浅谈HDFS源码的启动与心跳流程
Posted 数据之其然
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈HDFS源码的启动与心跳流程相关的知识,希望对你有一定的参考价值。
在我们读这篇文章知晓hadoop RPC原理,查看,接下来,我们可以针对Apache hadoop技术源码阅读技巧进行分享。
1、NameNode启动流程源码深度剖析
我们可以从上图了解到一些信息,我们可以了解一些相关的参数信息,对此我们在hdfs架构设计可以往NameDode几个重要的类进行读解,我们可以先从NameNode类去了解得知:
NameNode服务既管理了HDFS的集群的命名空间(目录树)和 "inode table"。一个HDFS集群里面只有一个NameNode.(除了HA方案,或者是联邦)Namenode管理了两张比较重要的表:
一张表管理了文件与block之间的关系。
另一张表管理了block文件块与 DataNode主机之间的关系。
说明:
第一张表非常珍贵,存储到了磁盘上面。(因为文件与block块之间的关系是不会发生变化的)
第二张表是每次NameNode重启的时候重新构建出来的
Namenode服务是由三个重要的类支撑的
(1)NameNode类
管理配置的参数hdfs-site.xml core-site.xml
(2)NameNode server
IPC Server:
NameNodeRPCServer:开放端口,等待别人调用.比如:8020/9000
HTTP Server:
NameNodeHttpServer:开放50070界面,我们可以通过这个界面了解HDFS的情况
(3)FSNameSystem
这个类非常重要,管理了HDFS的元数据(目录树的信息)
NameNode的启动流程无非服务端就是 RPCServer,它的默认端口号为 9000/8020, HttpServer的默认端口号为 50070,后面启动HTTPServer
if (NamenodeRole.NAMENODE == role) {//TODO 启动HTTPServerstartHttpServer(conf);}
启动HTTPServer完毕后,它会加载元数据,加载元数据这个事,目前对集群刚启动的时候,我们不做重点分析,在后面分析到管理元数据的时候,我们会回过头来在分析,而为什么现在不分析?
重要,这个就是Hadoop RPC,当启动一些公共的服务。NameNode RPC的服务就是在里面启动的
如:进行资源检查,检查是否有磁盘足够存储元数据、进入安全模式检查,检查是否可以退出安全模式。
startCommonServices(conf);而上面提过元数据管理,它的逻辑代码如下:
namesystem.startCommonServices(conf, haContext);registerNNSMXBean();if (NamenodeRole.NAMENODE != role) {startHttpServer(conf);httpServer.setNameNodeAddress(getNameNodeAddress());httpServer.setFSImage(getFSImage());}
在NameNode类里,我们在读源码会看到有个叫getHttpServerBindAddress方法,主要是设置了主机名和端口号
private void startHttpServer(final Configuration conf) throws IOException {//TODO getHttpServerBindAddress 里面设置了主机名和端口号httpServer = new NameNodeHttpServer(conf, this, getHttpServerBindAddress(conf));httpServer.start();httpServer.setStartupProgress(startupProgress);}
我们在分析源码时,需要留意的关键点 初始化的方法,它的代码逻辑如下:
initialize(conf);try {haContext.writeLock();state.prepareToEnterState(haContext);state.enterState(haContext);} finally {haContext.writeUnlock();}} catch (IOException e) {this.stop();throw e;} catch (HadoopIllegalArgumentException e) {this.stop();throw e;}this.started.set(true);}
我们以往做常规操作把集群刚刚搭建起来,然后集群进行初始化,都会执行“ hdfs namenode -format”命令,HDFS集群的时候会传进参数,我们这时候需要了解它的业务代码逻辑:
StartupOption startOpt = parseArguments(argv);if (startOpt == null) {printUsage(System.err);return null;}setStartupOption(conf, startOpt);switch (startOpt) {case FORMAT: {boolean aborted = format(conf, startOpt.getForceFormat(),startOpt.getInteractiveFormat());terminate(aborted ? 1 : 0);return null; // avoid javac warning}case GENCLUSTERID: {System.err.println("Generating new cluster id:");System.out.println(NNStorage.newClusterID());terminate(0);return null;}case FINALIZE: {System.err.println("Use of the argument '" + StartupOption.FINALIZE +"' is no longer supported. To finalize an upgrade, start the NN " +" and then run `hdfs dfsadmin -finalizeUpgrade'");terminate(1);return null; // avoid javac warning}case ROLLBACK: {boolean aborted = doRollback(conf, true);terminate(aborted ? 1 : 0);return null; // avoid warning}case BOOTSTRAPSTANDBY: {String toolArgs[] = Arrays.copyOfRange(argv, 1, argv.length);int rc = BootstrapStandby.run(toolArgs, conf);terminate(rc);return null; // avoid warning}case INITIALIZESHAREDEDITS: {boolean aborted = initializeSharedEdits(conf,startOpt.getForceFormat(),startOpt.getInteractiveFormat());terminate(aborted ? 1 : 0);return null; // avoid warning}case BACKUP:case CHECKPOINT: {NamenodeRole role = startOpt.toNodeRole();DefaultMetricsSystem.initialize(role.toString().replace(" ", ""));return new BackupNode(conf, role);}case RECOVER: {NameNode.doRecovery(startOpt, conf);return null;}case METADATAVERSION: {printMetadataVersion(conf);terminate(0);return null; // avoid javac warning}case UPGRADEONLY: {DefaultMetricsSystem.initialize("NameNode");new NameNode(conf);terminate(0);return null;}default: {DefaultMetricsSystem.initialize("NameNode");//因为我们现在分析的是启动namenode的代码,所以代码肯定是走到这儿了。//TODO 关键代码return new NameNode(conf);}}}
启动NameNode的代码后,肯定是走到这一步
在HDFS场景驱动下,我们只关心NameNode是如何启动的?阅读源码过程中,发现kafka 这个代码就写得比较好,我们可以看得详细一点。
public static void main(String argv[]) throws Exception {//解析参数if (DFSUtil.parseHelpArgument(argv, NameNode.USAGE, System.out, true)) {//参数异常退出System.exit(0);}
我们知道创建NameNode的核心代码,主要是RPC的服务端的,如下逻辑代码:
try {StringUtils.startupShutdownMessage(NameNode.class, argv, LOG);//TODO 创建NameNode的核心代码//RPC的服务端NameNode namenode = createNameNode(argv, null);if (namenode != null) {namenode.join();}} catch (Throwable e) {LOG.error("Failed to start namenode.", e);terminate(1, e);}}
接着我们在读源码有几个重要的类,分别是:
FSNamesystem
NameNodeResourceChecker
NameNodeResourcePolicy
CheckableNameNodeResource
NameNodeHttpServer、DFSConfigKeys
FSNamesystem类查看,发现NameNode启动的时候,主要是存储资源检查。其中,需要关注的文件 core-site.xml hdfs-site.xml,比如:
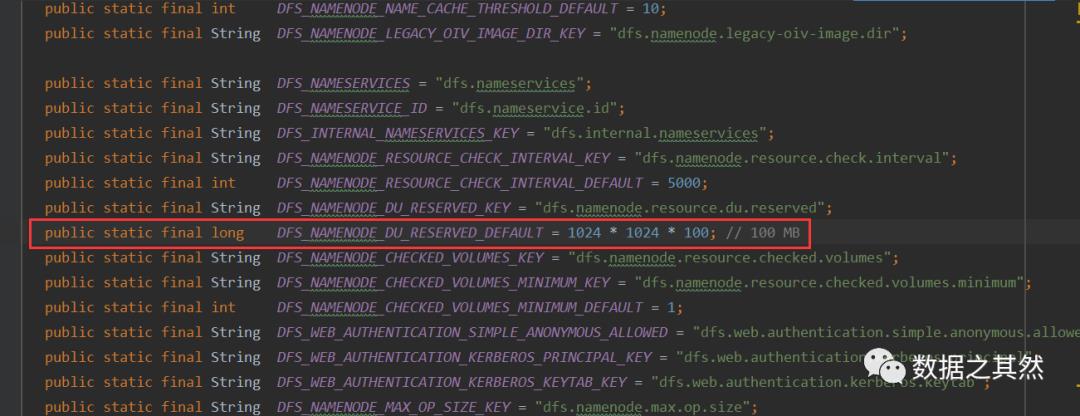
(1)fsimage目录磁盘的存储够不够(100M)
(2)editLog目录 磁盘的存储够不够(100M)
默认,这两个文件存储在同一个目录。
问题:NameNode如何做资源检查,定位元数据存在哪儿?
NameNode资源检查 通过core-site.xml hdfs-site.xml两个文件,就知道了元数据存在哪儿,NameNode的两个目录:存储fsiamge的目录,存储editlog的目录。
但是一般情况下,或者默认情况这两个使用的是同一个目录,加载了配置文件,配置文件里面有存储元数据的目录
在此,我们需要关注几个点,比如:检查是否有足够的磁盘存储元数据、HDFS的安全模式、启动重要服务的代码逻辑
nnResourceChecker = new NameNodeResourceChecker(conf);//TODO 检查是否有足够的磁盘存储元数据checkAvailableResources();assert safeMode != null && !isPopulatingReplQueues();StartupProgress prog = NameNode.getStartupProgress();prog.beginPhase(Phase.SAFEMODE);prog.setTotal(Phase.SAFEMODE, STEP_AWAITING_REPORTED_BLOCKS,getCompleteBlocksTotal());//TODO HDFS的安全模式setBlockTotal();//TODO 启动重要服务blockManager.activate(conf);} finally {writeUnlock();}registerMXBean();DefaultMetricsSystem.instance().register(this);if (inodeAttributeProvider != null) {inodeAttributeProvider.start();dir.setINodeAttributeProvider(inodeAttributeProvider);}snapshotManager.registerMXBean();}
接着,我们在读源码过程中的NameNodeResourceChecker查看发现,比如:获取当前目录的空间大小,如果空间大小小于 100M 就返回false
@Overridepublic boolean isResourceAvailable() {//TODO 获取当前目录的空间大小long availableSpace = df.getAvailable();if (LOG.isDebugEnabled()) {LOG.debug("Space available on volume '" + volume + "' is "+ availableSpace);}//TODO 如果空间大小小于 100M 就返回falseif (availableSpace < duReserved) {//ERRORLOG.warn("Space available on volume '" + volume + "' is "+ availableSpace +", which is below the configured reserved amount " + duReserved);/*** NameNode:有可能误操作,跑了一个任务,这个任务生成了很多数据。**/return false;} else {return true;}}
说明:NameNode:有可能误操作,跑了一个任务,这个任务生成了很多数据
问题:namenode服务器上面,肯定会有很多个目录?到底我们需要监控哪些目录呢?
(1)阈值
 (2)添加需要监控的磁盘
(2)添加需要监控的磁盘
localEditDirs -》 hdfs-site.xml core-site.xml
for (URI editsDirToCheck : localEditDirs) {addDirToCheck(editsDirToCheck,FSNamesystem.getRequiredNamespaceEditsDirs(conf).contains(editsDirToCheck));}
比如:一个目录就是一个CheckedVolume、这个对象其实就是一个目录、volumes里面会有多个路径(目录)
//一个目录就是一个CheckedVolumeCheckedVolume newVolume = new CheckedVolume(dir, required);//这个对象其实就是一个目录CheckedVolume volume = volumes.get(newVolume.getVolume());if (volume == null || !volume.isRequired()) {//volumes里面会有多个路径(目录)volumes.put(newVolume.getVolume(), newVolume);}
关键调用的代码,volumes 里面存放的就是需要检查的目录,如果资源不够,返回值是false
public boolean hasAvailableDiskSpace() {//关键调用的是这儿的代码// //volumes 里面存放的就是需要检查的目录//如果资源不够,返回值是falsereturn NameNodeResourcePolicy.areResourcesAvailable(volumes.values(),minimumRedundantVolumes);}
继续读源码NameNodeResourcePolicy类查看,发现它是通过遍历每个目录来判断磁盘资源是否充足,它的代码逻辑如下:
//遍历每个目录for (CheckableNameNodeResource resource : resources) {if (!resource.isRequired()) {redundantResourceCount++;if (!resource.isResourceAvailable()) {disabledRedundantResourceCount++;}} else {requiredResourceCount++;//TODO 判断磁盘资源是否充足//resource.isResourceAvailable() = false//!false = true//如果空间不够那么就返回falseif (!resource.isResourceAvailable()) {// Short circuit - a required resource is not available.return false;}}}
继续读源码CheckableNameNodeResource类查看,我们知道Hadoop喜欢自己封装东西。举个例子,本来就有RPC的服务。但是Hadoop自己封装了一个Hadoop RPC,这个地方也是类似,本来有HttpServer,Hadoop经过封装封装了,比如 HttpServer2服务,它的代码逻辑是这样:
HttpServer2.Builder builder = DFSUtil.httpServerTemplateForNNAndJN(conf,httpAddr, httpsAddr, "hdfs",DFSConfigKeys.DFS_NAMENODE_KERBEROS_INTERNAL_SPNEGO_PRINCIPAL_KEY,DFSConfigKeys.DFS_NAMENODE_KEYTAB_FILE_KEY);httpServer = builder.build();if (policy.isHttpsEnabled()) {// assume same ssl port for all datanodesInetSocketAddress datanodeSslPort = NetUtils.createSocketAddr(conf.getTrimmed(DFSConfigKeys.DFS_DATANODE_HTTPS_ADDRESS_KEY, infoHost + ":"+ DFSConfigKeys.DFS_DATANODE_HTTPS_DEFAULT_PORT));httpServer.setAttribute(DFSConfigKeys.DFS_DATANODE_HTTPS_PORT_KEY,datanodeSslPort.getPort());}initWebHdfs(conf);httpServer.setAttribute(NAMENODE_ATTRIBUTE_KEY, nn);httpServer.setAttribute(JspHelper.CURRENT_CONF, conf);
有个绑定一堆servlet,也就是说servlet越多,支持的功能就越多
setupServlets(httpServer, conf);启动httpServer服务,对外开放50070端口
httpServer.start();当然,在NameNodeHttpServer类里,发现还有一个上传元数据的请求,SecondaryNameNode/StandByNamenode合并出来的FSImage需要替换Active NameNode的fsimage,发送的就是http的请求,请求就会转发给这个servlet
httpServer.addInternalServlet("imagetransfer", ImageServlet.PATH_SPEC,ImageServlet.class, true);
我们可以在50070界面上浏览目录信息,就是因为这儿有这个servlet,如:"http://hadoop1:50070/listpahts/?path=/"
httpServer.addInternalServlet("listPaths", "/listPaths/*",ListPathsServlet.class, false);httpServer.addInternalServlet("data", "/data/*",FileDataServlet.class, false);httpServer.addInternalServlet("checksum", "/fileChecksum/*",FileChecksumServlets.RedirectServlet.class, false);httpServer.addInternalServlet("contentSummary", "/contentSummary/*",ContentSummaryServlet.class, false);}
2、DataNode启动流程源码深度剖析
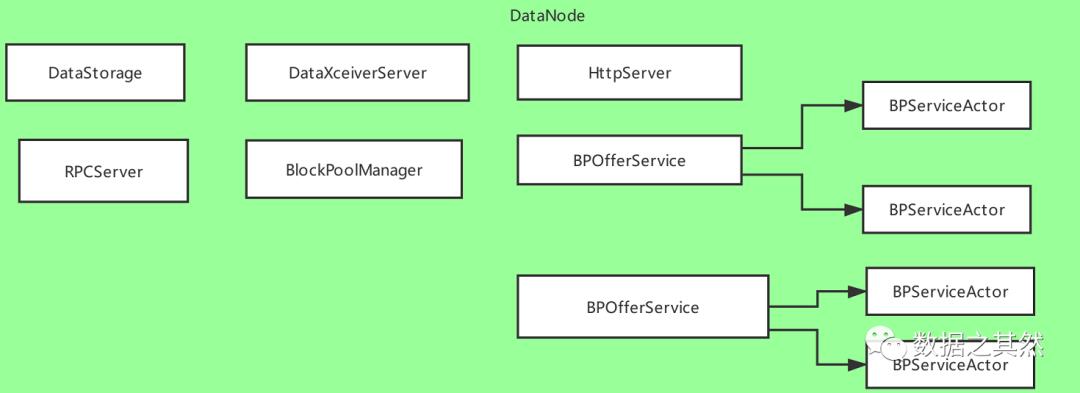
Data启动初始化
注册流程
DataNode与NameNode启动流程
(1)DataNode存储hdfs上block文件块。在一个文件系统里面可以有多个dataNode,每个DataNode周期性的跟NameNode进行通信,客户端也可以跟DataNode进行交互,或者DataNode之间也可以进行相互通信。
(2)DataNode存储一系列block,DataNode允许客户端去读写block。DataNode也会去响应NameNode,响应NameNode发送过来的一些指令,
比如:删除block,复制block等操作。
说明:NameNode不会直接去操作DataNode,如:datanode -> 发送心跳 Namenode
(3)datanode管理了一个重要的表:block -》 stream of bytes 一些元数据的信息。
(4)这个信息是存储在本地磁盘,DataNode启动的时候会把这些信息,汇报给NameNode,启动了以后也会再去不断的汇报。
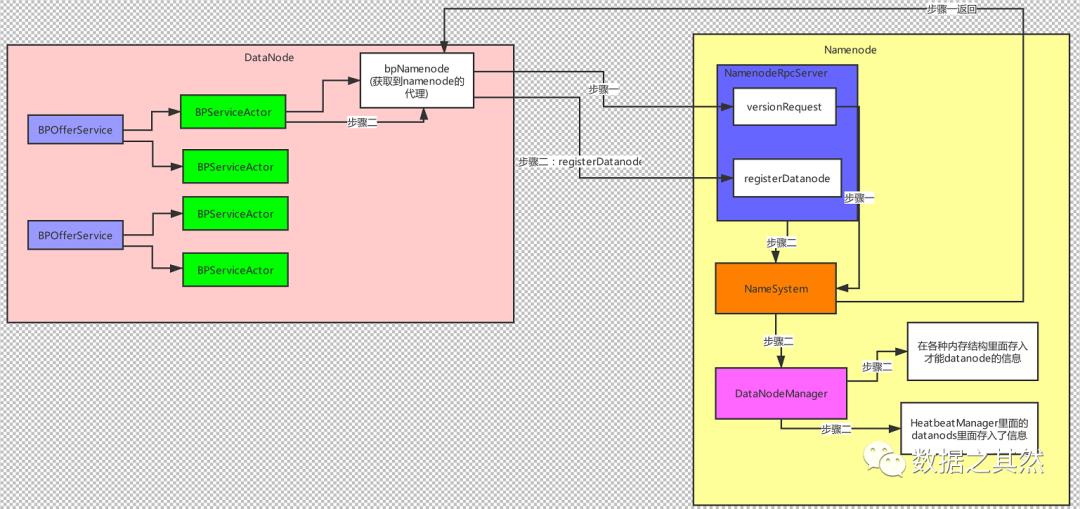
(5)DataNode启动了以后会一直去问namenode自己需要干些什么?
NameNode是不能直接去操作DataNode的。DataNode启动了以后,会跟NameNode,进行心跳,NameNode接收到了心跳了以后,如果需要这个DataNode做什么事,就会给DataNode一个返回值(指令),DataNode接收到这些指令以后就知道NameNode想让他做什么事了
(6)DataNode开放了Socket服务,让客户端或者别的DataNode来进行读写数据。DataNode启动的时候会把自己的主机名和端口号汇报给NameNode,也就是说如果Client和DataNode想要去访问某个DataNode.首先要跟NameNode进行通信,从NameNode那儿获取到目标DataNode的主机名和端口号。这样才可以访问到对应的DataNode了。
总结:
一个集群里面可以有很多个DataNode,这些DataNode就是用来存储数据的。
DataNode启动了以后会周期性的跟NameNode进行通信(心跳,块汇报)
NameNode不能直接操作DataNode.而是通信心跳返回值指令的方式去操作的DataNode.
DataNode启动了以后开放了一个socket的服务(RPC),等待别人去调用他。
读源码关注这几个类
DataXceiverServer
DataStorage
Storage
InterDatanodeProtocol
BlockPoolManager
DatanodeProtocolClientSideTranslatorPB
在DataXceiverServer类里,发现这个服务启动起来以后是用来处理客户端或者其他DataNode发送过来的的读写block数据请求的,这个地方没有使用Hadoop的RPC,每发送过来一个block 都启动一个DataXceiver 去处理这个block,它的逻辑代码如下:
new Daemon(datanode.threadGroup,DataXceiver.create(peer, datanode, this)).start();
在BlockPoolManager类里,发现会遍历所有的联邦
synchronized void startAll() throws IOException {try {UserGroupInformation.getLoginUser().doAs(new PrivilegedExceptionAction<Object>() {@Overridepublic Object run() throws Exception {//TODO 遍历所有的BPOfferService 遍历所有的联邦for (BPOfferService bpos : offerServices) {//TODO 重要bpos.start();}return null;}});} catch (InterruptedException ex) {IOException ioe = new IOException();ioe.initCause(ex.getCause());throw ioe;}}
重要代码
doRefreshNamenodes(newAddressMap);比如:namenode服务器搭建好:namenode上的配置文件一模一样的复制到各个datanode节点。
通常情况下:HDFS集群的架构是HA架构,如果是联邦架构,里面就会有多个namenodeservice
hadoop1,hadoop2 -> 联邦1 service1hadoop3,hadoop4 -> 联邦2 service2
toAdd里面有多少有的联邦:
一个联邦就是一个NameService,如果是2个联邦,那么这个地方就会有两个值,BPOfferService -》 一个联邦
重要的关系:
一个联邦对应一个BPOfferService
一个联邦里面的一个NameNode就是一个BPServiceActor,也就是正常来说一个BPOfferService对应两个BPServiceActor
BPOfferService bpos = createBPOS(addrs);bpByNameserviceId.put(nsToAdd, bpos);offerServices.add(bpos);}
最后,DataNode向NameNode进行注册和心跳
startAll();//术的层面 道的层知其所以然、知其所以必然,知其然而不知其所以然;蒙惠者虽知其然,而未必知其所以然;也这是我们从学习实践中得出的深切体会!分享完毕,谢谢!
以上是关于浅谈HDFS源码的启动与心跳流程的主要内容,如果未能解决你的问题,请参考以下文章