不想手动打验证码?基于python的验证码自动识别方案
Posted 魔理沙的日记本
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不想手动打验证码?基于python的验证码自动识别方案相关的知识,希望对你有一定的参考价值。
这是我记录的第 2 个没用小技巧
为了您的健康请勿酒后编程
胡桃真是太可爱啦
在用爬虫搜集信息时经常会遇到需要登陆才能搜集的情况。
平时自己登录都懒得从歪比吧波里分辨验证码的你
怎么能受这种委屈?
没有你爬虫哪来的验证码啊喂,好好反省一下
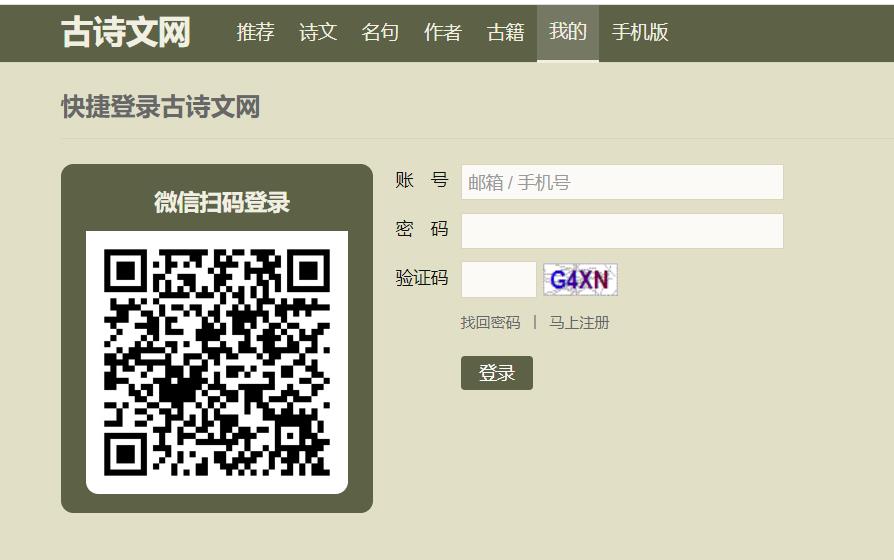
就这?
我当然不是要用OCR识别这么高门槛的东西
就像python的丰富三方库一样
我们要学会借助外力。
那就是已经十分完备的验证码识别平台。
本次我要介绍的平台叫超级鹰。
是付费平台,不过一包辣条的钱足够。
Languages : Python 100%
运行环境:Python3
Windows/Linux/Mac
项目分析:
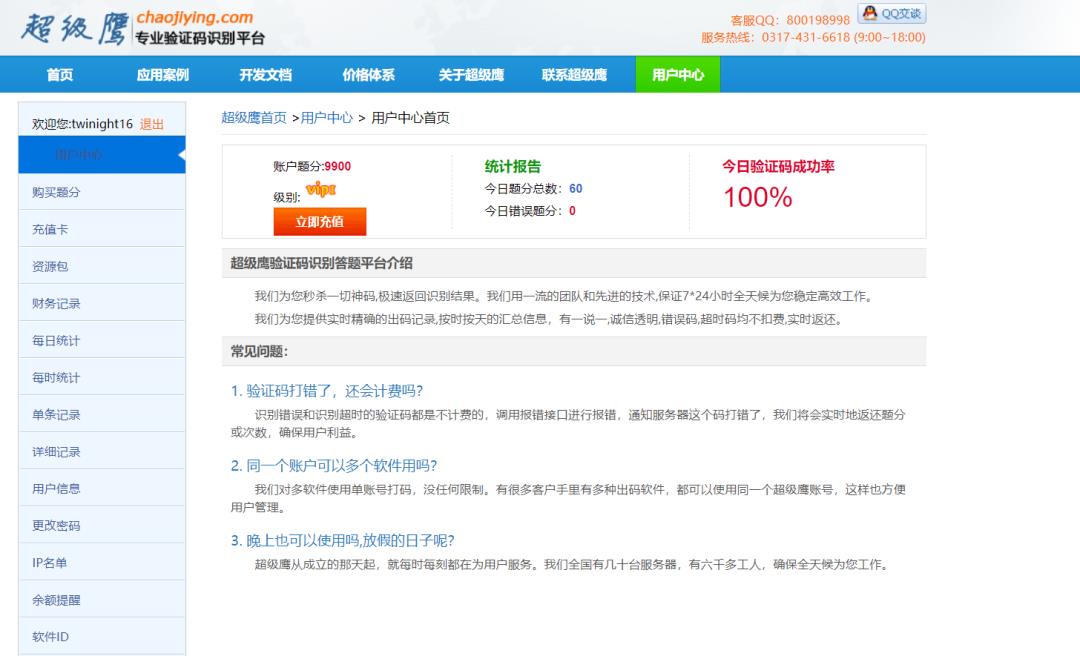
经过注册登陆后,我们先充个一块两块的获取一下点数。
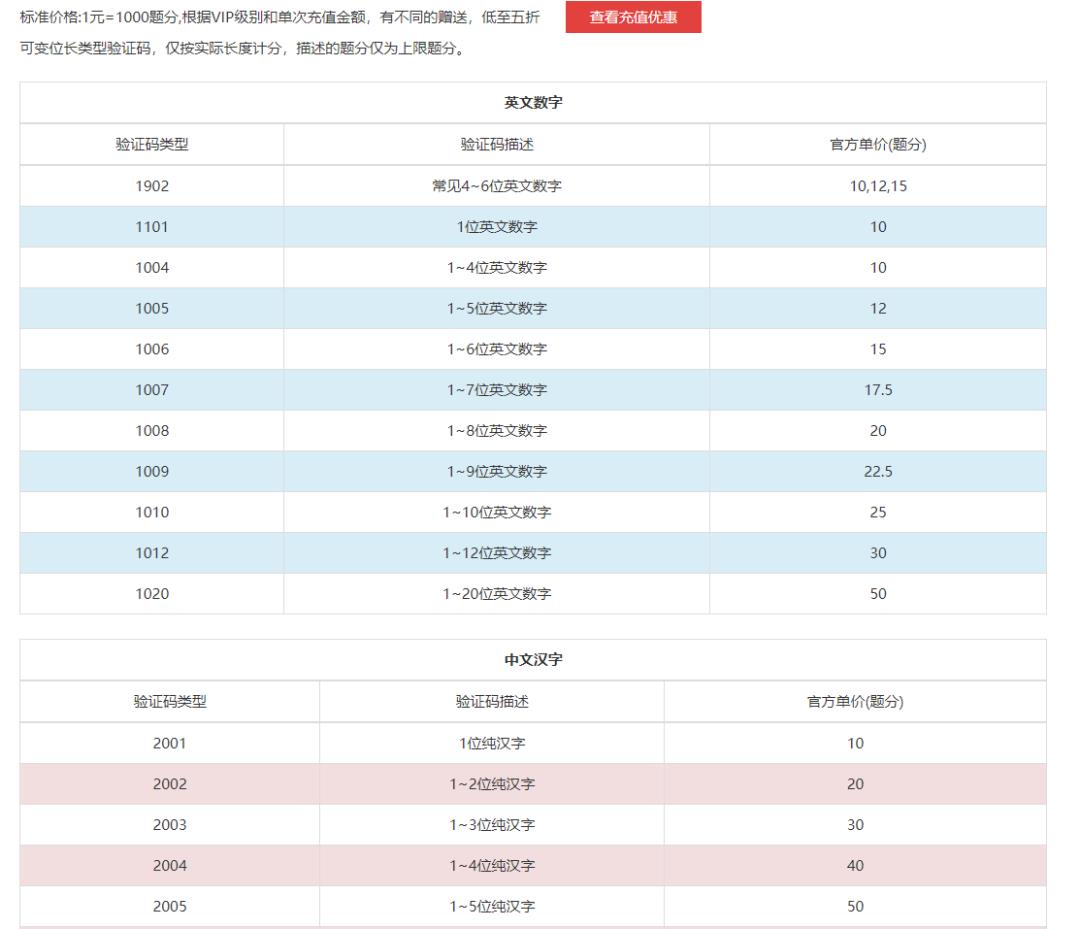
在价格体系中我们可以看到这个平台的可识别种类比较全。
记好了你要识别的种类的类型码。
同时在你的软件ID中新建一个软件获取号码。
进入开发文档,选择python并下载解压,放进你的项目文件夹里。
(当然其他语言操作大同小异)
准备工作完成。
第一步:建立与网站的连接,获取验证码
这里以古诗文网为例。
请出我们的requests库。
解析方式嘛。。。抓阄

用卫生纸抓阄的屑
好了就是你xpath.
code:

从网页中解析出验证码的标签并拼接出url.
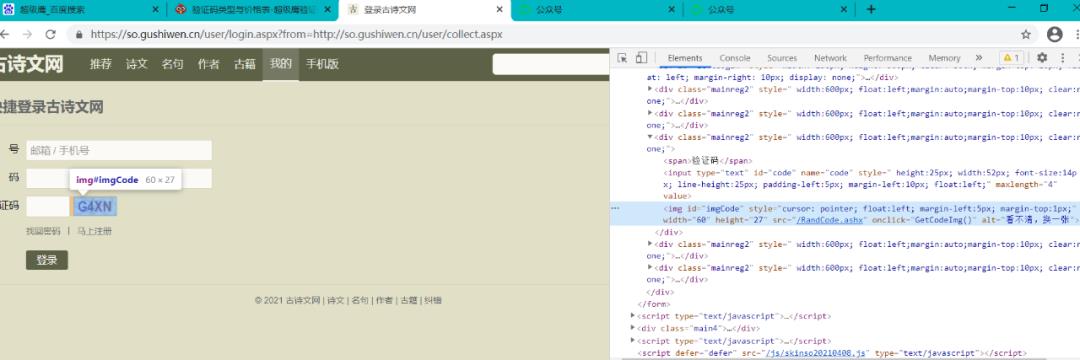
在这个地方嗷
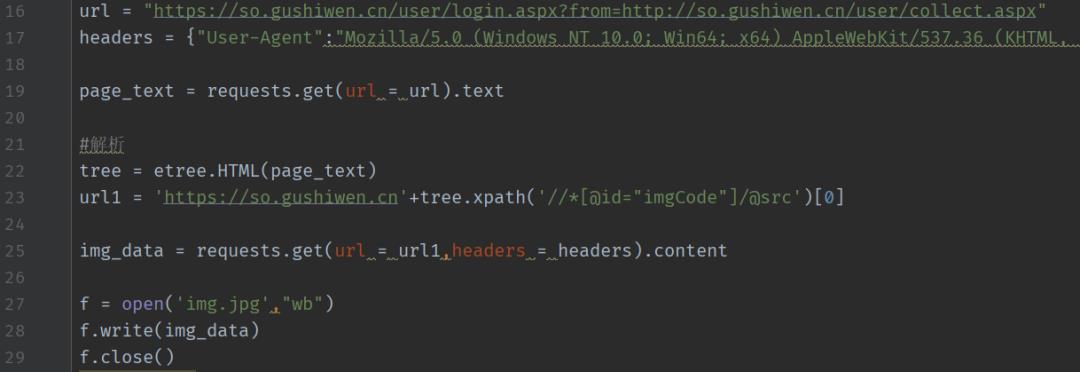
之后直接获取验证码图片并存储。
code:
第二步:对接平台
打开下载的发文档,填写参数。
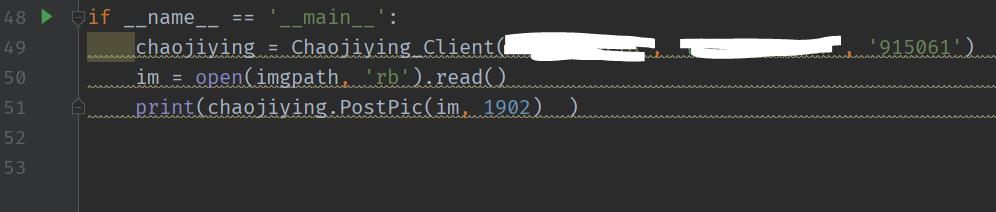
填写的有用户名,密码,软件ID
识别图像路径和文档类型肯定不能写死,先写上变量名
之后定义一个函数和一个空集。
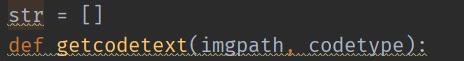
可以看到代码的上半部分是一个用于引用的类。
直接封装,引用就完事。
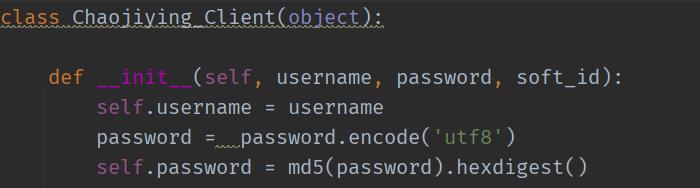

第三步:给变量赋值
古诗文网的验证码显然是最普通的形式
对应号码1902
把图片存储路径也写到函数里。


运行一下,可以看到,首先我们拿到了验证码。
之后网站自动识别出了正确结果。
你可能会说:还不如我自己去看。
可人力终归有时间空间限制。
如果你要多线程或定时爬取
你能保证自己全天候都能完成识别任务吗?
所以,自动化的魅力还是无穷的啊
而我只花了一包辣条钱。
以上是关于不想手动打验证码?基于python的验证码自动识别方案的主要内容,如果未能解决你的问题,请参考以下文章