我说一致性Hash简单,没人反对吧?
Posted 享学课堂online
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我说一致性Hash简单,没人反对吧?相关的知识,希望对你有一定的参考价值。
Hash算法,比如说在安全加密领域MD5,SHA等加密算法,在数据存储和查找方面有Hash表等,以上都应用到了Hash算法
为什么需要使用Hash?
Hash算法比较多的应用在数据存储和查找领域,最经典的就是Hash表,它的查询效率非常之高,其中的哈希算法如果设计的ok的话,那么Hash表的数据查询时间复杂度可以接近于O(1)
需求:提供一组数据 1,5,7,6,3,4,8,对这组数据进行存储,然后随便给定一个数n,请你判断n是否存在 于刚才的数据集中?
list:List[1,5,7,6,3,4,8]
/ 通过循环判断来实现for(int element: list) {if(element == n) {//如果相等,说明n存在于数据集中}}
以上这种方法这种方法叫做顺序查找法 :这种方式我们是通过循环来完成,比较原始,效率也不高
二分查找:排序之后折半查找,相对于顺序查找法会提高一些效率,但是效率也并不是特别好 我能否不循环!不二分!而是通过一次查询就把数据n从数据集中查询出来?可以!
定义了一个数组,数组长度大于等于数据集长度,此处长度为9数据1就存储在下标为1的位置,3就存储 在下标为3的元素位置,,,依次类推。
这个时候,我想看下5存在与否,只需要判断list.get(5) array[5] 是否为空,如果为空,代表5不存在于 数据集,如果不为空代表5在数据集当中,通过一次查找就达到了目的,时间复杂度为O(1)。
这种方式叫做“直接寻址法”:直接把数据和数组的下标绑定到一起,查找的时候,直接array[n]就取出 了数据
优点:速度快,一次查找得到结果
缺点:
浪费空间,比如 1,5,7,6,3,4,8,12306 ,最大值12306 ,按照上述方式需要定义一个比如⻓度为12307的数组,但是只存储零星的几个数据,其他位置空间都浪费着
数据如:1,5,7,6,3,4,8,12,1,2,1,2,1,2,1,2,1,2,1,2,1,2,1,2,1,2,1,2最大值12,比如开辟13个空间,存储不了这么多内容
现在,换一种设计,如果数据是3,5,7,12306,一共4个数据,我们开辟任意个空间,比如5个,那 么具体数据存储到哪个位置呢,我们可以对数据进行求模(对空间位置数5),根据求模余数确定存储 位置的下标,比如3%5=3,就可以把3这个数据放到下标为3的位置上,12306%5=1,就把12306这个 数据存储到下标为1的位置上
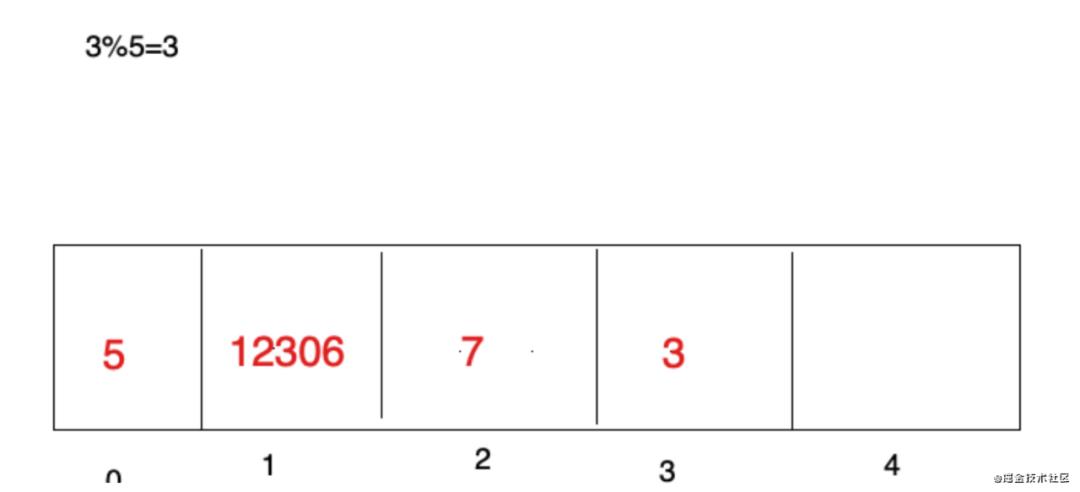
对于上面的数据求模他就是一个hash算法,只不过这是一种比较普通又简单的hash 算法,这种构造Hash算法的方式叫做除留余数法
如果是数据1,6,7,8把这四个数据存储到上面的数组中
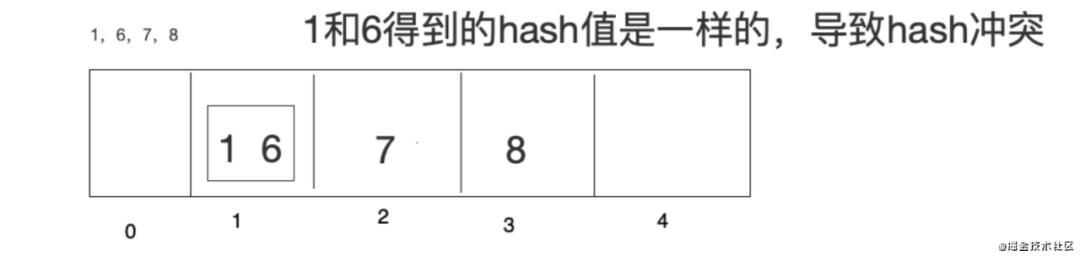
应对Hash冲突,有以下几种解决办法
开放寻址法:1放进去了,6再来,发现位置被1站了,向前后者向后找空闲的位置存放,这么做有个缺点就是如果数组长度定义好了比如10,长度不能扩展,来了11个数据,不管Hash冲突不冲突,肯定存不下这么多数据
链表法:在数组元素存储位置放一个链表
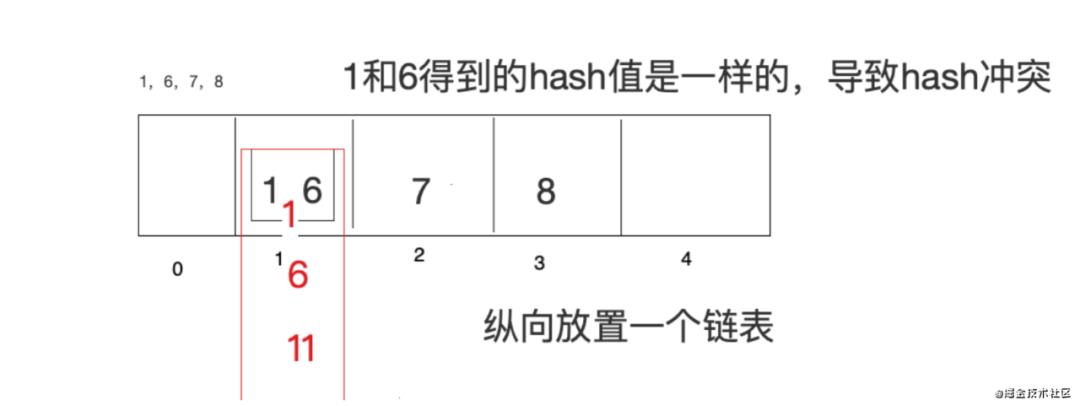
如果Hash算法设计的比较好的话,那么查询效率会更接近于O(1),如果Hash算法设计的比较low,那么查询效率就会很低了。所以,Hash表的查询效率高不高取决于Hash算法,Hash算法能够让数据平均分布,既能够节省空间又能够提高查询效率。
Hash算法的应用场景
主要的应用场景归纳起来两个:
请求的负载均衡(比如nginx的ip_hash策略):Nginx的IP_hash策略可以在客户端ip不变的情况下,将其发出的请求始终路由到同一个目标服务器上,实现会话粘滞,避免处理session共享问题。缺点也很明显:在客户端很多的情况下,映射表非常大,浪费内存空间。客户端上下线,目标服务器上下线,都会导致重新维护映射表,映射表维护成本很大
分布式存储:以分布式内存数据库Redis为例,集群中有redis1,redis2,redis3 三台Redis服务器,那么,在进行数据存储时,<key1,value1>数据存储到哪个服务器当中呢?针对key进行hash处理 hash(key1)%3=index, 使用余数index锁定存储的具体服务器节点
普通Hash算法存在的问题
普通Hash算法存在一个问题,以ip_hash为例,假定下载用户ip固定没有发生改变,现在tomcat3出现 了问题,down机了,服务器数量由3个变为了2个,之前所有的求模都需要重新计算。
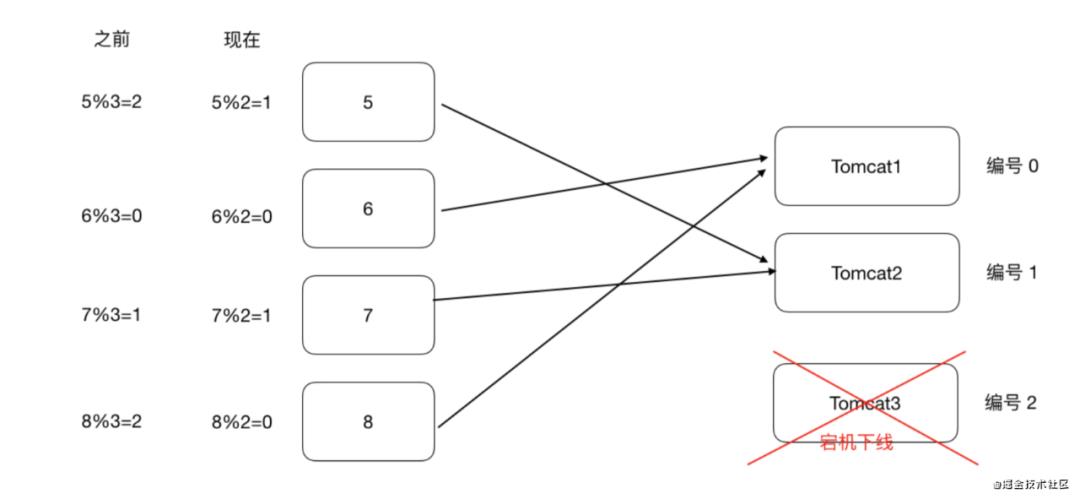
如果在真实生产情况下,后台服务器很多台,客户端也有很多,那么影响是很大的,缩容和扩容都会存 在这样的问题,大量用户的请求会被路由到其他的目标服务器处理,用户在原来服务器中的会话都会丢 失。
一致性Hash算法

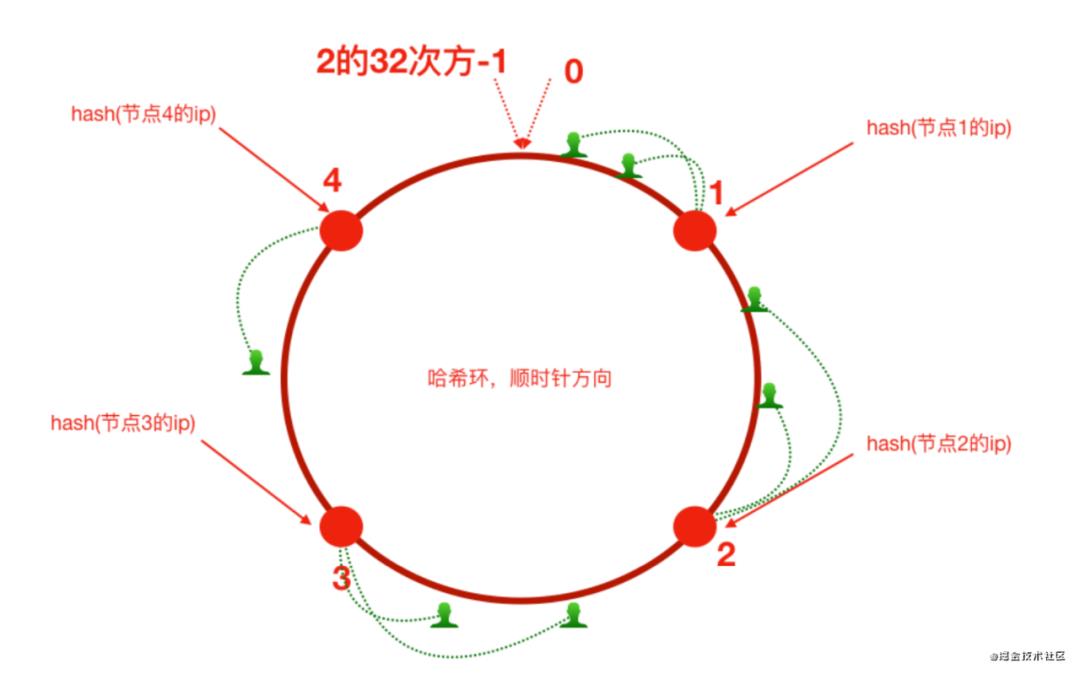
假如将服务器3下线,服务器3下线后,原来路由到3的客户端重新路由到服务器4,对于其他客户端没有 影响只是这一小部分受影响(请求的迁移达到了最小,这样的算法对分布式集群来说非常合适的,避免了大量请求迁移 )
增加服务器5之后,原来路由到3的部分客户端路由到新增服务器5上,对于其他客户端没有影响只是这 一小部分受影响(请求的迁移达到了最小,这样的算法对分布式集群来说非常合适的,避免了大量请求 迁移 )
如图所示,每一台服务器负责一段,一致性哈希算法对于节点的增减都只需重定位环空间中的一小 部分数据,具有较好的容错性和可扩展性。
但是,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中 只有两台服务器,其环分布如下,节点2只能负责非常小的一段,大量的客户端
请求落在了节点1上,这就是数据(请求)倾斜问题
为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个 哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。
具体做法可以在服务器ip或主机名的后面增加编号来实现。比如,可以为每台服务器计算三个虚拟节 点,于是可以分别计算 “节点1的ip#1”、“节点1的ip#2”、“节点1的ip#3”、“节点2的ip#1”、“节点2的 ip#2”、“节点2的ip#3”的哈希值,于是形成六个虚拟节点,当客户端被路由到虚拟节点的时候其实是被 路由到该虚拟节点所对应的真实节点
手写实现一致性Hash算法
不含虚拟节点
public class ConsistentHashNoVirtual { public static void main(String[] args) { //定义服务器ipString[] tomcatServers = new String[]{"123.111.0.0","123.101.3.1","111.20.35.2","123.98.26.3"};SortedMap<Integer,String> hashServerMap = new TreeMap<>(); for (String tomcatServer: tomcatServers){ //求出每一个ip的hash值,对应到hash环上,存储hash值与ip的对应关系int serverHash = Math.abs(tomcatServer.hashCode()); //存储hash值与ip的对应关系hashServerMap.put(serverHash,tomcatServer);} //定义客户端ipString[] clients = new String[]{"10.78.12.3","113.25.63.1","126.12.3.8","126.12.3.4","126.12.3.1"}; for (String client: clients){ int clientHash = Math.abs(client.hashCode()); //根据客户端ip的哈希值去找出哪一个服务器节点能够处理SortedMap<Integer, String> integerStringSortedMap =hashServerMap.tailMap(clientHash); if (integerStringSortedMap.isEmpty()){// 取哈希环上的顺时针第一台服务器Integer firstKey = hashServerMap.firstKey();System.out.println("==========>>>>客户端:" + client +" 被路由到服务器:" + hashServerMap.get(firstKey));}else {Integer firstKey = integerStringSortedMap.firstKey();System.out.println("==========>>>>客户端:" + client +" 被路由到服务器:" + hashServerMap.get(firstKey));}}}}
结果:
=========>客户端:10.78.12.3 被路由到服务器:111.20.35.2==========>客户端:113.25.63.1 被路由到服务器:123.98.26.3==========>客户端:126.12.3.8 被路由到服务器:111.20.35.2==========>客户端:126.12.3.4 被路由到服务器:111.20.35.2==========>客户端:126.12.3.1 被路由到服务器:111.20.35.2
含虚拟节点
public class ConsistentHashNoVirtual { public static void main(String[] args) { //定义服务器ipString[] tomcatServers = new String[]{"123.111.0.0","123.101.3.1","111.20.35.2","123.98.26.3"};SortedMap<Integer,String> hashServerMap = new TreeMap<>(); //定义针对每个真实服务器虚拟出来几个节点int virtaulCount = 3; for (String tomcatServer: tomcatServers){ //求出每一个ip的hash值,对应到hash环上,存储hash值与ip的对应关系int serverHash = Math.abs(tomcatServer.hashCode()); //存储hash值与ip的对应关系hashServerMap.put(serverHash,tomcatServer); //处理虚拟节点for (int i = 0; i < virtaulCount; i++){ int virtualHash = Math.abs((tomcatServer + "#" +i).hashCode());hashServerMap.put(virtualHash,"----由虚拟节点"+ i + "映射过来的请求:"+ tomcatServer);}}//定义客户端ipString[] clients = new String[]{"10.78.12.3","113.25.63.1","126.12.3.8","126.12.3.4","126.12.3.1"}; for (String client: clients){ int clientHash = Math.abs(client.hashCode()); //根据客户端ip的哈希值去找出哪一个服务器节点能够处理SortedMap<Integer, String> integerStringSortedMap =hashServerMap.tailMap(clientHash); if (integerStringSortedMap.isEmpty()){ // 取哈希环上的顺时针第一台服务器Integer firstKey = hashServerMap.firstKey();System.out.println("==========>>>>客户端:" + client + " 被路由到服务器:" + hashServerMap.get(firstKey));}else {Integer firstKey = integerStringSortedMap.firstKey();System.out.println("==========>>>>客户端:" + client + " 被路由到服务器:" + hashServerMap.get(firstKey));}}}}
结果:
==========>客户端:10.78.12.3 被路由到服务器:111.20.35.2==========>客户端:113.25.63.1 被路由到服务器:----由虚拟节点2映射过来的请求:111.20.35.2==========>客户端:126.12.3.8 被路由到服务器:----由虚拟节点0映射过来的请求:123.101.3.1==========>客户端:126.12.3.4 被路由到服务器:----由虚拟节点0映射过来的请求:123.101.3.1==========>客户端:126.12.3.1 被路由到服务器:----由虚拟节点0映射
以上是关于我说一致性Hash简单,没人反对吧?的主要内容,如果未能解决你的问题,请参考以下文章