面试官:来来来!聊聊MySQL数据库的insert buffer和change buffer吧
Posted Echo1024
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:来来来!聊聊MySQL数据库的insert buffer和change buffer吧相关的知识,希望对你有一定的参考价值。

Hi,大家好!我是白日梦!
今天我要跟你分享的MySQL话题是:“用大白话讲明白MySQL的insert buffer和change buffer” 本文是MySQL专题的第 30 篇。欢迎关注!持续更新中~
一、前言
二、问题引入(索引树)
三、change buffer存在的意义
四、再看change buffer
五、change buffer 的限制
六、change buffer 相关参数
七、查看你的MySQL的change buffer
八、灵魂拷问
九、参考
十、推荐阅读
一、前言
终于《为研发同学同学定制的MySQL面试指南》第30篇更新来啦~
说来话长,都说百度是养老厂,结果偏偏干出了pdd的感觉。最近工作确实比较忙,然后周六日又想放松一下接连好多周六日都和同学出去游玩。

立个flag吧!后续的更新进度做到每周至少一更。欢迎关注白日梦,干货分享不断~
好!开始啦,做了这么久研发的你,有没有听别人说过、或者在哪里见过insert buffer 、change buffer呢?这篇文章我们一起闲聊一下MySQL的insert buffer、change buffer,彻底揭开这两个名词的面纱!
二、问题引入
在白日梦看来,如果你想更好的理解 insert buffer、change buffer。首先你得先掌握一些前置的知识,比如MySQL索引的相关知识。所以不要着急,我们一点点展开话题,从你数据的知识过度到insert buffer、change buffer上去,你会发现豁然开朗。
2.1、聚簇索引
首先我们回顾一下MySQL的聚簇索引,这个东西大家肯定不陌生吧!我打赌在做的各位面试前都会背一背什么是聚簇索引。
大家可以看下面这张图,它就是对B+tree的抽象。它有很多特性,在这篇文章中只需要知道如下几个就好了
-
它是一个B+tree。 -
我们管这棵树的叶子结点叫做 数据页。 -
叶子结点中存储的数据行是一个全集,怎么解释这个全集呢?比如数据表就3列,id、name、age。所谓的全集就是说:每行数据都有id、name、age这3列。 -
我们管非叶子结点叫做 索引页。
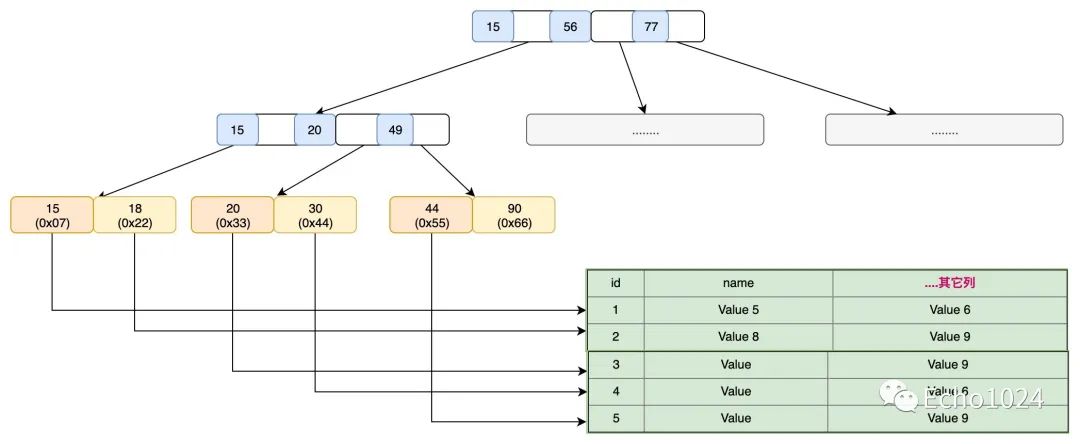
而且我跟大家讲哦,这棵B+tree是会被存储在Disk中的。如果你不能很好的理解的话,可以读一下下面的两段话:
比如一条update sql想修改id = 999的数据行,那它会怎么操作数据页呢?简单来说就是:首先会检查一下buffer pool中有没有包含这条数据的数据页。如果有的话,直接update。如果没有的话进行一次磁盘IO把该数据页加载进内存,然后将其update。然后这时的数据页也就变成了脏页。等后续其它机制将该数据页刷新回Disk。完成内存和数据。
读上面的这段话,你要重点感受一下:数据页从磁盘到Buffer Pool中的这个过程(最终会被挂载在B+tree的叶子结点上)
其实你类比着数据页来看,对于B+tree的非叶子结点来说也是一样的。上面我说了,我们管非叶子结点叫做索引页。为啥这样说呢?其实本质上非叶子结点也是数据页,只不过它里面存储的数据是索引数据。而且和普通的数据页一样,当你需要它而且它还不在内存中时,进行磁盘操作将其读取内存中。
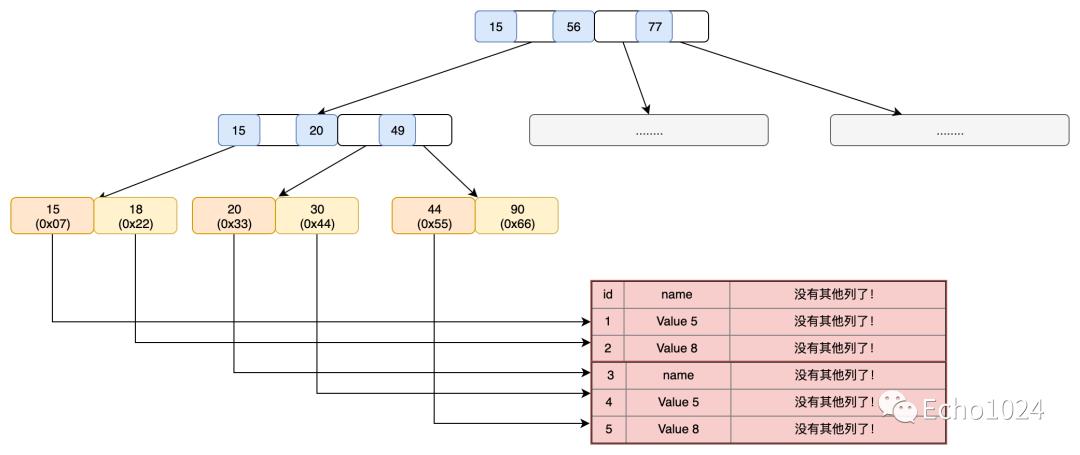
2.2、普通索引
普通的索引也就是我们常说的二级索引、联合索引等等。
比如我们将name列设置成index的话,那么MySQL就会为我们这个索引单独创建一个B+Tree。(是的!它是独立于主键索引之外的另一颗B+Tree)。而且你注意一下如下几点:
-
和聚簇索引一样的是,我们管它的非叶子结点叫做:索引页 -
它的叶子结点中存储的并不是所有的列的全集。比如我们对name列创建索引,那么它的叶子节点中存储的就是id、name两列。并会按照name排序。
三、change buffer存在的意义
了解了上面的索引相关的前置知识点再来看insert buffer和change buffer那其实就很简单了。
我们这一小节来看一下change buffer存在的意义:
其实说白了其实insert buffer也好,还是change buffer也好,它们其实就是MySQL在我们对非唯一的二级索引进行DML(删除行、写入行、修改行)操作时作出的优化逻辑。目的就是让MySQL的性能更好。
比如还是我们这个例子:表里面有3列。id、name、age。然后id是主键、name是非唯一的二级索引。
一条update sql:update xx set name = "赐我白日梦" where name = “白日梦”打过来之后,执行流程大概就像下面这样:
1、检查需要被update的数据是否在buffer pool中。
2、如果在buffer pool中直接将其update。
3、如果不在buffer pool中,进行磁盘的IO操作,将其读取内存中,再把它update。

现在的问题是,name列是个索引列。上文也说了,既然是索引列就意味着需要为它单独创建一颗B+Tree。
那你的update sql要做修改,那是不是会分成两个大的步骤
1、Step1: 对buffer pool中的数据页中的数据进行update。
2、Step2: 维护为name单独创建的B+Tree。
你想呀既然MySQL要优化我们对非唯一的二级索引的DML操作,肯定要有个需要优化的点吧!
而这里的Step2,就是insert buffer和change buffer 存在的意思所在!
为啥这样说呢?因为在本篇文章的开头我们提到了,B+tree也是存储在Disk中的,那它肯定就难免发生随机磁盘IO。
或者你想一下:你只是想update 几条数据。假设运气很不好这几条都没有在buffer pool中。那没办法,我们只能去读磁盘。但是更不巧的,涉及到的二级索引页竟然也没有在内存中,我们竟然还要同步等待这一次随机磁盘IO!!!
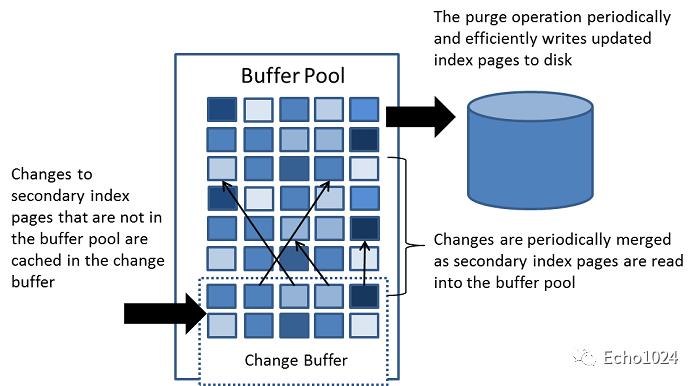
四、再看change buffer
change buffer的本质上其实也是一块内存。
比如你的:insert、delete、update等DML操作需要用到的二级索引页(注意是二级索引页,具体就比如说为name列这个二级索引创建的B+Tree的叶子节点,而不是Buffer pool中的普通数据页)
就是当这些二级索引页不在内存中时,你对它们的操作会被缓存在change buffer中(目的是省去这次随机的磁盘IO)。等之后MySQL空闲了、或者是MySQL关闭前、或者是有读取操作时再将这部分缓存操作merge到B+Tree中。
五、change buffer 的限制
这个现实其实已经说过了
1、首先得要求是二级索引。如果不是二级索引到话,那前面change buffer存在意义又是什么呢?没有啥可优化的地方。那不如不要这个change buffer
2、要求二级索引不能唯一。这个很好理解。如果name列是唯一的。那我每次insert 之前是不是都必须去看下内存、Disk上到底有没有已经存在的相同值的索引。这也就意味着这个insert 操作其实是不能被缓存的!必须立即知道到底能否insert 成功。对吧!不这样的话,你打算返回给客户端什么结果呢?
六、change buffer 相关参数
参数:innodb_change_buffer_max_size
作用:控制change buffer能占用buffer pool总内存的比例
范围:默认25(表示change buffer最大能占用其25%的内存),最大50。
参数:innodb_change_buffering
作用:控制change buffer对哪些dml起作用
可选参数:all(insert、delete、update)、none(不缓存任何操纵)、inserts、deletes、purges
七、查看你的MySQL的change buffer
# 命令
SHOW ENGINE INNODB STATUS\G
# 查看如下部分
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 4425293, used cells 32, node heap has 1 buffer(s)
13577.57 hash searches/s, 202.47 non-hash searches/s
# insert:insert buffer
# delete mask:delete buffer
# delete :purge buffer
# discarded operations:当change buffer发生merge时,数据表被删除了!无需再merge
八、灵魂拷问
如果你能回答上这个问题,说明你真的理解了change buffer!
问:
我开启change buffer 之后,现在要删除一个非唯一的二级辅助索引数据行,比如就删除name=Tom的行,并且这个索引页不在内存中……接下来会发生什么?
按照change buffer的作用来说,是不是当索引页不在内存中时,不去读盘,而是会把这个删除操作写到change buffer 中?
那问题又来了,既然你是把这个操作写到了change buffer中,那你返回给客户端的影响行数怎么算出来的呢?你都没有读读磁盘,万一磁盘上都没你要删除的数据呢…… 你告诉客户端,删除成功了,影响行数为1?

答:其实客户端每次都能得到正确的影响行数!不错,change buffer中是把缓存了你的delete操作,但是buffer pool是没有被影响的呀,如果buffer pool中没有这个name=Tom的行,它依然会去读磁盘的!你品一品,buffer pool和change buffer是两块缓存哦~
九、参考
https://dev.mysql.com/doc/refman/5.7/en/innodb-change-buffer.html
十一、推荐阅读
1、
2、数据库面经,常见的面试题
3
4
6
7
20
21
27、--续
以上是关于面试官:来来来!聊聊MySQL数据库的insert buffer和change buffer吧的主要内容,如果未能解决你的问题,请参考以下文章
面试官:兄弟,聊聊MySQL的Client和Proxy分库分表架构设计?