Lucene还可以这样玩?SpringBoot集成Lucene实现自己的轻量级搜索引擎(附源码)
Posted 螺旋编程极客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene还可以这样玩?SpringBoot集成Lucene实现自己的轻量级搜索引擎(附源码)相关的知识,希望对你有一定的参考价值。

前言

哈喽,大家好,我是丸子。
搜索引擎想必大家都并不陌生,比如百度,谷歌都是常见的搜索引擎。
在我们实际的项目开发中,也经常遇到类似的业务需求,比如公司要开发一个知识库项目,知识库里有上百万条文章,要求我们能够输入关键字,查询出包含有关键字的文章内容,并且对关键字进行高亮处理,显示查询后的最佳摘要,这个时候传统的数据库LIKE查询虽然能勉强满足业务需求,但是查询速度令人无法忍受,这个时候就需要借助搜索引擎来进行处理。
在Java开发领域,Lucene可以算是开山鼻祖,现在常用的Solr和ElasticSearch底层都是基于Lucene,很多开发人员并没有系统的学习过Lucene,都是直接上手Solr或ElasticSearch进行开发,但实际上掌握Lucene的常用api,理解其底层原理还是比较重要的,这有利于我们对全文检索领域有更加深入的理解,同时我们也可以根据自己的业务需求定制个性化的搜索引擎,我所在的公司使用的就是基于Lucene自研的搜索引擎服务,针对公司独特的业务场景,使用起来特别方便。
本篇文章将详细讲解如何使用SpringBoot集成Lucene实现自己的轻量级搜索引擎,相关源码资料可以查看文末获取!
Lucene为什么查的快
Lucene之所以查的快,原因在于它内部使用了倒排索引算法,在这里简单的介绍一下原理:
普通查询是根据文章找关键字,而倒排索引是根据关键字找文章!
比如“我今天很开心,因为马上就要下班了”这句话,从中搜索“开心”,普通查询要遍历整句话,直到找到“开心”二字为止,效率低下。倒排索引则是对整句话使用分词器进行分词处理,从而“开心”二字可以直接指向这句话,搜索的时候直接就可以根据“开心”搜到所属的内容,达到快速响应的效果。
springBoot集成Lucene
下面我会以Demo的形式详细讲解springBoot如何集成Lucene实现增删查改,以及显示高亮和最佳摘要(demo全部资料和源码在文末获取)。
一.建表
以mysql为例,创建数据库lucene_demo,建表article,作为数据源,之后对表内容进行增删查改的时候同步到Lucene索引数据,建表语句如下:
CREATE TABLE `article` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',`title` varchar(200) DEFAULT NULL COMMENT '标题',`content` longtext COMMENT '内容',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
二.创建SpringBoot项目
在这里我直接拿自己的代码生成器生成,配置好基础内容点击生成,即可生成一个完整的前后台项目框架,省去了搭建项目的繁琐步骤,这样我们可以在生成的代码基础上进行开发:
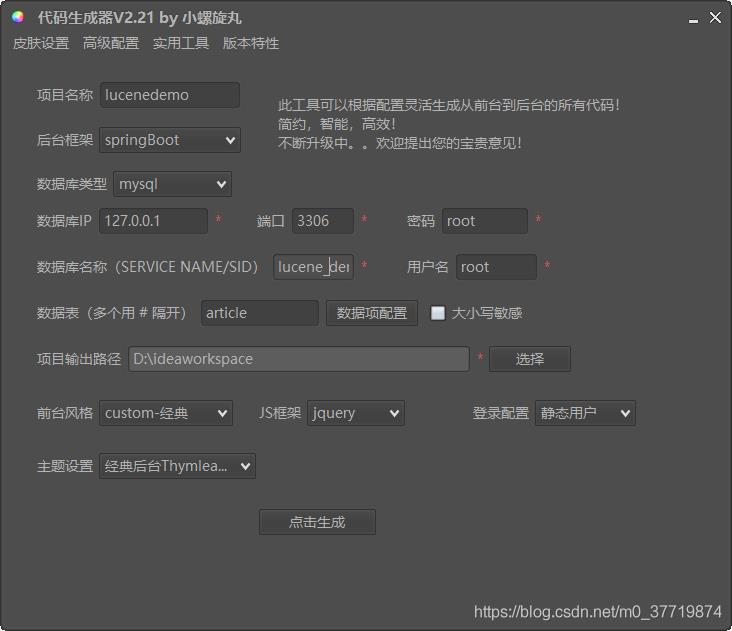
生成的项目结构和代码如下:
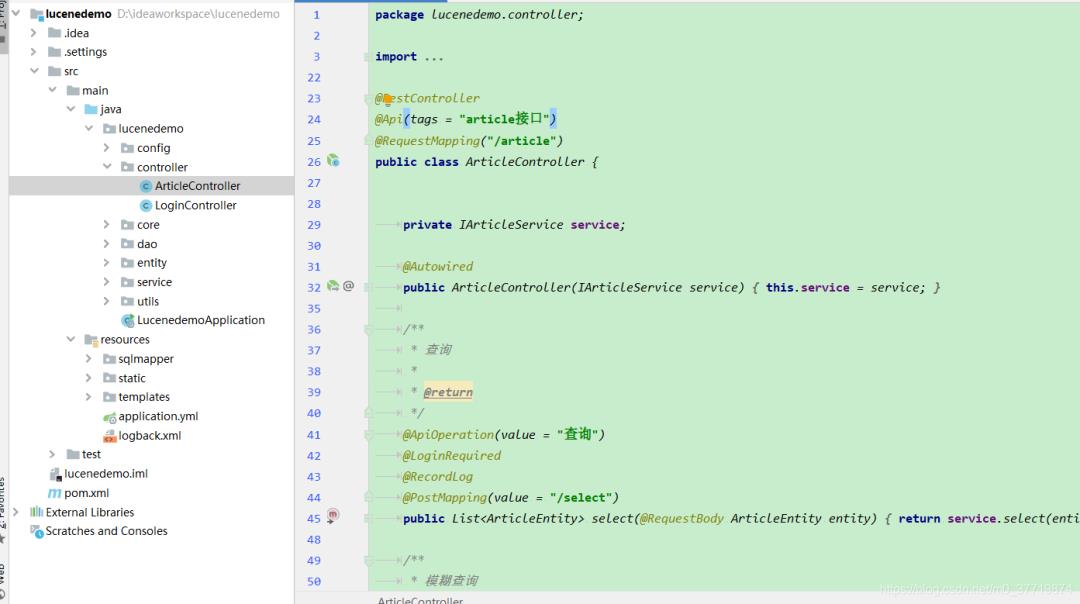
三.引入Lucene相关依赖
pom.xml引入Lucene相关依赖:
<dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>8.1.0</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId><version>8.1.0</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>8.1.0</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-highlighter</artifactId><version>8.1.0</version></dependency>
四.引入IK分词器依赖
目前市面上有不少中文分词器,但最受欢迎的还是IK分词器,Lucene自带的分词器对中文只能单字拆分,显然不符合我们的需求,但IK分词器解决了这个问题,他可以把一段话分成多组不同的中文单词,帮助建立搜索索引。
公共maven仓库中没有IK分词器的依赖,需要我们install一下,文末资料中有IK分词器的源码,可以导入idea直接install到自己的maven仓库,然后引入依赖到项目即可。
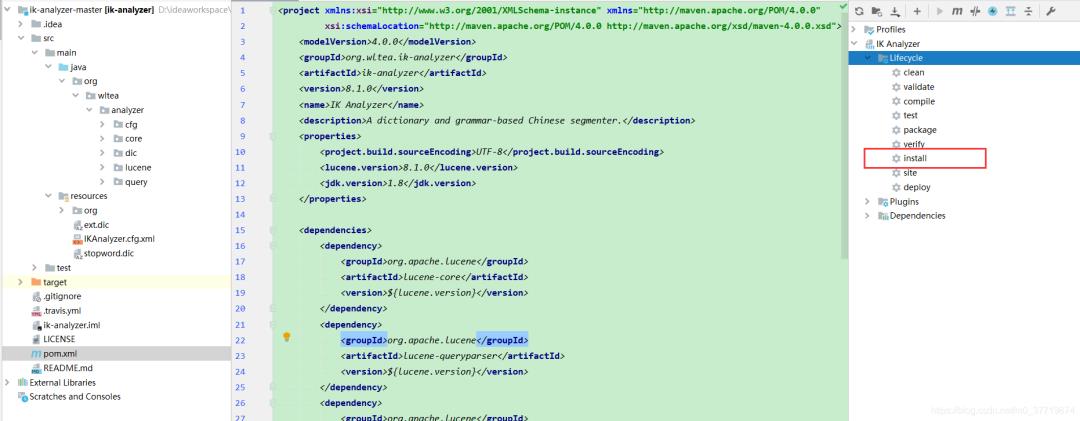
pom.xml引入Ik分词器相关依赖(因为之前已经引入了Lucene相关依赖,所以引入Ik的时候去除一下,防止依赖冲突):
<dependency><groupId>org.wltea.ik-analyzer</groupId><artifactId>ik-analyzer</artifactId><version>8.1.0</version><exclusions><exclusion><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId></exclusion><exclusion><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId></exclusion><exclusion><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId></exclusion><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId></exclusion></exclusions></dependency>
五.项目启动时加载IK分词器
最好在我们启动项目的时候就把IK分词器加载进内存当中,这样第一次查询就不必再进行加载,避免第一次查询因为加载分词器造成卡顿,创建init包,建立BusinessInitializer类,如下:
代码如下:
package lucenedemo.init;import org.springframework.boot.ApplicationArguments;import org.springframework.boot.ApplicationRunner;import org.springframework.stereotype.Component;import org.wltea.analyzer.cfg.DefaultConfig;import org.wltea.analyzer.dic.Dictionary;/*** 业务初始化器** @author zrx*/public class BusinessInitializer implements ApplicationRunner {public void run(ApplicationArguments args) {//加载ik分词器配置 防止第一次查询慢Dictionary.initial(DefaultConfig.getInstance());}}
引入IK的配置文件IKAnalyzer.cfg.xml以及扩展字典ext.dic和停止词字典stopword.dic,可以添加和屏蔽某些词语,把配置文件放入resources下:
在这里我们添加两个扩展词小螺旋丸和小千鸟,查询的时候可以用来做测试,如果测试的时候可以被完整标记高亮,说明词语被成功识别,因为IK自带的字典里,没有这两个单词,IK自带的字典位于IK源码的resources包下,感兴趣的朋友可以通过源码自行查看:
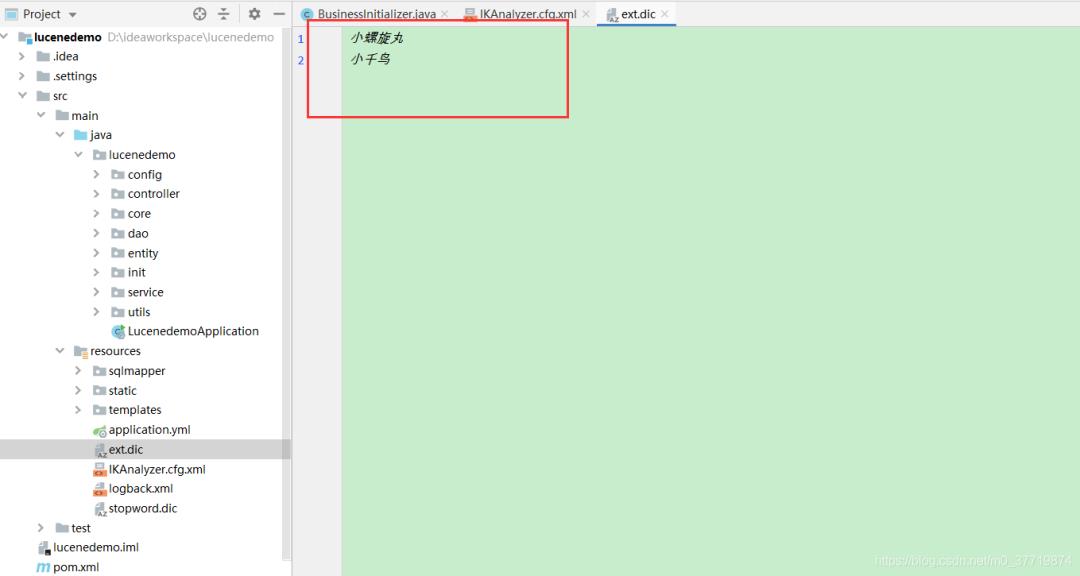
添加完毕,我们启动项目,发现词典被成功加载,如下:

接下来我们进行增删查改的开发。
六.增删查改业务开发:
1、配置索引库存放位置
首先我们需要配置索引的存放位置,可以把它理解为一个数据库,只不过这个数据库存放的是一些索引文件,我们在yml中指定位置,创建Config配置类,用@value注解获取它的值,方便随时在代码中获取,如下:
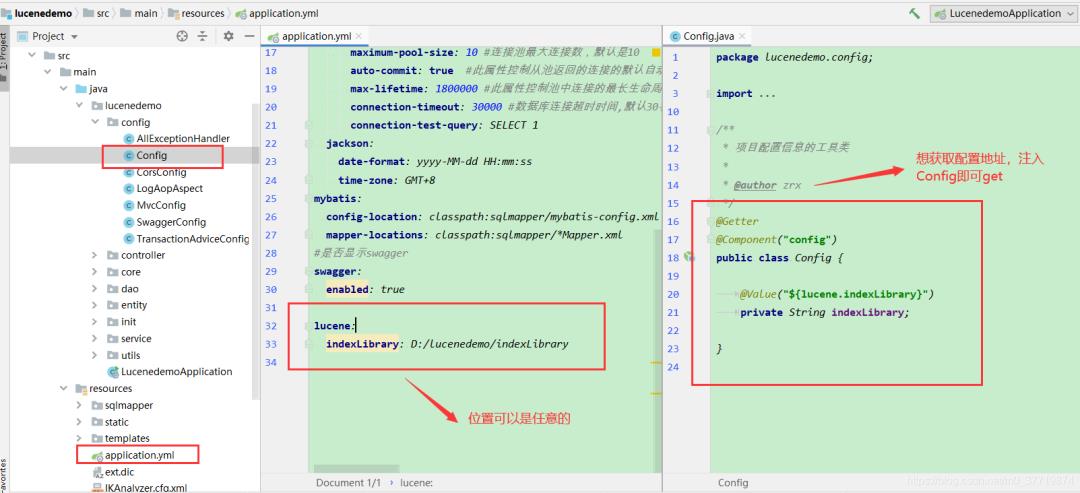
2、增删查改的时候同步索引:
数据库的增删查改方法代码生成器已经帮助我们生成完毕,只需要在原来的功能基础上添加对于索引库相关的代码逻辑即可!
首先是添加和更新操作,添加更新放在一起,根据主键id判断,如果索引中存在此id,则更新,否则添加,在service实现类中添加addOrUpIndex方法,同时每次添加和更新的时候都要调一下此方法,同步索引,代码基本每一行都有完整注释,如下:
/*** mapper文件里增加 useGeneratedKeys="true" keyProperty="id" keyColumn="id"属性,否则自增主键映射不上** @param entity*/@Overridepublic void add(ArticleEntity entity) {dao.add(entity);addOrUpIndex(entity);}@Overridepublic void update(ArticleEntity entity) {dao.update(entity);addOrUpIndex(entity);}/*** 添加或更新索引* @param entity*/private void addOrUpIndex(ArticleEntity entity) {IndexWriter indexWriter = null;IndexReader indexReader = null;Directory directory = null;Analyzer analyzer = null;try {//创建索引目录文件File indexFile = new File(config.getIndexLibrary());File[] files = indexFile.listFiles();// 1. 创建分词器,分析文档,对文档进行分词analyzer = new IKAnalyzer();// 2. 创建Directory对象,声明索引库的位置directory = FSDirectory.open(Paths.get(config.getIndexLibrary()));// 3. 创建IndexWriteConfig对象,写入索引需要的配置IndexWriterConfig writerConfig = new IndexWriterConfig(analyzer);// 4.创建IndexWriter写入对象indexWriter = new IndexWriter(directory, writerConfig);// 5.写入到索引库,通过IndexWriter添加文档对象documentDocument doc = new Document();//查询是否有该索引,没有添加,有则更新TopDocs topDocs = null;//判断索引目录文件是否存在文件,如果没有文件,则为首次添加,有文件,则查询id是否已经存在if (files != null && files.length != 0) {//创建查询对象QueryParser queryParser = new QueryParser("id", analyzer);Query query = queryParser.parse(String.valueOf(entity.getId()));indexReader = DirectoryReader.open(directory);IndexSearcher indexSearcher = new IndexSearcher(indexReader);//查询获取命中条目topDocs = indexSearcher.search(query, 1);}//StringField 不分词 直接建索引 存储doc.add(new StringField("id", String.valueOf(entity.getId()), Field.Store.YES));//TextField 分词 建索引 存储doc.add(new TextField("title", entity.getTitle(), Field.Store.YES));//TextField 分词 建索引 存储doc.add(new TextField("content", entity.getContent(), Field.Store.YES));//如果没有查询结果,添加if (topDocs != null && topDocs.totalHits.value == 0) {indexWriter.addDocument(doc);//否则,更新} else {indexWriter.updateDocument(new Term("id", String.valueOf(entity.getId())), doc);}} catch (Exception e) {e.printStackTrace();throw new RuntimeException("添加索引库出错:" + e.getMessage());} finally {if (indexWriter != null) {try {indexWriter.close();} catch (IOException e) {e.printStackTrace();}}if (indexReader != null) {try {indexReader.close();} catch (IOException e) {e.printStackTrace();}}if (directory != null) {try {directory.close();} catch (IOException e) {e.printStackTrace();}}if (analyzer != null) {analyzer.close();}}}
代码应该很容易就可以看明白,这里我们把实体的title和content进行分词,并存储为索引文件,所以接下来查询的时候也要根据这两个字段来进行查询,查询的时候我们要对查询结果进行分页,Lucene的分页方式比较特别,他没有类似数据库那种提供开始和结束下标定位元素的方法,而是只能指定查询的总条目数,然后把所有的命中结果查询出来,比如一共有100条数据,查询第一页返回10条,查询第十页则会返回100条,需要我们在逻辑上对查询结果进行分页,取我们想要的数据,也可以利用Luncene提供的SearchAfter方法进行查询,它可以根据指定的最后一个元素查询接下来指定数目的元素,但这需要我们查询出前n个元素然后取最后一个元素传给SearchAfter方法,两种方法效率上并没有太大区别,毕竟Lucene本身就很快。但这也涉及到一个问题,如果查询的数据量过多,比如上千万条可能会导致内存溢出,这就需要我们根据业务做一个取舍,用户在查询的时候通常只会看前几页的数据,所以我们可以指定一下最大的查询数量,比如10000条,无论实际符合条件的结果有多少,我们最多只查询前10000条,这样问题便得到解决,其实很多搜索引擎也是这样做的!
如果你说我就要看全部的数据,那就涉及到了数据的分布式存储,在分页的时候就需要每台服务器进行查询然后汇总查询结果,这里的问题就比较复杂了,在此处不做深究,以后可以专门聊一聊,其实业界已经有了几种比较成熟的解决方案,可以较好的解决分布式存储的分页问题。
这里代码中并没有指定查询的最大数量,毕竟是个demo,没必要弄的这么复杂,代码如下:
@Overridepublic PageData<ArticleEntity> fullTextSearch(String keyWord, Integer page, Integer limit) {List<ArticleEntity> searchList = new ArrayList<>(10);PageData<ArticleEntity> pageData = new PageData<>();File indexFile = new File(config.getIndexLibrary());File[] files = indexFile.listFiles();//沒有索引文件,不然沒有查詢結果if (files == null || files.length == 0) {pageData.setCount(0);pageData.setTotalPage(0);pageData.setCurrentPage(page);pageData.setResult(new ArrayList<>());return pageData;}IndexReader indexReader = null;Directory directory = null;try (Analyzer analyzer = new IKAnalyzer()) {directory = FSDirectory.open(Paths.get(config.getIndexLibrary()));//多项查询条件QueryParser queryParser = new MultiFieldQueryParser(new String[]{"title", "content"}, analyzer);//单项//QueryParser queryParser = new QueryParser("title", analyzer);Query query = queryParser.parse(!StringUtils.isEmpty(keyWord) ? keyWord : "*:*");indexReader = DirectoryReader.open(directory);//索引查询对象IndexSearcher indexSearcher = new IndexSearcher(indexReader);TopDocs topDocs = indexSearcher.search(query, 1);//获取条数int total = (int) topDocs.totalHits.value;pageData.setCount(total);int realPage = total % limit == 0 ? total / limit : total / limit + 1;pageData.setTotalPage(realPage);//获取结果集ScoreDoc lastSd = null;if (page > 1) {int num = limit * (page - 1);TopDocs tds = indexSearcher.search(query, num);lastSd = tds.scoreDocs[num - 1];}//通过最后一个元素去搜索下一页的元素 如果lastSd为null,查询第一页TopDocs tds = indexSearcher.searchAfter(lastSd, query, limit);QueryScorer queryScorer = new QueryScorer(query);//最佳摘要SimpleSpanFragmenter fragmenter = new SimpleSpanFragmenter(queryScorer, 200);//高亮前后标签SimplehtmlFormatter formatter = new SimpleHTMLFormatter("<b><font color='red'>", "</font></b>");//高亮对象Highlighter highlighter = new Highlighter(formatter, queryScorer);//设置高亮最佳摘要highlighter.setTextFragmenter(fragmenter);//遍历查询结果 把标题和内容替换为带高亮的最佳摘要for (ScoreDoc sd : tds.scoreDocs) {Document doc = indexSearcher.doc(sd.doc);ArticleEntity articleEntity = new ArticleEntity();Integer id = Integer.parseInt(doc.get("id"));//获取标题的最佳摘要String titleBestFragment = highlighter.getBestFragment(analyzer, "title", doc.get("title"));//获取文章内容的最佳摘要String contentBestFragment = highlighter.getBestFragment(analyzer, "content", doc.get("content"));articleEntity.setId(id);articleEntity.setTitle(titleBestFragment);articleEntity.setContent(contentBestFragment);searchList.add(articleEntity);}pageData.setCurrentPage(page);pageData.setResult(searchList);return pageData;} catch (Exception e) {e.printStackTrace();throw new RuntimeException("全文檢索出错:" + e.getMessage());} finally {if (indexReader != null) {try {indexReader.close();} catch (IOException e) {e.printStackTrace();}}if (directory != null) {try {directory.close();} catch (IOException e) {e.printStackTrace();}}}}
最后是删除索引,根据唯一标识id删除即可,代码如下:
@Overridepublic void delete(ArticleEntity entity) {dao.delete(entity);//同步删除索引deleteIndex(entity);}private void deleteIndex(ArticleEntity entity) {//删除全文检索IndexWriter indexWriter = null;Directory directory = null;try (Analyzer analyzer = new IKAnalyzer()) {directory = FSDirectory.open(Paths.get(config.getIndexLibrary()));IndexWriterConfig writerConfig = new IndexWriterConfig(analyzer);indexWriter = new IndexWriter(directory, writerConfig);//根据id字段进行删除indexWriter.deleteDocuments(new Term("id", String.valueOf(entity.getId())));} catch (Exception e) {e.printStackTrace();throw new RuntimeException("删除索引库出错:" + e.getMessage());} finally {if (indexWriter != null) {try {indexWriter.close();} catch (IOException e) {e.printStackTrace();}}if (directory != null) {try {directory.close();} catch (IOException e) {e.printStackTrace();}}}}
至此,Lucene的后台增删查改功能开发完毕!
3、利用swagger测试
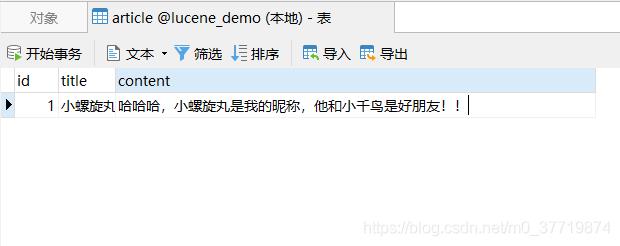
接下来我们利用swagger对功能进行测试,测试之前我们把controller层增删查改方法的 @LoginRequired 注解去掉(@LoginRequired是代码生成器最新版添加的注解,可以控制方法必须登录才可以调用),这样可以不必登录,打开swagger,添加一条数据,如下:
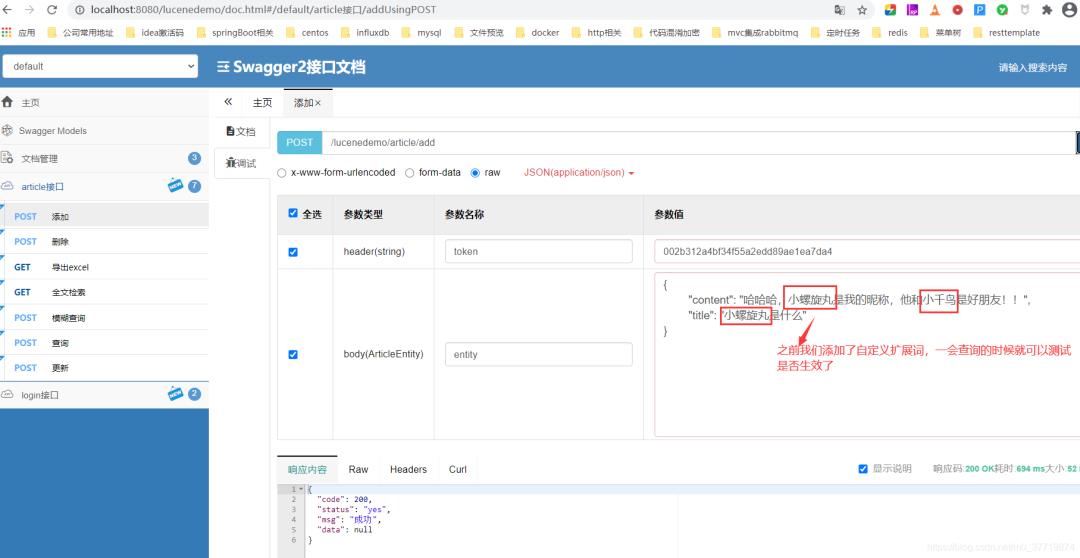
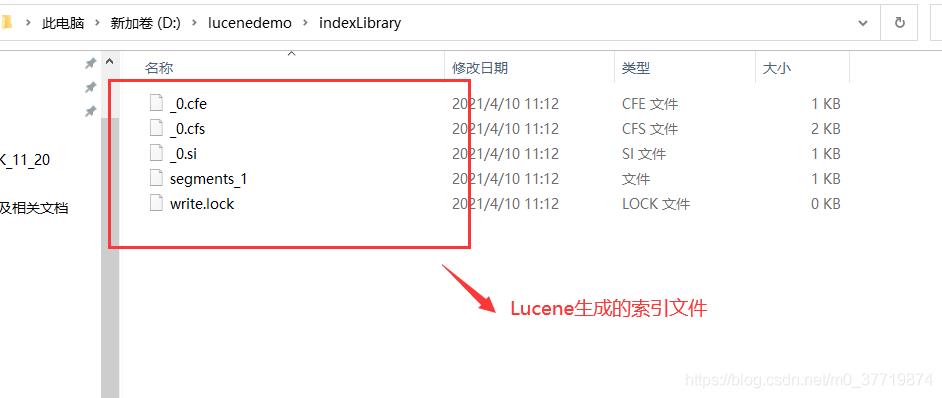
如上,数据添加成功,数据库数据添加成功,Lucene索引文件夹也生成了相关索引文件,如下:
接下里我们测一下全文检索功能,如下:
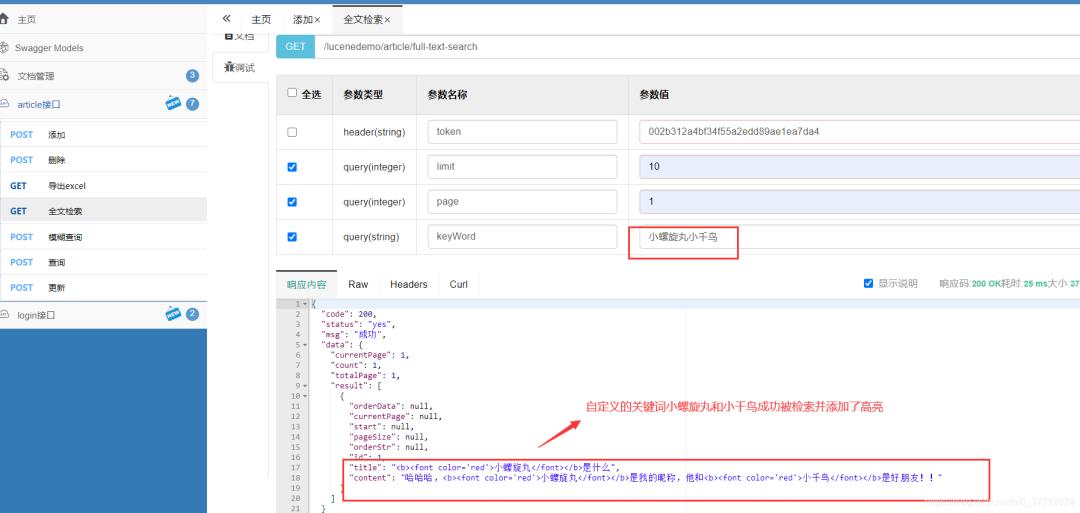
删除功能也可正常使用并同步删除索引,此处就不截图了。这样一来,后台api测试完毕,符合预期效果,记下来进入前台实现阶段。
4、前台实现
前台实现没有什么好说的,就是跟后端对接口进行交互,前端真是我的硬伤,我根据代码生成器生成的列表页做了调整,最终实现效果如下: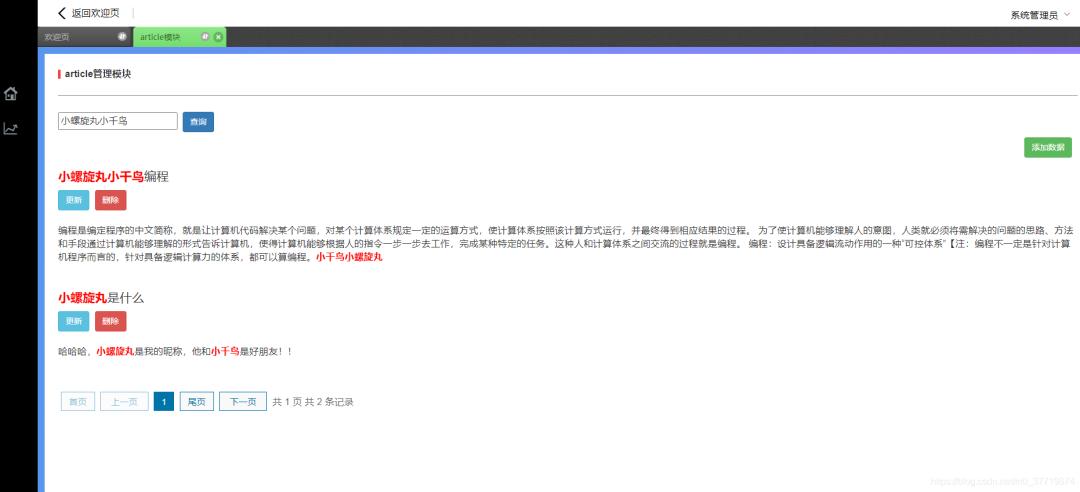
前台代码就不贴了,没有太大意义,毕竟有了后台的数据返回,前台有n多种展示方式,大家根据自己的习惯去对接口就好了,完整的前后台代码以及sql文件等可于文末获取。
结语
本篇文章我们利用Lucene自己实现了一个非常轻量的搜索引擎,其实我们可以利用反射把它做成一个通用的查询框架,这样无论实体的属性名称怎么变,都可以灵活应对。
全文检索在Java开发领域是一个重要的知识点,需要我们深入理解和掌握,希望通过本篇文章可以让你对Lucene有一个更加全面的认识,代码生成器不出意外本月会更新一版,我们下次更新,再见啦!
以上是关于Lucene还可以这样玩?SpringBoot集成Lucene实现自己的轻量级搜索引擎(附源码)的主要内容,如果未能解决你的问题,请参考以下文章