揭秘PyTorch内核!核心开发者亲自全景解读(47页PPT)
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了揭秘PyTorch内核!核心开发者亲自全景解读(47页PPT)相关的知识,希望对你有一定的参考价值。
新智元原创
新智元原创
来源:Inside 245-5D
编辑:鹏飞
【新智元导读】本文以内部PyTorch核心开发者视角,非常详细透彻的分析了PyTorch的内部结构,为开发者提供一张地图,告诉您“支持自动区分的张量库”的基本概念结构,并提供一些工具和技巧,以便找到适合代码库。对学习PyTorch、尤其是致力于参与PyTorch贡献有非常大的意义。
PyTorch是一个开源的Python机器学习库,基于Torch,已成为最受欢迎的机器学习框架之一。
相比Tensorflow,PyTorch的社区由更多专业机器学习开发人员、软件架构师和公司内部程序员组成。
PyTorch也更多地用于数据分析和业务环境中的特殊模型中。
在PyTorch社区中,有更多的Python开发人员从事Web应用程序。此外,这种Python向框架的多功能性,使得研究人员能够以几乎无痛的方式测试想法,使得它成为最先进的尖端解决方案的首选框架。
对于准备、正在学习PyTorch的读者来说,了解其内部机制能够极大的提升学习效率、增进对PyTorch设计原理和目的的了解,从而能够更好的在工作学习中使用该工具。如果你立志参与到PyTorch后续的改进中,那么更应该深入的了解其内部机制。
好消息是,Facebook Research Engineer、斯坦福博士生、PyTorch核心开发人员Edward Z. Yang为大家带来一份PyTorch内部机制的详解slides,新智元在此强力推荐给广大读者。正文约3500字,阅读可能需要10分钟。
由于微信的限制无法展示高清图像,我们特意为大家在文末找来了可下载的高清完整版,预祝大家学习愉快!
主要针对使用过PyTorch的人,尤其是希望成为PyTorch贡献者、但却被PyTorch的庞大复杂的C++代码库吓到的人。
最终目的是能够为大家提供一个通关宝典,让大家了解“支持自动区分的Tensor库”的基本概念结构,并提供一些工具和技巧,用来更容易的找到适合代码库。
读者只需要对PyTorch有一个初步的了解,并且有过一定的动手经验即可。门槛还是非常低的。
全部内容分为两部分。首先介绍Tensor库的概念。作者将从Tensor数据类型开始,更详细地讨论这种数据类型提供的内容,以便让读者更好地了解它是如何实际实现的。布局、设备和dtype的三位一体,探讨如何考虑对Tensor类的扩展。
第二部分将讨论PyTorch实战。例如使用autograd来降低工作量,哪些代码关键、为什么?以及各种用来编写内核的超酷的工具。
Tensor
Tensor是PyTorch中的中心数据结构。我们可以将Tensor视为由一些数据组成,然后是一些描述Tensor大小的元数据,包含元素的类型(dtype),Tensor所依赖的设备(CPU内存?CUDA内存?)。以及Strides(步幅)。Strides实际上是PyTorch的一个显著特征。
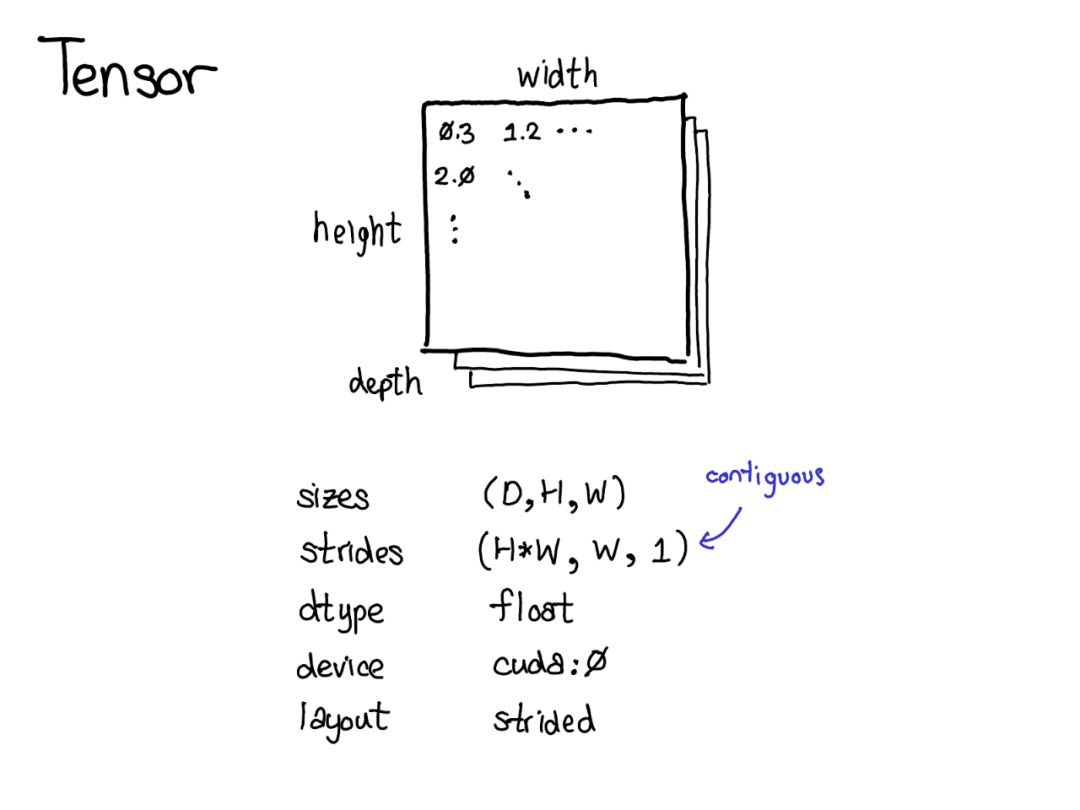
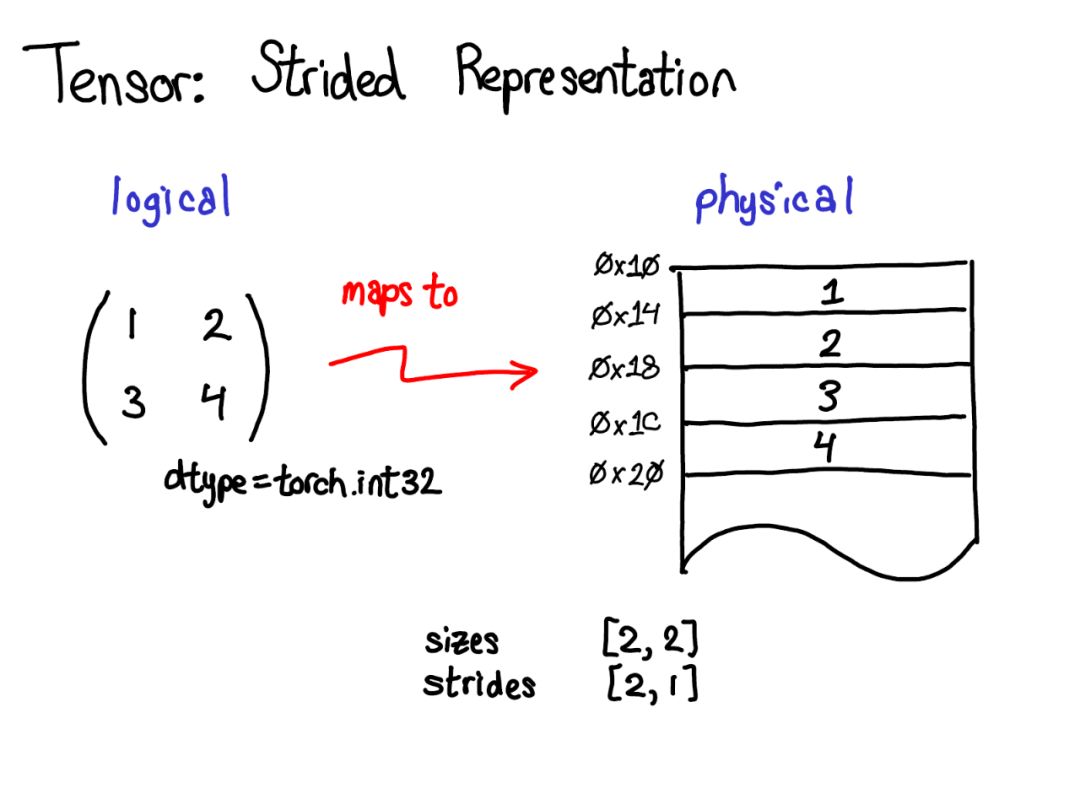
Tensor是一个数学概念。在计算机上最常见的表示是将Tensor中的每个元素连续地存储在内存中,将每一行写入内存,如上所示。
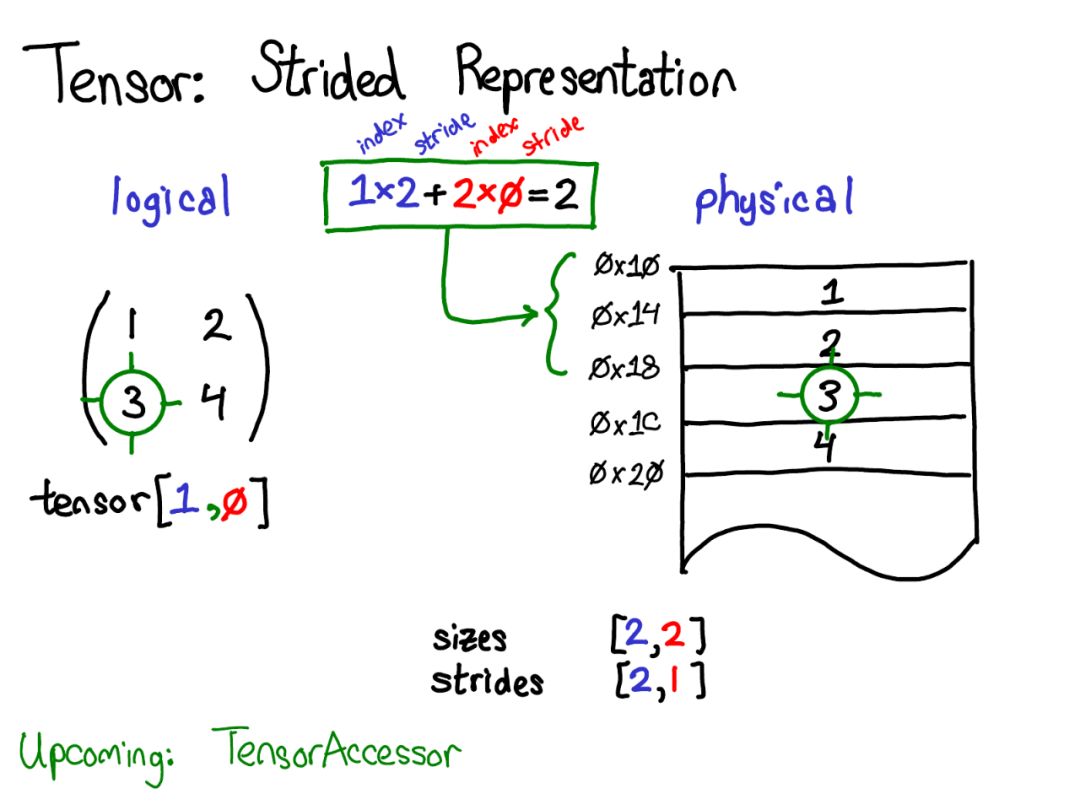
假设我想在逻辑表示中访问位置Tensor[0,1]处的元素。通过Stride我们应该这样做:
找出Tensor的任何元素存在的位置,将每个索引乘以该维度的相应Stride,并将它们加在一起。
上图中将第一维蓝色和第二维红色进行了颜色编码,以便在Stride计算中跟踪索引和步幅。
以上是Stride的一个例子。Stride表示实际上可以让你代表Tensor的各种有趣的方法; 如果你想玩弄各种可能性,请查看Stride Visualizer。
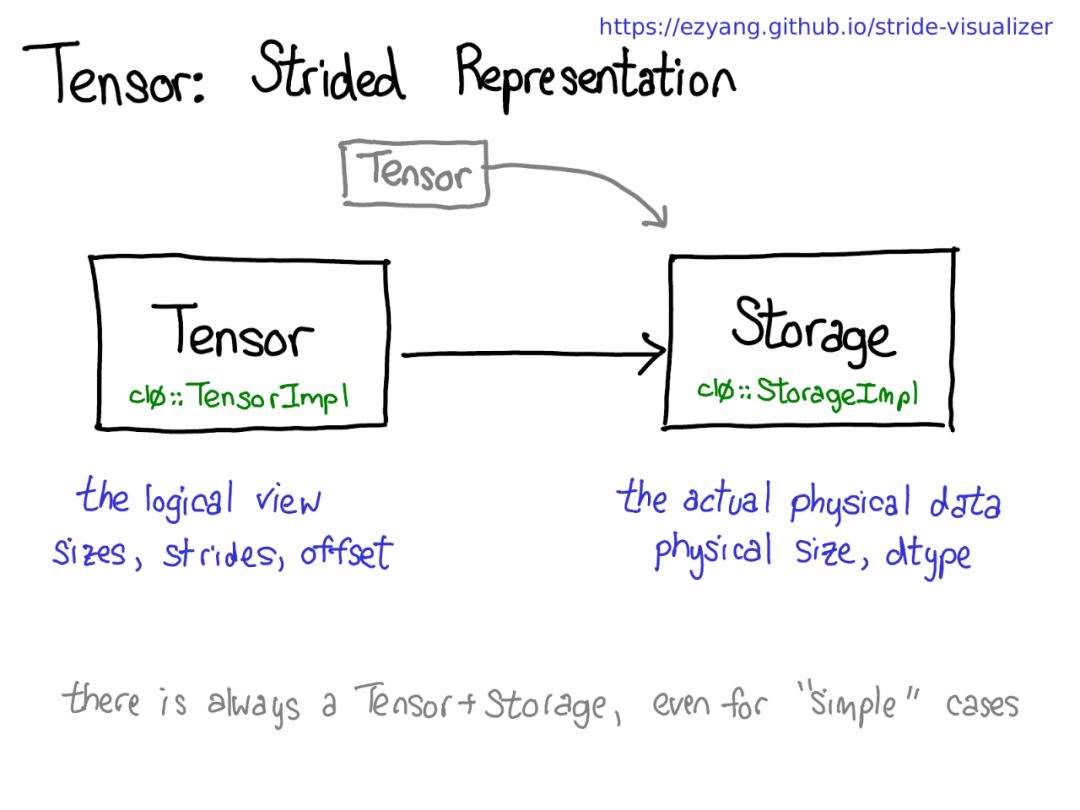
可能存在共享相同存储的多个Tensor,但请记住一点:有Tensor的地方,就有存储。
存储定义Tensor的dtype和物理大小,而每个Tensor记录大小,步幅和偏移,定义物理内存的逻辑解释。
Tensor扩展
有很多有趣的扩展,如XLA张量,量化张量,或MKL-DNN张量,作为张量库,我们必须考虑是如何适应这些扩展。
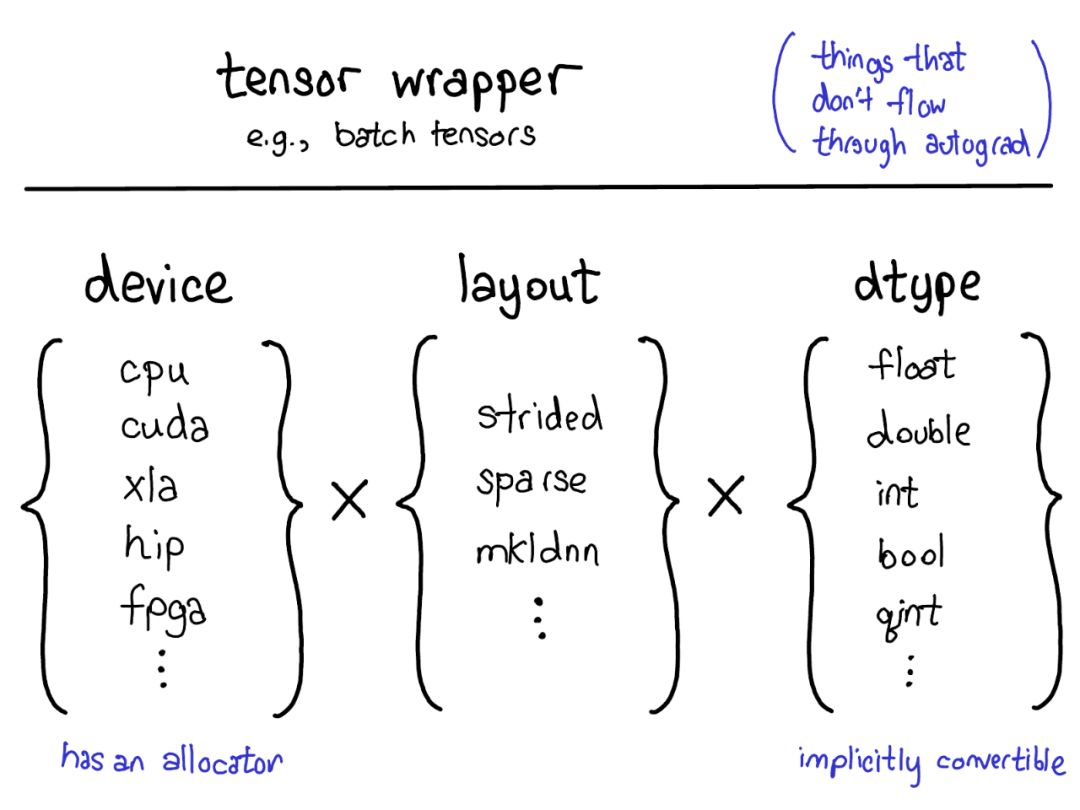
当前的扩展模型在张量上提供了四个扩展点。首先,用三个参数用来确定张量是什么:
设备
张量的物理存储器实际存储在何处,例如在CPU上,NVIDIA GPU(cuda)上,或者可能在AMD GPU(hip)或TPU(xla)上的描述。设备的显着特征是它有自己的分配器,不能与任何其他设备一起使用。
布局
布局用来描述我们如何逻辑地解释这个物理内存。最常见的布局是跨步张量,但稀疏张量具有不同的布局,涉及2个张量:一个用于索引、一个用于数据。
MKL-DNN张量可能具有更奇特的布局,例如阻挡布局,这不能仅使用步幅来表示。
dtype
描述了它实际存储在张量的每个元素中的含义。这可以是浮点数或整数,或者它可以是例如量化的整数。
顺便说一下,如果你想为PyTorch张量添加一个扩展名,请联系PyTorch官方。
了解你手里的武器
PyTorch有很多文件夹,CONTRIBUTING文档有非常详细的描述。但实际上,你真正需要了解的只有四个:
torch/:包含导入和使用的实际Python模块。Python代码,很容易上手调试。
torch/csrc/:它实现了在Python和C++之间进行转换的绑定代码,以及一些非常重要的PyTorch功能,如autograd引擎和JIT编译器。它还包含C++前台代码。
aten/:“A Tensor Library”的缩写(由Zachary DeVito创造),是一个实现Tensors操作的C++库。存放一些内核代码存在的地方,尽量不要在那里花太多时间。
c10/:这是一个双关语。C代表Caffe,10既是二级制的2,也是十进制的10(英文Ten,同时也是Tensor的前半部分)。包含PyTorch的核心抽象,包括Tensor和Storage数据结构的实际实现。
让我们看看这种代码分离在实践中是如何分解的:

调用一个函数的时候,会经历以下步骤:
将Python翻译成C
处理变量调度
处理设备类型/布局调度
我们有实际的内核,它既可以是现代本机函数,也可以是传统的TH函数

值得一提的是,所有代码都是自动生成的,所以不会出现在GitHub的repo里,必须自己构建PyTorch后才能看到。不过你也不必非常深刻地理解这段代码在做什么,自动生成的嘛。
从武器库中挑选写内核的趁手兵刃
PyTorch为内核编写者提供了许多有用的工具。在本节中,我们将介绍其中比较趁手的工具。
要利用PyTorch带来的所有代码生成,需要为运算符编写schema。详细介绍参见GitHub的README。

错误检查可以通过低阶API(TORCH_CHECK)和高阶API实现。高阶API可以基于TensorArg元数据提供用户友好的错误消息。
要执行dtype调度,应该使用AT_DISPATCH_ALL_TYPES宏,用来获取张量的dtype,并用于可从宏调度的每个dtype的lambda。通常,这个lambda只调用一个模板化的辅助函数。

如何提高工作效率
别编辑header!
编辑header会导致很长的重构时间,尽量去编辑.cpp文件。
别直接用CI去测试
CI是一个直接可用的测试代码的变动是否有效的非常棒的工具,但如果你真的一点不都改设置恐怕要浪费很长时间在测试过程中。
强烈建议设置ccache
它有可能让你避免在编辑header时进行大量重新编译。而当我们在不需要重新编译文件时进行了重新编译,它还有助于掩盖构建系统中的错误。
用一台高性能的工作站
如果你建立一个带有CPU和RAM的强大服务器,你将获得更愉快的体验。特别是,不建议在笔记本电脑上进行CUDA构建。
本文是对原文的综述,更多细节请前往:
http://blog.ezyang.com/2019/05/pytorch-internals/
高清完整版PDF下载:
http://web.mit.edu/~ezyang/Public/pytorch-internals.pdf
新智元春季招聘开启,一起弄潮 AI 之巅!
岗位详情请戳:
【加入社群】
以上是关于揭秘PyTorch内核!核心开发者亲自全景解读(47页PPT)的主要内容,如果未能解决你的问题,请参考以下文章