日志收集系统之Apache Flume
Posted StreamCloudNative
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日志收集系统之Apache Flume相关的知识,希望对你有一定的参考价值。
Flume 是什么?
Flume 是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。它具有基于流数据流的简单灵活的体系结构。它具有可调整的可靠性机制以及许多故障转移和恢复机制,具有强大的功能和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
系统架构
Agent 主要由: Source、Channel、Sink 三个组件组成.
Source:
从数据发生器接收数据,并将接收的数据以 Flume 的 Event 格式传递给一个或者多个通道 channel。
Source 组件类型:
| 类型 | 描述 |
|---|---|
| Avro | 监听 Avro 端口并接收 Avro Client 的流数据 |
| Thrift | 监听 Thrift 端口并接收 Thrift Client 的流数据 |
| Exec | 基于 Unix 的 command 在标准输出上生产数据 |
| JMS | 从 JMS(Java 消息服务)采集数据 |
| Spooling Directory | 监听指定目录 |
| 通过 API 持续下载 Twitter 数据 | |
| Kafka | 采集 Kafka Topic 中的 Message |
| NetCat | 监听端口(要求所提供的数据是换行符分隔的文本) |
| Sequence Generator | 序列产生器,连续不断产生 Event,用于测试 |
| Syslog | 采集 syslog 日志消息,支持单端口 TCP、多端口 TCP 和 UDP日志采集 |
| HTTP | 接收 HTTP POST 和 GET 数据 |
| Stress | 用于 Source 压力测试 |
| Legacy | 向下兼容,接收低版本 Flume 的数据 |
| Custom | 自定义 Source 的接口 |
| Scribe | 从 facebook Scribe 采集数据 |
Channel:
Channel 是一种短暂的存储容器,它将从 Source 处接收到的 Event 格式的数据缓存起来,直到它们被 Sinks 消费掉,它在 Source 和 Sink 间起着桥梁的作用,Channel 是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的 Source 和 Sink 链接.
Channel 组件类型:
| 类型 | 描述 |
|---|---|
| Memory | Event 数据存储在内存中 |
| JDBC | Event 数据存储在持久化存储中,当前 Flume Channel 内置支持 Derby |
| Kafka | Event 存储在 Kafka 集群 |
File Channel |
Event 数据存储在磁盘文件中 |
Spillable Memory Channel |
Event 数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) |
Pseudo Transaction Channel |
测试用途 |
| Custom Channel | 自定义 Channel 实现 |
Sink:
Sink 将数据存储到集中存储器比如 Hbase 和 HDFS,它从 channels 消费数据(events) 并将其传递给目标地。目标地可能是另一个 Sink,也可能 HDFS、HBase。
Sink 组件类型:
| 类型 | 描述 |
|---|---|
| HDFS | 数据写入 HDFS |
| HIVE | 数据导入到 HIVE 中 |
| Logger | 数据写入日志文件 |
| Avro | 数据被转换成 Avro Event,然后发送到配置的 RPC 端口上 |
| Thrift | 数据被转换成 Thrift Event,然后发送到配置的 RPC 端口上 |
| IRC | 数据在 IRC 上进行回放 |
| File Roll | 存储数据到本地文件系统 |
| Null | 丢弃到所有数据 |
| Hive | 数据写入 Hive |
| HBase | 数据写入 HBase 数据库 |
| Morphline Solr | 数据发送到 Solr 搜索服务器(集群) |
| ElasticSearch | 数据发送到 Elastic Search 搜索服务器(集群) |
| Kite Dataset | 写数据到 Kite Dataset,试验性质的 |
| Kafka | 数据写到 Kafka Topic |
| Custom | 自定义 Sink 实现 |
应用场景
1、电子商务网站
比如我们在做一个电子商务网站,然后我们想从消费用户中访问点特定的节点区域来分析消费者的行为或者购买意图. 这样我们就可以更加快速的将他想要的推送到界面上,实现这一点,我们需要将获取到的它访问的页面以及点击的产品数据等日志数据信息收集并移交给 Hadoop平台上去分析,而 Flume 正是帮我们做到这一点。
2、内容推送
现在流行的内容推送,比如广告定点投放以及新闻私人定制也是基于此。
3、ETL工具
可以利用插件把关系型数据库实时增量的导入到 Hdfs 外部数据源。
优势
1、Flume 可以将应用产生的数据存储到任何集中存储器中,比如HDFS、HBase;
2、当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,Flume 会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供平稳的数据;
3、提供上下文路由特征;
4、Flume 的管道是基于事务,保证了数据在传送和接收时的一致性;
5、Flume 是可靠的,容错性高的,可升级的,易管理的,并且可定制的。
主要特征
1、Flume 可以高效率的将多个网站服务器中收集的日志信息存入 HDFS/HBase 中;
2、使用 Flume,我们可以将从多个服务器中获取的数据迅速的移交给 Hadoop 中;
3、除了日志信息,Flume 同时也可以用来接入收集规模宏大的社交网络节点事件数据,比如facebook,twitter,电商网站如亚马逊,flipkart等;
4、支持各种接入资源数据的类型以及接出数据类型;
5、支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等;
6、可以水平扩展。
其它架构类型
多代理流
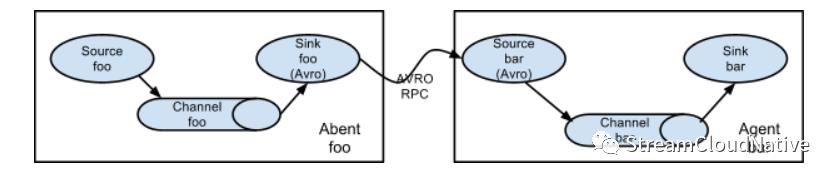
合并流
日志收集中的一种非常常见的情况是,大量的日志生成客户端将数据发送到连接到存储子系统的几个使用方代理。例如,从数百台 Web 服务器收集的日志发送到许多写入 HDFS 群集的代理。
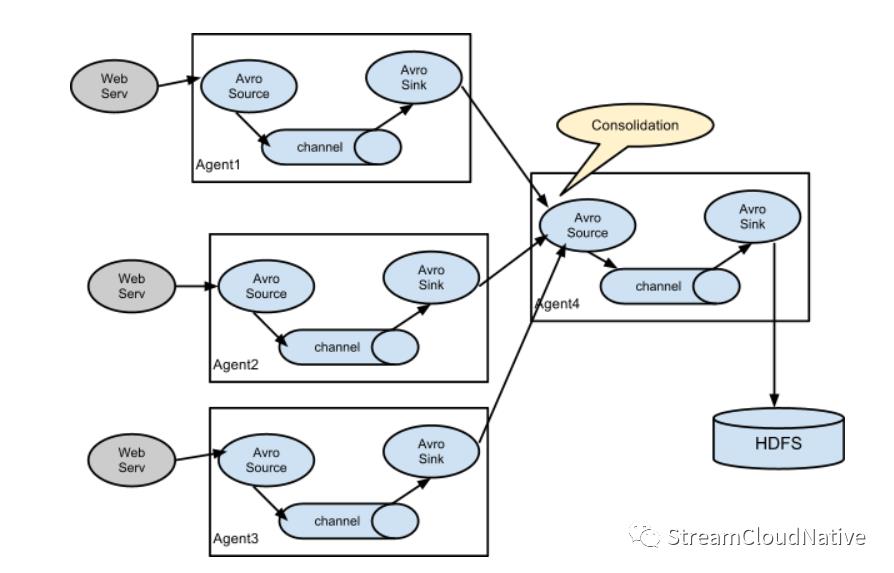
在 Flume 中,可以通过为多个第一层代理配置一个 Avro Sink 来实现这一点,它们均指向单个代理的 Avro 源(同样,在这种情况下,您可以使用thrift Source/Sink/Client)。第二层代理上的此源将接收到的事件合并到一个通道中,该通道由接收器消耗到其最终目的地。
多路利用流
Flume 支持将事件流复用到一个或多个目的地。这是通过定义一种流多路复用器来实现的,该流多路复用器可以将事件复制或选择性地路由到一个或多个通道。
上面的示例显示了来自代理 “ foo” 的源,将流分流到三个不同的通道。可以复制或多路复用。在复制流的情况下,每个事件都发送到所有三个通道。对于多路复用情况,当事件的属性与预配置的值匹配时,事件将传递到可用通道的子集。例如,如果将名为 “txnType” 的事件属性设置为 “customer”,则它应转到 Channel1 和 Channel3,如果它是 “vendor”,则应转到Channel2,否则应到 Channel3。可以在代理的配置文件中设置映射。
总结
Flume 的架构设计的简单易用,对于初学者而言也可以快速上手,其提供了多种类型的插件,在业务场景中可以根据需要选择使用最佳类型的插件,而且 Flume 提供了扩展接口,开发者可以基于扩展接口自定义插件类型。Flume 的配置方式比较简单,在 conf 中配置 3 个组件类型的属性,即可以使用其功能。
对技术感兴趣的朋友,可以通过下面的二维码关注我,谢谢!
以上是关于日志收集系统之Apache Flume的主要内容,如果未能解决你的问题,请参考以下文章