云原生学习之一:微服务
Posted 软硬件融合
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生学习之一:微服务相关的知识,希望对你有一定的参考价值。
背景:
虚拟化技术是云计算最核心的部分,传统的虚拟化包括计算机虚拟化,也包括虚拟网络和分布式存储等。
基于操作系统虚拟化的容器技术Docker和容器编排工具Kubernetes的兴起,使得云原生(Cloud Native)成为越来越流行的一个概念。相比传统虚拟化,云原生的落地场景越来越大,所占份额也越来越大。
本期是第一篇,我们来一起学习“微服务”。
1 什么是微服务?
AWS给出的定义是:微服务是一种开发软件的架构和组织方法,其中软件由通过明确定义的 API 进行通信的小型独立服务组成。这些服务由各个小型独立团队负责。微服务架构使应用程序更易于扩展和更快地开发,从而加速创新并缩短新功能的上市时间。
整体式架构与微服务架构
通过整体式架构,所有进程紧密耦合,并可作为单项服务运行。这意味着,如果应用程序的一个进程遇到需求峰值,则必须扩展整个架构。随着代码库的增长,添加或改进整体式应用程序的功能变得更加复杂。这种复杂性限制了试验的可行性,并使实施新概念变得困难。整体式架构增加了应用程序可用性的风险,因为许多依赖且紧密耦合的进程会扩大单个进程故障的影响。
使用微服务架构,将应用程序构建为独立的组件,并将每个应用程序进程作为一项服务运行。这些服务使用轻量级 API 通过明确定义的接口进行通信。这些服务是围绕业务功能构建的,每项服务执行一项功能。由于它们是独立运行的,因此可以针对各项服务进行更新、部署和扩展,以满足对应用程序特定功能的需求。
图1 将整体式应用程序拆分为微服务
参考链接:https://aws.amazon.com/cn/microservices/
2 微服务的特点
基于服务的组件
什么是组件?我们的定义是,一个组件就是一个可以独立更换和升级的软件单元。服务(services)是进程外的组件,它们通过诸如web service请求或远程过程调用这样的机制来进行通信。
以使用服务(而不是软件库)的方式来实现组件化的一个主要原因是,服务可以被独立部署。一个良好的微服务架构的目的,是通过内聚的服务边界和服务协议方面的演进机制,使得这样的修改最小化。
以服务的方式来实现组件化的另一个结果,是能获得更加显式的组件接口。传统编程语言并没有一个良好的机制来定义显式的发布接口,从而导致组件间出现过度紧密的耦合。通过使用显式的远程调用机制,服务可以更容易做到解耦。
我们可以把每个服务映射为一个独立运行的进程;也可以把总是一起被开发和部署的多个进程打包成一个服务,比如一个应用系统的进程和仅被该服务使用的数据库。
团队组织
管理分解通常是基于技术类型,我们组建了用户界面团队、服务器端团队和数据库团队。要实现一个简单的变更,都需要跨团队的合作。
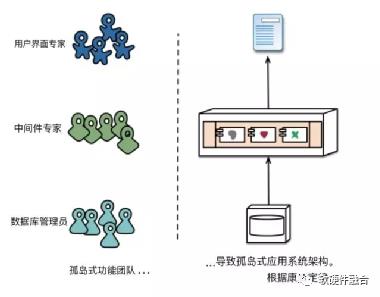
图2 基于技术类型的团队组织和产品结构
微服务使用不同的方法来分解系统,即根据业务功能(business capability)来将系统分解为若干服务。这些服务针对该业务领域提供广泛堆栈的软件实现,包括用户界面、持久性存储以及任何对外的协作性操作。因此,团队是跨职能的,它拥有软件开发所需的全方位的技能:用户体验、数据库和项目管理。
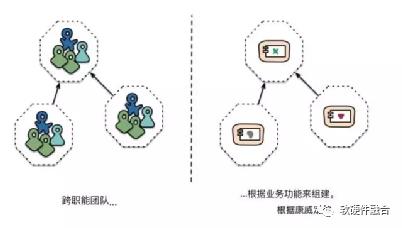
图3 被团队边界所强化的服务边界
以上述方式来组织团队,跨职能团队负责构建和运维每个产品,而每个产品被拆分为多个独立的服务,彼此通过一个消息总线来通信。
做产品而不是做项目
大部分应用系统的开发工作都使用项目模型:目标是交付某一个软件,之后就认为完工了。之后软件就被移交给维护团队,接着那个构建该软件的项目团队就会被解散。
微服务的理念是不采用上述模型,而采纳“一个团队在一个产品的整个生命周期中都应该保持对其拥有”这样的理念。通常认为这一点源自亚马逊的“谁构建,谁运行”的理念,即一个开发团队对一个在生产环境下运行的软件负全责。这会使开发人员每天都会关注软件是如何在生产环境下运行的,并且增进他们与用户的联系,因为他们必须承担某些技术支持工作。
功能强大的节点和功能简单的连接管道
微服务主张:智能端点(Smart Endpoints)和傻瓜管道(Dumb Pipes)。使用微服务所构建的各种应用的目标,都是尽可能地实现“高内聚和低耦合”,即接收一个请求,匹配合适的应用逻辑,并产生一个响应。这些应用通过使用简单的REST风格的协议进行编制,而不去使用复杂的协议,如"WS-编制"(WS-Choreography)、BPEL或通过位于中心的工具来进行编排。
微服务最常用的两种协议是:带有资源API的HTTP“请求-响应”协议,和轻量级的消息发送协议。
去中心化的组织
使用中心化的方式来对开发进行治理,其中一个后果,就是趋向于在单一技术平台上制定标准。经验表明,这种做法会带来局限性——不是每一个问题都是钉子,也不是每一个解决方案都得是用锤子。
如果能将单块应用的组件拆分成多个服务,那么在构建每个服务时,就可以有选择不同技术栈的机会。想要使用Node.js来搞出一个简单的报表页面?没问题。想用C++来做一个性能特棒的近乎实时的组件?没问题。想要换一种风格的数据库,来更好地适应某个组件的读取数据行为?没问题,可以重建。
Netflix公司是遵循上述理念的好例子。将实用且经过实战检验的代码以软件库的形式共享出来,鼓励其他开发人员以相似的方式来解决相似的问题,当然也为,在需要的时候选用不同的方案提供了可能。共享软件库往往集中在解决常见的问题,如数据存储、进程间通信和基础设施自动化。
或许去中心化地治理技术的极盛时期,就是亚马逊的“谁构建,谁运行”的风气开始普及的时候。各个团队负责其所构建的软件的所有方面的工作,其中包括7 x 24地对软件进行运维。将运维这一级别的职责下放到团队这种做法,目前绝对不是主流。但是我们确实看到越来越多的公司,将运维的职责交给开发团队。
去中心化的数据管理
去中心化的管理数据,其表现形式多种多样。从最抽象的层面看,这意味着各个系统对客观世界所构建的概念模型,将彼此各不相同。当在一个大型的企业中进行系统集成时,这是一个常见的问题。比如:
对于“客户”这个概念,从销售人员的视角看,就与从支持人员的视角看有所不同。从销售人员的视角所看到的一些被称之为“客户”的事物,或许在支持人员的视角中根本找不到。
而那些在两个视角中都能看到的事物,或许各自具有不同的属性。
更糟糕的是,那些在两个视角中的同一个属性名称,或许在语义上仍有微妙的不同。
解决这类问题的一个有效方法,就是使用领域驱动设计(Domain-Driven Design, DDD)中的“有界限的上下文”(Bounded Context)的概念。DDD将一个复杂的领域划分为多个有界限上下文,并且将其相互之间的关系用图画出来。
如同在概念模型上进行去中心化的决策一样,微服务也在数据存储上进行去中心化的决策。微服务更喜欢让每一个服务来管理其自有数据库。其实现可以采用相同数据库技术的不同数据库实例,也可以采用完全不同的数据库系统。
图4 单系统的单数据库和多系统的多数据库
在各个微服务之间将数据“去中心化”的管理,会影响软件更新的管理。处理软件更新的常用方法,当更新多个资源的时候,使用事务来保证一致性。
集中式的使用事务,有助于保持数据一致性。但是在时域上会导致明显的耦合。这样,当在多个服务之间处理事务时会出现一致性问题。分布式事务实现起来难度非常大。为此,微服务架构更强调在各个服务之间进行“无事务”的协调。这源自微服务社区明确地认识到下述两点,即数据一致性可能只要求数据在最终达到一致,并且一致性问题能够通过补偿操作来进行处理。
参考链接:https://martinfowler.com/articles/microservices.html
简单的总结
我们通常的互联网系统,随着用户访问量的提升:
我们从单块应用中,分离出了前端页面,数据库部署到独立的服务器;
再后来,通过负载均衡,把应用再平行扩展;
再后来,我们把实际的应用程序继续分解到微服务。
每个访问都是通过微服务,微服务内部实现自己的内部逻辑和高可用,给外部提供特定的Service API。应用从单块到微服务,就是系统逐渐解构的过程。
欢迎加入软硬件融合技术交流群,
相互学习,共同进步。
以上是关于云原生学习之一:微服务的主要内容,如果未能解决你的问题,请参考以下文章
Spring Cloud与微服务学习总结(13)——云原生趋势下,微服务的拆分粒度如何把握?