,但又引入了新的问题。由于实际场景几乎没人使用,因此我不做介绍。
分布式事务-柔性事务
在介绍了刚性事务2PC后,接下来我们介绍柔性事务。柔性事物的理念是BASE。
BASE理论指的是:
Basically Available(基本可用)
Soft state(柔性状态--->中间状态:业务中间态、数据中间态)
Eventually consistent(最终一致性)
我们举一个数据中间态的例子。一个转账业务,我们给转账业务数据分成两部分:可用金额要和冻结金额(并不是说,转账业务一定要按照下面模式设计,只是当对一致性要求比较高的时候,用下面的模式)。

分布式事务-柔性事务-BASE-Saga
接下来,我们看柔性事物的实现,先看Saga。
Saga本质是将一个分布式事务分为多个本地事务。每个本地事务只有执行和补偿。我们拿银行业余来说,有转账业务,转账业务的补偿事务就是:转账冲正,如下图所示。如果转账失败,就调用转账冲正进行事务补偿。
、
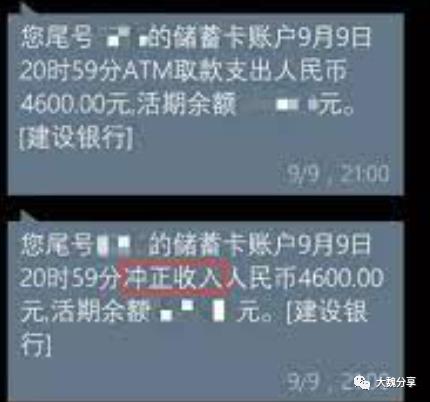
Saga的恢复模式分为:向后恢复(逆向补偿)和向前恢复(重试失败的事务)。
Sagas
业务逻辑层:基于AOP实现Proxy。@around
逻辑事务层增加注解,开启全局事务。
数据访问层:基于原则接口方法,在方法名加注释补偿方法名。@compensable(cancelMethod...)
Saga的开源实现:
ServiceComb(需要使用整套微服务,才能使用其中的Saga)
Seata,阿里开源的。SeataAT是Saga的优雅实现(使用状态机实现。上面的案例使用AOP实现)
在隔离性方面,Sagas隔离是通过业务中间态实现的。例如金融系统的中间账户。
例如郭德纲向大魏转账,真实模式是:
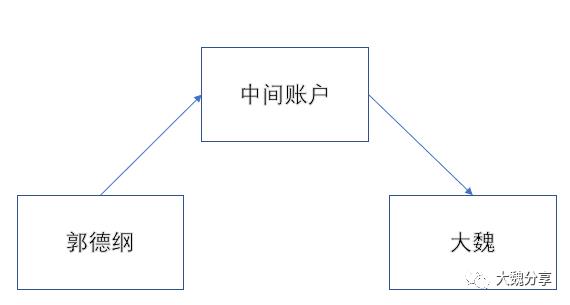
郭德纲向中间账户转账失败,那么中间账户会删除记录。如果一段时间没删除,例如5s,那么中间账户就会想大魏转账。
前面提到的转账和冲正是互为逆方法。同样,CRUD中,insert和delete也是互为逆方法。因此我们需要为update操作提供逆方法。
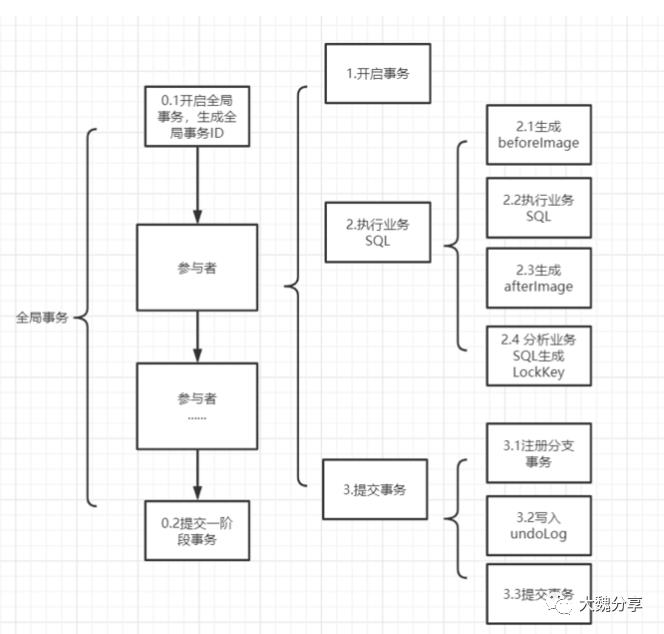
那么,如何为update提供优雅的事务补偿呢?使用Seata AT。Seata AT就是在Sagas的基础上实现了自动补偿。目前自动补偿的方案都是往这个方向努力,看谁支持的 sql 语法更多,支持的db类型更多。
Seata AT实现的方法如下图:
刚性事务与柔性事务的对比
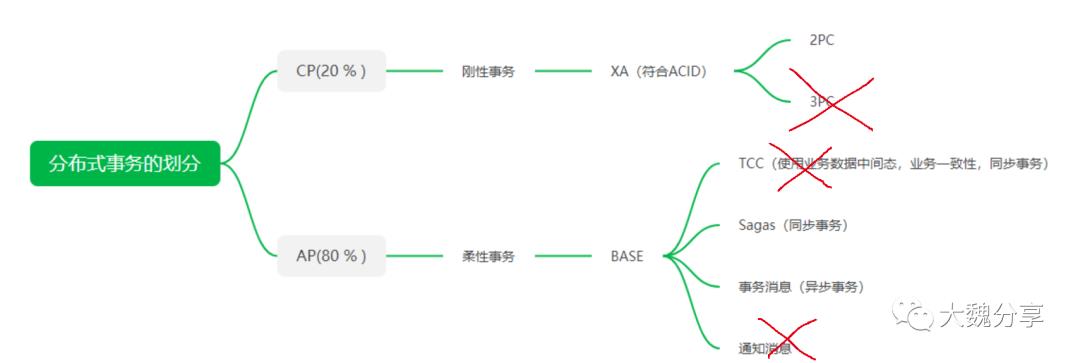
经过上面内容的介绍,我们将分布式事务分类图进行进一步细化。
分布式事务的分类如下:
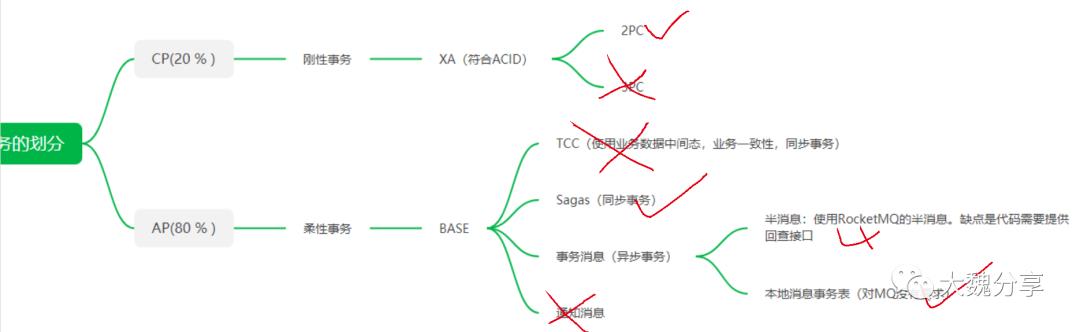
我们首先对刚性事务和柔性事务进行对比如下。
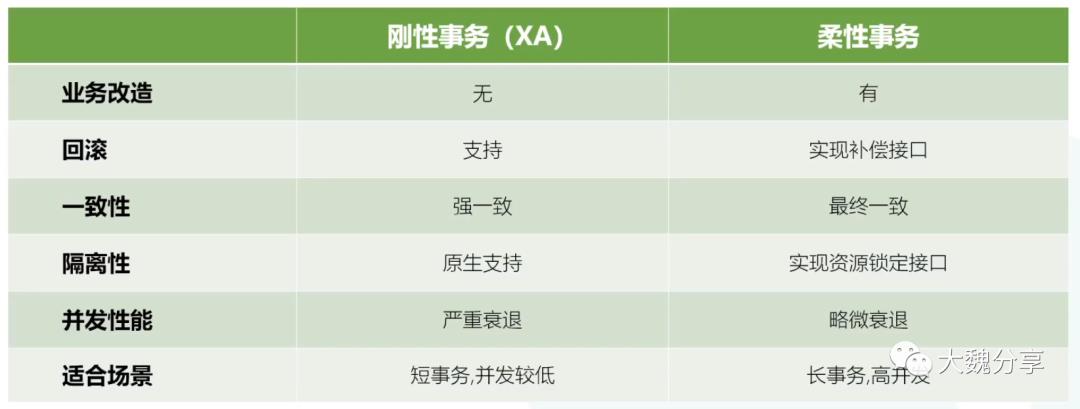
在柔性事物中,在柔性事物中,当业务失败还没来得及补偿时,是容易出现脏读的。隔离性支持到RU就可以。
分布式事务-BASE-事务消息的实现-半消息
大家不要认为金融行业的分布式事务一定是强一致的,实际情况中,强一致的比率不是特别高。例如蚂蚁金服2PC也没有大于20%。例如转账,用Saga、2PC都成。
那么,我们我们看一下事务消息的实现原理。
事务消息解决的是什么问题?我们先看一个常见的场景。
一个分布式事务由两个本地事务组成。两个事务之间有个MQ。A事务执行成功后(1),向MQ发送消息(2)。然后B事务消费消息(3)并执行本地事务(4)。
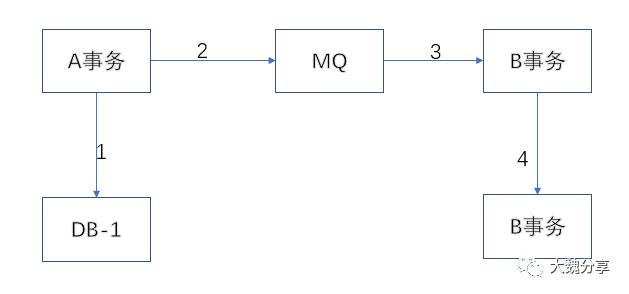
那么,事务消息解决的是什么问题呢?它解决的步骤1和步骤2的原子性问题。也即是说,把事务A写数据库和往MQ发消息这两件事,捏成一个原子事务。两件事要么一起成功、要么一起失败(下图篮圈)。
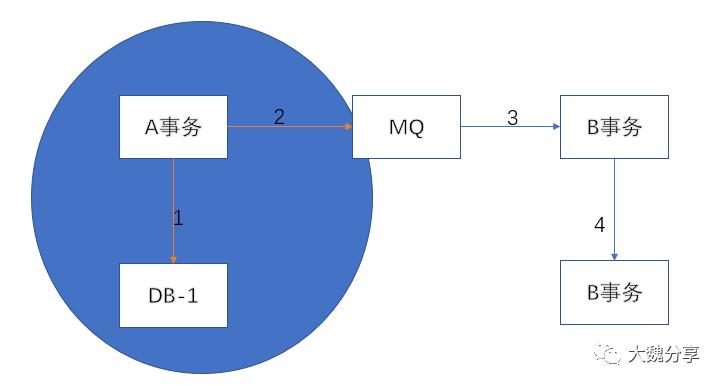
而分布式事务保证的是什么?是步骤1、2、3、4这四件事的原子性。也就是说,这四件事要么一起成功、要么一起失败(下图黄圈)。
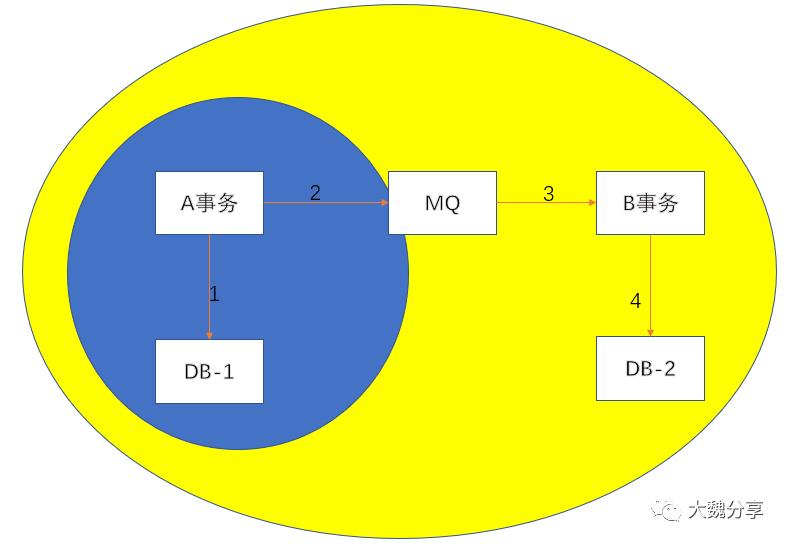
所以说:事务消息不是分布式事务。但它大大简化了事务分布式模型。它将两次RPC调用(一次分布式事务至少两次RPC调用)简化成RPC+发消息。因此事务消息对业务非常友好。
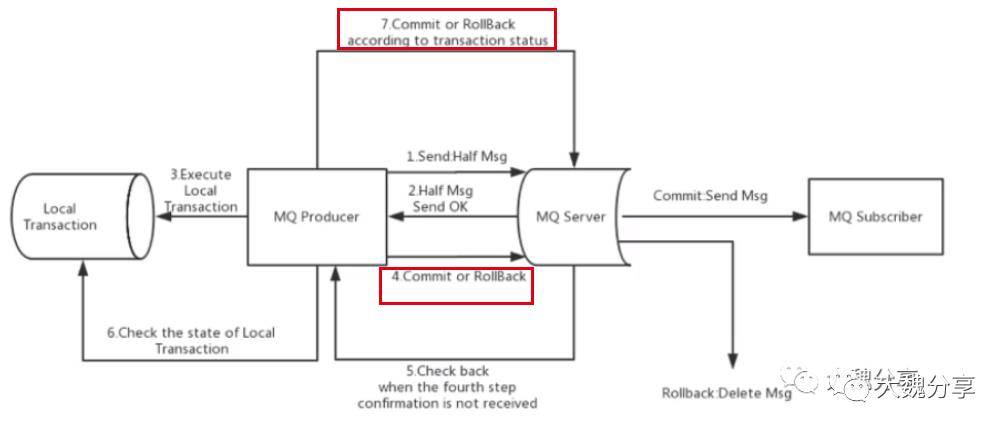
具体实现如下图所示:
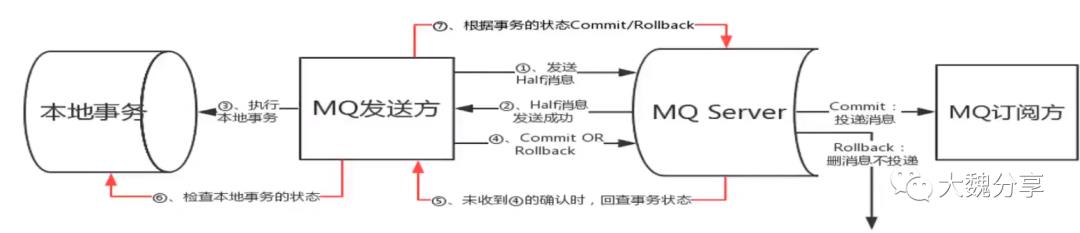
接下来,我们就上图步骤进行分析:
MQ Producer(是业务逻辑)发送半消息给MQ Server。半消息的特点是:不会被消费,先存在MQ里。
MQ Server告诉MQ Producer,半消息发送成功(这个通知是同步交付)。
访问数据库、执行本地事务。然后MQ Server把消息投递给MQ Subscriber。
MQ Producer告诉MQ Server,投递还是不投递消息。例如告诉MQ Server投递,那么MQ Server把半消息变成确认消息,进行消息投递。
MQ Server没有收到步骤4的确认,就回查MQ Producer,看消息是否需要投递。
MQ Producer查数据库,看此前本地事务是否提交、是否成功。
MQ Producer根据在数据库的查询结果,告诉MQ Server提交还是Rollback。然后MQ Server决定是丢弃还是投递消息。如果步骤1中,MQ Producer发送半消息后,MQ Producer挂了或者因为一些原因本地事务执行失败,那么步骤5-6回查,发现事务未成功,就会把半消息从MQ Server中删除。
京东购物24小时未支付订单自动取消的截图:
分布式事务-BASE-事务消息的实现-半消息-RocketMQ的实现
关于RocketMQ通过半消息实现事务消息原理,我们可以看得更细致些。
我们知道,在普通的MQ中,消息生产者将消息写入到CommitLog,然后Dispatcher将消息的索引信息放到Topic中以便消费者消费。那么,RocketMQ如何实现半消息?也就是消息放到Topic中不被消费?
RocketMQ有一个半消息Topic:RMQ_SYS_TRANS_HALF_TOPIC,它用于临时存放消息信息。这个Topic对消息消费者不可见。也就是说,消息生产者向Commitlog写入的如果是事务消息,Dispacher看到消息有transaction的标签,就会将消息的索引发送到RMQ_SYS_TRANS_HALF_TOPIC。也就是主题和队列名被替换了。但被替换的队列和主题名信息,会和索引一起存在RMQ_SYS_TRANS_HALF_TOPIC中。
除了半消息外,还有个OP消息主题RMQ_SYS_TRANS_OP_HALF_TOPIC。这个主题记录二阶段操作。OP消息包含如下两种:Rollback(只做记录)和Commit(根据备份信息重新构造消息并投递)。如下图所示其位置:
回查:对比HALF消息和OP消息主题。他们之间的差,就是需要回查的消息。如下图所示逻辑。
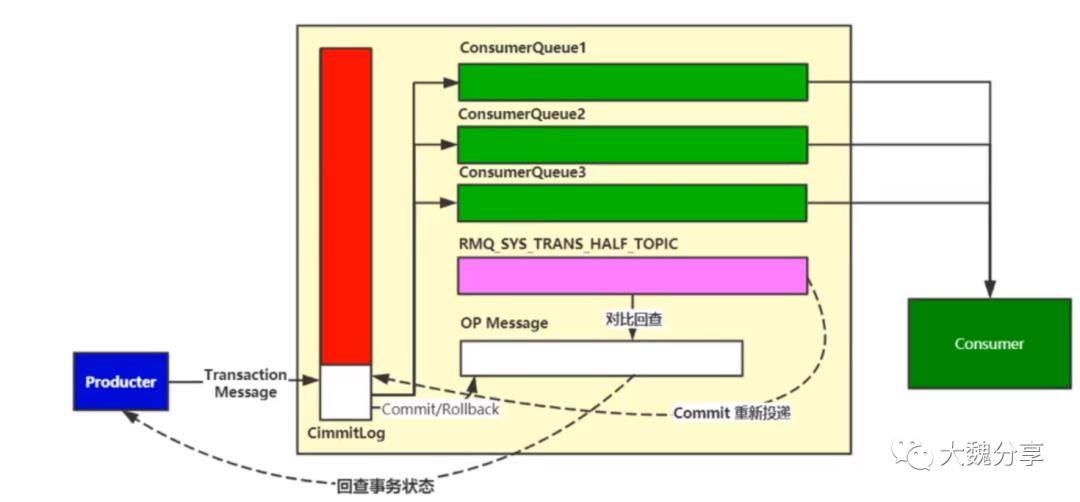
我们根据上图将半消息进行分析:
生产者发送事务消息,写到CommitLog。Dispatcher将其索引放入到RMQ_SYS_TRANS_HALF_TOPIC
消息生产者发送OP消息,这个消息先写入到CommitLog,然后被Dispatch到RMQ_SYS_TRANS_OP_HALF_TOPIC。
如果OP消息是Commit,MQ会将对这个半消息在CommitLog进行重构,然后再有Dispatcher重新投递到消费队列中。
MQ对比RMQ_SYS_TRANS_OP_HALF_TOPIC和RMQ_SYS_TRANS_HALF_TOPIC两个队列,在后者超时的消息,到前者进行回查。到消息生产者回查事务状态(DB)。
然后消息生产者再度发送OP消息(针对回查结果Commit还是Rollback)
重新投递到消费队列中的消息被消费者消费。
事务消息需要业务方提供回查接口,对业务侵入较大。
在上面的方案中,所有事务一致性的保证,都由RockerMQ完成,就必然会有回查,业务就需要提供回查接口。
使用RocketMQ优点是方案通用,缺点是:需要业务代码实现消息回查,增加开发的工作量;发送消息幂等;消费端需要处理幂等。
因此,方案2是使用本地消息事务表。
分布式事务-BASE-事务消息的实现-事务消息表
我们可以通过客户端来保证事务的一致性。也就是说,在本地DB中放一个消息表,通过本地事务管理器维护事务消息表(扫描发送、清理)。

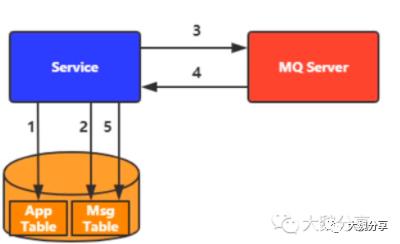
但是,上图只是实现了分布式事务的异步方式(有MQ),没有同步方式。接下来,我们看同时实现分布式事务同步和异步的模型。
柔性分布式事务的终极实现:Sagas+事务消息表
关于这种方式的实现,我们举例子说明。这是分布式事务的终极模型,也就是说,既能实现同步分布式事务(Saga),也能实现异步分布式事务(事务消息表)。
先看一张图:
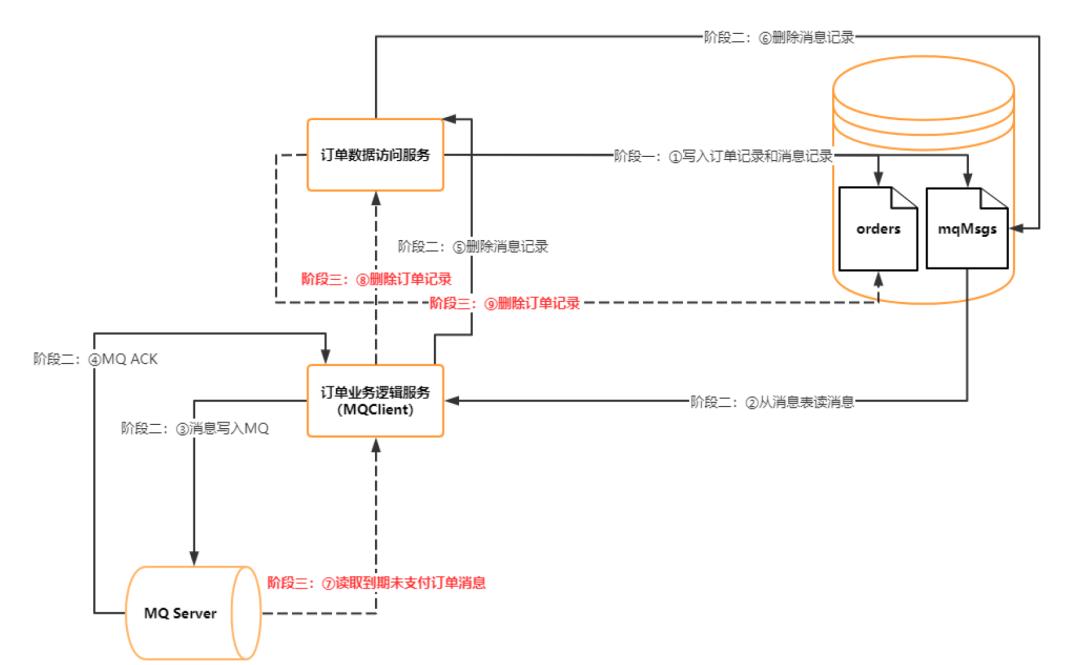
我们结合京东购物场景看这张图:
在京东买大魏的书,放在购物车里,然后到支付界面。有哪位书太贵,犹豫了,没再操作。这时候,业务系统做的事情是:订单数据服务在两个DB表里写入信息,一个是orders表,同一个是mqMsgs,也就是消息表。表中存放的,就是支付消息。这两个表的写操作,在同一个数据库链接里完成。因此这两个表的写操作,就是一个本地事务。
订单业务逻辑服务从DB消息表中读取消息,写入到MQ中,这是通过起定时任务实现的(它是个子线程),业务逻辑层有MQClient。这个定时任务就是从DB表读信息,投递到MQ上。
MQ Server给订单逻辑服务返回ACK。
MQ给订单逻辑服务发ACK
订单业务逻辑调用订单数据访问服务,发起删除消息记录。
订单数据服务操作DB中的消息表,删除表中的数据。===>消息投递成功,就删除DB消息表中的记录。
订单业务逻辑从MQ中读取订单到期未支付消息(京东是24小时)。
订单业务逻辑服务调用订单数据服务,删除订单记录。
订单数据服务操作数据库表,删除数据库中orders表中的订单记录。
总结来说,上面的路子是:将向MQ发送消息的操作,通过AOP篡改为写DB,然后再通过业务逻辑层的定时任务定期从DB消息表中读消息并且放到MQ。
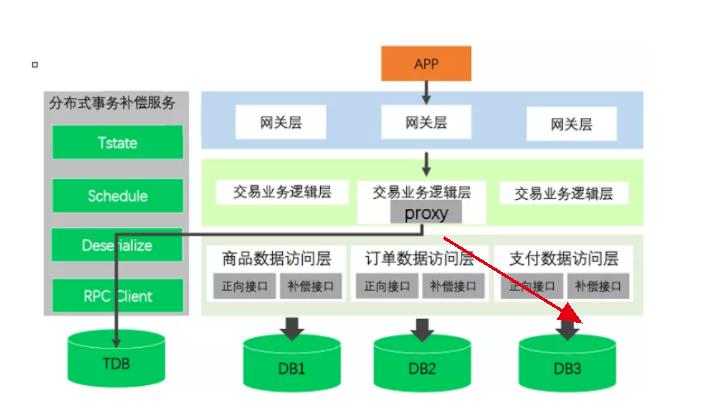
柔性分布式事务的终极实现:Sagas+事务消息表:架构分析
我们再举一个京东网购退货的例子:
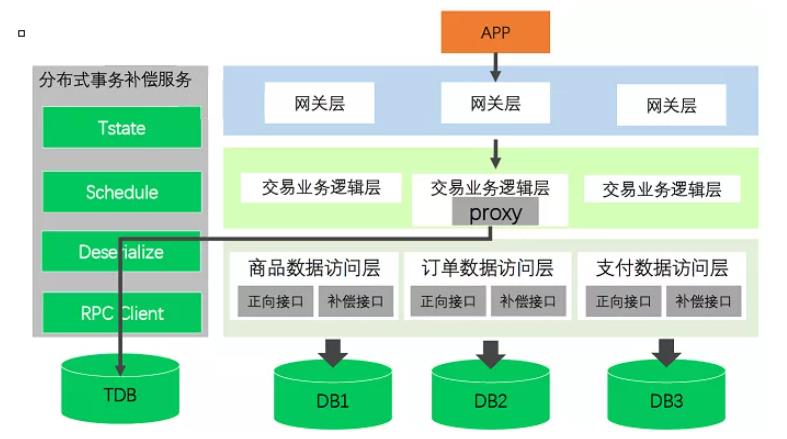
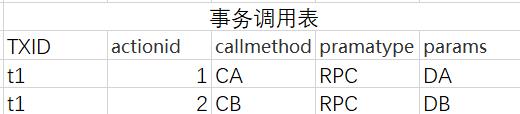
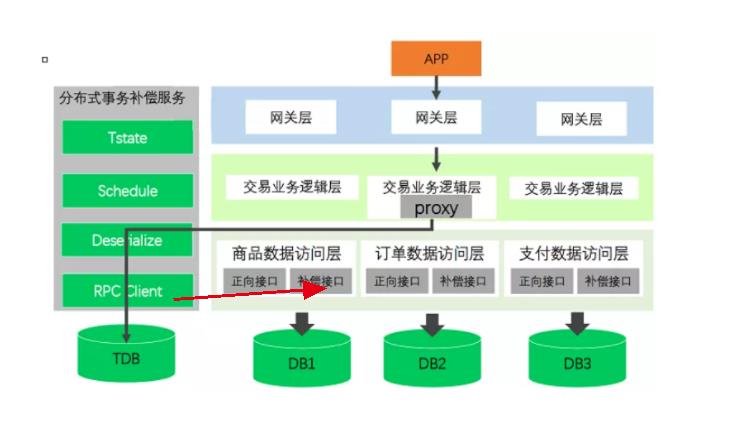
在上图中,TDB会有两个表。也就是说,事务补偿能够成功实现,主要靠TDB中的这两张表!:
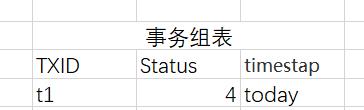
事务状态表(记录事务组状态;txid、state、timestap)、
事务调用组表(记录事务组中每一次调用和相关参数;txid、actionid、callmethod、pramatype、params)。
接下来,我们介绍上面两个表每个字段的含义:txid是主键、state表示事务状态(例如:1开始 2成功 3失败 4补偿成功 )、actionid是操作次数的id、callmethod是补偿接口、调用服务的类型(如web/RPC)、params是具体数据包的调度参数。
而事务补偿,就是当事务调用失败,事务拦截器修改事务组状态(state)。然后由TM发起,分布式事务补偿服务异步执行补偿。
上面的内容比较抽象,我们结合场景进行说明,还是以下图为例。
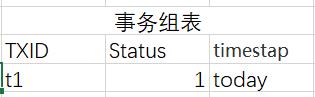
大魏在京东购物,这是一个分布式事务。这个时候,proxy生成事务组表的一行数据,并且记录(t1代表分布式事务1):
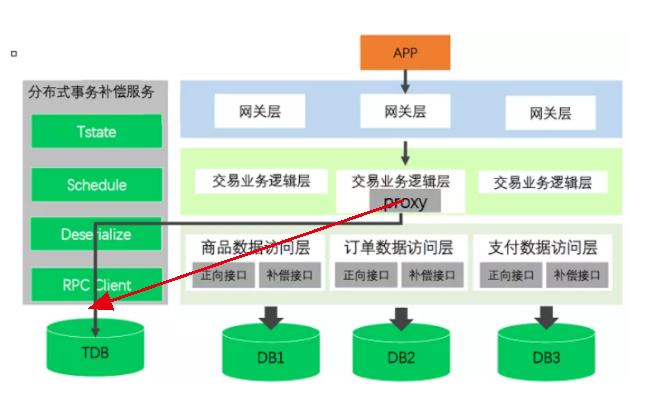
接下来,要正式干活儿了。Proxy记录事务A的调用信息,写入事务组表:

记录完毕后,A做本地事务:
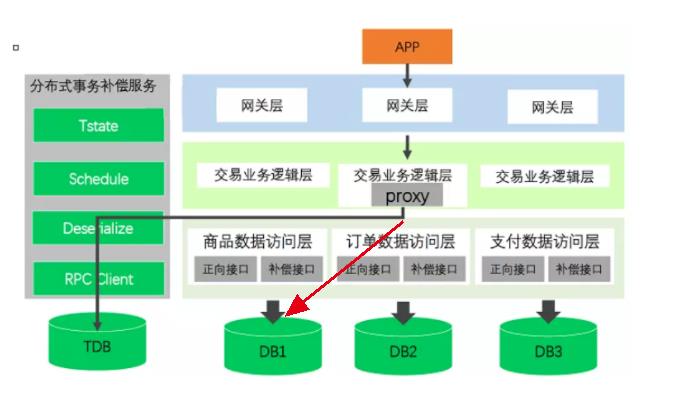
A执行成功后,Proxy用类似的方式管理B,以此类推C。
Proxy在事务调用表中记录B的调用内容:
B本地事务执行:
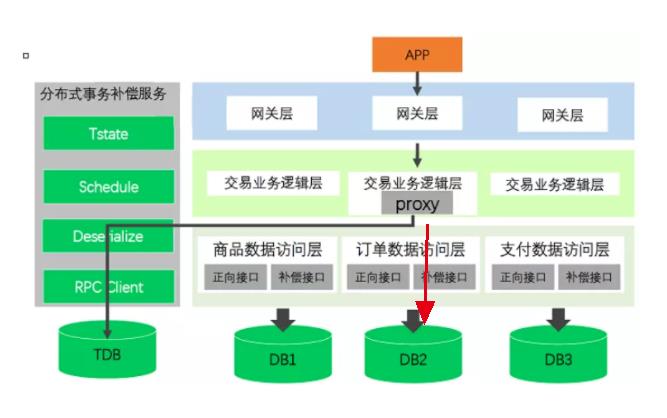
Proxy在事务调用表中记录C的调用内容:
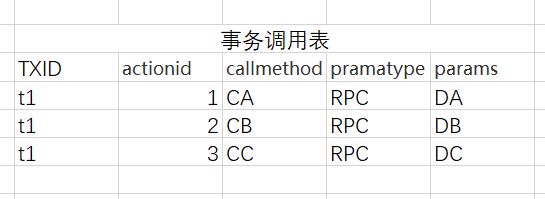
然后C执行。
当C本地事务执行成功后,Proxy将会修改TDB中的信息:
修改前:
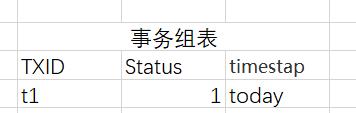
修改后:
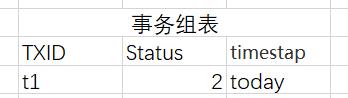
也就是说,标记分布式事务执行成功。
但是,如果在上面的步骤中,C执行失败呢?
首先,Proxy会将TDB中的事务组表进行如下修改,将状态从1开始修改为3失败:
修改前:
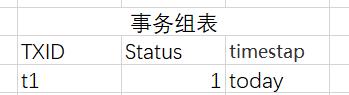
修改后:
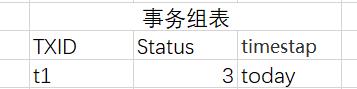
接下来,Schedule(即TM)会扫描到(定期扫描)t1失败(状态为3)。然后Schedule发现T1在事务调用表有2个关联的本地事务(C做失败已经自动rollback)
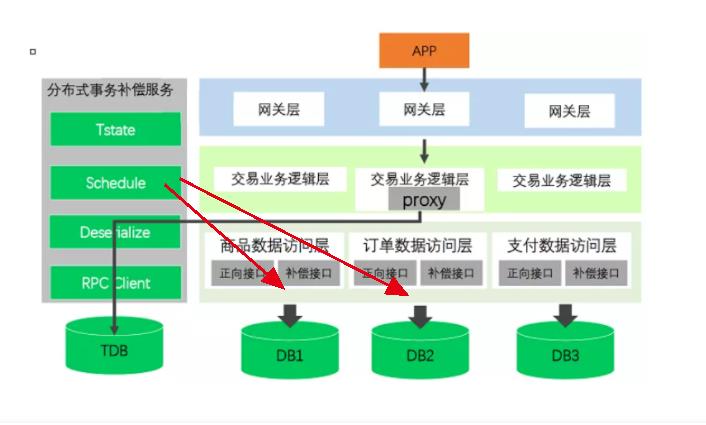
接下来,根据事务调用表中的pramatype字段,RPC Client调用补偿接口,对事务进行补偿。
先补偿B:
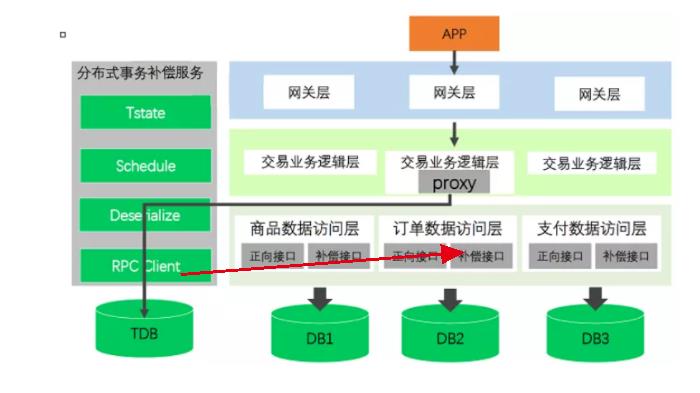
再补偿A:
最后,补偿完毕后,proxy修改TBD中的事务组表,将state从3改成4,代表补偿成功。
柔性分布式事务的终极实现:Sagas+事务消息表:案例分析
我们上述逻辑,结合业务逻辑组件进行结合。这次我们把业务逻辑模块换一下。京东购物,选中货物后,库存会被锁住(A)、然后支付的时候,会选择红包或者京东卡,会有减红包或减京东卡余额的操作(C)、最后成功创建订单(C)。
具体参考下图:
以上是关于分布式事务的前世今生(全篇)的主要内容,如果未能解决你的问题,请参考以下文章