MySQL水平无限拓展
Posted IT猿Q
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL水平无限拓展相关的知识,希望对你有一定的参考价值。
一、概述
数据拆分常用的就是垂直拆分和水平拆分,垂直拆分比较简单,也就是本来一个数据库,数据量大之后,从业务角度进行拆分多个库。如下图,独立的拆分出订单库和用户库。
而水平拆分的概念,是同一个业务数据量大之后,进行水平拆分
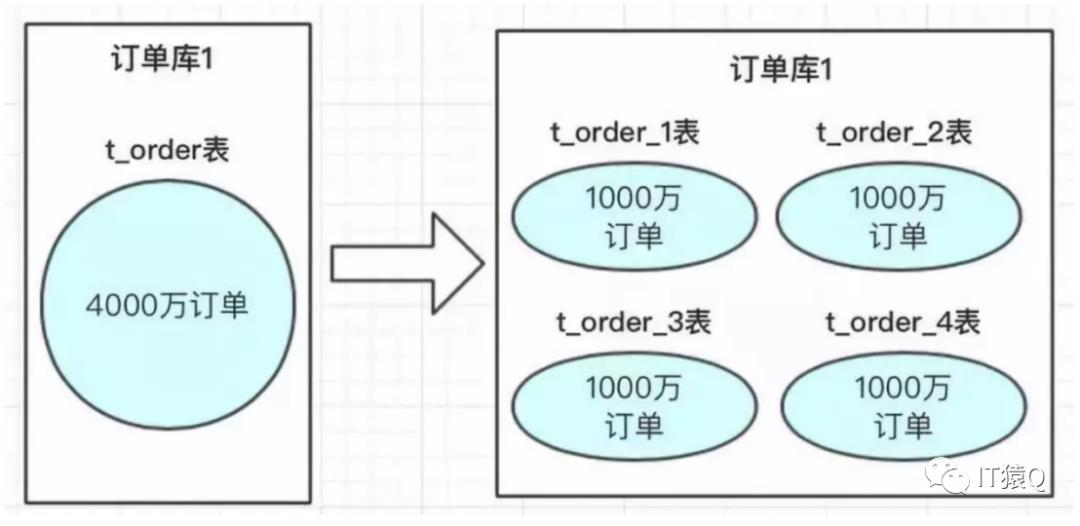
像上图中订单数据达到了4000万,mysql单表数据太大,会导致性能变慢。水平拆分方案可以把4000万数据拆分4张表或者更多。当然也可以分库,再分表;把压力从数据库层级分开。当然,这种水平拆分方案在拓容时比较困难。接下来,我们看一下这种水平分库分表的实施方案。
二、常用分库分表方案
水平分库分表方案中有常用的方案,hash取模和range范围方案,range方案比较简单,比如表0存储id为1到1千万的数据,表1存储id为1千万到2千万的数据,以此类推,随着数据增长不断增加表或库即可,如下图:
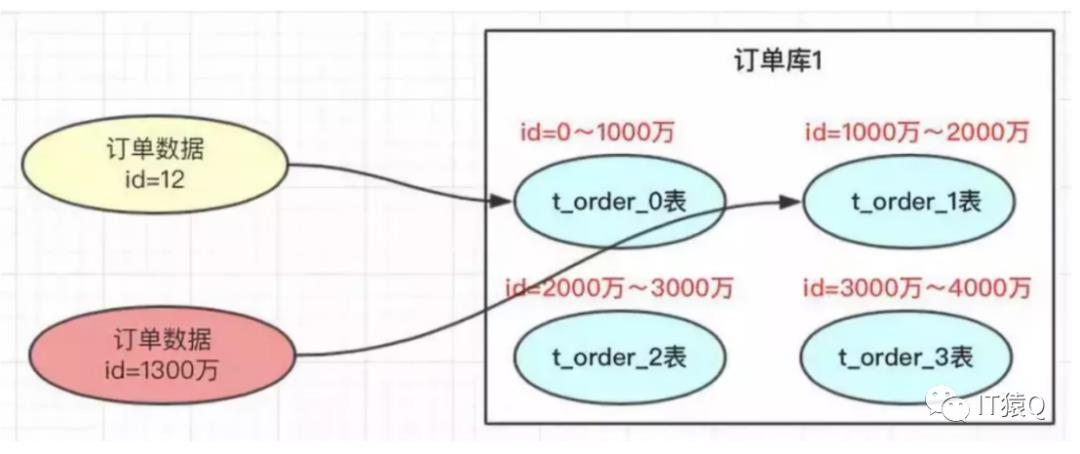
range方案是简单,但是它有热点数据问题,假设这是张订单表,最后面新增的那张表肯定是最频繁使用的表,而前面的表可能很少使用到,这样就会造成最后面那张表的负载过大,最终会达到一个瓶颈,未必能够满足系统的承载量。要想达到负载均衡,还得使用hash取模法,如下图:
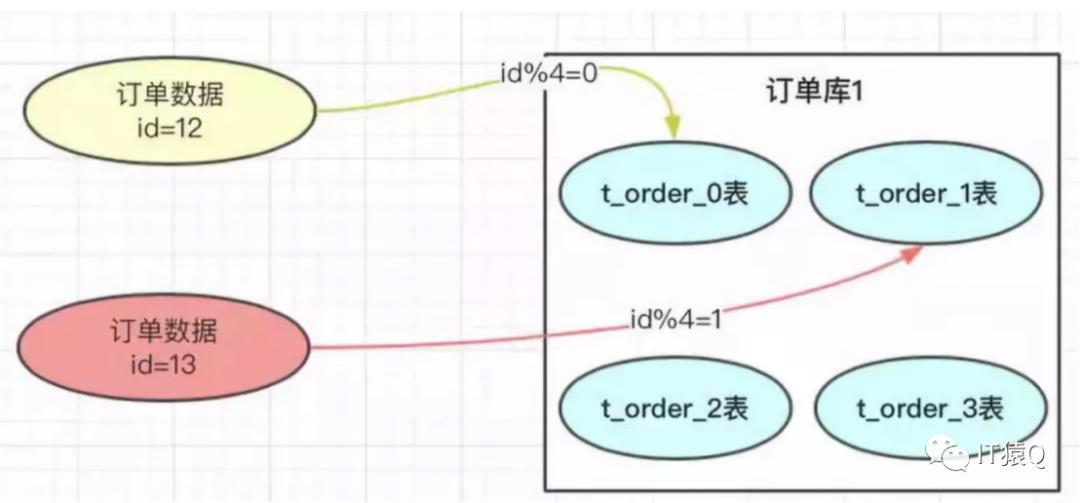
这种方案直观且简单易行,不过,如果业务继续增长,数据量已经增加到上亿,这个时候四张表可能也扛不住了,那就需要再继续拆分,比如拆成8个表,如下图:
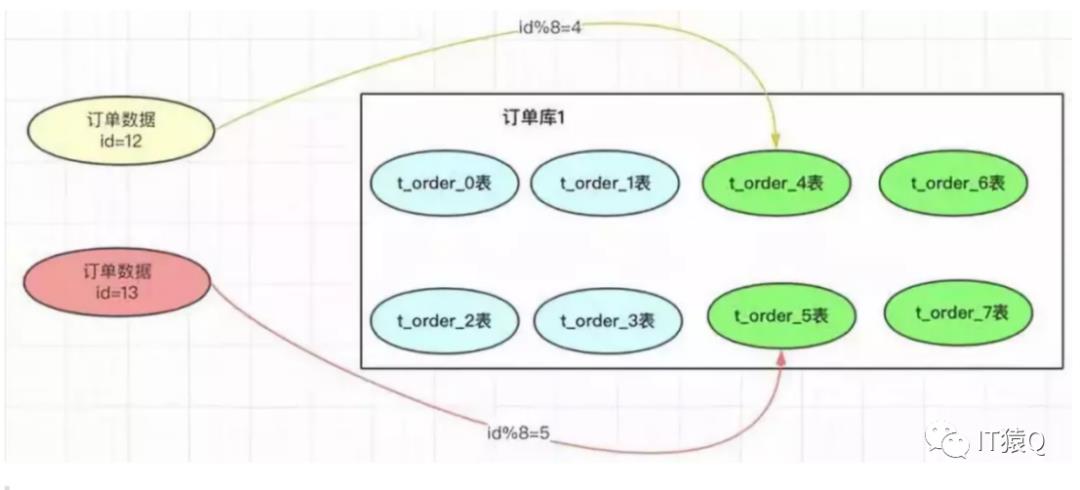
在这个拓容过程中,困难的是对旧数据的迁移,我们接着探讨可行方案
方案1:停机维护
停机之后,没有流量进入,这时可以直接新建多四张表,然后需要自研一个数据迁移工具,把旧数据重新分配到8张表,迁移完毕之后恢复流量即可,这个方案风险较高,数据迁移人员需要在规定时间内完成,并且不能出现异常问题,并且,不是所有业务都可以接受停机。
方案2:日志法
这个方案思路也很简单,就是业务应用记录下被修改过的记录,等数据迁移完毕之后,把那些在迁移过程中被修改过的数据重新从旧表覆盖新表的值,这样就可以做到无需停机,大体步骤如下:
步骤一:服务进行升级,记录“对旧库上的数据修改”的日志(这里的修改,指数据的insert, delete, update),这个日志不需要记录详细数据,主要记录下面几项内容:
库名 |
表名 |
主键ID |
类型(insert/update/delete) |
具体新增了什么行,修改后的数据格式是什么,不需要详细记录。这样的好处是,不管业务细节如何变化,日志的格式是固定的,这样能保证方案的通用性(不一定非得是日志,记录在数据库也是可以的,保证到日志表和业务表的事务一致性就行)。
步骤二:研发一个数据迁移工具,进行数据迁移。这个数据迁移工具和离线迁移工具一样,把旧库中的数据转移到新库中来。步骤三:研发一个读取日志并迁移数据的小工具,要把步骤二迁移数据过程中产生的差异数据追平,即用旧表数据覆盖新表的数据
步骤四:研发一个数据校验的小工具,在持续重放日志,追平数据的过程中,将旧库和新库中的数据进行比对,直到数据完全一致
步骤五:在数据比对完全一致之后,将流量迁移到新库,新库提供服务,完成迁移。如果步骤四数据一直是99.9%的一致,不能完全一致,也是正常的,可以做一个秒级的旧库readonly,等日志重放程序完全追上数据后,再进行切库切流量。
至此,升级完毕,整个过程能够持续对线上提供服务,不影响服务的可用性。
方案3:双写法
步骤一:服务进行升级,对“对旧库上的数据修改”(这里的修改,为数据的insert, delete, update),在新库上进行相同的修改操作,这就是所谓的“双写”,主要修改操作包括:
(1)旧库与新库的同时insert
(2)旧库与新库的同时delete
(3)旧库与新库的同时update
由于新库中此时是没有数据的,所以双写旧库与新库中的affect rows可能不一样,不过这完全不影响业务功能,只要不切库,依然是旧库提供业务服务
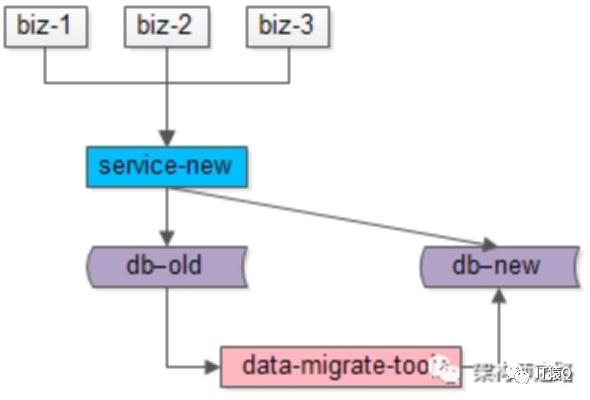
步骤二:研发一个数据迁移工具,进行数据迁移。这个数据迁移工具在本文中已经出现过了,把旧库中的数据转移到新库中来。
由于迁移数据的过程中,旧库新库双写操作在同时进行,怎么证明数据迁移完成之后数据就完全一致了呢?
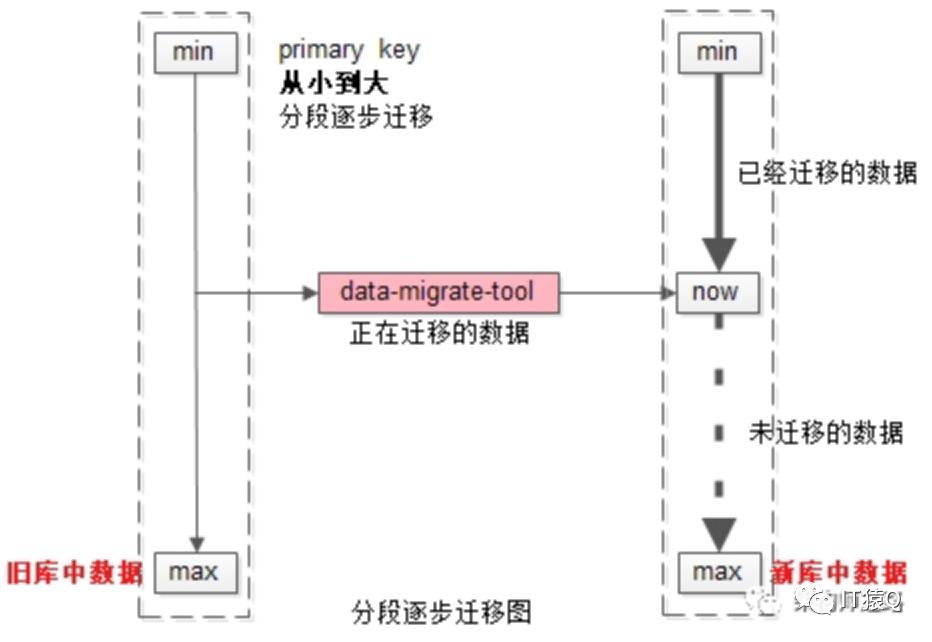
如上图所示:
(1)左侧是旧库中的数据,右侧是新库中的数据
(2)按照primary key从min到max的顺序,分段,限速进行数据的迁移,假设已经迁移到now这个数据段
数据迁移过程中的修改操作分别讨论:
(1)假设迁移过程中进行了一个双insert操作,旧库新库都插入了数据,数据一致性没有被破坏
(2)假设迁移过程中进行了一个双delete操作,这又分为两种情况
(2.1)假设这delete的数据属于[min,now]范围,即已经完成迁移,则旧库新库都删除了数据,数据一致性没有被破坏
(2.2)假设这delete的数据属于[now,max]范围,即未完成迁移,则旧库中删除操作的affect rows为1,新库中删除操作的affect rows为0,但是数据迁移工具在后续数据迁移中,并不会将这条旧库中被删除的数据迁移到新库中,所以数据一致性仍没有被破坏
(3)假设迁移过程中进行了一个双update操作,可以认为update操作是一个delete加一个insert操作的复合操作,所以数据仍然是一致的
除非除非除非,在一种非常非常非常极限的情况下:
(1)date-migrate-tool刚好从旧库中将某一条数据X取出
(2)在X插入到新库中之前,旧库与新库中刚好对X进行了双delete操作
(3)date-migrate-tool再将X插入到新库中
这样,会出现新库比旧库多出一条数据X。
但无论如何,为了保证数据的一致性,切库之前,还是需要进行数据校验的
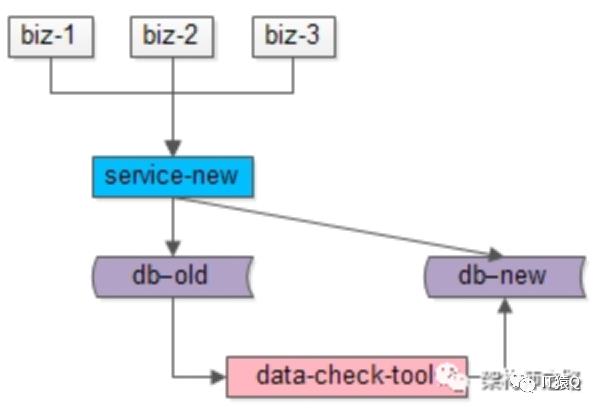
步骤三:在数据迁移完成之后,需要使用数据校验的小工具,将旧库和新库中的数据进行比对,完全一致则符合预期,如果出现步骤二中的极限不一致情况,则以旧库中的数据为准。
步骤四:数据完全一致之后,将流量切到新库,完成平滑数据迁移。
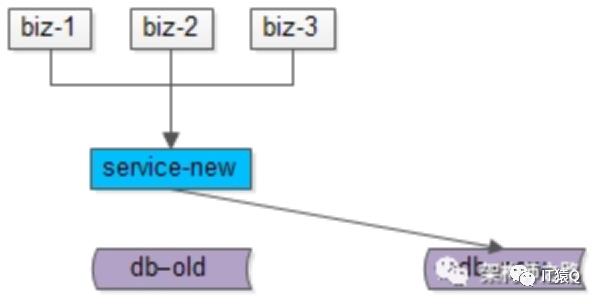
至此,升级完毕,整个过程能够持续对线上提供服务,不影响服务的可用性。
三、合体版分库分表方案
range方案和hash方案都各有自己的优缺点,range可以解决数据迁移问题,hash可以解决数据均匀的问题,那我们可以不可以两者相结合呢?利用这两者的特性呢?
答案是可以的,这时需要引入group的概念,这个组里面包含了一些分库以及分表,如下图:
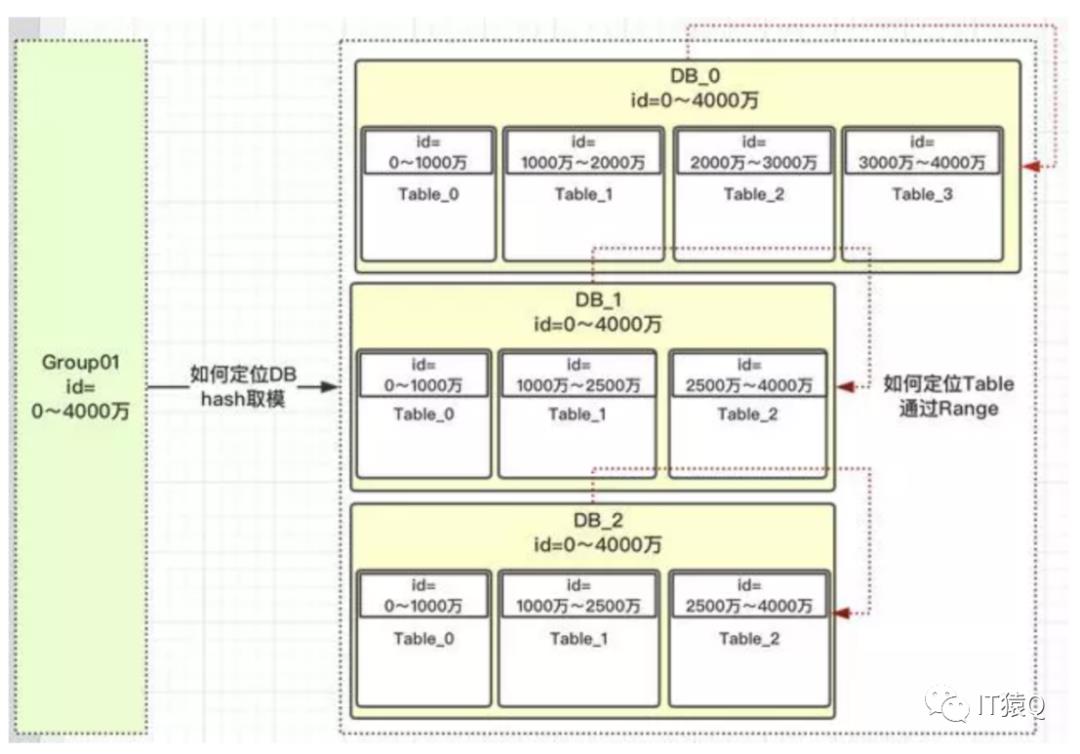
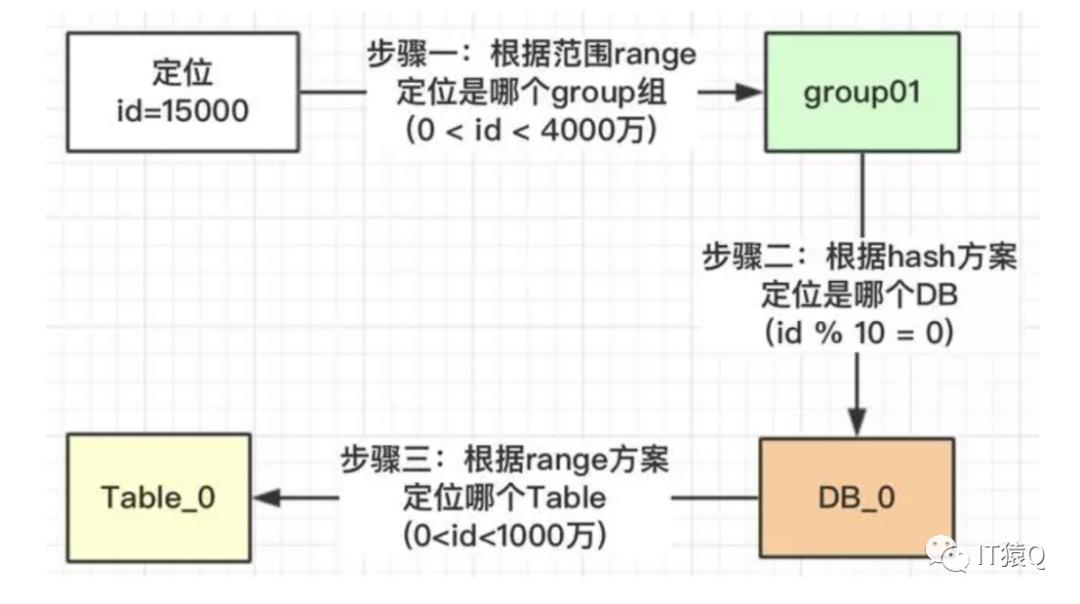
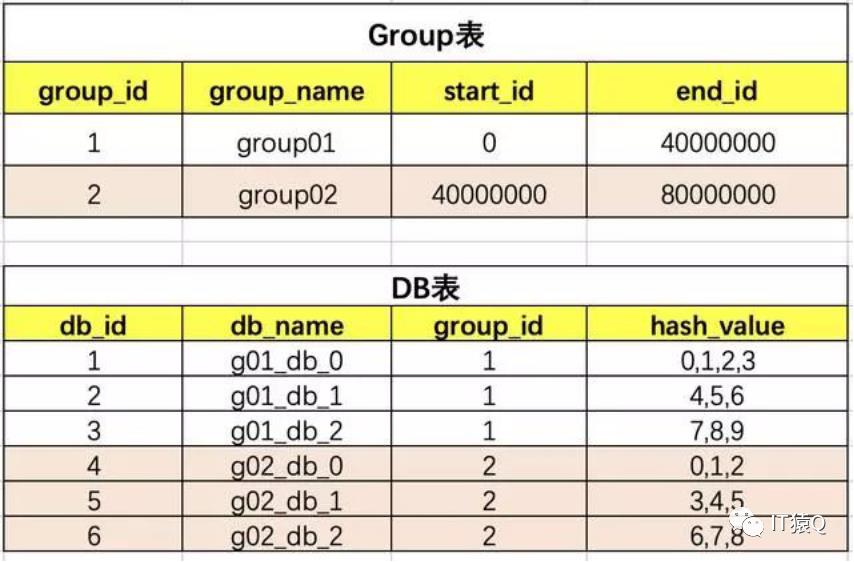
上图的group01负责id范围0到4000万的数据,共有3个库,10张表。那么一个id要怎么定位到哪个DB,又再定位到哪张表呢?看以id=15000的一条数据为例看下面的流程图:
到这里,可能会有疑问:为什么group01组中有3个DB,但hash取模时的模数是10而不是3呢?
这是因为在我们安排服务器时,有些服务器的性能高,存储高,就可以安排多存放些数据,有些性能低的就少放点数据。如果我们取模是按照DB总数3,进行取模,那就代表着【0,4000万】的数据是平均分配到3个DB中的,那就不能够实现按照服务器能力适当分配了。按照Table总数10就能够达到,看如何达到:
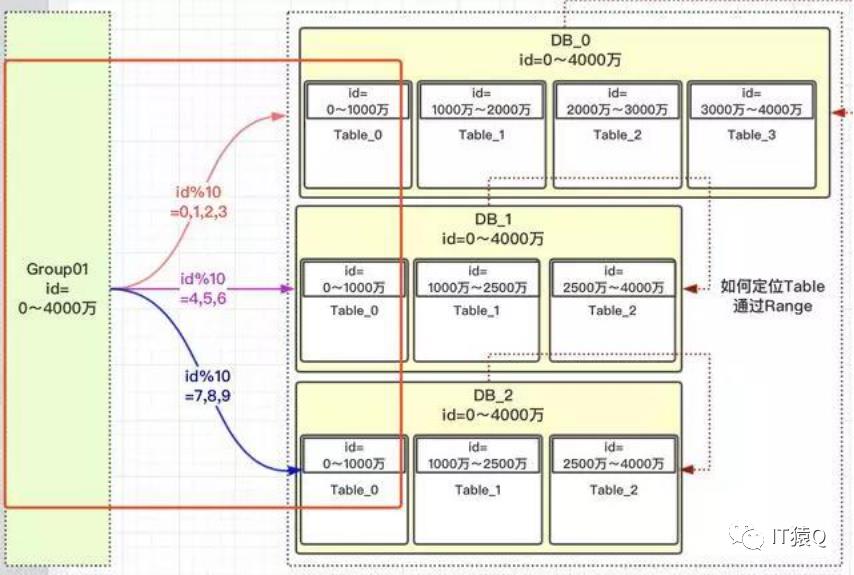
上图中我们对10进行取模,如果值为【0,1,2,3】就路由到DB_0,【4,5,6】路由到DB_1,【7,8,9】路由到DB_2。现在小伙伴们有没有理解,这样的设计就可以把多一点的数据放到DB_0中,其他2个DB数据量就可以少一点。DB_0承担了4/10的数据量,DB_1承担了3/10的数据量,DB_2也承担了3/10的数据量。整个Group01承担了【0,4000万】的数据量。
通过上述方法,我们解决了热点数据负载不均衡的问题,我们可以看到,id在【0,1000万】范围内的,根据上面的流程设计,1000万以内的id都均匀的分配到DB_0,DB_1,DB_2三个数据库中的Table_0表中,为什么可以均匀,因为我们用了hash的方案,对10进行取模。
那要如何拓容呢?我们依葫芦画瓢再搞一个group02即可:
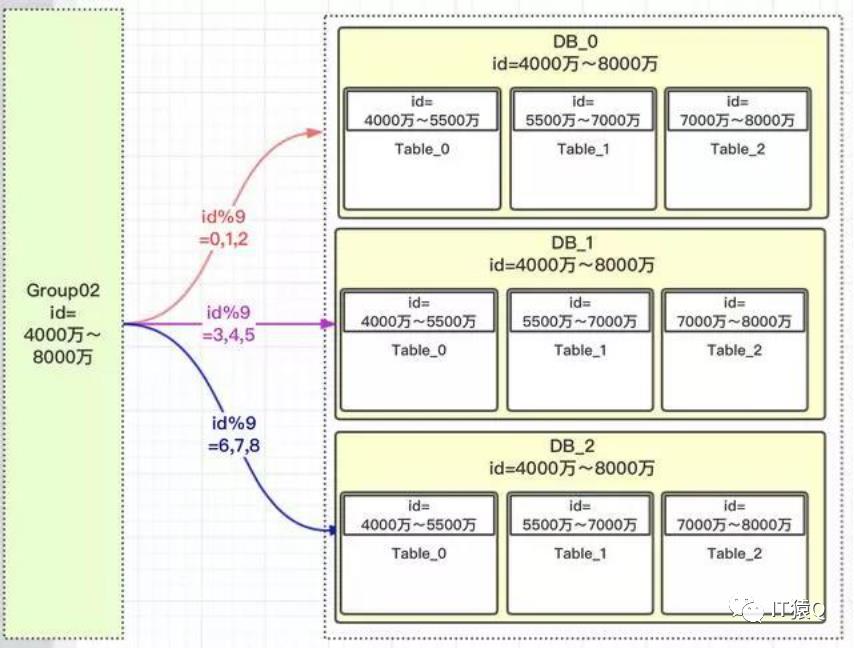
如上图所示,假设我们把id在[1,4000万]分在group01,把id在[4001万,8000万]分在group02,然后在group01、group02内再对id取模分表,这样当id快增长到8000万时,我们再加一个group03分组,以此类推即可。group02的定位逻辑如下:
1.先根据id框定在哪个区间,如现有一个id为40000010的记录,那就会定位在group02这个分组
2.因为group02有9张表,我们就得到40000010 % 9 = 5,所以落在DB_1
3.再看一下40000010这个id范围,是落在Table_0这张表,至此定位完毕
上述方案的映射关系表如下:
到这里可能还有人会想,如果不存在数据库服务器硬件配置不一致的情况,在定位库的时候是不是可以不对表总数取模,而对数据库总数取模呢?当然可以,假设我们的group01还是分为DB_0,DB_1,DB_2三个库,每个库都设置4张表Table_0,Table_1,Table_2,Table_3,那定位DB的时候就用id模3,定位Table的时候就用id模4,假设现在有一个id=15的数据,15%3=0,将定位到DB_0,然后再取模15%4=3,将定位到Table_2。这样,这4000万条数据就会均匀的分配到3个DB的3张表上,这里为什么是3张表而不是12张表呢?这是因为分配到DB_0的id,永远都是模数为0的数,而这一类的id对4取模,永远得到3,所以它永远只会命中Table_2这张表,当然,如果定位库时的字段和定位表时的字段不是同一个字段,这个时候是可以平均分配到12张表上面的,比如定位库时使用order_Id字段取模,定位表时使用user_id字段取模,这种情况就能做到所有表都会被命中,不过,如果某些user_id交易量特别多,就会导致被这些user_id命中的表数据量会比其他表的数据要多。
综上来说,在定位库的时候还是对总表数取模更加通用,如果不存在硬件配置不一样的情况,那就给每个库都分配相同个数的hash值就好了
以 分成3组 + 数据库高可用方案(以MGR为例) 的话,整体的部署结构可能如下图:
四、总结
range方案,hash方案,range+hash方案,都有各自的优缺点,需要根据不同的业务属性、公司发展阶段、运维能力等维度来判断应该选择哪种方案。range+hash方案看起来挺完美,但也有其缺点的,比如:
1)如果是订单类业务,就有明显的冷热数据属性,当id增长到group02的时候,group01上的数据可能就很少会被用到了,但他们又占据了很大一部分资源,这个时候我们可能需要把group01上的数据进行归档处理,比如把group01上的数据全部导入Elasticsearch/Mongodb/Hbase/ClickHouse等数据仓库,这样就可以释放group01的机器资源,后续若需要拓展多一个group03,就又可以重复使用这部分硬件资源了。2)如果是用户或者账户类业务,它就没有明显的冷热数据属性,这类业务对于分组数据量的区间把控就会变得比较重要,如果分组内数据区间过小,会导致分组中的数据过少,可能远没有达到这些机器的瓶颈,造成资源浪费,如果分组内数据区间过大,可能导致分组中的数据过大,数据库负载过高,难以很好的应对系统响应,这时就需要为这个组增加机器并重新分片。
3)上面的案例是根据单个字段来分库的情况,假设这是张用户表,分库的字段是userId,而用户登录时一般是根据 username、email、phone等来登录,这时就需要建立userId和username、email、phone的映射关系,比如建一张映射表,只保存这4个字段,因为表字段少,可以保存很多数据而不需要对映射表进行分表处理,除此之外,也可以使用Redis等缓存中间件来保存映射关系。
4)上面的案例是根据单个字段来分库的情况,假设这是张订单表,交易系统是通过订单id来对订单进行读、写,而卖家、买家可能需要查询各自的订单,这个时候可能需要进行数据冗余,就是为订单表冗余两份数据,一份是卖家订单表,这个表通过卖家Id来水平分库、另一份是买家订单表,通过买家id来水平分库。
5)上面的案例是根据单个字段来分库的情况,假设这是张订单表,除了订单id、卖家id、买家id等条件查询,可能公司的同事在内部运营系统上还需要按时间、商品id等各种条件来查询或统计时,这个就需要分开处理了,优先保障交易系统的正常进行,至于卖家、买家、运营人员等,他们的查询需求,实时性要求相对没那么高,这时可以把订单表同步到Elasticsearch/Mongodb/Hadoop/ClickHouse等外部存储介质中提供查询。
不管是hash方案还是range+hash方案,对运维的要求是很高的,并且,如果给每一台数据库都加上高可用方案的话,那单纯是数据库物理机器的成本就高得吓人,真的到了很大的数据量级的时候,可以考虑下引入分布式数据库,如:Tidb、OceanBase、Spanner 等都提供了一整套完善的解决方案,能实现数据强一致、高可用、水平拓展,全部在数据库层面实现了。像TiDB不但提供OLTP在线交易保障,还提供OLAP离线分析功能,也就是不但可以作为在线交易库,还可以作为数据仓库,能够节省下建立数据仓库的成本。
参考文章:
https://www.w3cschool.cn/architectroad/architectroad-data-smooth-migration.html
以上是关于MySQL水平无限拓展的主要内容,如果未能解决你的问题,请参考以下文章
玩转RT-Thread系列教程--MultiButton-可以无限拓展按键的组件
玩转RT-Thread系列教程--MultiButton-可以无限拓展按键的组件