乘风破浪的Redis可能是史上第二强面试题解攻略
Posted 后端技术指南针
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了乘风破浪的Redis可能是史上第二强面试题解攻略相关的知识,希望对你有一定的参考价值。
金三银四的跳槽季,又翻出了一年前写的3万字的Redis面试总结,还是忍不住推荐一下,希望对大家有所帮助。
0x00.前言
众所周知数据结构和算法是面试重点,我们持续发力是十分明智的,要不然最后肯定是要吃亏的,少打打游戏刷刷微博可以改变我们的生活水平哦。
不过本文不是要讲述数据结构和算法的,而是另外一个面试重点Redis,因为Redis也是跨语言的共同技术点,无论是Java还是C++都会问到,所以是个高频面试点。
笔者是2017年才开始接触Redis的,期间自己搭过单机版和集群版,不过现在公司大一些都完全是运维来实现的,我们使用者只需要在web页面进行相关申请即可,很多细节都被屏蔽了,这样当然很方便啦,不过我们还是要深入理解一下的。
在工作几年中笔者接触过Redis、类Redis的SSDB和Pika、谷歌的Key-Value存储引擎LevelDB、FackBook的Key-Value存储引擎RocksDB等NoSQL,其中Redis是基于标准C语言开发的,是工程中和学习上都非常优秀的开源项目。
之前笔者写过几篇左右Redis的文章,但是知识点都分散着不利于阅读,所以本次就把之前的文章进行汇总补充,来形成一个全一些的集合,希望对关注我的读者有所帮助就足够啦。
文中列出来的考点较多并且累计达3w+字 ,因此建议读者收藏,以备不时之需,通过本文你将了解到以下内容:
-
Redis的作者和发展简史 -
Redis常用数据结构及其实现 -
Redis的SDS和C中字符串的原理和对比 -
Redis有序集合ZSet的底层设计和实现 -
Redis有序集合ZSet和跳跃链表问题 -
Redis字典的实现及渐进式Rehash过程 -
Redis单线程运行模式的基本原理和流程 -
Redis反应堆模式的原理和设计实现 -
Redis持久化方案及其基本原理 -
集群版Redis和Gossip协议 -
Redis内存回收机制和基本原理 -
Redis数据同步机制和基本原理
话不多说,时速400公里的大白号 开始加速!

笔者尽量详细地阐述每个问题,旨在深入理解避免囫囵吞枣的背诵,当然也会存在一些不足,如有问题可私信我。
0x01. 什么是Redis及其重要性?
Redis是一个使用ANSI C编写的开源、支持网络、基于内存、可选持久化的高性能键值对数据库。
Redis的之父是来自意大利的西西里岛的Salvatore Sanfilippo,Github网名antirez,笔者找了作者的一些简要信息并翻译了一下,如图:
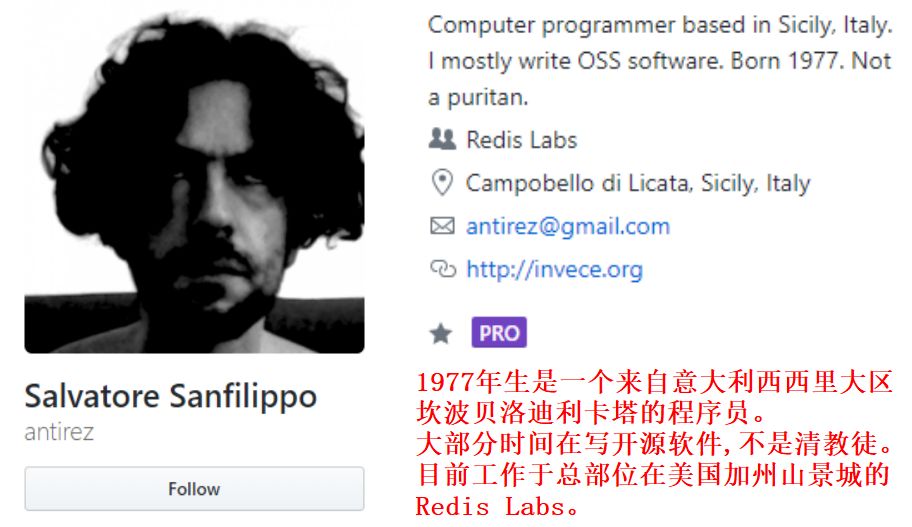
从2009年第一个版本起Redis已经走过了10个年头,目前Redis仍然是最流行的key-value型内存数据库的之一。
优秀的开源项目离不开大公司的支持,在2013年5月之前,其开发由VMware赞助,而2013年5月至2015年6月期间,其开发由毕威拓赞助,从2015年6月开始,Redis的开发由Redis Labs赞助。

笔者也使用过一些其他的NoSQL,有的支持的value类型非常单一,因此很多操作都必须在客户端实现,比如value是一个结构化的数据,需要修改其中某个字段就需要整体读出来修改再整体写入,显得很笨重,但是Redis的value支持多种类型,实现了很多操作在服务端就可以完成了,这个对客户端而言非常方便。
当然Redis由于是内存型的数据库,数据量存储量有限而且分布式集群成本也会非常高,因此有很多公司开发了基于SSD的类Redis系统,比如360开发的SSDB、Pika等数据库,但是笔者认为从0到1的难度是大于从1到2的难度的,毋庸置疑Redis是NoSQL中浓墨重彩的一笔,值得我们去深入研究和使用。
Redis提供了Java、C/C++、C#、 php 、javascript、 Perl 、Object-C、Python、Ruby、Erlang、Golang等多种主流语言的客户端,因此无论使用者是什么语言栈总会找到属于自己的那款客户端,受众非常广。
笔者查了datanyze.com网站看了下Redis和mysql的最新市场份额和排名对比以及全球Top站点的部署量对比(网站数据2019.12):
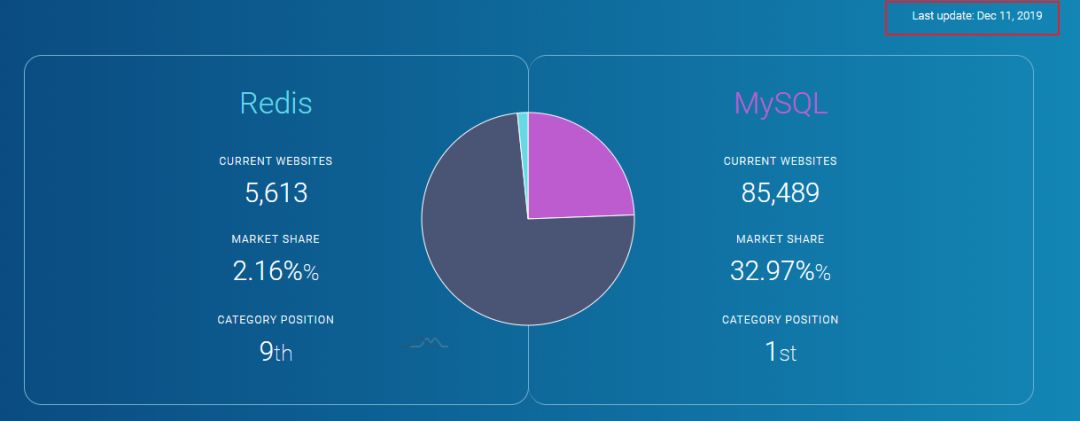
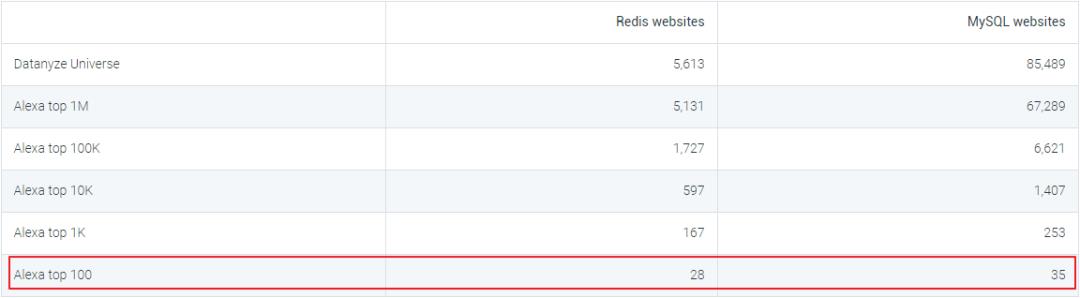
可以看到Redis总体份额排名第9并且在全球Top100站点中部署数量与MySQL基本持平,所以Redis还是有一定的江湖地位的。
0x02. 简述Redis常用的数据结构及其如何实现的?
Redis支持的常用5种数据类型指的是value类型,分别为:字符串String、列表List、哈希Hash、集合Set、有序集合Zset,但是Redis后续又丰富了几种数据类型分别是Bitmaps、HyperLogLogs、GEO。
由于Redis是基于标准C写的,只有最基础的数据类型,因此Redis为了满足对外使用的5种数据类型,开发了属于自己独有的一套基础数据结构,使用这些数据结构来实现5种数据类型。
Redis底层的数据结构包括:简单动态数组SDS、链表、字典、跳跃链表、整数集合、压缩列表、对象。
Redis为了平衡空间和时间效率,针对value的具体类型在底层会采用不同的数据结构来实现,其中哈希表和压缩列表是复用比较多的数据结构,如下图展示了对外数据类型和底层数据结构之间的映射关系:
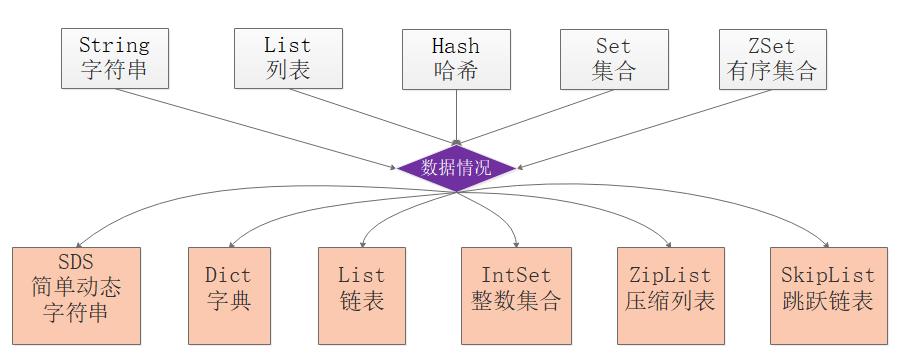
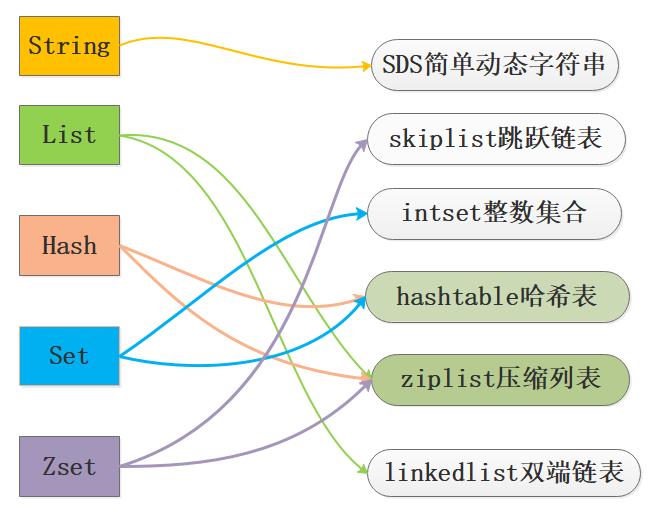
从图中可以看到ziplist压缩列表可以作为Zset、Set、List三种数据类型的底层实现,看来很强大,压缩列表是一种为了节约内存而开发的且经过特殊编码之后的连续内存块顺序型数据结构,底层结构还是比较复杂的。
0x03. Redis的SDS和C中字符串相比有什么优势?
在C语言中使用N+1长度的字符数组来表示字符串,尾部使用'\0'作为结尾标志,对于此种实现无法满足Redis对于安全性、效率、丰富的功能的要求,因此Redis单独封装了SDS简单动态字符串结构。
在理解SDS的优势之前需要先看下SDS的实现细节,找了github最新的src/sds.h的定义看下:
typedef char *sds;/*这个用不到 忽略即可*/
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};/*不同长度的header 8 16 32 64共4种 都给出了四个成员
len:当前使用的空间大小;alloc去掉header和结尾空字符的最大空间大小
flags:8位的标记 下面关于SDS_TYPE_x的宏定义只有5种 3bit足够了 5bit没有用
buf:这个跟C语言中的字符数组是一样的,从typedef char* sds可以知道就是这样的。
buf的最大长度是2^n 其中n为sdshdr的类型,如当选择sdshdr16,buf_max=2^16。
*/
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
#define SDS_TYPE_MASK 7
#define SDS_TYPE_BITS 3
看了前面的定义,笔者画了个图:

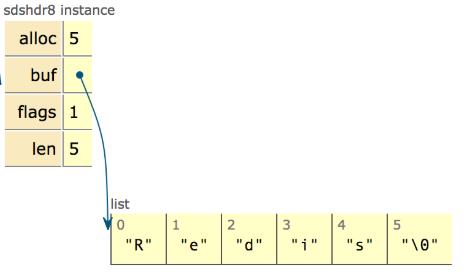
从图中可以知道sds本质分为三部分:header、buf、null结尾符,其中header可以认为是整个sds的指引部分,给定了使用的空间大小、最大分配大小等信息,再用一张网上的图来清晰看下sdshdr8的实例:
在sds.h/sds.c源码中可清楚地看到sds完整的实现细节,本文就不展开了要不然篇幅就过长了,快速进入主题说下sds的优势:
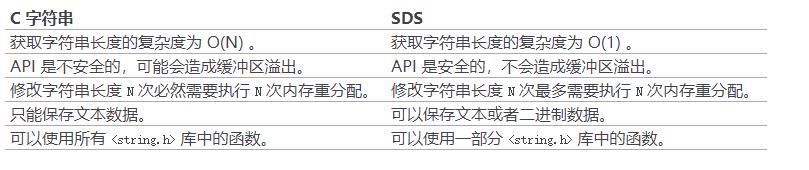
O(1)获取长度: C字符串需要遍历而sds中有len可以直接获得;
防止缓冲区溢出bufferoverflow: 当sds需要对字符串进行修改时,首先借助于len和alloc检查空间是否满足修改所需的要求,如果空间不够的话,SDS会自动扩展空间,避免了像C字符串操作中的覆盖情况;
有效降低内存分配次数:C字符串在涉及增加或者清除操作时会改变底层数组的大小造成重新分配、sds使用了空间预分配和惰性空间释放机制,说白了就是每次在扩展时是成倍的多分配的,在缩容是也是先留着并不正式归还给OS,这两个机制也是比较好理解的;
二进制安全:C语言字符串只能保存ascii码,对于图片、音频等信息无法保存,sds是二进制安全的,写入什么读取就是什么,不做任何过滤和限制;
老规矩上一张黄健宏大神总结好的图:
0x04. Redis的字典是如何实现的?简述渐进式rehash过程
字典算是Redis中常用数据类型中的明星成员了,前面说过字典可以基于ziplist和hashtable来实现,我们只讨论基于hashtable实现的原理。
字典是个层次非常明显的数据类型,如图:
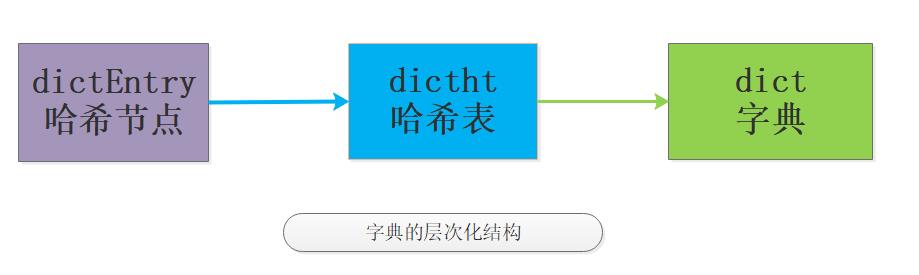
有了个大概的概念,我们看下最新的src/dict.h源码定义:
//哈希节点结构
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
//封装的是字典的操作函数指针
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
//哈希表结构 该部分是理解字典的关键
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
//字典结构
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
C语言的好处在于定义必须是由最底层向外的,因此我们可以看到一个明显的层次变化,于是笔者又画一图来展现具体的层次概念:
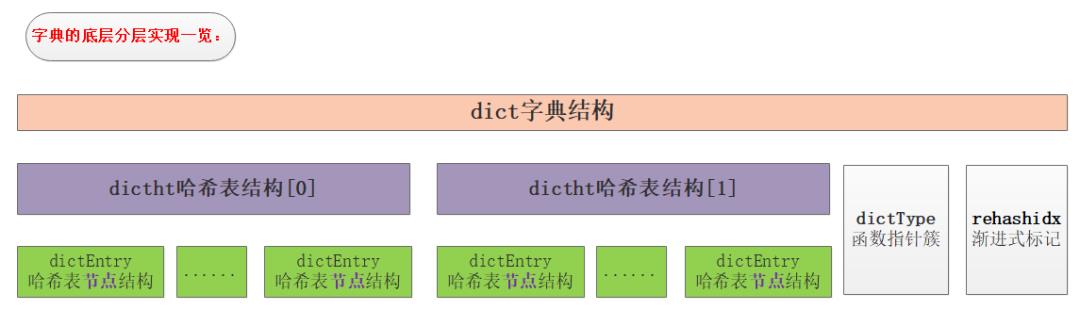
关于dictEntry
dictEntry是哈希表节点,也就是我们存储数据地方,其保护的成员有:key,v,next指针。key保存着键值对中的键,v保存着键值对中的值,值可以是一个指针或者是uint64_t或者是int64_t。next是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一次,以此来解决哈希冲突的问题。
如图为两个冲突的哈希节点的连接关系:
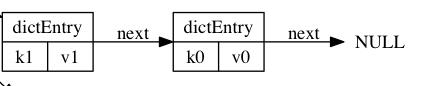
关于dictht
从源码看哈希表包括的成员有table、size、used、sizemask。table是一个数组,数组中的每个元素都是一个指向dictEntry结构的指针, 每个dictEntry结构保存着一个键值对;size 属性记录了哈希表table的大小,而used属性则记录了哈希表目前已有节点的数量。sizemask等于size-1和哈希值计算一个键在table数组的索引,也就是计算index时用到的。
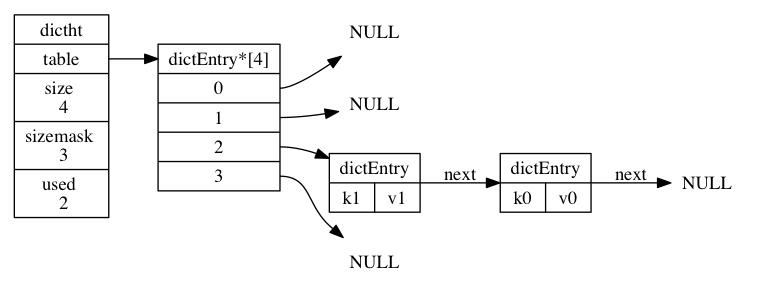
如上图展示了一个大小为4的table中的哈希节点情况,其中k1和k0在index=2发生了哈希冲突,进行开链表存在,本质上是先存储的k0,k1放置是发生冲突为了保证效率直接放在冲突链表的最前面,因为该链表没有尾指针。
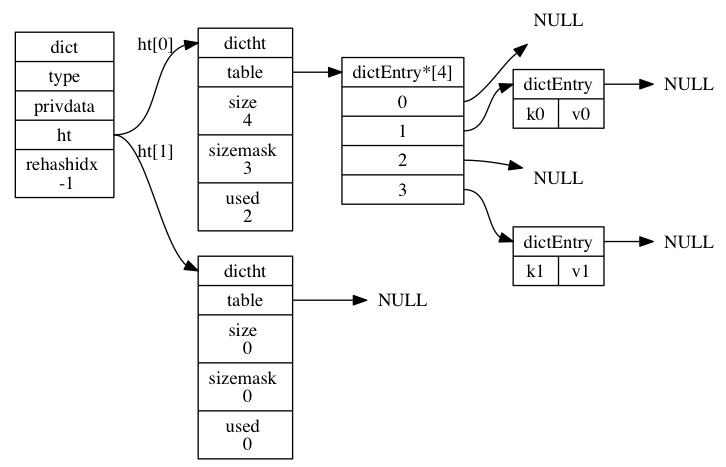
关于dict
从源码中看到dict结构体就是字典的定义,包含的成员有type,privdata、ht、rehashidx。其中dictType指针类型的type指向了操作字典的api,理解为函数指针即可,ht是包含2个dictht的数组,也就是字典包含了2个哈希表,rehashidx进行rehash时使用的变量,privdata配合dictType指向的函数作为参数使用,这样就对字典的几个成员有了初步的认识。
字典的哈希算法
//伪码:使用哈希函数,计算键key的哈希值
hash = dict->type->hashFunction(key);
//伪码:使用哈希表的sizemask和哈希值,计算出在ht[0]或许ht[1]的索引值
index = hash & dict->ht[x].sizemask;
//源码定义
#define dictHashKey(d, key) (d)->type->hashFunction(key)
redis使用MurmurHash算法计算哈希值,该算法最初由Austin Appleby在2008年发明,MurmurHash算法的无论数据输入情况如何都可以给出随机分布性较好的哈希值并且计算速度非常快,目前有MurmurHash2和MurmurHash3等版本。
普通Rehash重新散列
哈希表保存的键值对数量是动态变化的,为了让哈希表的负载因子维持在一个合理的范围之内,就需要对哈希表进行扩缩容。
扩缩容是通过执行rehash重新散列来完成,对字典的哈希表执行普通rehash的基本步骤为分配空间->逐个迁移->交换哈希表,详细过程如下:
为字典的ht[1]哈希表分配空间,分配的空间大小取决于要执行的操作以及ht[0]当前包含的键值对数量:
扩展操作时ht[1]的大小为第一个大于等于ht[0].used*2的2^n;
收缩操作时ht[1]的大小为第一个大于等于ht[0].used的2^n ;扩展时比如h[0].used=200,那么需要选择大于400的第一个2的幂,也就是2^9=512。
将保存在ht[0]中的所有键值对重新计算键的哈希值和索引值rehash到ht[1]上;
重复rehash直到ht[0]包含的所有键值对全部迁移到了ht[1]之后释放 ht[0], 将ht[1]设置为 ht[0],并在ht[1]新创建一个空白哈希表, 为下一次rehash做准备。
渐进Rehash过程
Redis的rehash动作并不是一次性完成的,而是分多次、渐进式地完成的,原因在于当哈希表里保存的键值对数量很大时, 一次性将这些键值对全部rehash到ht[1]可能会导致服务器在一段时间内停止服务,这个是无法接受的。
针对这种情况Redis采用了渐进式rehash,过程的详细步骤:
为ht[1]分配空间,这个过程和普通Rehash没有区别;
将rehashidx设置为0,表示rehash工作正式开始,同时这个rehashidx是递增的,从0开始表示从数组第一个元素开始rehash。
在rehash进行期间,每次对字典执行增删改查操作时,顺带将ht[0]哈希表在rehashidx索引上的键值对rehash到 ht[1],完成后将rehashidx加1,指向下一个需要rehash的键值对。
随着字典操作的不断执行,最终ht[0]的所有键值对都会被rehash至ht[1],再将rehashidx属性的值设为-1来表示 rehash操作已完成。
渐进式 rehash的思想在于将rehash键值对所需的计算工作分散到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式rehash而带来的阻塞问题。
看到这里不禁去想这种捎带脚式的rehash会不会导致整个过程非常漫长?如果某个value一直没有操作那么需要扩容时由于一直不用所以影响不大,需要缩容时如果一直不处理可能造成内存浪费,具体的还没来得及研究,先埋个问题吧!
0x05. 讲讲4.0之前版本的Redis的单线程运行模式
5.1 单线程模式的考量
CPU并非瓶颈:多线程模型主要是为了充分利用多核CPU,让线程在IO阻塞时被挂起让出CPU使用权交给其他线程,充分提高CPU的使用率,但是这个场景在Redis并不明显,因为CPU并不是Redis的瓶颈,Redis的所有操作都是基于内存的,处理事件极快,因此使用多线程来切换线程提高CPU利用率的需求并不强烈;
内存才是瓶颈:单个Redis实例对单核的利用已经很好了,但是Redis的瓶颈在于内存,设想64核的机器假如内存只有16GB,那么多线程Redis有什么用武之地?
复杂的Value类型:Redis有丰富的数据结构,并不是简单的Key-Value型的NoSQL,这也是Redis备受欢迎的原因,其中常用的Hash、Zset、List等结构在value很大时,CURD的操作会很复杂,如果采用多线程模式在进行相同key操作时就需要加锁来进行同步,这样就可能造成死锁问题。
集群化扩展:目前的机器都是多核的,但是内存一般128GB/64GB算是比较普遍了,但是Redis在使用内存60%以上稳定性就不如50%的性能了(至少笔者在使用集群化Redis时超过70%时,集群failover的频率会更高),因此在数据较大时,当Redis作为主存,就必须使用多台机器构建集群化的Redis数据库系统,这样以来Redis的单线程模式又被集群化的处理所扩展了;
软件工程角度:单线程无论从开发和维护都比多线程要容易非常多,并且也能提高服务的稳定性,无锁化处理让单线程的Redis在开发和维护上都具备相当大的优势;
类Redis系统:Redis的设计秉承实用第一和工程化,虽然有很多理论上优秀的设计模式,但是并不一定适用自己,软件设计过程就是权衡的过程。业内也有许多类Redis的NoSQL,比如360基础架构组开发的Pika系统,基于SSD和Rocks存储引擎,上层封装一层协议转换,来实现Redis所有功能的模拟,感兴趣的可以研究和使用。
5.2 Redis的文件事件和时间事件
时间事件
定时事件:任务在等待指定大小的等待时间之后就执行,执行完成就不再执行,只触发一次;
周期事件:任务每隔一定时间就执行,执行完成之后等待下一次执行,会周期性的触发;
周期性时间事件
删除数据库的key
触发RDB和AOF持久化
主从同步
集群化保活
关闭清理死客户端链接
统计更新服务器的内存、key数量等信息
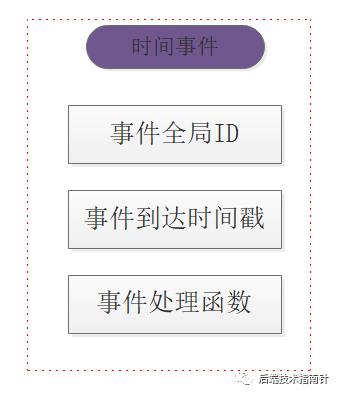
时间事件的无序链表
事件ID 全局唯一 依次递增
触发时间戳 ms级精度
事件处理函数 事件回调函数
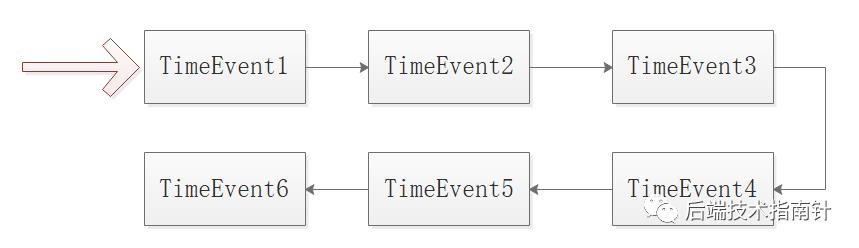
5.3 单线程模式中事件调度和执行
事件执行调度规则
事件执行调度的代码实现
int aeProcessEvents(aeEventLoop *eventLoop, int flags){int processed = 0, numevents;if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS))return 0;if (eventLoop->maxfd != -1 ||((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {int j;aeTimeEvent *shortest = NULL;struct timeval tv, *tvp;if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))shortest = aeSearchNearestTimer(eventLoop);if (shortest) {long now_sec, now_ms;aeGetTime(&now_sec, &now_ms);tvp = &tv;long long ms =(shortest->when_sec - now_sec)*1000 +shortest->when_ms - now_ms;if (ms > 0) {tvp->tv_sec = ms/1000;tvp->tv_usec = (ms % 1000)*1000;} else {tvp->tv_sec = 0;tvp->tv_usec = 0;}} else {if (flags & AE_DONT_WAIT) {tv.tv_sec = tv.tv_usec = 0;tvp = &tv;} else {tvp = NULL; /* wait forever */}}numevents = aeApiPoll(eventLoop, tvp);if (eventLoop->aftersleep != NULL && flags & AE_CALL_AFTER_SLEEP)eventLoop->aftersleep(eventLoop);for (j = 0; j < numevents; j++) {aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];int mask = eventLoop->fired[j].mask;int fd = eventLoop->fired[j].fd;int fired = 0;int invert = fe->mask & AE_BARRIER;if (!invert && fe->mask & mask & AE_READABLE) {fe->rfileProc(eventLoop,fd,fe->clientData,mask);fired++;}if (fe->mask & mask & AE_WRITABLE) {if (!fired || fe->wfileProc != fe->rfileProc) {fe->wfileProc(eventLoop,fd,fe->clientData,mask);fired++;}}if (invert && fe->mask & mask & AE_READABLE) {if (!fired || fe->wfileProc != fe->rfileProc) {fe->rfileProc(eventLoop,fd,fe->clientData,mask);fired++;}}processed++;}}/* Check time events */if (flags & AE_TIME_EVENTS)processed += processTimeEvents(eventLoop);return processed;}
事件执行和调度的伪码
def aeProcessEvents()#获取当前最近的待执行的时间事件time_event = aeGetNearestTimer()#计算最近执行事件与当前时间的差值remain_gap_time = time_event.when - uinx_time_now()#判断时间事件是否已经到期 则重置 马上执行if remain_gap_time < 0:remain_gap_time = 0#阻塞等待文件事件 具体的阻塞等待时间由remain_gap_time决定#如果remain_gap_time为0 那么不阻塞立刻返回aeApiPoll(remain_gap_time)#处理所有文件事件ProcessAllFileEvent()#处理所有时间事件ProcessAllTimeEvent()
事件调度和执行流程
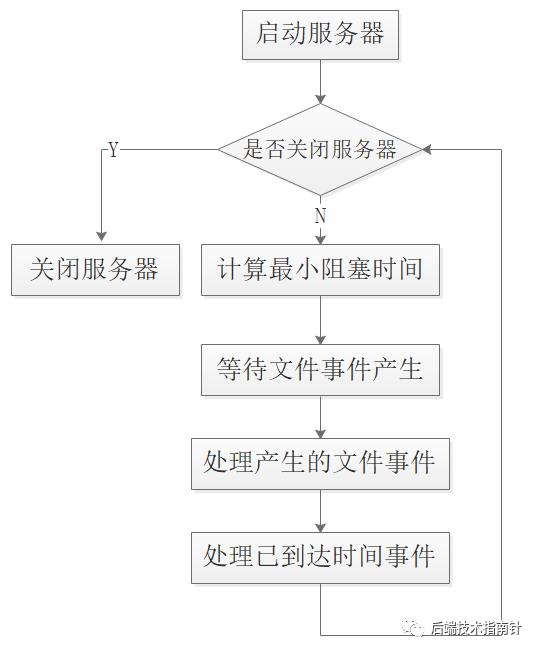
0x06. 谈谈对Redis的反应堆模式的认识
为什么要使用Reactor模式呢?
Redis如何实现自己的Reactor模式?
6.1 Reactor模式
epoll/kqueue将收集到的可读写事件全部放入队列中等待业务线程的处理,此时线程池的工作线程拿到任务进行处理,实际场景中可能有很多种请求类型,工作线程每拿到一种任务就进行相应的处理,处理完成之后继续处理其他类型的任务
工作线程需要关注各种不同类型的请求,对于不同的请求选择不同的处理方法,因此请求类型的增加会让工作线程复杂度增加,维护起来也变得越来越困难
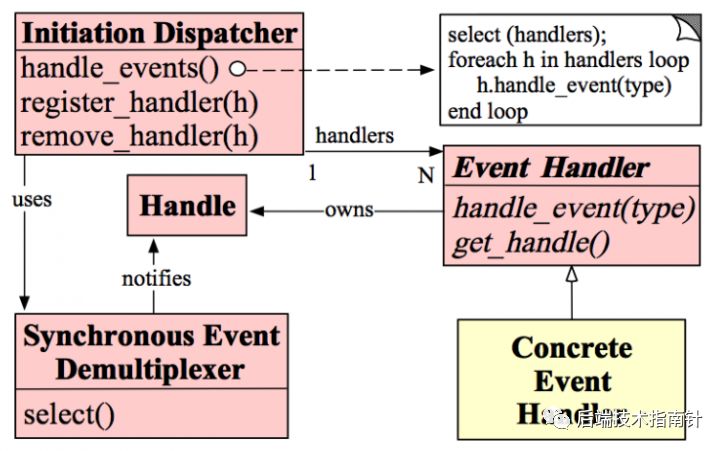
handle 可以理解为读写事件 可以注册到Reactor进行监控
Sync event demultiplexer 可以理解为epoll/kqueue/select等作为IO事件的采集器
Dispatcher 提供注册/删除事件并进行分发,作为事件分发器
Event Handler 事件处理器 完成具体事件的回调 供Dispatcher调用
Concrete Event Handler 具体请求处理函数
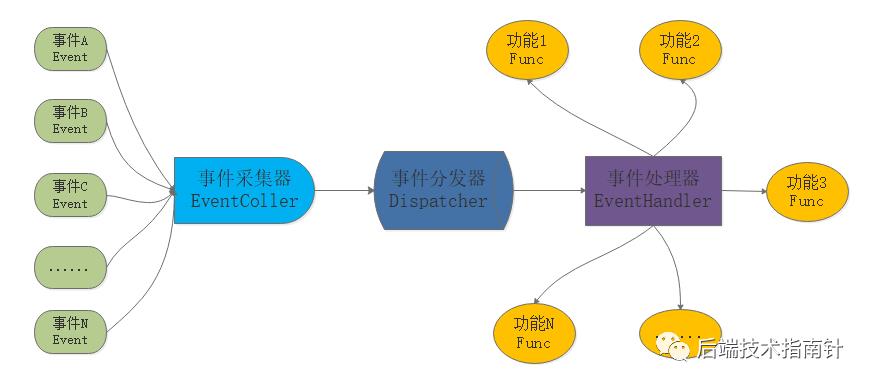
6.2 Reactor模式在Redis中的实现

Redis的IO复用的选择
#ifdef HAVE_EVPORT#include "ae_evport.c"#else#ifdef HAVE_EPOLL#include "ae_epoll.c"#else#ifdef HAVE_KQUEUE#include "ae_kqueue.c"#else#include "ae_select.c"#endif#endif#endif
Redis的任务事件队列
Redis事件分派器
AE_READABLE 客户端写数据、关闭连接、新连接到达
AE_WRITEABLE 客户端读数据
特别地,当一个套接字连接同时可读可写时,服务器会优先处理读事件再处理写事件,也就是读优先。
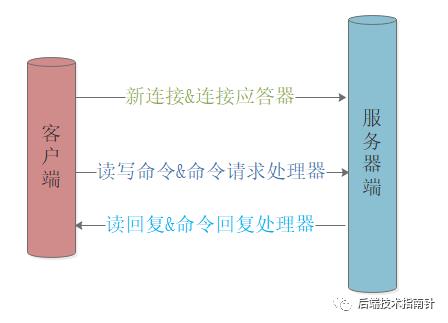
Redis事件处理器
连接应答处理器:实现新连接的建立
命令请求处理器:处理客户端的新命令
命令回复处理器:返回客户端的请求结果
复制处理器:实现主从服务器的数据复制
Redis C/S一次完整的交互
0x07. Redis是如何做持久化的及其基本原理
通俗讲持久化就是将内存中的数据写入非易失介质中,比如机械磁盘和SSD。
在服务器发生宕机时,作为内存数据库Redis里的所有数据将会丢失,因此Redis提供了持久化两大利器:RDB和AOF
RDB 将数据库快照以二进制的方式保存到磁盘中。
AOF 以协议文本方式,将所有对数据库进行过写入的命令和参数记录到 AOF 文件,从而记录数据库状态。
查看RDB配置
[redis@abc]$ cat /abc/redis/conf/redis.confsave 900 1save 300 10save 60 10000dbfilename "dump.rdb"dir "/data/dbs/redis/rdbstro"
前三行都是对触发RDB的一个条件, 如第一行表示每900秒钟有一条数据被修改则触发RDB,依次类推;只要一条满足就会进行RDB持久化;
第四行dbfilename指定了把内存里的数据库写入本地文件的名称,该文件是进行压缩后的二进制文件;
第五行dir指定了RDB二进制文件存放目录 ;
修改RDB配置
[redis@abc]$ bin/redis-cliCONFIG GET save1) "save"2) "900 1 300 10 60 10000"CONFIG SET save "21600 1000"OK
7.1 RDB的SAVE和BGSAVE
如图展示了bgsave的简单流程:
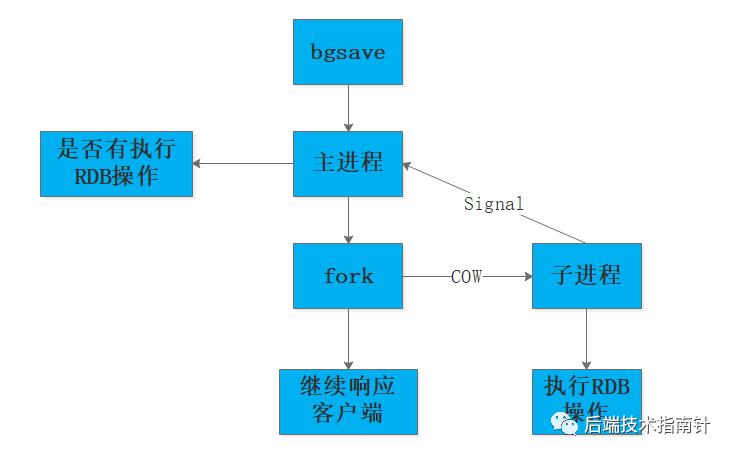
BGSAVE实现细节
Redis使用fork函数创建子进程;
父进程继续接收并处理命令请求,子进程将内存数据写入临时文件;
子进程写入所有数据后会用临时文件替换旧RDB文件;
执行fork的时OS会使用写时拷贝策略,对子进程进行快照过程优化。
我们可以通过定时备份RDB文件来实现Redis数据库备份,RDB文件是经过压缩的,占用的空间会小于内存中的数据大小。
除了自动快照还可以手动发送SAVE或BGSAVE命令让Redis执行快照。通过RDB方式实现持久化,由于RDB保存频率的限制,如果数据很重要则考虑使用AOF方式进行持久化。
7.2 AOF详解
[redis@abc]$ more appendonly.aof*2 # 2个参数$6 # 第一个参数长度为 6SELECT # 第一个参数$1 # 第二参数长度为 18 # 第二参数*3 # 3个参数$3 # 第一个参数长度为 4SET # 第一个参数$4 # 第二参数长度为 4name # 第二个参数$4 # 第三个参数长度为 4Jhon # 第二参数长度为 4
AOF配置:
[redis@abc]$ more ~/redis/conf/redis.confdir "/data/dbs/redis/abcd" #AOF文件存放目录appendonly yes #开启AOF持久化,默认关闭appendfilename "appendonly.aof" #AOF文件名称(默认)appendfsync no #AOF持久化策略auto-aof-rewrite-percentage 100 #触发AOF文件重写的条件(默认)auto-aof-rewrite-min-size 64mb #触发AOF文件重写的条件(默认)
always:服务器在每执行一个事件就把AOF缓冲区的内容强制性的写入硬盘上的AOF文件里,保证了数据持久化的完整性,效率是最慢的但最安全的;
everysec:服务端每隔一秒才会进行一次文件同步把内存缓冲区里的AOF缓存数据真正写入AOF文件里,兼顾了效率和完整性,极端情况服务器宕机只会丢失一秒内对Redis数据库的写操作;
no:表示默认系统的缓存区写入磁盘的机制,不做程序强制,数据安全性和完整性差一些。
执行set hello world 50次
最后执行一次 set hello china
最终对于AOF文件而言前面50次都是无意义的,AOF重写就是将key只保存最后的状态。
重写期间的数据一致性问题
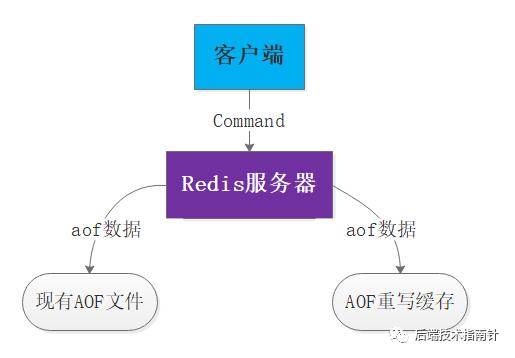
将 AOF 重写缓存中的内容全部写入到新 AOF 文件中
对新的 AOF 文件进行改名,覆盖原有的 AOF 文件
AOF重写的阻塞性
当前 AOF 文件大小
最后一次 重写之后, AOF 文件大小的变量
AOF文件大小增长百分比
没有 BGSAVE 命令在进行 防止于RDB的冲突
没有 BGREWRITEAOF 在进行 防止和手动AOF冲突
当前 AOF 文件大小至少大于设定值 基本要求 太小没意义
当前 AOF 文件大小和最后一次 AOF 重写后的大小之间的比率大于等于指定的增长百分比
7.3 Redis的数据恢复
Redis的数据恢复优先级
如果只配置 AOF ,重启时加载 AOF 文件恢复数据;
如果同时配置了 RDB 和 AOF ,启动只加载 AOF 文件恢复数据;
如果只配置 RDB,启动将加载 dump 文件恢复数据。
RDB是每隔一段时间持久化一次, 故障时就会丢失宕机时刻与上一次持久化之间的数据,无法保证数据完整性
AOF存储的是指令序列, 恢复重放时要花费很长时间并且文件更大
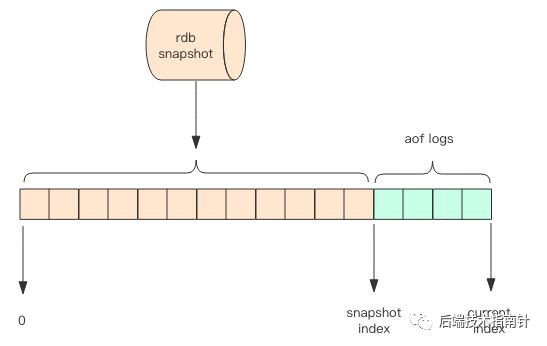
持久化实战
最安全的做法是RDB与AOF同时使用,即使AOF损坏无法修复,还可以用RDB来恢复数据,当然在持久化时对性能也会有影响。
Redis当简单缓存,没有缓存也不会造成缓存雪崩只使用RDB即可。
不推荐单独使用AOF,因为AOF对于数据的恢复载入比RDB慢,所以使用AOF的时候,最好还是有RDB作为备份。
采用新版本Redis 4.0的持久化新方案。
0x08.谈谈Redis的ZIPLIST的底层设计和实现
先不看Redis的对ziplist的具体实现,我们先来想一下如果我们来设计这个数据结构需要做哪些方面的考虑呢?思考式地学习收获更大呦!
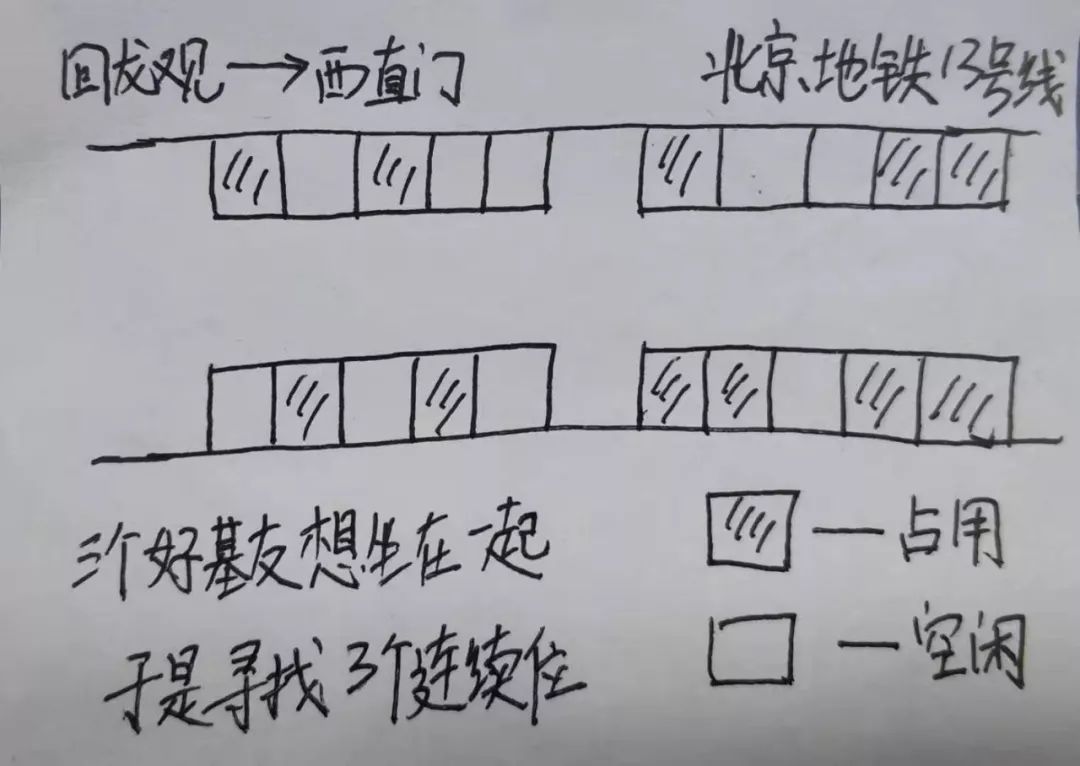
考虑点1:连续内存的双面性
连续型内存减少了内存碎片,但是连续大内存又不容易满足。这个非常好理解,你和好基友三人去做地铁,你们三个挨着坐肯定不浪费空间,但是地铁里很多人都是单独出行的,大家都不愿意紧挨着,就这样有2个的位置有1个的位置,可是3个连续的确实不好找呀,来张图:
考虑点2: 压缩列表承载元素的多样性
待设计结构和数组不一样,数组是已经强制约定了类型,所以我们可以根据元素类型和个数来确定索引的偏移量,但是压缩列表对元素的类型没有约束,也就是说不知道是什么数据类型和长度,这个有点像TCP粘包拆包的做法了,需要我们指定结尾符或者指定单个存储的元素的长度,要不然数据都粘在一起了。
考虑点3:属性的常数级耗时获取
就是说我们解决了前面两点考虑,但是作为一个整体,压缩列表需要常数级消耗提供一些总体信息,比如总长度、已存储元素数量、尾节点位置(实现尾部的快速插入和删除)等,这样对于操作压缩列表意义很大。
考虑点4:数据结构对增删的支持
理论上我们设计的数据结构要很好地支持增删操作,当然凡事必有权衡,没有什么数据结构是完美的,我们边设计边调整吧。
考虑点5:如何节约内存
我们要节约内存就需要特殊情况特殊处理,所谓变长设计,也就是不像双向链表一样固定使用两个pre和next指针来实现,这样空间消耗更大,因此可能需要使用变长编码。
ziplist总体结构
大概想了这么多,我们来看看Redis是如何考虑的,笔者又画了一张总览简图:
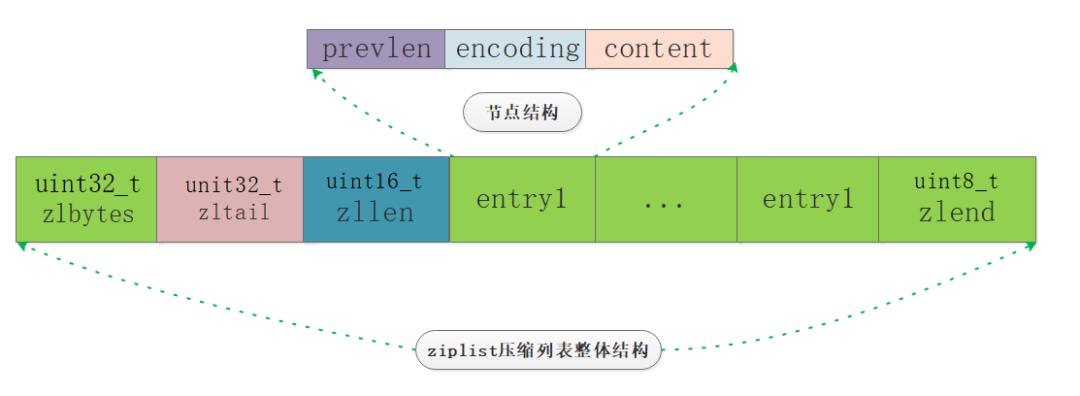
从图中我们基本上可以看到几个主要部分:zlbytes、zltail、zllen、zlentry、zlend。
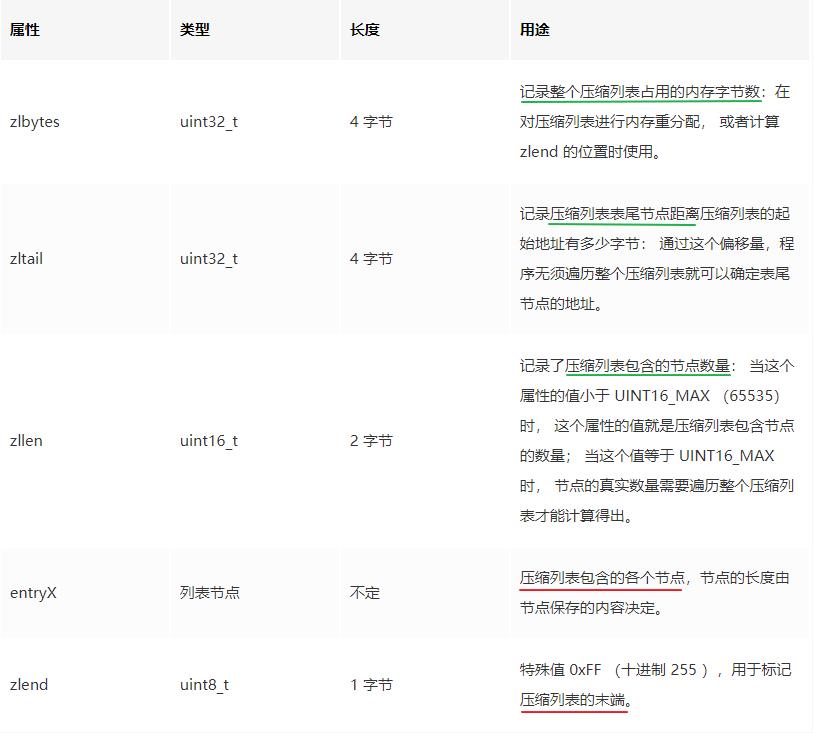
来解释一下各个属性的含义,借鉴网上一张非常好的图,其中红线验证了我们的考虑点2、绿线验证了我们的考虑点3:
来看下ziplist.c中对ziplist的申请和扩容操作,加深对上面几个属性的理解:
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
/* Resize the ziplist. */
unsigned char *ziplistResize(unsigned char *zl, unsigned int len) {
zl = zrealloc(zl,len);
ZIPLIST_BYTES(zl) = intrev32ifbe(len);
zl[len-1] = ZIP_END;
return zl;
}zlentry的实现
encoding编码和content存储
我们再来看看zlentry的实现,encoding的具体内容取决于content的类型和长度,其中当content是字符串时encoding的首字节的高2bit表示字符串类型,当content是整数时,encoding的首字节高2bit固定为11,从Redis源码的注释中可以看的比较清楚,笔者对再做一层汉语版的注释:
/*
###########字符串存储详解###############
#### encoding部分分为三种类型:1字节、2字节、5字节 ####
#### 最高2bit表示是哪种长度的字符串 分别是00 01 10 各自对应1字节 2字节 5字节 ####
#### 当最高2bit=00时 表示encoding=1字节 剩余6bit 2^6=64 可表示范围0~63####
#### 当最高2bit=01时 表示encoding=2字节 剩余14bit 2^14=16384 可表示范围0~16383####
#### 当最高2bit=11时 表示encoding=5字节 比较特殊 用后4字节 剩余32bit 2^32=42亿多####
* |00pppppp| - 1 byte
* String value with length less than or equal to 63 bytes (6 bits).
* "pppppp" represents the unsigned 6 bit length.
* |01pppppp|qqqqqqqq| - 2 bytes
* String value with length less than or equal to 16383 bytes (14 bits).
* IMPORTANT: The 14 bit number is stored in big endian.
* |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes
* String value with length greater than or equal to 16384 bytes.
* Only the 4 bytes following the first byte represents the length
* up to 32^2-1. The 6 lower bits of the first byte are not used and
* are set to zero.
* IMPORTANT: The 32 bit number is stored in big endian.
*########################字符串存储和整数存储的分界线####################*
*#### 高2bit固定为11 其后2bit 分别为00 01 10 11 表示存储的整数类型
* |11000000| - 3 bytes
* Integer encoded as int16_t (2 bytes).
* |11010000| - 5 bytes
* Integer encoded as int32_t (4 bytes).
* |11100000| - 9 bytes
* Integer encoded as int64_t (8 bytes).
* |11110000| - 4 bytes
* Integer encoded as 24 bit signed (3 bytes).
* |11111110| - 2 bytes
* Integer encoded as 8 bit signed (1 byte).
* |1111xxxx| - (with xxxx between 0000 and 1101) immediate 4 bit integer.
* Unsigned integer from 0 to 12. The encoded value is actually from
* 1 to 13 because 0000 and 1111 can not be used, so 1 should be
* subtracted from the encoded 4 bit value to obtain the right value.
* |11111111| - End of ziplist special entry.
*/content保存节点内容,其内容可以是字节数组和各种类型的整数,它的类型和长度决定了encoding的编码,对照上面的注释来看两个例子吧:

保存字节数组:编码的最高两位00表示节点保存的是一个字节数组,编码的后六位001011记录了字节数组的长度11,content 属性保存着节点的值 "hello world"。

保存整数:编码为11000000表示节点保存的是一个int16_t类型的整数值,content属性保存着节点的值10086。
prevlen属性
最后来说一下prevlen这个属性,该属性也比较关键,前面一直在说压缩列表是为了节约内存设计的,然而prevlen属性就恰好起到了这个作用,回想一下链表要想获取前面的节点需要使用指针实现,压缩列表由于元素的多样性也无法像数组一样来实现,所以使用prevlen属性记录前一个节点的大小来进行指向。
prevlen属性以字节为单位,记录了压缩列表中前一个节点的长度,其长度可以是 1 字节或者 5 字节:
如果前一节点的长度小于254字节,那么prevlen属性的长度为1字节, 前一节点的长度就保存在这一个字节里面。
如果前一节点的长度大于等于254字节,那么prevlen属性的长度为5字节,第一字节会被设置为0xFE,之后的四个字节则用于保存前一节点的长度。
思考:注意一下这里的第一字节设置的是0xFE而不是0xFF,想下这是为什么呢?
没错!前面提到了zlend是个特殊值设置为0xFF表示压缩列表的结束,因此这里不可以设置为0xFF,关于这个问题在redis有个issue,有人提出来antirez的ziplist中的注释写的不对,最终antirez发现注释写错了,然后愉快地修改了,哈哈!
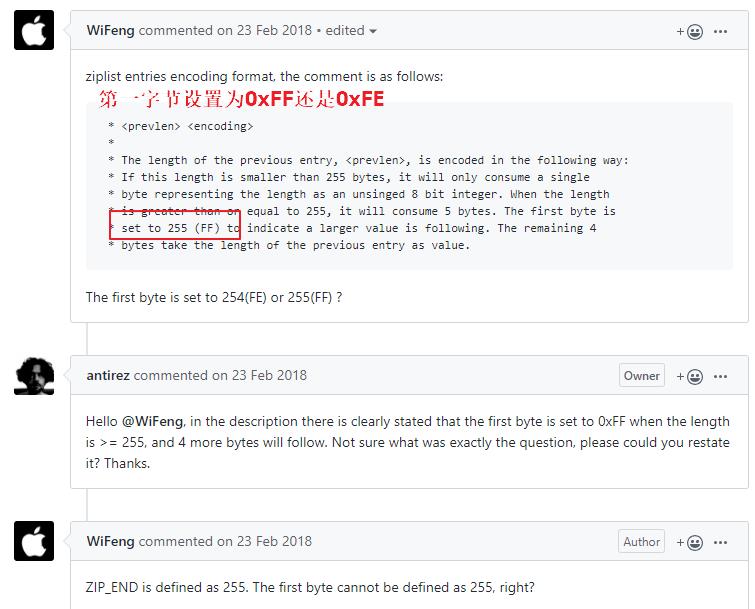
再思考一个问题,为什么prevlen的长度要么是1字节要么是5字节呢?为啥没有2字节、3字节、4字节这些中间态的长度呢?要解答这个问题就引出了今天的一个关键问题:连锁更新问题。
连锁更新问题
试想这样一种增加节点的场景:
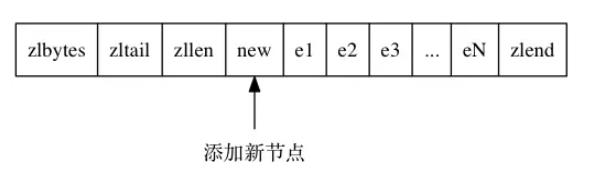
如果在压缩列表的头部增加一个新节点,并且长度大于254字节,所以其后面节点的prevlen必须是5字节,然而在增加新节点之前其prevlen是1字节,必须进行扩展,极端情况下如果一直都需要扩展那么将产生连锁反应:
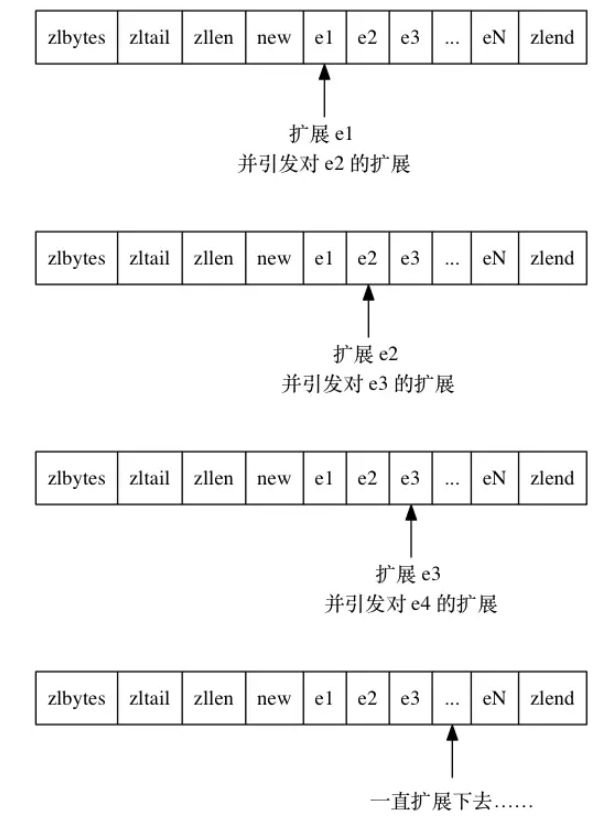
试想另外一种删除节点的场景:
如果需要删除的节点时小节点,该节点前面的节点是大节点,这样当把小节点删除时,其后面的节点就要保持其前面大节点的长度,面临着扩展的问题:
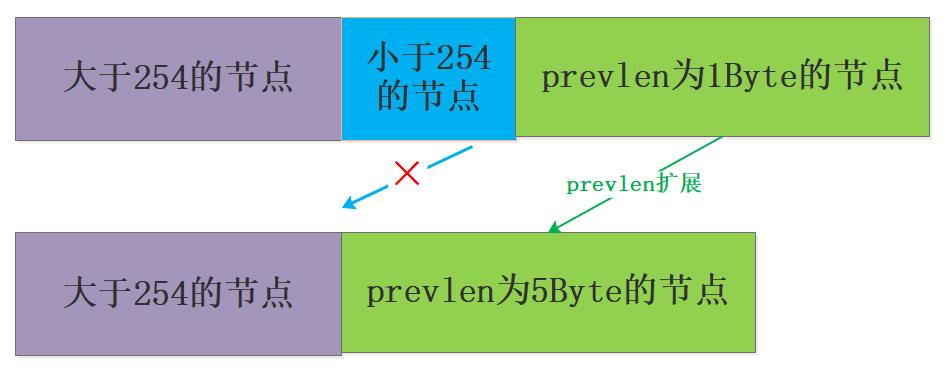
理解了连锁更新问题,再来看看为什么要么1字节要么5字节的问题吧,如果是2-4字节那么可能产生连锁反应的概率就更大了,相反直接给到最大5字节会大大降低连锁更新的概率,所以笔者也认为这种内存的小小浪费也是值得的。
从ziplist的设计来看,压缩列表并不擅长修改操作,这样会导致内存拷贝问题,并且当压缩列表存储的数据量超过某个阈值之后查找指定元素带来的遍历损耗也会增加。
0x09.谈谈Redis的Zset和跳跃链表问题
typedef struct zset {dict *dict;zskiplist *zsl;} zset;
ZSet中的字典和跳表布局:
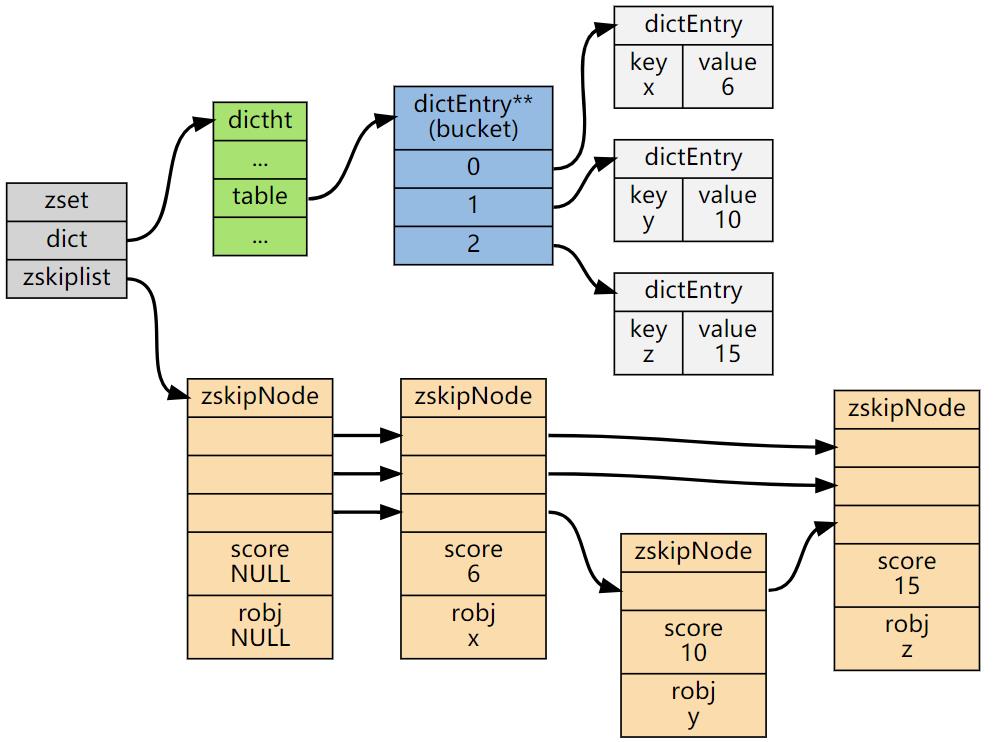
注:图片源自网络
9.1 ZSet中跳跃链表的实现细节
随机层数的实现原理
指定节点最大层数 MaxLevel,指定概率 p, 默认层数 lvl 为1
生成一个0~1的随机数r,若r<p,且lvl<MaxLevel ,则lvl ++
重复第 2 步,直至生成的r >p 为止,此时的 lvl 就是要插入的层数。
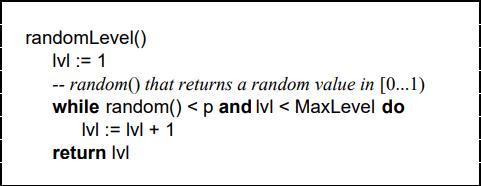
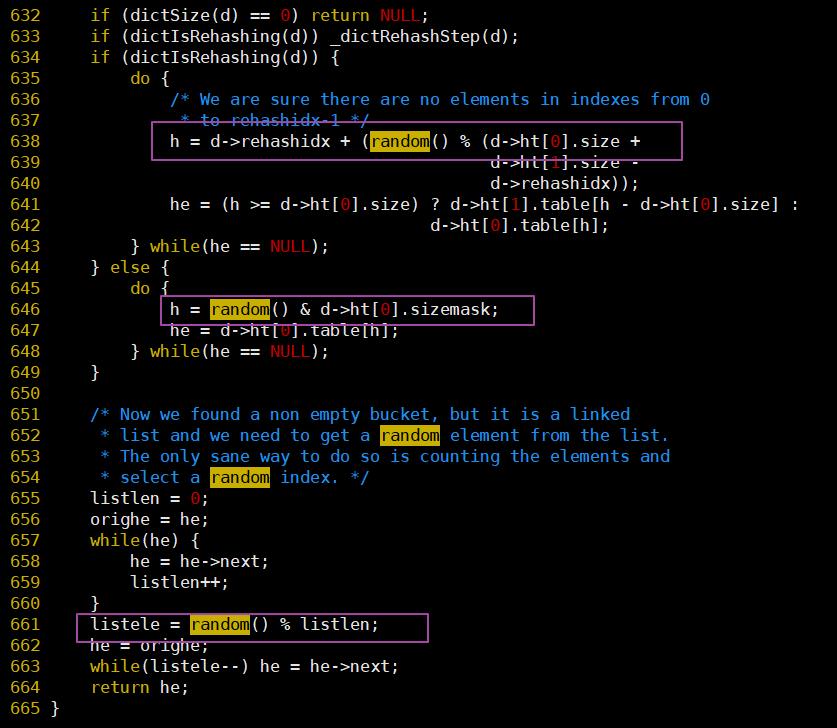
/* Returns a random level for the new skiplist node we are going to create.* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL* (both inclusive), with a powerlaw-alike distribution where higher* levels are less likely to be returned. */int zslRandomLevel(void) {int level = 1;while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))level += 1;return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;}
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
(random()&0xFFFF) < (ZSKIPLIST_P*0xFFFF)
random()在dict.c中的使用
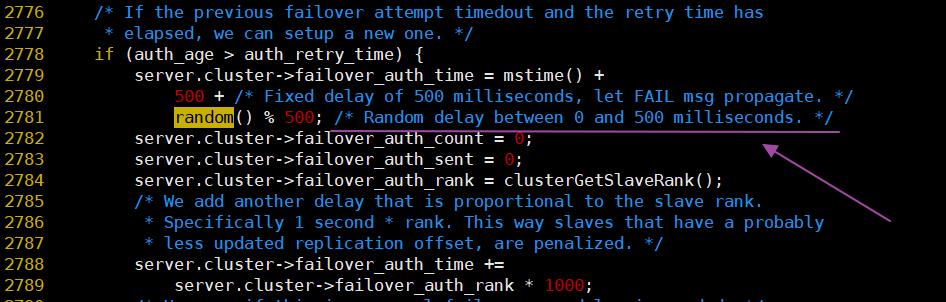
random()在cluster.c中的使用
ZSKIPLIST_P*0xFFFFtemplate <typename Key, typename Value>int SkipList<Key, Value>::randomLevel() {static const unsigned int kBranching = 4;int height = 1;while (height < kMaxLevel && ((::Next(rnd_) % kBranching) == 0)) {height++;}assert(height > 0);assert(height <= kMaxLevel);return height;}uint32_t Next( uint32_t& seed) {seed = seed & 0x7fffffffu;if (seed == 0 || seed == 2147483647L) {seed = 1;}static const uint32_t M = 2147483647L;static const uint64_t A = 16807;uint64_t product = seed * A;seed = static_cast<uint32_t>((product >> 31) + (product & M));if (seed > M) {seed -= M;}return seed;}
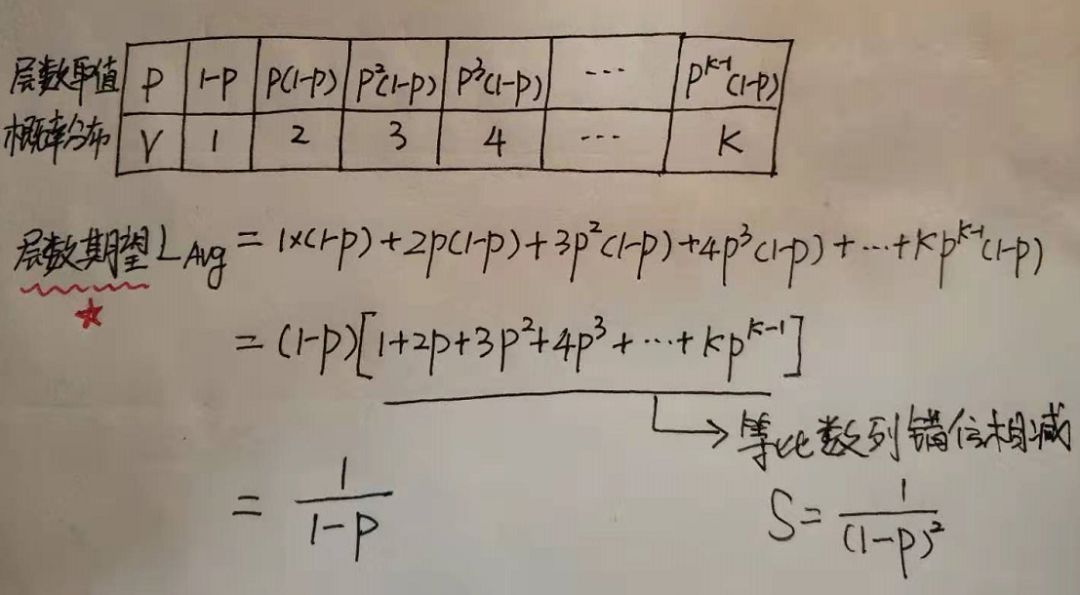
跳表结点的平均层数
如果某件事的发生频率和它的某个属性成幂关系,那么这个频率就可以称之为符合幂次定律。幂次定律的表现是少数几个事件的发生频率占了整个发生频率的大部分, 而其余的大多数事件只占整个发生频率的一个小部分。
节点层数至少为1,大于1的节点层数满足一个概率分布。
节点层数恰好等于1的概率为p^0(1-p)。
节点层数恰好等于2的概率为p^1(1-p)。
节点层数恰好等于3的概率为p^2(1-p)。
节点层数恰好等于4的概率为p^3(1-p)。
依次递推节点层数恰好等于K的概率为p^(k-1)(1-p)
0x0A.谈谈集群版Redis和Gossip协议
A.1 关于集群的一些基础
单实例Redis架构
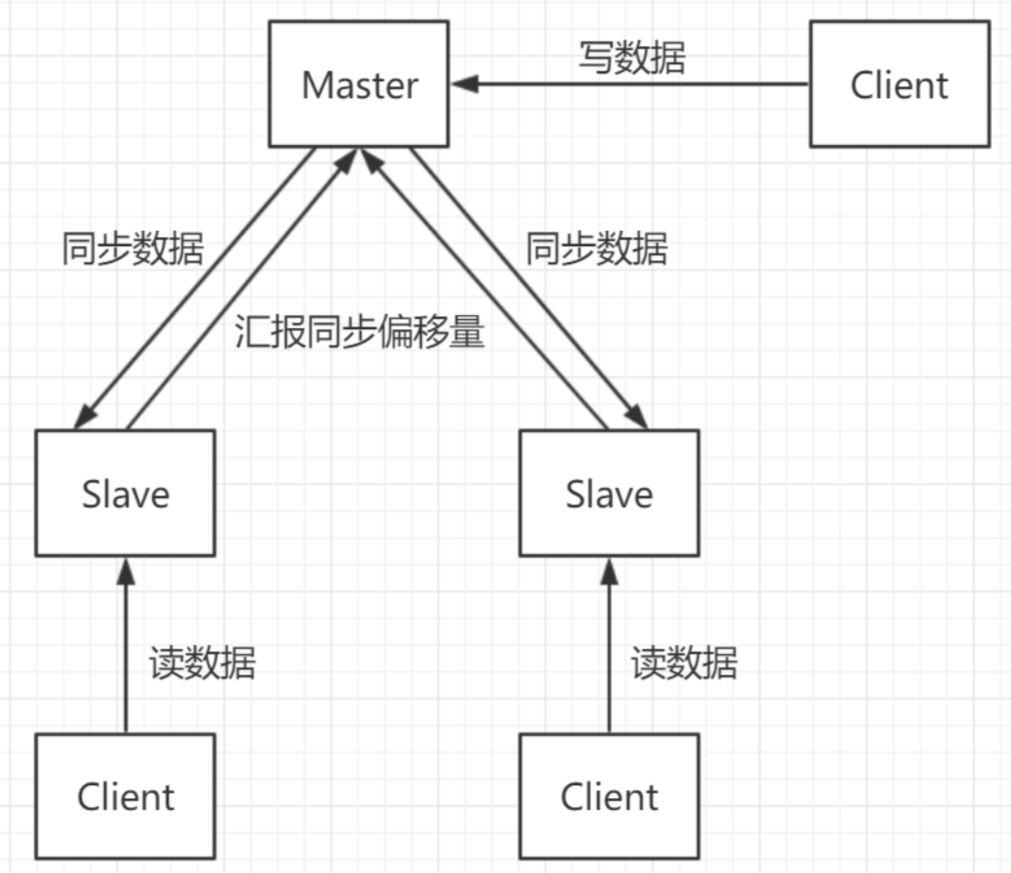
注:图片来自网络
集群与分片
客户端分片:这种情况主要是类似于哈希取模的做法,当客户端对服务端的数量完全掌握和控制时,可以简单使用。
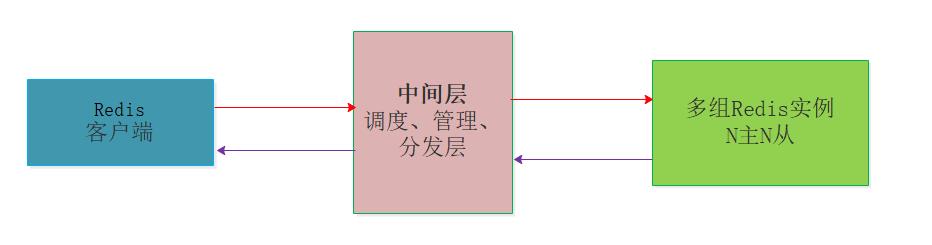
中间层分片:这种情况是在客户端和服务器端之间增加中间层,充当管理者和调度者,客户端的请求打向中间层,由中间层实现请求的转发和回收,当然中间层最重要的作用是对多台服务器的动态管理。
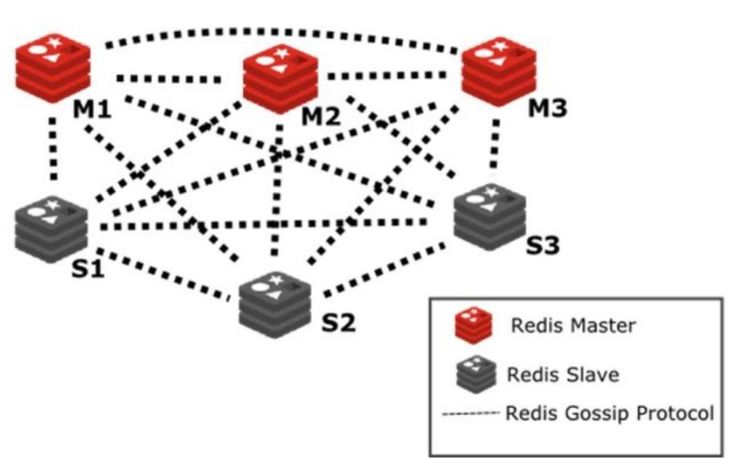
服务端分片:不使用中间层实现去中心化的管理模式,客户端直接向服务器中任意结点请求,如果被请求的Node没有所需数据,则像客户端回复MOVED,并告诉客户端所需数据的存储位置,这个过程实际上是客户端和服务端共同配合,进行请求重定向来完成的。
中间层分片的集群版Redis
服务端分片的官方集群版本
注:图片来自网络
A.2 Redis Cluster的基本运行原理
结点状态信息结构
当前集群状态
集群中各节点所负责的slots信息,及其migrate状态
集群中各节点的master-slave状态
集群中各节点的存活状态及不可达投票
Gossip协议的概念
gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议。
在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。
gossip protocol 最初是由施乐公司帕洛阿尔托研究中心(Palo Alto Research Center)的研究员艾伦·德默斯(Alan Demers)于1987年创造的。
https://www.iteblog.com/archives/2505.html
Gossip算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵就是在杂乱无章中寻求一致,这充分说明了Gossip的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,当然这也是疫情传播的特点。
https://www.backendcloud.cn/2017/11/12/raft-gossip/
Gossip协议的使用
Meet 通过「cluster meet ip port」命令,已有集群的节点会向新的节点发送邀请,加入现有集群。
Pong 节点收到 ping 消息后会回复 pong 消息,消息中同样带有自己已知的两个节点信息。
Fail 节点 ping 不通某节点后,会向集群所有节点广播该节点挂掉的消息。其他节点收到消息后标记已下线。
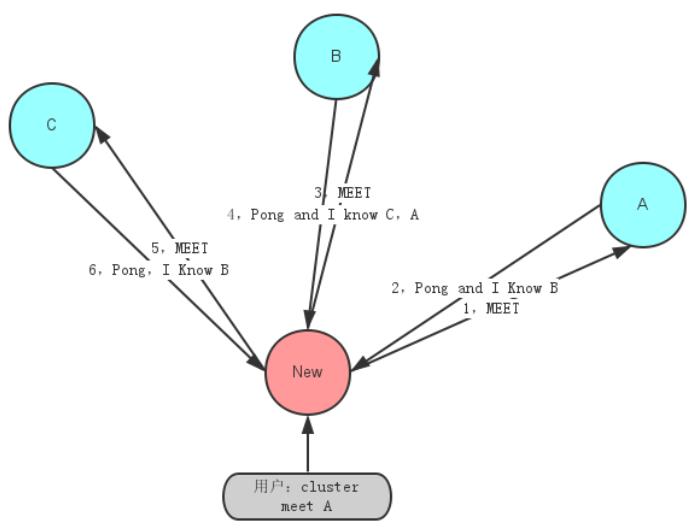
注:图片来自网络
基于Gossip协议的故障检测
有半数以上的主节点将 node 标记为 PFAIL 状态。
当前节点也将 node 标记为 PFAIL 状态。
0x0B.谈谈对Redis的内存回收机制的理解
Redis作为内存型数据库,如果单纯的只进不出早晚就撑爆了,事实上很多把Redis当做主存储DB用的家伙们早晚会尝到这个苦果,当然除非你家厂子确实不差钱,数T级别的内存都毛毛雨,或者数据增长一定程度之后不再增长的场景,就另当别论了。
为了让Redis服务安全稳定的运行,让使用内存保持在一定的阈值内是非常有必要的,因此我们就需要删除该删除的,清理该清理的,把内存留给需要的键值对,试想一条大河需要设置几个警戒水位来确保不决堤不枯竭,Redis也是一样的,只不过Redis只关心决堤即可,来一张图:
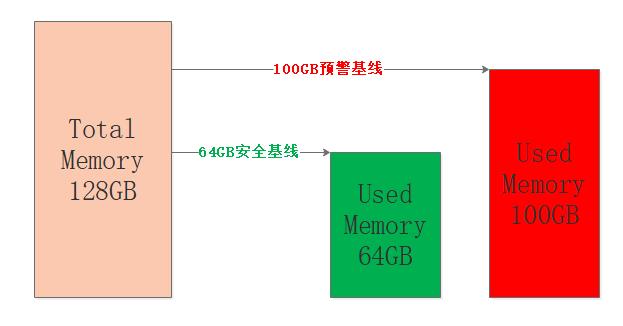
图中设定机器内存为128GB,占用64GB算是比较安全的水平,如果内存接近80%也就是100GB左右,那么认为Redis目前承载能力已经比较大了,具体的比例可以根据公司和个人的业务经验来确定。
笔者只是想表达出于安全和稳定的考虑,不要觉得128GB的内存就意味着存储128GB的数据,都是要打折的。
B.1 回收的内存从哪里来
Redis占用的内存是分为两部分:存储键值对消耗和本身运行消耗。显然后者我们无法回收,因此只能从键值对下手了,键值对可以分为几种:带过期的、不带过期的、热点数据、冷数据。对于带过期的键值是需要删除的,如果删除了所有的过期键值对之后内存仍然不足怎么办?那只能把部分数据给踢掉了。

B.2 如何实施过期键值对的删除
要实施对键值对的删除我们需要明白如下几点:
带过期超时的键值对存储在哪里?
如何判断带超时的键值对是否可以被删除了?
删除机制有哪些以及如何选择?
1.键值对的存储
老规矩来到github看下源码,src/server.h中给的redisDb结构体给出了答案:
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
Redis本质上就是一个大的key-value,key就是字符串,value有是几种对象:字符串、列表、有序列表、集合、哈希等,这些key-value都是存储在redisDb的dict中的,来看下黄健宏画的一张非常赞的图:
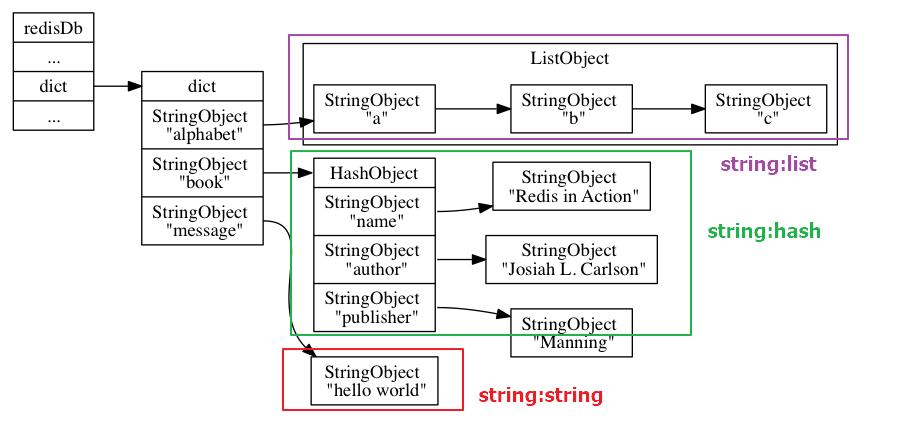
看到这里,对于删除机制又清晰了一步,我们只要把redisDb中dict中的目标key-value删掉就行,不过貌似没有这么简单,Redis对于过期键值对肯定有自己的组织规则,让我们继续研究吧!
redisDb的expires成员的类型也是dict,和键值对是一样的,本质上expires是dict的子集,expires保存的是所有带过期的键值对,称之为过期字典吧,它才是我们研究的重点。
对于键,我们可以设置绝对和相对过期时间、以及查看剩余时间:
使用EXPIRE和PEXPIRE来实现键值对的秒级和毫秒级生存时间设定,这是相对时长的过期设置
使用EXPIREAT和EXPIREAT来实现键值对在某个秒级和毫秒级时间戳时进行过期删除,属于绝对过期设置
通过TTL和PTTL来查看带有生存时间的键值对的剩余过期时间
上述三组命令在设计缓存时用处比较大,有心的读者可以留意。
过期字典expires和键值对空间dict存储的内容并不完全一样,过期字典expires的key是指向Redis对应对象的指针,其value是long long型的unix时间戳,前面的EXPIRE和PEXPIRE相对时长最终也会转换为时间戳,来看下过期字典expires的结构,笔者画了个图:
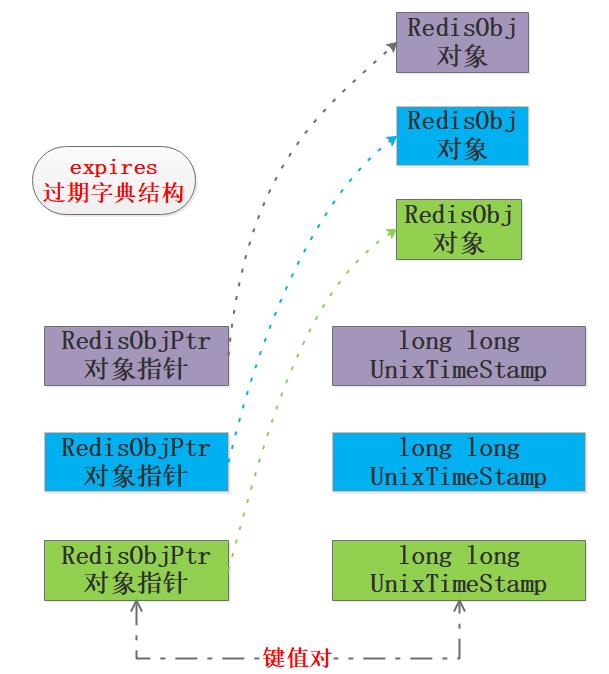
2. 键值对的过期删除判断
判断键是否过期可删除,需要先查过期字典是否存在该值,如果存在则进一步判断过期时间戳和当前时间戳的相对大小,做出删除判断,简单的流程如图:
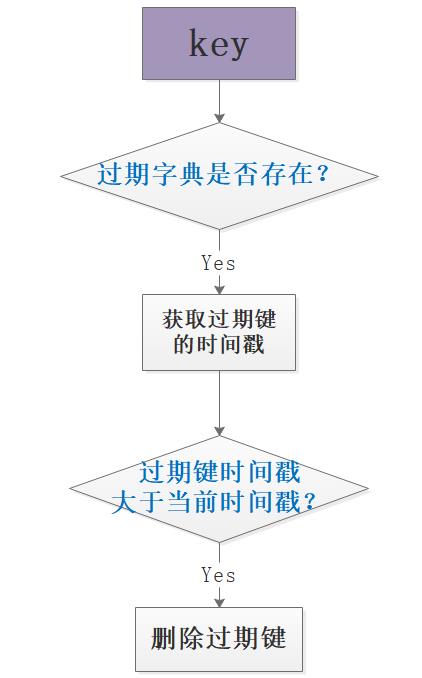
3. 键值对的删除策略
经过前面的几个环节,我们知道了Redis的两种存储位置:键空间和过期字典,以及过期字典expires的结构、判断是否过期的方法,那么该如何实施删除呢?
先抛开Redis来想一下可能的几种删除策略:
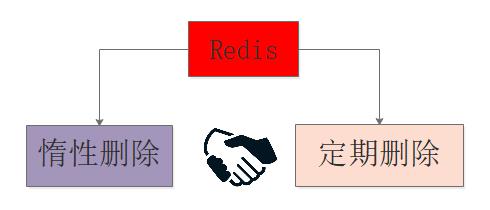
定时删除:在设置键的过期时间的同时,创建定时器,让定时器在键过期时间到来时,即刻执行键值对的删除;
定期删除:每隔特定的时间对数据库进行一次扫描,检测并删除其中的过期键值对;
惰性删除:键值对过期暂时不进行删除,至于删除的时机与键值对的使用有关,当获取键时先查看其是否过期,过期就删除,否则就保留;
在上述的三种策略中定时删除和定期删除属于不同时间粒度的主动删除,惰性删除属于被动删除。
三种策略都有各自的优缺点:定时删除对内存使用率有优势,但是对CPU不友好,惰性删除对内存不友好,如果某些键值对一直不被使用,那么会造成一定量的内存浪费,定期删除是定时删除和惰性删除的折中。
Reids采用的是惰性删除和定时删除的结合,一般来说可以借助最小堆来实现定时器,不过Redis的设计考虑到时间事件的有限种类和数量,使用了无序链表存储时间事件,这样如果在此基础上实现定时删除,就意味着O(N)遍历获取最近需要删除的数据。
但是我觉得antirez如果非要使用定时删除,那么他肯定不会使用原来的无序链表机制,所以个人认为已存在的无序链表不能作为Redis不使用定时删除的根本理由,冒昧猜测唯一可能的是antirez觉得没有必要使用定时删除。
4. 定期删除的实现细节
定期删除听着很简单,但是如何控制执行的频率和时长呢?
试想一下如果执行频率太少就退化为惰性删除了,如果执行时间太长又和定时删除类似了,想想还确实是个难题!并且执行定期删除的时机也需要考虑,所以我们继续来看看Redis是如何实现定期删除的吧!笔者在src/expire.c文件中找到了activeExpireCycle函数,定期删除就是由此函数实现的,在代码中antirez做了比较详尽的注释,不过都是英文的,试着读了一下模模糊糊弄个大概,所以学习英文并阅读外文资料是很重要的学习途径。
先贴一下代码,核心部分算上注释大约210行,具体看下:
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which
we do extra efforts. */
void activeExpireCycle(int type) {
/* Adjust the running parameters according to the configured expire
* effort. The default effort is 1, and the maximum configurable effort
* is 10. */
unsigned long
effort = server.active_expire_effort-1, /* Rescale from 0 to 9. */
config_keys_per_loop = ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP +
ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP/4*effort,
config_cycle_fast_duration = ACTIVE_EXPIRE_CYCLE_FAST_DURATION +
ACTIVE_EXPIRE_CYCLE_FAST_DURATION/4*effort,
config_cycle_slow_time_perc = ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC +
2*effort,
config_cycle_acceptable_stale = ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE-
effort;
/* This function has some global state in order to continue the work
* incrementally across calls. */
static unsigned int current_db = 0; /* Last DB tested. */
static int timelimit_exit = 0; /* Time limit hit in previous call? */
static long long last_fast_cycle = 0; /* When last fast cycle ran. */
int j, iteration = 0;
int dbs_per_call = CRON_DBS_PER_CALL;
long long start = ustime(), timelimit, elapsed;
/* When clients are paused the dataset should be static not just from the
* POV of clients not being able to write, but also from the POV of
* expires and evictions of keys not being performed. */
if (clientsArePaused()) return;
if (type == ACTIVE_EXPIRE_CYCLE_FAST) {
/* Don't start a fast cycle if the previous cycle did not exit
* for time limit, unless the percentage of estimated stale keys is
* too high. Also never repeat a fast cycle for the same period
* as the fast cycle total duration itself. */
if (!timelimit_exit &&
server.stat_expired_stale_perc < config_cycle_acceptable_stale)
return;
if (start < last_fast_cycle + (long long)config_cycle_fast_duration*2)
return;
last_fast_cycle = start;
}
/* We usually should test CRON_DBS_PER_CALL per iteration, with
* two exceptions:
*
* 1) Don't test more DBs than we have.
* 2) If last time we hit the time limit, we want to scan all DBs
* in this iteration, as there is work to do in some DB and we don't want
* expired keys to use memory for too much time. */
if (dbs_per_call > server.dbnum || timelimit_exit)
dbs_per_call = server.dbnum;
/* We can use at max 'config_cycle_slow_time_perc' percentage of CPU
* time per iteration. Since this function gets called with a frequency of
* server.hz times per second, the following is the max amount of
* microseconds we can spend in this function. */
timelimit = config_cycle_slow_time_perc*1000000/server.hz/100;
timelimit_exit = 0;
if (timelimit <= 0) timelimit = 1;
if (type == ACTIVE_EXPIRE_CYCLE_FAST)
timelimit = config_cycle_fast_duration; /* in microseconds. */
/* Accumulate some global stats as we expire keys, to have some idea
* about the number of keys that are already logically expired, but still
* existing inside the database. */
long total_sampled = 0;
long total_expired = 0;
for (j = 0; j < dbs_per_call && timelimit_exit == 0; j++) {
/* Expired and checked in a single loop. */
unsigned long expired, sampled;
redisDb *db = server.db+(current_db % server.dbnum);
/* Increment the DB now so we are sure if we run out of time
* in the current DB we'll restart from the next. This allows to
* distribute the time evenly across DBs. */
current_db++;
/* Continue to expire if at the end of the cycle more than 25%
* of the keys were expired. */
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
iteration++;
/* If there is nothing to expire try next DB ASAP. */
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
slots = dictSlots(db->expires);
now = mstime();
/* When there are less than 1% filled slots, sampling the key
* space is expensive, so stop here waiting for better times...
* The dictionary will be resized asap. */
if (num && slots > DICT_HT_INITIAL_SIZE &&
(num*100/slots < 1)) break;
/* The main collection cycle. Sample random keys among keys
* with an expire set, checking for expired ones. */
expired = 0;
sampled = 0;
ttl_sum = 0;
ttl_samples = 0;
if (num > config_keys_per_loop)
num = config_keys_per_loop;
/* Here we access the low level representation of the hash table
* for speed concerns: this makes this code coupled with dict.c,
* but it hardly changed in ten years.
*
* Note that certain places of the hash table may be empty,
* so we want also a stop condition about the number of
* buckets that we scanned. However scanning for free buckets
* is very fast: we are in the cache line scanning a sequential
* array of NULL pointers, so we can scan a lot more buckets
* than keys in the same time. */
long max_buckets = num*20;
long checked_buckets = 0;
while (sampled < num && checked_buckets < max_buckets) {
for (int table = 0; table < 2; table++) {
if (table == 1 && !dictIsRehashing(db->expires)) break;
unsigned long idx = db->expires_cursor;
idx &= db->expires->ht[table].sizemask;
dictEntry *de = db->expires->ht[table].table[idx];
long long ttl;
/* Scan the current bucket of the current table. */
checked_buckets++;
while(de) {
/* Get the next entry now since this entry may get
* deleted. */
dictEntry *e = de;
de = de->next;
ttl = dictGetSignedIntegerVal(e)-now;
if (activeExpireCycleTryExpire(db,e,now)) expired++;
if (ttl > 0) {
/* We want the average TTL of keys yet
* not expired. */
ttl_sum += ttl;
ttl_samples++;
}
sampled++;
}
}
db->expires_cursor++;
}
total_expired += expired;
total_sampled += sampled;
/* Update the average TTL stats for this database. */
if (ttl_samples) {
long long avg_ttl = ttl_sum/ttl_samples;
/* Do a simple running average with a few samples.
* We just use the current estimate with a weight of 2%
* and the previous estimate with a weight of 98%. */
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
}
/* We can't block forever here even if there are many keys to
* expire. So after a given amount of milliseconds return to the
* caller waiting for the other active expire cycle. */
if ((iteration & 0xf) == 0) { /* check once every 16 iterations. */
elapsed = ustime()-start;
if (elapsed > timelimit) {
timelimit_exit = 1;
server.stat_expired_time_cap_reached_count++;
break;
}
}
/* We don't repeat the cycle for the current database if there are
* an acceptable amount of stale keys (logically expired but yet
* not reclained). */
} while ((expired*100/sampled) > config_cycle_acceptable_stale);
}
elapsed = ustime()-start;
server.stat_expire_cycle_time_used += elapsed;
latencyAddSampleIfNeeded("expire-cycle",elapsed/1000);
/* Update our estimate of keys existing but yet to be expired.
* Running average with this sample accounting for 5%. */
double current_perc;
if (total_sampled) {
current_perc = (double)total_expired/total_sampled;
} else
current_perc = 0;
server.stat_expired_stale_perc = (current_perc*0.05)+
(server.stat_expired_stale_perc*0.95);
}说实话这个代码细节比较多,由于笔者对Redis源码了解不多,只能做个模糊版本的解读,所以难免有问题,还是建议有条件的读者自行前往源码区阅读,抛砖引玉看下笔者的模糊版本:
该算法是个自适应的过程,当过期的key比较少时那么就花费很少的cpu时间来处理,如果过期的key很多就采用激进的方式来处理,避免大量的内存消耗,可以理解为判断过期键多就多跑几次,少则少跑几次;
由于Redis中有很多数据库db,该算法会逐个扫描,本次结束时继续向后面的db扫描,是个闭环的过程;
定期删除有快速循环和慢速循环两种模式,主要采用慢速循环模式,其循环频率主要取决于server.hz,通常设置为10,也就是每秒执行10次慢循环定期删除,执行过程中如果耗时超过25%的CPU时间就停止;
慢速循环的执行时间相对较长,会出现超时问题,快速循环模式的执行时间不超过1ms,也就是执行时间更短,但是执行的次数更多,在执行过程中发现某个db中抽样的key中过期key占比低于25%则跳过;
主体意思:定期删除是个自适应的闭环并且概率化的抽样扫描过程,过程中都有执行时间和cpu时间的限制,如果触发阈值就停止,可以说是尽量在不影响对客户端的响应下润物细无声地进行的。
5. DEL删除键值对
在Redis4.0之前执行del操作时如果key-value很大,那么可能导致阻塞,在新版本中引入了BIO线程以及一些新的命令,实现了del的延时懒删除,最后会有BIO线程来实现内存的清理回收。
B.2 内存淘汰机制
为了保证Redis的安全稳定运行,设置了一个max-memory的阈值,那么当内存用量到达阈值,新写入的键值对无法写入,此时就需要内存淘汰机制,在Redis的配置中有几种淘汰策略可以选择,详细如下:
noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错;
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中移除最近最少使用的 key;
allkeys-random:当内存不足以容纳新写入数据时,在键空间中随机移除某个 key;
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key;
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 key;
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 key 优先移除;
后三种策略都是针对过期字典的处理,但是在过期字典为空时会noeviction一样返回写入失败,毫无策略地随机删除也不太可取,所以一般选择第二种allkeys-lru基于LRU策略进行淘汰。
个人认为antirez一向都是工程化思维,善于使用概率化设计来做近似实现,LRU算法也不例外,Redis中实现了近似LRU算法,并且经过几个版本的迭代效果已经比较接近理论LRU算法的效果了,这个也是个不错的内容,由于篇幅限制,本文计划后续单独讲LRU算法时再进行详细讨论。
过期健删除策略强调的是对过期健的操作,如果有健过期而内存足够,Redis不会使用内存淘汰机制来腾退空间,这时会优先使用过期健删除策略删除过期健。
内存淘汰机制强调的是对内存数据的淘汰操作,当内存不足时,即使有的健没有到达过期时间或者根本没有设置过期也要根据一定的策略来删除一部分,腾退空间保证新数据的写入。
0x0C.谈谈对Redis数据同步机制和原理的理解
理解持久化和数据同步的关系,需要从单点故障和高可用两个角度来分析:
C.1 单点宕机故障
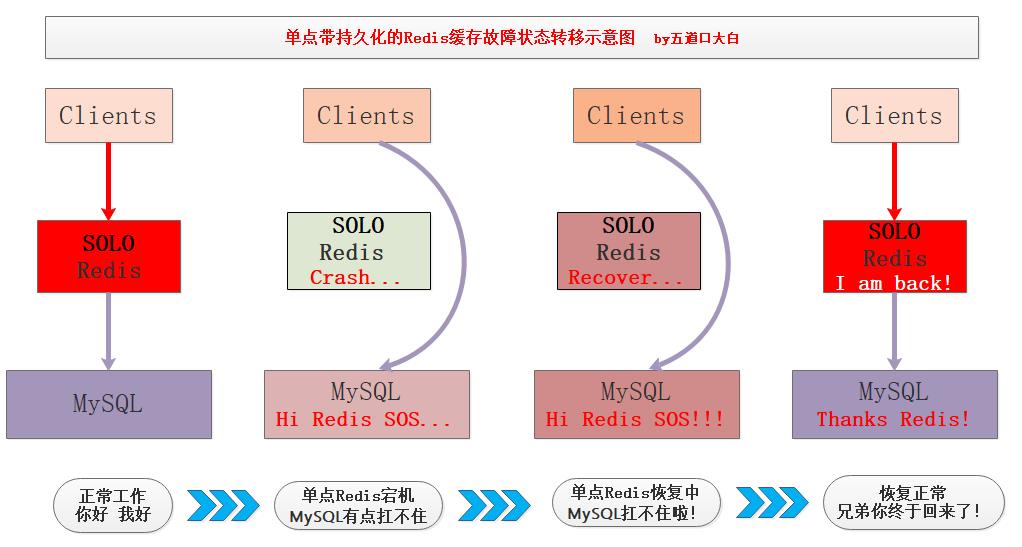
假如我们现在只有一台作为缓存的Redis机器,通过持久化将热点数据写到磁盘,某时刻该Redis单点机器发生故障宕机,此期间缓存失效,主存储服务将承受所有的请求压力倍增,监控程序将宕机Redis机器拉起。
重启之后,该机器可以Load磁盘RDB数据进行快速恢复,恢复的时间取决于数据量的多少,一般秒级到分钟级不等,恢复完成保证之前的热点数据还在,这样存储系统的CacheMiss就会降低,有效降低了缓存击穿的影响。
在单点Redis中持久化机制非常有用,只写文字容易让大家睡着,我画了张图:
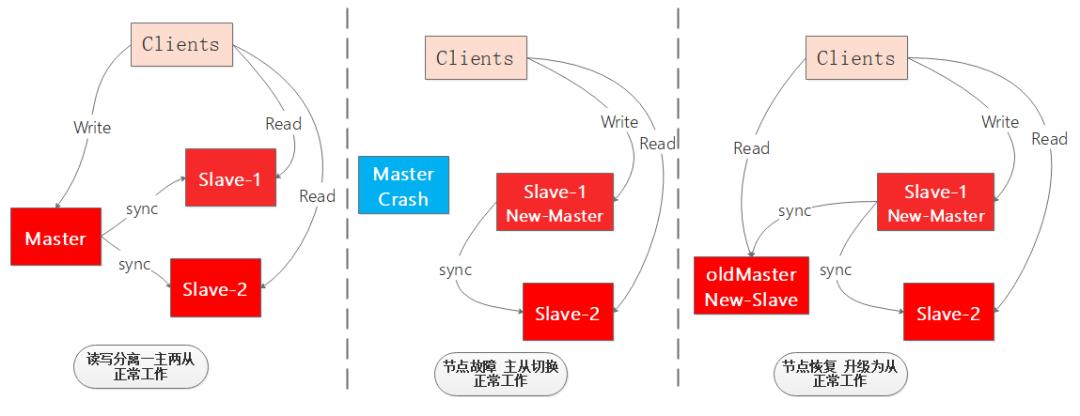
作为一个高可用的缓存系统单点宕机是不允许的,因此就出现了主从架构,对主节点的数据进行多个备份,如果主节点挂点,可以立刻切换状态最好的从节点为主节点,对外提供写服务,并且其他从节点向新主节点同步数据,确保整个Redis缓存系统的高可用。
如图展示了一个一主两从读写分离的Redis系统主节点故障迁移的过程,整个过程并没有停止正常工作,大大提高了系统的高可用:
从上面的两点分析可以得出个小结论【划重点】:
持久化让单点故障不再可怕,数据同步为高可用插上翅膀。
我们理解了数据同步对Redis的重要作用,接下来继续看数据同步的实现原理和过程、重难点等细节问题吧!
C.2 Redis系统中的CAP理论
对分布式存储有了解的读者一定知道CAP理论,说来惭愧笔者在2018年3月份换工作的时候,去Face++旷视科技面后端开发岗位时就遇到了CAP理论,除了CAP理论问题之外其他问题都在射程内,所以最终还是拿了Offer。
在理论计算机科学中,CAP定理又被称作布鲁尔定理Brewer's theorem,这个定理起源于加州大学伯克利分校的计算机科学家埃里克·布鲁尔在2000年的分布式计算原理研讨会PODC上提出的一个猜想。
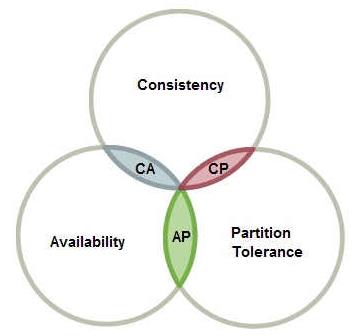
在2002年麻省理工学院的赛斯·吉尔伯特和南希·林奇发表了布鲁尔猜想的证明,使之成为一个定理。它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
C Consistent 一致性 连贯性
A Availability 可用性
P Partition Tolerance 分区容忍性
来看一张阮一峰大佬画的图:
举个简单的例子,说明一下CP和AP的兼容性:
理解CP和AP的关键在于分区容忍性P,网络分区在分布式存储中再平常不过了,即使机器在一个机房,也不可能全都在一个机架或一台交换机。
这样在局域网就会出现网络抖动,笔者做过1年多DPI对于网络传输中最深刻的三个名词:丢包、乱序、重传。所以我们看来风平浪静的网络,在服务器来说可能是风大浪急,一不小心就不通了,所以当网络出现断开时,这时就出现了网络分区问题。
对于Redis数据同步而言,假设从结点和主结点在两个机架上,某时刻发生网络断开,如果此时Redis读写分离,那么从结点的数据必然无法与主继续同步数据。在这种情况下,如果继续在从结点读取数据就造成数据不一致问题,如果强制保证数据一致从结点就无法提供服务造成不可用问题,从而看出在P的影响下C和A无法兼顾。
其他几种情况就不深入了,从上面我们可以得出结论:当Redis多台机器分布在不同的网络中,如果出现网络故障,那么数据一致性和服务可用性无法兼顾,Redis系统对此必须做出选择,事实上Redis选择了可用性,或者说Redis选择了另外一种最终一致性。
C.3 Redis的最终一致性和复制
Redis选择了最终一致性,也就是不保证主从数据在任何时刻都是一致的,并且Redis主从同步默认是异步的,亲爱的盆友们不要晕!不要蒙圈!
我来一下解释同步复制和异步复制(注意:考虑读者的感受 我并没有写成同步同步和异步同步 哈哈):
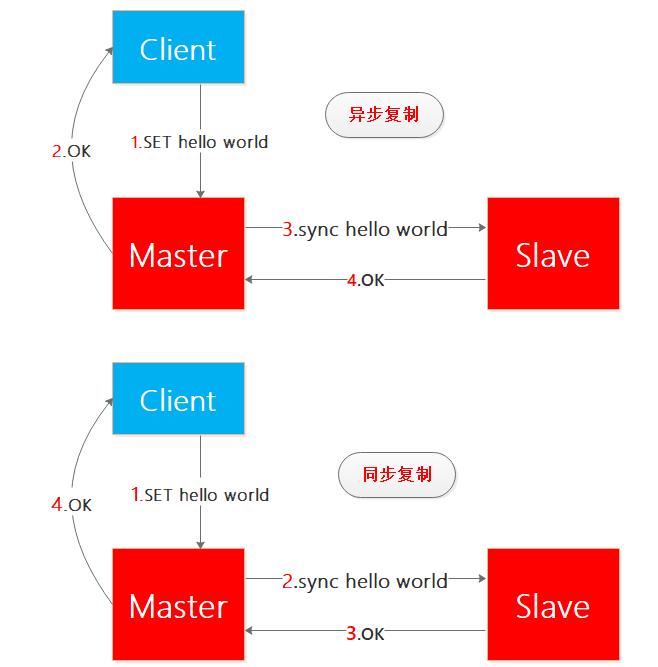
一图胜千言,看红色的数字就知道同步复制和异步复制的区别了:
异步复制:当客户端向主结点写了hello world,主节点写成功之后就向客户端回复OK,这样主节点和客户端的交互就完成了,之后主节点向从结点同步hello world,从结点完成之后向主节点回复OK,整个过程客户端不需要等待从结点同步完成,因此整个过程是异步实现的。
同步复制:当客户端向主结点写了hello world,主节点向从结点同步hello world,从结点完成之后向主节点回复OK,之后主节点向客户端回复OK,整个过程客户端需要等待从结点同步完成,因此整个过程是同步实现的。
Redis选择异步复制可以避免客户端的等待,更符合现实要求,不过这个复制方式可以修改,根据自己需求而定吧。
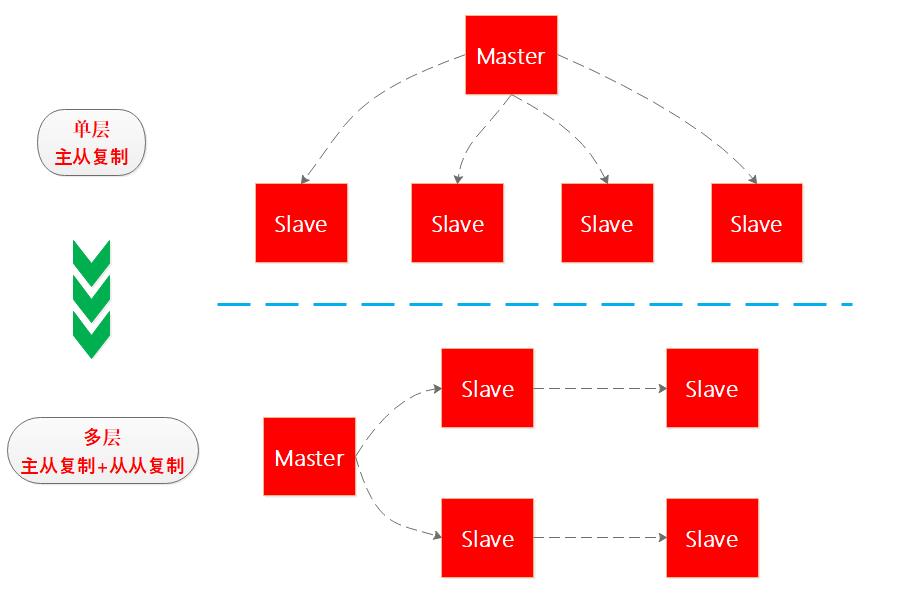
1.从从复制
假如Redis高可用系统中有一主四从,如果四个从同时向主节点进行数据同步,主节点的压力会比较大,考虑到Redis的最终一致性,因此Redis后续推出了从从复制,从而将单层复制结构演进为多层复制结构,笔者画了个图看下:
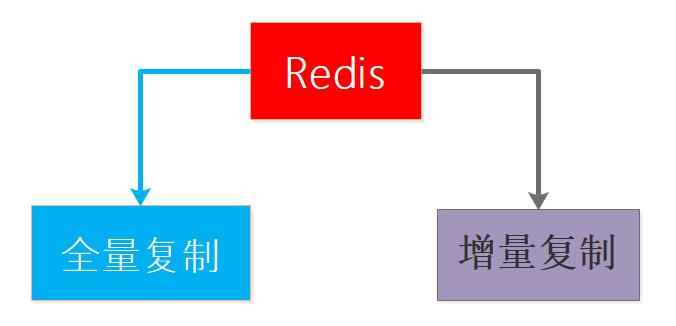
2.全量复制和增量复制
全量复制是从结点因为故障恢复或者新添加从结点时出现的初始化阶段的数据复制,这种复制是将主节点的数据全部同步到从结点来完成的,所以成本大但又不可避免。
增量复制是主从结点正常工作之后的每个时刻进行的数据复制方式,涓涓细流同步数据,这种同步方式又轻又快,优点确实不少,不过如果没有全量复制打下基础增量复制也没戏,所以二者不是矛盾存在而是相互依存的。
3.全量复制过程分析
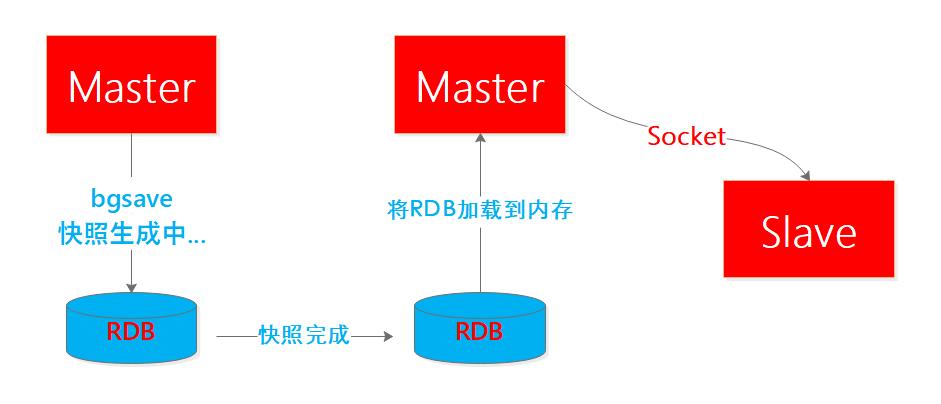
Redis的全量复制过程主要分三个阶段:
快照阶段:从结点向主结点发起SYNC全量复制命令,主节点执行bgsave将内存中全部数据生成快照并发送给从结点,从结点释放旧内存载入并解析新快照,主节点同时将此阶段所产生的新的写命令存储到缓冲区。
缓冲阶段:主节点向从节点同步存储在缓冲区的操作命令,这部分命令主节点是bgsave之后到从结点载入快照这个时间段内的新增命令,需要记录要不然就出现数据丢失。
增量阶段:缓冲区同步完成之后,主节点正常向从结点同步增量操作命令,至此主从保持基本一致的步调。
借鉴参考1的一张图表,写的很好:

考虑一个多从并发全量复制问题:
如果此时有多个从结点同时向主结点发起全量同步请求会怎样?
Redis主结点是个聪明又诚实的家伙,比如现在有3个从结点A/B/C陆续向主节点发起SYNC全量同步请求。
主节点在对A进行bgsave的同时,B和C的SYNC命令到来了,那么主节点就一锅烩,把针对A的快照数据和缓冲区数据同时同步给ABC,这样提高了效率又保证了正确性。
主节点对A的快照已经完成并且现在正在进行缓冲区同步,那么只能等A完成之后,再对B和C进行和A一样的操作过程,来实现新节点的全量同步,所以主节点并没有偷懒而是重复了这个过程,虽然繁琐但是保证了正确性。
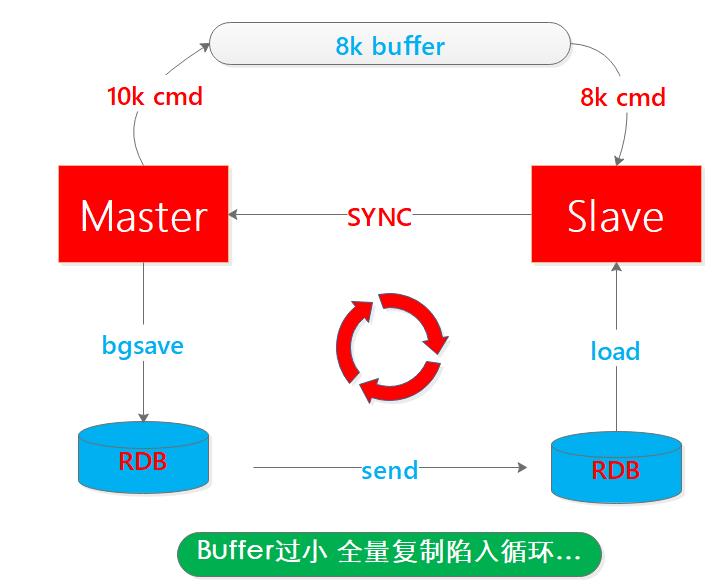
再考虑一个快照复制循环问题:
主节点执行bgsave是比较耗时且耗内存的操作,期间从结点也经历装载旧数据->释放内存->装载新数据的过程,内存先升后降再升的动态过程,从而知道无论主节点执行快照还是从结点装载数据都是需要时间和资源的。
抛开对性能的影响,试想如果主节点快照时间是1分钟,在期间有1w条新命令到来,这些新命令都将写到缓冲区,如果缓冲区比较小只有8k,那么在快照完成之后,主节点缓冲区也只有8k命令丢失了2k命令,那么此时从结点进行全量同步就缺失了数据,是一次错误的全量同步。
无奈之下,从结点会再次发起SYNC命令,从而陷入循环,因此缓冲区大小的设置很重要,二话不说再来一张图:
4.增量复制过程分析
增量复制过程稍微简单一些,但是非常有用,试想复杂的网络环境下,并不是每次断开都无法恢复,如果每次断开恢复后就要进行全量复制,那岂不是要把主节点搞死,所以增量复制算是对复杂网络环境下数据复制过程的一个优化,允许一段时间的落后,最终追上就行。
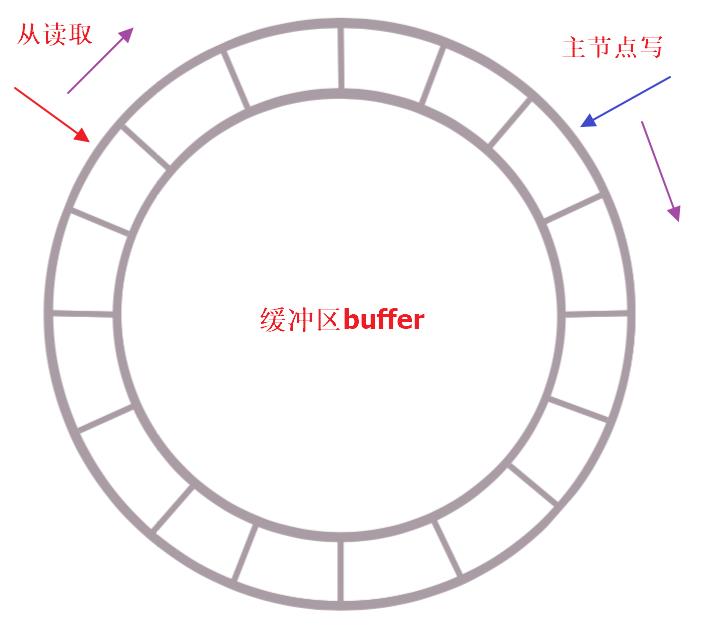
增量复制是个典型的生产者-消费者模型,使用定长环形数组(队列)来实现,如果buffer满了那么新数据将覆盖老数据,因此从结点在复制数据的同时向主节点反馈自己的偏移量,从而确保数据不缺失。
这个过程非常好理解,kakfa这种MQ也是这样的,所以在合理设置buffer大小的前提下,理论上从的消费能力是大于主的生产能力的,大部分只有在网络断开时间过长时会出现buffer被覆盖,从结点消费滞后的情况,此时只能进行全量复制了。
5.无盘复制
理解无盘复制之前先看下什么是有盘复制呢?
所谓盘是指磁盘,可能是机械磁盘或者SSD,但是无论哪一种相比内存都更慢,我们都知道IO操作在服务端的耗时是占大头的,因此对于全量复制这种高IO耗时的操作来说,尤其当服务并发比较大且还在进行其他操作时对Redis服务本身的影响是比较大大,之前的模式时这样的:
在Redis2.8.18版本之后,开发了无盘复制,也就是避免了生成的RDB文件落盘再加载再网络传输的过程,而是流式的遍历发送过程,主节点一边遍历内存数据,一边将数据序列化发送给从结点,从结点没有变化,仍然将数据依次存储到本地磁盘,完成传输之后进行内存加载,可见无盘复制是对IO更友好。
0x0D.谈谈基于Redis的分布式锁和Redlock算法
D.1 基于Redis的分布式锁简介
最初分布式锁借助于setnx和expire命令,但是这两个命令不是原子操作,如果执行setnx之后获取锁但是此时客户端挂掉,这样无法执行expire设置过期时间就导致锁一直无法被释放,因此在2.8版本中Antirez为setnx增加了参数扩展,使得setnx和expire具备原子操作性。

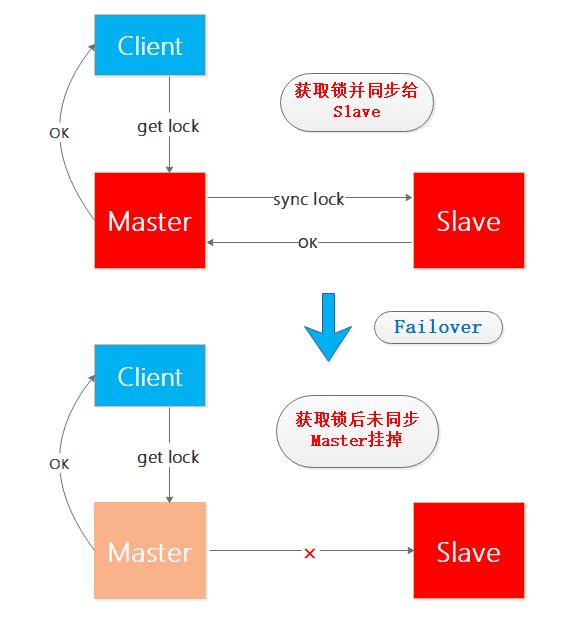
在单Matster-Slave的Redis系统中,正常情况下Client向Master获取锁之后同步给Slave,如果Client获取锁成功之后Master节点挂掉,并且未将该锁同步到Slave,之后在Sentinel的帮助下Slave升级为Master但是并没有之前未同步的锁的信息,此时如果有新的Client要在新Master获取锁,那么将可能出现两个Client持有同一把锁的问题,来看个图来想下这个过程:
为了保证自己的锁只能自己释放需要增加唯一性的校验,综上基于单Redis节点的获取锁和释放锁的简单过程如下:
// 获取锁 unique_value作为唯一性的校验
SET resource_name unique_value NX PX 30000
// 释放锁 比较unique_value是否相等 避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
这就是基于单Redis的分布式锁的几个要点。
D.2 Redlock算法基本过程
Redlock算法是Antirez在单Redis节点基础上引入的高可用模式。在Redis的分布式环境中,我们假设有N个完全互相独立的Redis节点,在N个Redis实例上使用与在Redis单实例下相同方法获取锁和释放锁。
现在假设有5个Redis主节点(大于3的奇数个),这样基本保证他们不会同时都宕掉,获取锁和释放锁的过程中,客户端会执行以下操作:
-
获取当前Unix时间,以毫秒为单位
-
依次尝试从5个实例,使用相同的key和具有唯一性的value获取锁
当向Redis请求获取锁时,客户端应该设置一个网络连接和响应超时时间,这个超时时间应该小于锁的失效时间,这样可以避免客户端死等 -
客户端使用当前时间减去开始获取锁时间就得到获取锁使用的时间。当且仅当从半数以上的Redis节点取到锁,并且使用的时间小于锁失效时间时,锁才算获取成功
-
如果取到了锁,key的真正有效时间等于有效时间减去获取锁所使用的时间,这个很重要
-
如果因为某些原因,获取锁失败(没有在半数以上实例取到锁或者取锁时间已经超过了有效时间),客户端应该在所有的Redis实例上进行解锁,无论Redis实例是否加锁成功,因为可能服务端响应消息丢失了但是实际成功了,毕竟多释放一次也不会有问题
上述的5个步骤是Redlock算法的重要过程,也是面试的热点,有心的读者还是记录一下吧!
D.3 Redlock算法是否安全的争论
1.关于马丁·克莱普曼博士
2016年2月8号分布式系统的专家马丁·克莱普曼博士(Martin Kleppmann)在一篇文章How to do distributed locking 指出分布式锁设计的一些原则并且对Antirez的Redlock算法提出了一些质疑。笔者找到了马丁·克莱普曼博士的个人网站以及一些简介,一起看下:
用搜狗翻译看一下:
1.我是剑桥大学计算机科学与技术系的高级研究助理和附属讲师,由勒弗乌尔姆信托早期职业奖学金和艾萨克牛顿信托基金资助。我致力于本地优先的协作软件和分布式系统安全。
2.我也是剑桥科珀斯克里斯蒂学院计算机科学研究的研究员和主任,我在那里从事本科教学。
3.2017年,我为奥雷利出版了一本名为《设计数据密集型应用》的书。它涵盖了广泛的数据库和分布式数据处理系统的体系结构,是该出版社最畅销书之一。
4.我经常在会议上发言,我的演讲录音已经被观看了超过15万次。
5.我参与过各种开源项目,包括自动合并、Apache Avro和Apache Samza。
6.2007年至2014年间,我是一名工业软件工程师和企业家。我共同创立了Rapportive(2012年被领英收购)和Go Test(2009年被红门软件收购)。
7.我创作了几部音乐作品,包括《二月之死》(德语),这是唐克·德拉克特对该书的音乐戏剧改编,于2007年首映,共有150人参与。
大牛就是大牛,能教书、能出书、能写开源软件、能创业、能写音乐剧,优秀的人哪方面也优秀,服气了。

2.马丁博士文章的主要观点
马丁·克莱普曼在文章中谈及了分布式系统的很多基础问题,特别是分布式计算的异步模型,文章分为两大部分前半部分讲述分布式锁的一些原则,后半部分针对Redlock提出一些看法:
-
Martin指出即使我们拥有一个完美实现的分布式锁,在没有共享资源参与进来提供某种fencing栅栏机制的前提下,我们仍然不可能获得足够的安全性
-
Martin指出,由于Redlock本质上是建立在一个同步模型之上,对系统的时间有很强的要求,本身的安全性是不够的
针对fencing机制马丁给出了一个时序图:
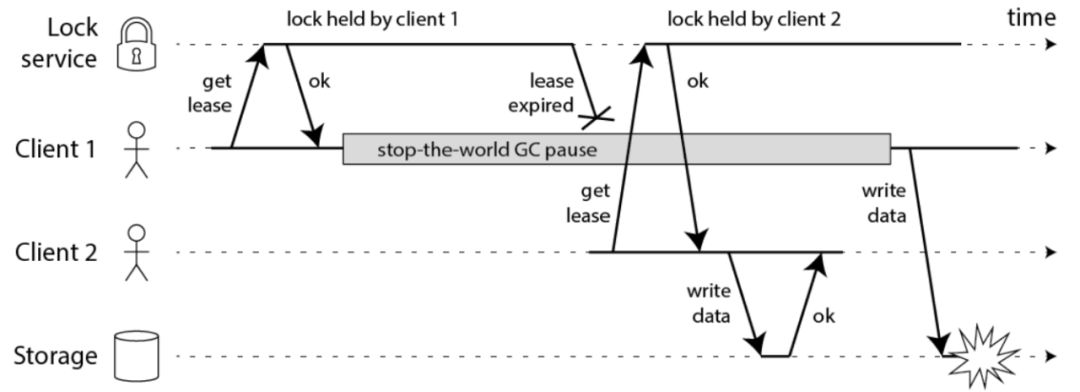
针对这种情况马丁指出要增加fencing机制,具体来说是fencing token隔离令牌机制,同样给出了一张时序图:
客户端1获得锁并且获得序号为33的令牌,但随后它进入长时间暂停,直至锁超时过期,客户端2获取锁并且获得序号为34的令牌,然后将其写入发送到存储服务。随后,客户端1复活并将其写入发送到存储服务,然而存储服务器记得它已经处理了具有较高令牌号的写入34,因此它拒绝令牌33的请求。
Redlock算法并没有这种唯一且递增的fencing token生成机制,这也意味着Redlock算法不能避免由于客户端阻塞带来的锁过期后的操作问题,因此是不安全的。
这个观点笔者觉得并没有彻底解决问题,因为如果客户端1的写入操作是必须要执行成功的,但是由于阻塞超时无法再写入同样就产生了一个错误的结果,客户端2将可能在这个错误的结果上进行操作,那么任何操作都注定是错误的。
3.马丁博士对Redlock的质疑
马丁·克莱普曼指出Redlock是个强依赖系统时间的算法,这样就可能带来很多不一致问题,他给出了个例子一起看下:
假设多节点Redis系统有五个节点A/B/C/D/E和两个客户端C1和C2,如果其中一个Redis节点上的时钟向前跳跃会发生什么?
-
客户端C1获得了对节点A、B、c的锁定,由于网络问题,法到达节点D和节点E -
节点C上的时钟向前跳,导致锁提前过期 -
客户端C2在节点C、D、E上获得锁定,由于网络问题,无法到达A和B -
客户端C1和客户端C2现在都认为他们自己持有锁
分布式异步模型:
上面这种情况之所以有可能发生,本质上是因为Redlock的安全性对Redis节点系统时钟有强依赖,一旦系统时钟变得不准确,算法的安全性也就无法保证。
马丁其实是要指出分布式算法研究中的一些基础性问题,好的分布式算法应该基于异步模型,算法的安全性不应该依赖于任何记时假设。
分布式异步模型中进程和消息可能会延迟任意长的时间,系统时钟也可能以任意方式出错。这些因素不应该影响它的安全性,只可能影响到它的活性,即使在非常极端的情况下,算法最多是不能在有限的时间内给出结果,而不应该给出错误的结果,这样的算法在现实中是存在的比如Paxos/Raft,按这个标准衡量Redlock的安全级别是达不到的。
4.马丁博士文章结论和基本观点
马丁表达了自己的观点,把锁的用途分为两种:
-
效率第一
使用分布式锁只是为了协调多个客户端的一些简单工作,锁偶尔失效也会产生其它的不良后果, 就像你收发两份相同的邮件一样,无伤大雅 -
正确第一
使用分布式锁要求在任何情况下都不允许锁失效的情况发生,一旦发生失效就可能意味着数据不一致、数据丢失、文件损坏或者其它严重的问题, 就像给患者服用重复剂量的药物一样,后果严重
最后马丁出了如下的结论:
-
为了效率而使用分布式锁
单Redis节点的锁方案就足够了Redlock则是个过重而昂贵的设计 -
为了正确而使用分布式锁
Redlock不是建立在异步模型上的一个足够强的算法,它对于系统模型的假设中包含很多危险的成分
马丁认为Redlock算法是个糟糕的选择,因为它不伦不类:出于效率选择来说,它过于重量级和昂贵,出于正确性选择它又不够安全。
5.Antirez的反击
http://antirez.com/news/101
Antirez认为马丁的文章对于Redlock的批评可以概括为两个方面:
-
带有自动过期功能的分布式锁,必须提供某种fencing栅栏机制来保证对共享资源的真正互斥保护,Redlock算法提供不了这样一种机制 -
Redlock算法构建在一个不够安全的系统模型之上,它对于系统的记时假设有比较强的要求,而这些要求在现实的系统中是无法保证的
Antirez对这两方面分别进行了细致地反驳。
关于fencing机制
Antirez提出了质疑:既然在锁失效的情况下已经存在一种fencing机制能继续保持资源的互斥访问了,那为什么还要使用一个分布式锁并且还要求它提供那么强的安全性保证呢?
退一步讲Redlock虽然提供不了递增的fencing token隔离令牌,但利用Redlock产生的随机字符串可以达到同样的效果,这个随机字符串虽然不是递增的,但却是唯一的。
关于记时假设
Antirez针对算法在记时模型假设集中反驳,马丁认为Redlock失效情况主要有三种:
-
1.时钟发生跳跃 -
2.长时间的GC pause -
3.长时间的网络延迟
后两种情况来说,Redlock在当初之处进行了相关设计和考量,对这两种问题引起的后果有一定的抵抗力。
时钟跳跃对于Redlock影响较大,这种情况一旦发生Redlock是没法正常工作的。
Antirez指出Redlock对系统时钟的要求并不需要完全精确,只要误差不超过一定范围不会产生影响,在实际环境中是完全合理的,通过恰当的运维完全可以避免时钟发生大的跳动。
6.马丁的总结和思考
分布式系统本身就很复杂,机制和理论的效果需要一定的数学推导作为依据,马丁和Antirez都是这个领域的专家,对于一些问题都会有自己的看法和思考,更重要的是很多时候问题本身并没有完美的解决方案。
这次争论是分布式系统领域非常好的一次思想的碰撞,很多网友都发表了自己的看法和认识,马丁博士也在Antirez做出反应一段时间之后再次发表了自己的一些观点:
For me, this is the most important point: I don’t care who is right or wrong in this debate — I care about learning from others’ work, so that we can avoid repeating old mistakes, and make things better in future. So much great work has already been done for us: by standing on the shoulders of giants, we can build better software.
By all means, test ideas by arguing them and checking whether they stand up to scrutiny by others. That’s part of the learning process. But the goal should be to learn, not to convince others that you are right. Sometimes that just means to stop and think for a while.
简单翻译下就是:
对马丁而言并不在乎谁对谁错,他更关心于从他人的工作中汲取经验来避免自己的错误重复工作,正如我们是站在巨人的肩膀上才能做出更好的成绩。
另外通过别人的争论和检验才更能让自己的想法经得起考验,我们的目标是相互学习而不是说服别人相信你是对的,所谓一人计短,思考辩驳才能更加接近真理。
以上是关于乘风破浪的Redis可能是史上第二强面试题解攻略的主要内容,如果未能解决你的问题,请参考以下文章