Lucene深入浅出
Posted 分享录
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene深入浅出相关的知识,希望对你有一定的参考价值。
1.Lucene的由来
原始的搜索技术
-
如果用户比较少而且数据库的数据量比较小,那么这种方式实现搜索功能在企业中是比较常见的。
现在的搜索技术
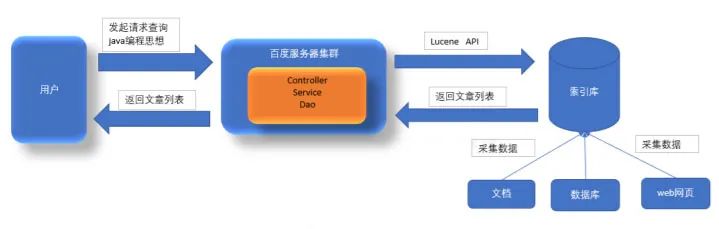
-
使用 Lucene 的 API 的来操作服务器上的索引库,可解决数据库压力和速度的问题。
2.Lucene是什么?
Lucene 是一种全文检索技术,常见的搜索框架 Solr 或 ElasticSearch 都是基于Lucene进行扩展开发的。所谓全文检索就是计算机索引程序通过扫描文件中的每一个词,对每一个词建立一个索引,指明该词在文件中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户。
Lucene 是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎、部分文本分析引擎。
Lucene 的创始人是 Doug Cutting,其目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene 提供了一个简单却强大的应用程序接口,能够做全文索引和搜寻, 在Java开发环境里 Lucene 是一个成熟且免费的开放源代码工具。
Lucene 并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品。
3.常见的查询算法
顺序扫描法
所谓顺序扫描,就是在要找内容的文件中进行全文件扫描,如果此文档包含要查找的内容,则此文档为我们要找的文件,否则接着看下一个文件,直到扫描完所有的文件。
优点:查询精准率高缺点:查询速度会随着数据量的增大而变慢场景:数据库中的Like关键字查询、文本编辑器的Ctrl+F查找功能倒排索引
Lucene采用的就是倒排索引
所谓倒排索引,就是查询前会先将查询的内容提取出来组成文档(正文),然后对文档进行切分词组成索引(目录),这个过程中索引可以去掉重复的词,索引和文档有关联关系,查询的时候先查询索引,通过索引找文档的这个过程叫做全文检索。
优点:查询精准率高、查询速度快缺点:索引文件会占用额外的磁盘空间场景:进行海量数据查询
4.基本的应用场景
用于站内搜索,例如:淘宝、京东
用于垂直领域搜索,例如:招聘网
作为搜索引擎,例如:百度、Google
二、两大核心流程
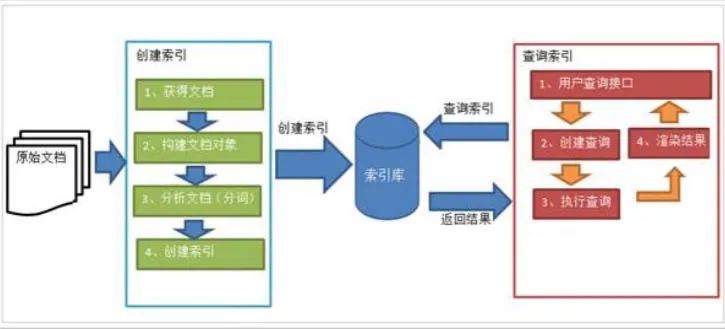
1.构建索引库的流程
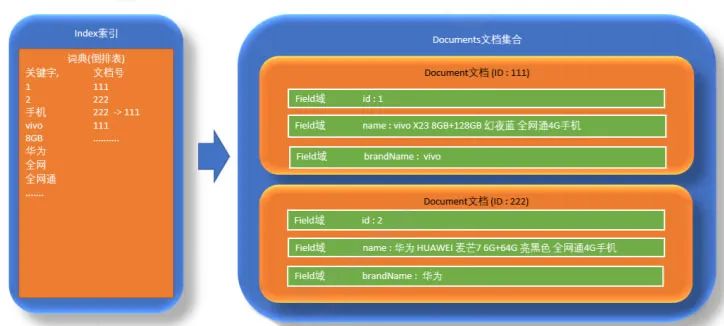
获取内容
从互联网上、数据库、文件系统中等获取需要搜索的原始信息,这个过程就是信息采集,采集数据的目的是为了对原始内容进行索引。
对于互联网上的网页,可以使用工具将网页抓取到本地生成html文件
对于数据库中的数据,可以直接连接数据库读取表中的数据
对于文件系统中的某个文件,可以通过I/O操作读取文件的内容
创建文档
将获取的原始内容创建成文档(Document),文档是由一个一个的键值对组成,相当于数据库中的一条数据。

分析文档
对文档中的内容进行分析,利用分词器进行拆分。
建立索引
将拆分后的词整合在一起,建立成一个索引库,相当于一个目录。

2.搜索索引库中数据的流程
创建查询
用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以指定要查询关键字、要搜索的Field文档域等,查询对象会生成具体的查询语法。
执行搜索
根据查询语法在倒排索引库中分别找出对应搜索词的索引,从而找到索引所对应的文档。
渲染结果
将搜索到的结果从索引库返回给系统,由系统将结果渲染到界面。
三、核心的底层原理
1.索引库的存储结构
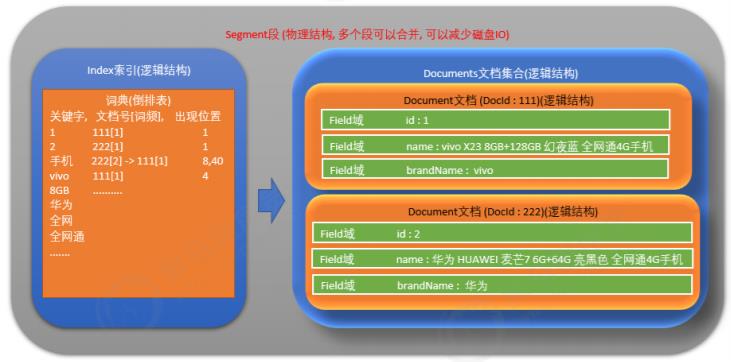
索引(Index)
一个目录一个索引,在Lucene中一个索引库是放在一个文件夹中的。
段(Segment)
一个索引由多个段组成,多个段可以合并以减少读取内容时候的磁盘IO。
Lucene 中的数据写入会先写内存的一个Buffer,当Buffer内数据到一定量后会被flush成一个 Segment,每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。
Segment 中写入的文档不可被修改,但可被删除,删除的方式也不是在文件内部原地更改,而是会由另外一个文件保存需要被删除的文档的DocID,保证数据文件不可被修改。
索引的查询需要对多个 Segment 进行查询并对结果进行合并,还需要处理被删除的文档,为了对查询进行优化,Lucene会有策略对多个Segment进行合并。
文档(Document)
文档是索引的基本单位,不同的文档是保存在不同的段中的,一个段可以包含多篇文档。
新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中。
域(Field)
域是文档的基本单位,由键值对组成。
文档包含不同类型的信息,可以分开索引保存在不同的域里,不同域的索引方式可以不同。
2.索引库中的物理文件

| 名称 | 扩展名 | 描述 |
|---|---|---|
| Segments File | segments_n | 保存了一个提交点(a commit point)的信息 |
| Lock File | write.lock | 防止多个IndexWriter同时写到一份索引文件中 |
| Segment Info | .si | 保存了索引段的元数据信息 |
| Compound File | .cfs,.cfe | 一个可选的虚拟文件,把所有索引信息都存储到复合索 引文件中 |
| Fields | .fnm | 保存fields的相关信息 |
| Field Index | .fdx | 保存指向field data的指针 |
| Field Data | .fdt | 文档存储的字段的值 |
| Term Dictionary | tim | term词典,存储term信息 |
| Term Index | .tip | 到Term Dictionary的索引 |
| Frequencies | .doc | 由包含每个term以及频率的docs列表组成 |
| Positions | .pos | 存储出现在索引中的term的位置信息 |
| Payloads | .pay | 存储额外的per-position元数据信息,例如字符偏移和 用户payloads |
| Norms | nvd,.nvm | nvm文件保存索引字段加权因子的元数据,.nvd文件保 存索引字段加权数据 |
| Per-Document Values | .dvd,.dvm | .dvm文件保存索引文档评分因子的元数据,.dvd文件保 存索引文档评分数据 |
| Term Vector Index | tvx | 将偏移存储到文档数据文件中 |
| Term Vector Documents | .tvd | 包含有term vectors的每个文档信息 |
| Term Vector Fields | .tvf | 字段级别有关term vectors的信息 |
| Live Documents | .liv | 哪些是有效文件的信息 |
| Point values | dii,.dim | 保留索引点,如果有的话 |
3.索引库中词典的构建
指的是索引库中对关键字目录进行构建
| 存储结构 | 描述 |
|---|---|
| 跳跃表 | 占用内存小,且可调,但是对模糊查询支持不好 |
| 排序列表 | 使用二分法查找,不平衡 |
| 字典树 | 查询效率跟字符串长度有关,但只适合英文词典 |
| 哈希表 | 性能高,内存消耗大,几乎是原始数据的三倍 |
| 双数组字典树 | 适合做中文词典,内存占用小,很多分词工具均采用此种算法 |
| FST | 一种有限状态转移机,Lucene 4有开源实现,并大量使用 |
| B树/B+树 | 磁盘索引,更新方便,但检索速度慢,多用于数据库 |
跳跃表结构
单链表

跳跃表
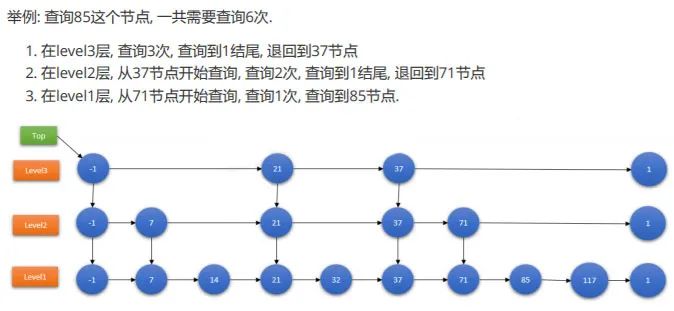
优点:结构简单、跳跃间隔、级数可控缺点:模糊查询支持不好FST结构
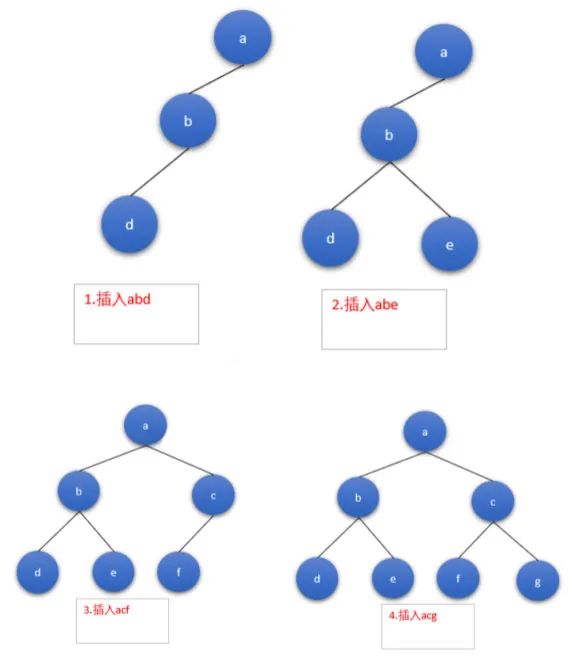
优点:内存占用率低、查询快、能够支持模糊查询缺点:结构复杂、输入要求有序、更新不易
三、Field域详解
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field。
Document是Field 的一个承载体,Field名即是索引内容的字段名称,Field值即是索引的内容。
1.Field域的三大属性
是否分词
是:进行分词,即将Field值进行分词,分词的目的是为了索引。一般进行分词的都是用户可进行搜索的内容
否:不进行分词。一般不进行分词的都是一些不可分割的内容
是否索引
是:进行索引,将Field分词后的词存储到索引域,索引的目的是为了搜索。一般进行索引的都是作为用户查询条件的内容
否:不进行索引。一般不进行索引的都是不作为用户查询条件的内容
是否存储
是:进行存储,将Field值存储在文档中,存储的目的是为了展示。一般进行存储的都是需要展示的内容
否:不进行存储。一般不进行存储的都是不需要展示的内容
2.Field域的常见类型
| Field类型 | Java类型 | 是否分词 | 是否索引 | 是否存储 | 描述 |
|---|---|---|---|---|---|
| StringField | String | N | Y | Y或N | 此类型会将整个字符串存储在索引中 |
| FloatPoint | Float | Y | Y | N | 对Float类型进行分词和索引 |
| DoublePoint | Double | Y | Y | N | 对Double类型进行分词和索引 |
| LongPoint | Long | Y | Y | N | 对Long类型进行分词和索引 |
| IntPoint | Integer | Y | Y | N | 对Integer类型进行分词和索引 |
| StoredField | 多种类型 | N | N | Y | 对值进行存储 |
| TextField | String或流 | Y | Y | Y或N | 对值进行分词、索引 |
| NumericDocValuesField | 数值类型 | - | - | - | 配合排序使用 |
四、索引库的维护
1.添加索引
一般用于在索引库初始化或数据库新增数据的时候
void addIndex() throws Exception{// 创建Document文档对象集合Document document = new Document();document.add(new StringField("id", "000000001", Field.Store.YES));document.add(new TextField("字段名", "字段值", Field.Store.YES));// 创建分词器对象Analyzer analyzer = new StandardAnalyzer();// 创建IndexWriterConfig对象IndexWriterConfig indexConfig = new IndexWriterConfig(analyzer);// 创建Directory对象,用于声明索引库的存储位置Directory directory = FSDirectory.open(Paths.get("索引库的位置"));// 创建IndexWriter对象并把Document写入到索引库中IndexWriter writer = new IndexWriter(directory, indexConfig);writer.addDocument(document);// 释放资源writer.close();}
2.修改索引
一般用于在数据库修改数据的时候
void updIndex() throws Exception{// 创建Document文档对象集合Document document = new Document();document.add(new StringField("id", "000000001", Field.Store.YES));document.add(new TextField("字段名", "新的字段值", Field.Store.YES));// 创建分词器对象Analyzer analyzer = new StandardAnalyzer();// 创建IndexWriterConfig对象IndexWriterConfig indexConfig = new IndexWriterConfig(analyzer);// 创建Directory对象,用于声明索引库的存储位置Directory directory = FSDirectory.open(Paths.get("索引库的位置"));// 创建IndexWriter对象并把Document写入到索引库中IndexWriter writer = new IndexWriter(directory, indexConfig);writer.updateDocument(new Term("id", "000000001"), document);// 释放资源writer.close();}
3.删除索引
一般用于在数据库删除数据的时候
void delIndex() throws Exception{// 创建分词器对象Analyzer analyzer = new StandardAnalyzer();// 创建IndexWriterConfig对象IndexWriterConfig indexConfig = new IndexWriterConfig(analyzer);// 创建Directory对象,用于声明索引库的存储位置Directory directory = FSDirectory.open(Paths.get("索引库的位置"));// 创建IndexWriter对象并把Document写入到索引库中IndexWriter writer = new IndexWriter(directory, indexConfig);writer.deleteDocuments(new Term("id", "000000001"),...);// 根据条件删除writer.deleteDocuments(new Query(),...);// 根据条件删除writer.deleteAll();// 删除全部// 释放资源writer.close();}
五、什么是分词器?
1.基础概述
分词器就是将要索引的内容进行分词解析,分词的目的就是生成索引目录,方便搜索使用。
分词:将采集到的数据Document对象中的Field值按照指定的分词规则进行拆分。
过滤:将拆分后的词进行过滤,比如:去掉重复的词、大写转为小写、标点符号的去除、去掉停用词等。
[注]:停用词就是在搜索引擎解析时会被自动忽略的字或词,比如:语气助词、副词、介词、连接词等。
2.使用时机
索引库建立时使用
在创建索引库或对索引库进行新增、修改时使用,主要是为了对文档内容进行解析,生成索引目录。
搜索内容时使用
在用户搜索时使用,主要是为了对用户输入的关键词进行解析,便于搜索到想要的结果。
3.Lucene原生的分词器
Lucene自带的常见分词器
StandardAnalyzer
可以对用英文进行分词,对中文是单字分词也就是一个字就认为是一个词
WhitespaceAnalyzer
仅仅是去掉了空格,没有其他任何操作,不支持中文分词
SimpleAnalyzer
将除了字母以外的所有符号全部去掉,字母转化为小写,不支持中文分词
CJKAnalyzer
去掉空格、标点符号,字母转化为小写,对中日韩文字进行二分法分词
CustomAnalyzer
自定义分词规则
// 核心源码protected TokenStreamComponents createComponents(String fieldName) {final StandardTokenizer src = new StandardTokenizer();src.setMaxTokenLength(this.maxTokenLength);TokenStream tok = new LowerCaseFilter(src);TokenStream tok = new StopFilter(tok, this.stopwords);return new TokenStreamComponents(src, tok) {protected void setReader(Reader reader) {src.setMaxTokenLength(StandardAnalyzer.this.maxTokenLength);super.setReader(reader);}};}
// 核心源码protected TokenStreamComponents createComponents(String fieldName) {return new TokenStreamComponents(new WhitespaceTokenizer());}
// 核心源码protected TokenStreamComponents createComponents(String fieldName) {Tokenizer tokenizer = new LetterTokenizer();return new TokenStreamComponents(tokenizer, new LowerCaseFilter(tokenizer));}
// 核心源码protected TokenStreamComponents createComponents(String fieldName) {Tokenizer source = new StandardTokenizer();TokenStream result = new CJKWidthFilter(source);TokenStream result = new LowerCaseFilter(result);TokenStream result = new CJKBigramFilter(result);return new TokenStreamComponents(source, new StopFilter(result, this.stopwords));}
protected TokenStreamComponents createComponents(String fieldName) {Tokenizer tk = this.tokenizer.create(this.attributeFactory(fieldName));TokenStream ts = tk;TokenFilterFactory[] var4 = this.tokenFilters;int var5 = var4.length;for(int var6 = 0; var6 < var5; ++var6) {TokenFilterFactory filter = var4[var6];ts = filter.create((TokenStream)ts);}return new TokenStreamComponents(tk, (TokenStream)ts);}
4.常见的中文分词器
第三方提供的分词器
paoding
庖丁解牛最新版在 https://code.google.com/p/paoding/ 中最多支持Lucene 3.0,且最新提交的代码在 2008-06-03,在svn中最新也是2010年提交,已经过时,不予考虑。
mmseg4j
最新版已从 https://code.google.com/p/mmseg4j/ 移至 https://github.com/chenlb/mmseg4j-solr,支持Lucene 4.10,且在github中最新提交代码是2014年6月,从09年~14年一 共有:18个版本,也就是一年几乎有3个大小版本,有较大的活跃度,用了mmseg算法。
ansj_seg
最新版本在 https://github.com/NLPchina/ansj_seg tags仅有1.1版本,从2012年到 2014年更新了大小6次,但是作者本人在2014年10月10日说明:“可能我以后没有精力来维护 ansj_seg了”,现在由”nlp_china”管理。2014年11月有更新。并未说明是否支持Lucene,是一个 由CRF(条件随机场)算法所做的分词算法。
imdict-chinese-analyzer
最新版在 https://code.google.com/p/imdict-chinese-analyzer/ , 最新更新也在2009年5月,下载源码,不支持Lucene 4.10 。是利用HMM(隐马尔科夫链)算法。
Jcseg
最新版本在http://git.oschina.net/lionsoul/jcseg,支持Lucene 4.10,作者有较高的活跃度。利用mmseg算法。
IK-analyze
最新版在https://code.google.com/p/ik-analyzer/上,支持Lucene 4.10从2006年 12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主 体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开 始,IK发展为面向Java的公用 分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了 简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。但是也就是 2012年12月后没有在更新。
// 核心源码protected TokenStreamComponents createComponents(String fieldName) {Tokenizer _IKTokenizer = new IKTokenizer(this.useSmart());return new TokenStreamComponents(_IKTokenizer);}
六、基础Java API的使用
1.创建模拟数据
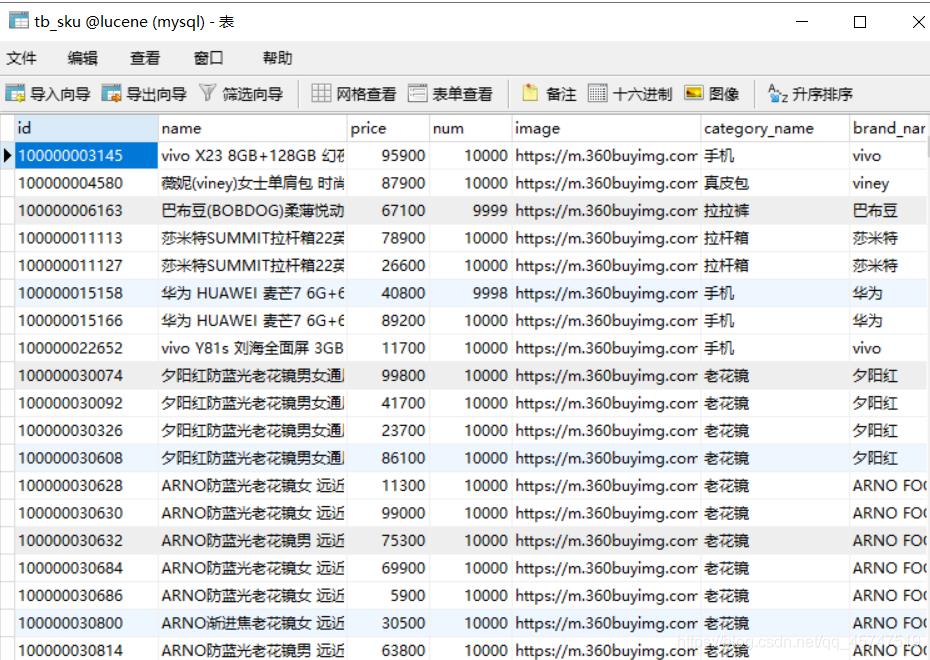
创建数据库 lucene ,执行 tb_sku.sql 文件,模拟商品数据。
2.项目环境的搭建
添加相关依赖
添加配置
<!--Spring Boot相关依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-thymeleaf</artifactId></dependency><!--Lucene相关依赖--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>8.4.0</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId><version>8.4.0</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>8.4.0</version></dependency><dependency><groupId>com.github.magese</groupId><artifactId>ik-analyzer</artifactId><version>8.4.0</version></dependency><!--数据库相关依赖--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.12</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.2.0</version></dependency><!--其它依赖--><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.73</version></dependency>
server.port=8080server.servlet.context-path=/spring.application.name=lucenespring.datasource.type=com.alibaba.druid.pool.DruidDataSourcespring.datasource.driver-class-name=com.mysql.jdbc.Driverspring.datasource.url=jdbc:mysql://localhost:3306/lucenespring.datasource.username=rootspring.datasource.password=rootmybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImplmybatis-plus.type-aliases-package=com.jhy.lucene.pojo
分词器的配置
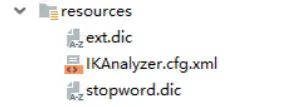
中文分词器配置,解压 ik-analyzer 的源码,将配置文件拷贝到项目的 resources 目录下 (可选)
创建实体类
生成索引库过程
("tb_sku")public class Sku {//商品主键idprivate String id;//商品名称private String name;//价格private Integer price;//库存数量private Integer num;//图片private String image;//分类名称private String categoryName;//品牌名称private String brandName;//规格private String spec;//销量private Integer saleNum;}
void createFlow() throws Exception{// 获取数据List<Sku> skus = skuDao.selectList(null);// 创建Document文档对象集合List<Document> documents = new ArrayList<>();for (Sku sku : skus) {Document document = new Document();document.add(new TextField("id", sku.getId(), Field.Store.YES));document.add(new TextField("name", sku.getName(), Field.Store.YES));document.add(new TextField("price", sku.getPrice().toString(),Field.Store.YES));document.add(new TextField("image", sku.getImage(), Field.Store.YES));document.add(new TextField("categoryName", sku.getCategoryName(),Field.Store.YES));document.add(new TextField("brandName", sku.getBrandName(), Field.Store.YES));documents.add(document);}// 创建分词器对象Analyzer analyzer = new StandardAnalyzer();// 创建IndexWriterConfig对象IndexWriterConfig indexConfig = new IndexWriterConfig(analyzer);// 创建Directory对象,用于声明索引库的存储位置Directory directory = FSDirectory.open(Paths.get("索引库的位置"));// 创建IndexWriter对象并把Document写入到索引库中IndexWriter writer = new IndexWriter(directory, indexConfig);for (Document document : documents) {writer.addDocument(document);}// 释放资源writer.close();}
3.测试使用
查看生成的索引库
使用Luke工具查看内容

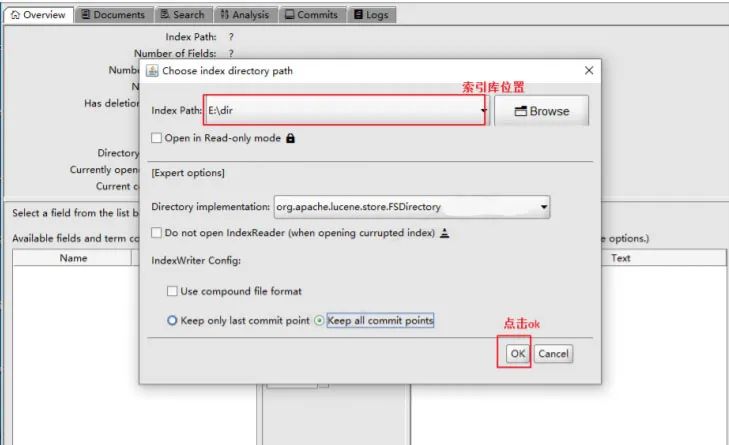
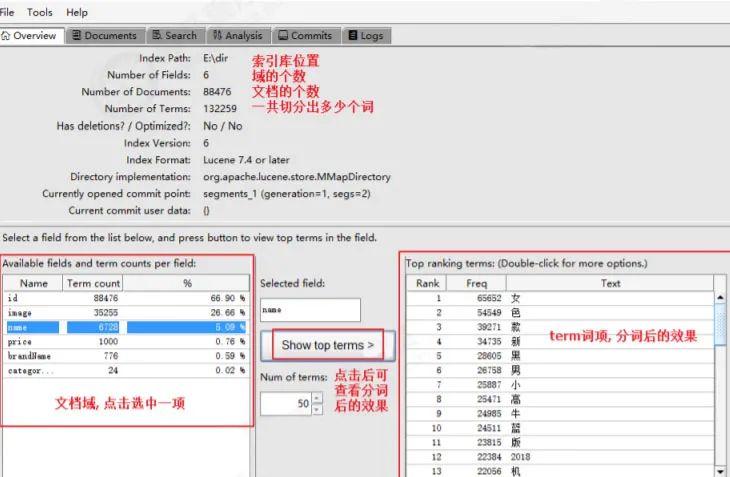
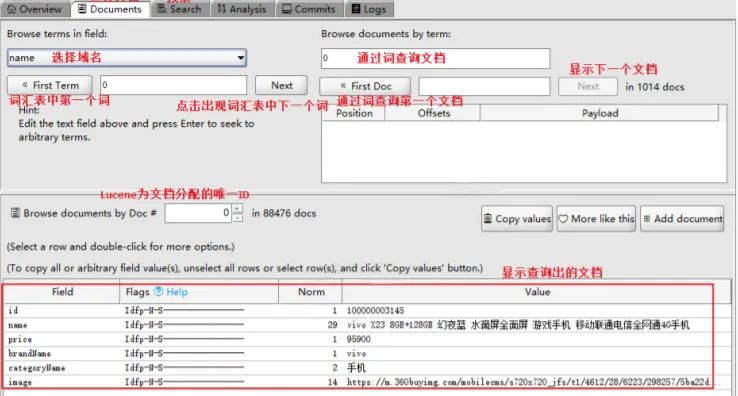
使用Luke工具进行搜索
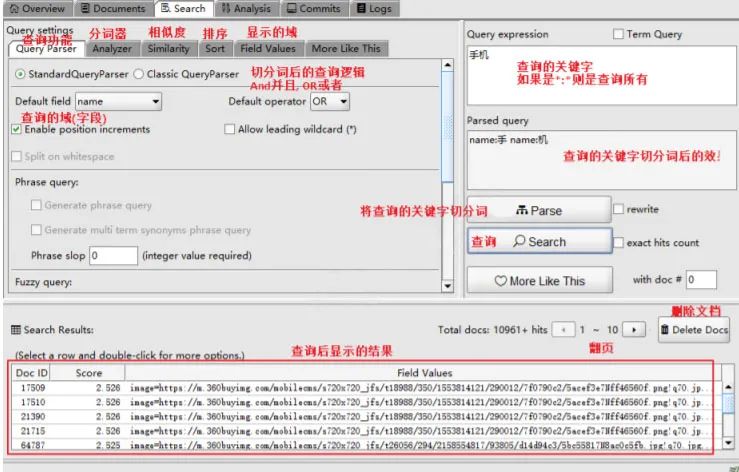
使用代码进行搜索
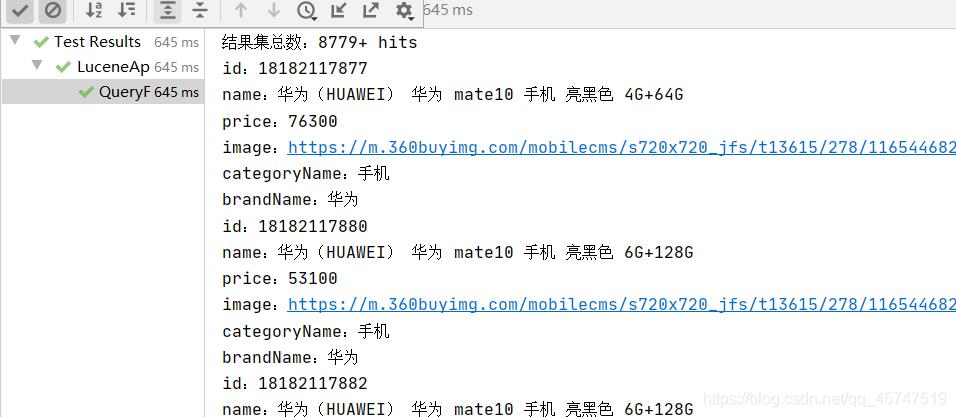
void QueryFlow() throws Exception{// 创建Query搜索对象(参数一:默认查询的Field域名称、参数二:使用的分词器)Analyzer analyzer = new StandardAnalyzer();QueryParser queryParser = new QueryParser("name", analyzer);Query query = queryParser.parse("华为手机");// 创建Directory对象,指明索引库的位置Directory directory =FSDirectory.open(Paths.get("索引库的位置"));// 创建IndexReader索引读取对象IndexReader reader = DirectoryReader.open(directory);// 创建IndexSearcher索引搜索对象IndexSearcher searcher = new IndexSearcher(reader);// 执行搜索,获取返回结果集TopDocsTopDocs docs = searcher.search(query, 10);// 解析结果集System.out.println("结果集总数:" + docs.totalHits);ScoreDoc[] scoreDocs = docs.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {Document document = searcher.doc(scoreDoc.doc);System.out.println("id:" + document.get("id"));System.out.println("name:" + document.get("name"));System.out.println("price:" + document.get("price"));System.out.println("image:" + document.get("image"));System.out.println("categoryName:" + document.get("categoryName"));System.out.println("brandName:" + document.get("brandName"));}// 释放资源reader.close();}
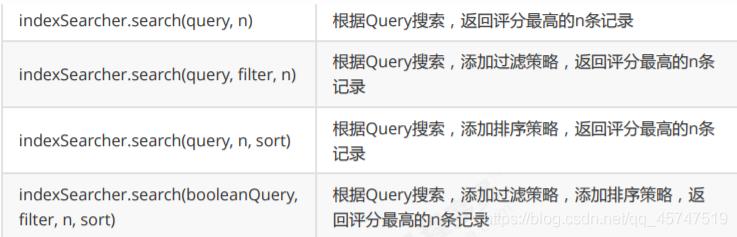
七、Lucene的高级使用
1.文本搜索
void Query() throws Exception{Analyzer analyzer = new IKAnalyzer();//参数一:默认查询的Field域名称//参数二:使用的分词器类型QueryParser queryParser = new QueryParser("name", analyzer);Query query = queryParser.parse("华为手机"); // 使用默认Field域名称Query query = queryParser.parse("name:华为手机"); // 使用指定Field域名称Query query = queryParser.parse("description:华为手机"); // 使用指定Field域名称// 创建Directory对象,指明索引库的位置Directory directory = FSDirectory.open(Paths.get("索引库的位置"));// 创建IndexReader索引读取对象IndexReader reader = DirectoryReader.open(directory);// 创建IndexSearcher索引搜索对象IndexSearcher searcher = new IndexSearcher(reader);// 执行搜索,获取返回结果集TopDocsTopDocs docs = searcher.search(query);}
2.多域搜索
void Query() throws Exception{Analyzer analyzer = new IKAnalyzer();//参数一:默认查询的Field域名称集合//参数二:使用的分词器类型String[] fields = {"name", "description"};QueryParser queryParser = new MultiFieldQueryParser(fields, analyzer);Query query = queryParser.parse("华为手机");// 创建Directory对象,指明索引库的位置Directory directory = FSDirectory.open(Paths.get("索引库的位置"));// 创建IndexReader索引读取对象IndexReader reader = DirectoryReader.open(directory);// 创建IndexSearcher索引搜索对象IndexSearcher searcher = new IndexSearcher(reader);// 执行搜索,获取返回结果集TopDocsTopDocs docs = searcher.search(query);}
3.范围搜索
void Query() throws Exception{Analyzer analyzer = new IKAnalyzer();//参数一:查询的Field域名称//参数二:最小值//参数三:最大值Query query = FloatPoint.newRangeQuery("price", 100, 1000);// 创建Directory对象,指明索引库的位置Directory directory = FSDirectory.open(Paths.get("索引库的位置"));// 创建IndexReader索引读取对象IndexReader reader = DirectoryReader.open(directory);// 创建IndexSearcher索引搜索对象IndexSearcher searcher = new IndexSearcher(reader);// 执行搜索,获取返回结果集TopDocsTopDocs docs = searcher.search(query);}
4.组合搜索
void Query() throws Exception{Analyzer analyzer = new IKAnalyzer();// 条件1Query query1 = FloatPoint.newRangeQuery("price", 100, 1000);// 条件2QueryParser queryParser = new QueryParser("name", analyzer);Query query2 = queryParser.parse("华为手机");// 条件组合// BooleanClause.Occur.MUST 必须 相当于and, 并且// BooleanClause.Occur.MUST_NOT 不必须 相当于not, 取非// BooleanClause.Occur.SHOULD 应该 相当于or, 或者BooleanQuery.Builder builder = new BooleanQuery.Builder();builder.add(query1, BooleanClause.Occur.MUST);builder.add(query2, BooleanClause.Occur.MUST);Query query = builder.build();// 创建Directory对象,指明索引库的位置Directory directory = FSDirectory.open(Paths.get("索引库的位置"));// 创建IndexReader索引读取对象IndexReader reader = DirectoryReader.open(directory);// 创建IndexSearcher索引搜索对象IndexSearcher searcher = new IndexSearcher(reader);// 执行搜索,获取返回结果集TopDocsTopDocs docs = searcher.search(query);}
------------END-----------
更多原创文章请扫描上面(微信内长按可识别)二维码访问我的个人网站(https://www.xubingtao.cn),或者打开我的微信小程序: 可以评论以及在线客服反馈问题,其他平台小程序和APP请访问:https://www.xubingtao.cn/?p=1675。祝大家生活愉快!
以上是关于Lucene深入浅出的主要内容,如果未能解决你的问题,请参考以下文章