MySQL 深入剖析Explain
Posted php技术爱好者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 深入剖析Explain相关的知识,希望对你有一定的参考价值。
作为一个程序员,平时工作中多少担任着一些运维开发工作;自从入职新公司起,每天都能频繁的看到运维监控群里的报警信息,如下:
【阿里云监控】应用分组-RDS实例组-1个实例发生报警, 触发规则:CpuUsage_80.0 19:29 华北2(北京)-云数据库RDS版[RDS常规实例-xxxx] ,CPU使用率(100>=80 ),持续时间14分钟 ,实例详情 目前共有1个问题实例,详情查看故障列表
这种情况,作为一个有着极强责任心的我来说,我能允许这种情况发生?
于是就开始致力于SQL的优化工作,大体会从以下方面着手:1、查看慢日志,并使用explain分析,定位慢的原因;2、查看其他数据库的负载,确认是不是流量分配不均匀;3、同一时间是否有大批量的定时作业同时工作;
经过一番排查,果然发现了问题
1、确实有很多慢查询,而且95%以上的慢查询都落在主库上。主要是因为早期后台业务系统为了能实时的看到数据的变更,直接连到主库进行查询。还有就是早期没有BI系统,很多的报表查询(往往涉及到多表查询)也都是直接连接主库进行查询,经常看到查询时间在100s,200s以上的,主库不报警才怪!
2、主库的负载长期保持在70%左右,经常性的高达90%甚至100%,而3台从库的负载则一直在20%左右;
3、因为是后台业务系统,必然会涉及到定时作业。发现有很多任务执行时间在10min以上,甚至动不动就执行半个小时,一个小时左右。
既然发现问题,那就好解决了
1、首先把查询进行分散,充分利用线上数据库资源,避免所有慢查询都落到主库上;
2、根据explain的结果对sql进行优化,主要优化方式是在查询列上添加适当的索引、对一些复杂的sql进行拆分或者建立统计中间表;
3、找出执行时间长的脚本,尽量把脚本的执行时间分散,避免同一时间大批量任务同时运行的情况;代码review,分析脚本执行慢的原因并解决;
经过两个周左右的持续优化,现在在运维报警群里几乎看不到了DB的报警,线上各DB的负载基本稳定的保持在20%-50%之间!
Explain字段说明
下面就分享一下如何利用Explain进行SQL优化,以及对Explain执行结果中的字段进行深入剖析:
| 项 |
说明 |
| id | SELECT的查询序列号(一般有union,join,或者子查询的时候,就显示1,2了)
|
| select_type查询类型 |
说明 |
SIMPLE |
简单SELECT,不使用UNION或子查询等 |
| PRIMARY | 子查询中最外层查询,查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY |
| UNION | UNION中的第二个或后面的SELECT语句 |
DEPENDENT UNION |
UNION中的第二个或后面的SELECT语句,取决于外面的查询 |
| UNION RESULT | UNION的结果,union语句中第二个select开始后面所有select |
| SUBQUERY | 子查询中的第一个SELECT,结果不依赖于外部查询 |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT,依赖于外部查询 |
| DERIVED | 派生表的SELECT, FROM子句的子查询 |
| UNCACHEABLE SUBQUERY | 一个子查询的结果不能被缓存,必须重新评估外链接的第一行 |
| 项 |
说明 |
| table | 输出结果集的表,有时不是真实的表名字,可能是简称,也可能是第几步执行的结果的简称。 |
| 项 |
说明 |
| partitions | mysql5.6以上版本才有该列,该列显示的为分区表命中的分区情况。非分区表该字段为空(null) |
| type 重要的项,显示连接使用的类型,按最优到最差的类型排序 | 说明 |
| system | 表仅有一行(系统表)。这是 const 连接类型的一个特例。 |
| const | const 用于用常数值比较 PRIMARY KEY 时。当 查询的表仅有一行时,使用 System。 |
| eq_ref | 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件 |
| ref | 连接不能基于关键字选择单个行,可能查找到多个符合条件的行。叫做 ref 是因为索引要跟某个参考值相比较。这个参考值或者是一个常数,或者是来自一个表里的多表查询的结果值。 |
| ref_or_null | 如同 ref,但是 MySQL 必须在初次查找的结果里找出 null 条目,然后进行二次查找。 |
| index_merge | 说明索引合并优化被使用了。 |
unique_subquery |
在某些 IN 查询中使用此种类型,而不是常规的 ref:value IN (SELECT primary_key FROM single_table WHERE some_expr) |
| index_subquery | 在 某 些 IN 查 询 中 使 用 此 种 类 型 , 与 unique_subquery 类似,但是查询的是非唯一 性索引: value IN (SELECT key_column FROM single_table WHERE some_expr) |
| range | 只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引。当使用=、 <>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比较关键字列时,可 以使用 range。 |
index |
全表扫描,只是扫描表的时候按照索引次序进行而不是行。主要优点就是避免了排序,但是开销仍然非常大。 |
| all | 最坏的情况,从头到尾全表扫描。 |
| 项 | 说明 |
| possible_keys | 查询可能使用到的索引都会在这里列出来,如果没有任何索引显示 null 。 |
| 项 | 说明 |
| key | 查询真正使用到的索引,必然包含在possible_keys中,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。 |
| 项 | 说明 |
| key_len |
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度) |
| 项 |
说明 |
| rows | 这里是执行计划中估算的扫描行数,不是精确值 |
| Extra项 |
说明 |
distinct |
在select部分使用了distinct关键字; |
| no tables used | 不带from字句的查询或者From dual查询; |
| using filesort | 排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中; |
| using index | 查询时不需要回表查询,直接通过索引就可以获取查询的数据; |
| Using index condition | 查找使用了索引,但是需要回表查询数据。 |
| using join buffer(block nested loop),using join buffer(batched key access) | 5.6.x之后的版本优化关联查询的BNL,BKA特性。主要是减少内表的循环数量以及比较顺序地扫描查询; |
| using sort_union,using_union,using intersect,using sort_intersection | using intersect:表示使用and的各个使用索引的条件时,该信息表示是从处理结果获取交集 using union:表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集 using sort_union和using sort_intersection:与前面两个对应的类似,只是他们是出现在用and和or查询信息量大时,先查询主键,然后进行排序合并后,才能读取记录并返回; |
| using temporary | 用临时表保存中间结果,常用于GROUP BY 和 ORDER BY操作中,一般看到它说明查询需要优化了,就算避免不了临时表的使用也要尽量避免硬盘临时表的使用。临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量,used_tmp_table, used_tmp_disk_table才能看出来; |
| using where | 表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。查询条件中分为限制条件和检查条件,5.6之前,存储引擎只能根据限制条件扫描数据并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。5.6.x之后支持ICP特性,可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition; |
| firstmatch(tb_name) | 5.6.x开始引入的优化子查询的新特性之一,常见于where子句含有in()类型的子查询。如果内表的数据量比较大,就可能出现这个; |
| loosescan(m..n) | 5.6.x之后引入的优化子查询的新特性之一,在in()类型的子查询中,子查询返回的可能有重复记录时,就可能出现这个。 |
Explain实例分析
CREATE TABLE `customer` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(64) NOT NULL DEFAULT '' COMMENT '客户姓名',`address` varchar(255) NOT NULL DEFAULT '' COMMENT '客户地址',`phone` varchar(32) NOT NULL DEFAULT '' COMMENT '客户电话',`gender` varchar(8) NOT NULL DEFAULT '',`del_flag` tinyint(4) NOT NULL DEFAULT '1' COMMENT '1:正常 2:删除',`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (`id`),KEY `idx_name` (`name`)) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4mysql> select * from customer;+----+--------+--------------------+-------------+--------+----------+---------------------+---------------------+| id | name | address | phone | gender | del_flag | updated_at | created_at |+----+--------+--------------------+-------------+--------+----------+---------------------+---------------------+| 1 | 张三 | 安徽阜阳 | 13209876543 | male | 1 | 2021-04-25 20:10:04 | 2020-01-01 14:53:45 || 2 | 李四 | 河南郑州 | 17890909090 | male | 1 | 2021-04-25 20:10:04 | 2020-01-01 14:53:45 || 3 | 老刘 | 湖北武汉 | 16578890987 | male | 1 | 2021-04-25 20:10:04 | 2020-01-01 14:53:46 || 4 | 花花 | 北京市昌平区 | 13278787834 | male | 1 | 2021-04-25 20:10:04 | 2020-01-01 16:27:39 || 5 | 张三 | 四川成都 | 13209090909 | female | 1 | 2021-04-25 20:10:19 | 2021-04-25 20:08:53 |+----+--------+--------------------+-------------+--------+----------+---------------------+---------------------+
id主键索引,name普通索引(非唯一),gender无索引;
Using where
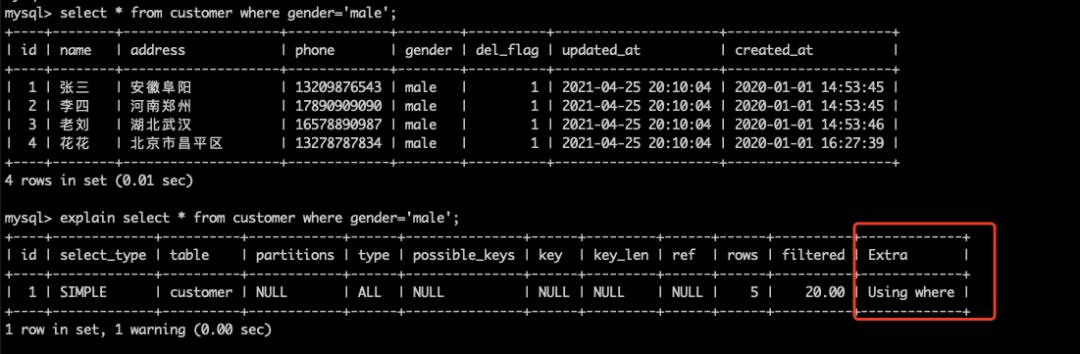
结果说明:
Extra为Using where说明,SQL使用了where条件过滤数据。
需要注意的是:
(1)返回所有记录的SQL,不使用where条件过滤数据,一般都不符合预期,对于这类SQL往往需要进行优化;
(2)使用了where条件的SQL,并不代表不需要优化,还需要配合explain结果中的type(连接类型)来综合判断;
本例虽然Extra字段说明使用了where条件过滤,但type属性是ALL,表示需要扫描全部数据,仍有优化空间。
常见的优化方法为,在where过滤属性上添加索引。但是针对本例的这种场景,gender只有两种结果,字段区分度不高,所以即使添加索引对性能的提升也很有限。
Using index
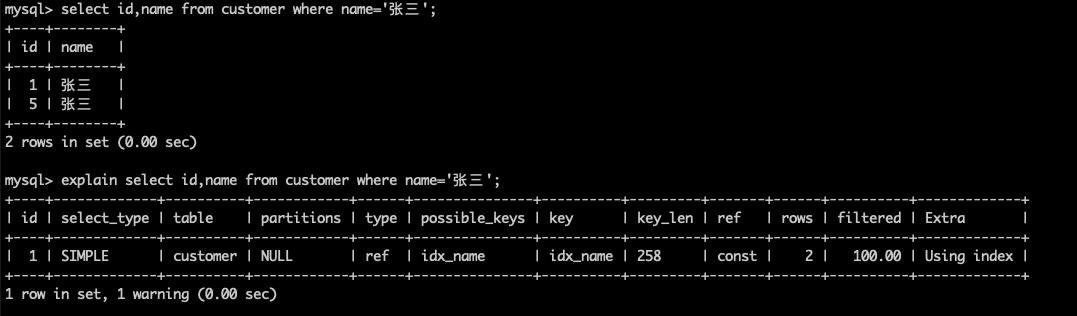
结果说明:
Extra为Using index说明,SQL所需要返回的所有列数据均在一棵索引树上,命中了覆盖索引,无需回表,所以这类SQL语句往往性能较好。
Using where; Using index

结果说明:
表示首先存储引擎通过索引检索将检索结果返回,再通过where语句对检索结果进行过滤。表示select的数据在索引中能找到,但需要根据where条件过滤,这种情况也不回表。
Using index condition(mysql 5.7及以上版本extra中显示的为NUll)
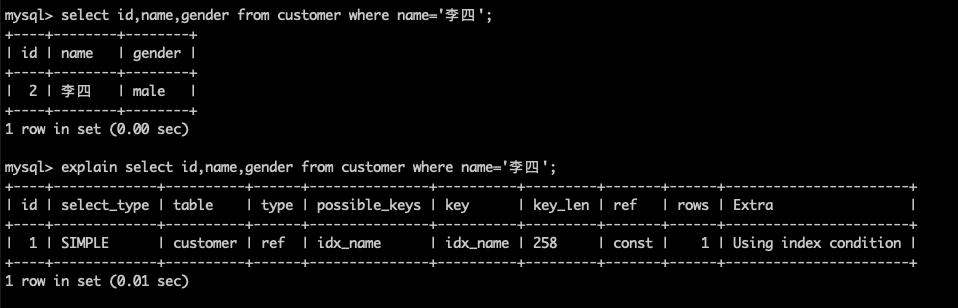
结果说明:
Extra为Using index condition说明,确实命中了索引,但不是所有的列数据都在索引树上,还需要访问实际的行记录(回表)。这类SQL语句性能也较高,但不如Using index。
Using filesort

结果说明:
Extra为Using filesort说明,得到所需结果集,需要对所有记录进行文件排序。这类SQL语句性能极差,需要进行优化。
一般在一个没有建立索引的列上进行了order by,就会触发filesort,常见的优化方案是,在order by的列上添加索引,避免每次查询都全量排序。
Using temporary
结果说明:
Extra为Using temporary说明,需要建立临时表(temporary table)来暂存中间结果。 这类SQL语句性能较低,往往也需要进行优化。
一般group by和order by同时存在,且作用于不同的字段时,就会建立临时表,以便计算出最终的结果集。
Using join buffer (Block Nested Loop)
结果说明:
Extra为Using join buffer (Block Nested Loop)说明,需要进行嵌套循环计算。这类SQL语句性能往往也较低,需要进行优化。
两个关联表join,关联字段均未建立索引,就会出现这种情况。常见的优化方案是,在关联字段上添加索引,避免每次嵌套循环计算。
感兴趣的同学可以参考下面两篇文章进行更深层次的了解:
技术分享 | MySQL 优化:JOIN 优化实践:https://zhuanlan.zhihu.com/p/103661924
数据库基础(七)Mysql Join算法原理:https://zhuanlan.zhihu.com/p/54275505
以上就是自己做DB优化期间的总结,欢迎批评指正,下一篇我计划分享一下MySQL索引类型以及相关的数据结构。。。
以上是关于MySQL 深入剖析Explain的主要内容,如果未能解决你的问题,请参考以下文章