数据库基础篇—— SQL之数据查询
Posted Python之每日一课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库基础篇—— SQL之数据查询相关的知识,希望对你有一定的参考价值。
目录
-
前言 -
数据准备
-
一、DQL语言的学习 基础查询
条件查询
排序查询
分组查询
常见函数
连接查询
子查询
分页查询
union联合查询
前言
数据准备
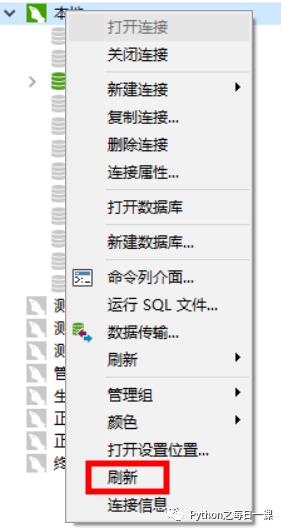
1、 选中本地数据库—>点击运行SQL文件
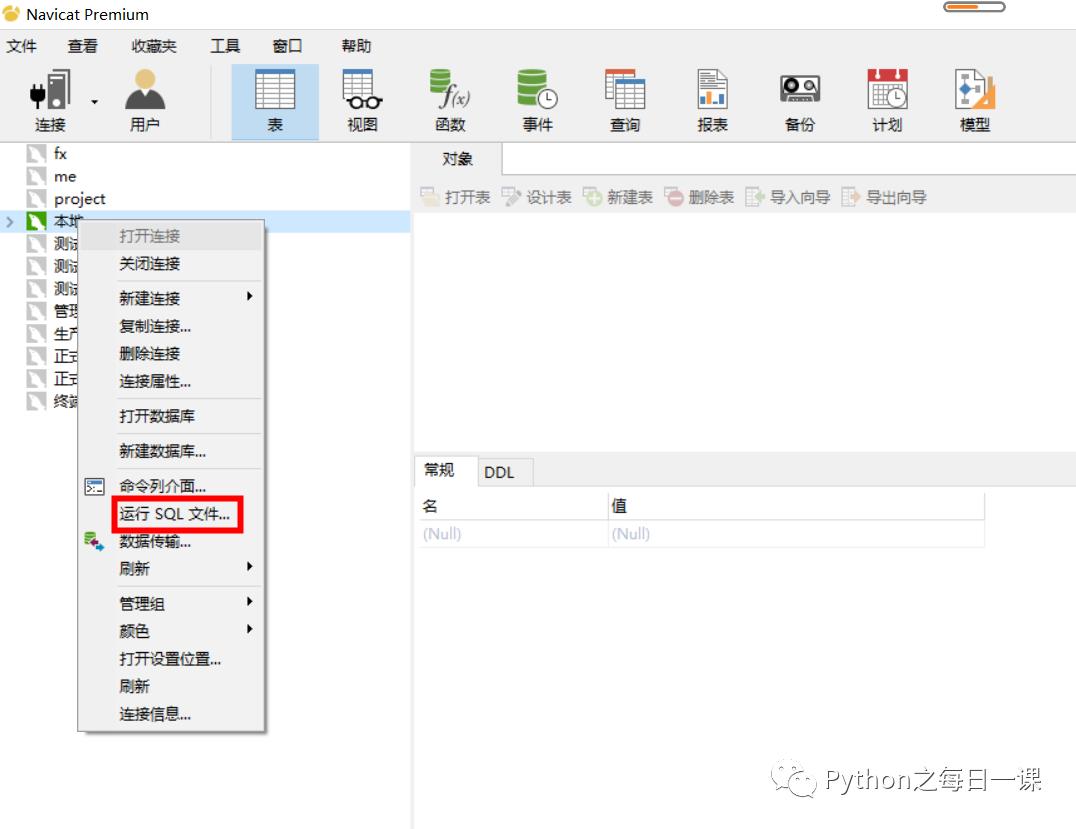
2、 选中三个点—>选择要执行的SQL脚本—>打开
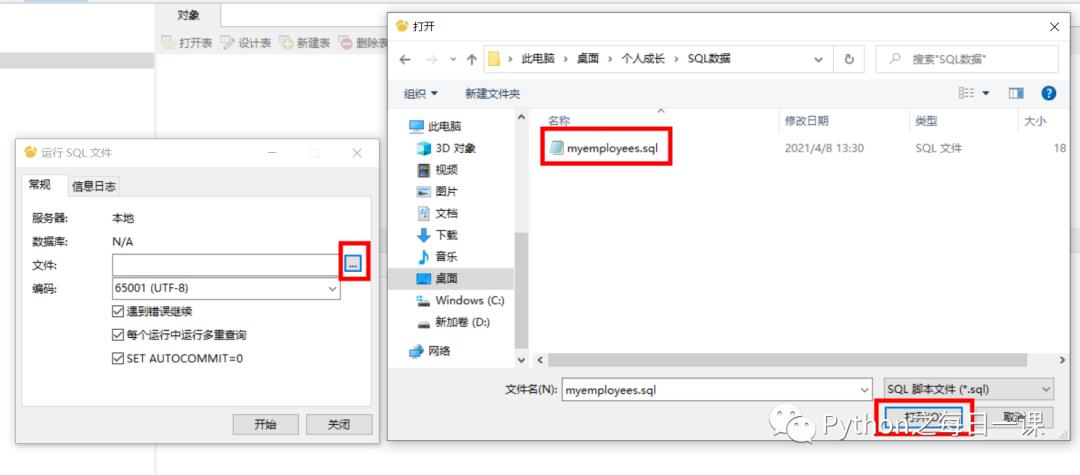
3、 点击开始—>数据导入成功—>关闭
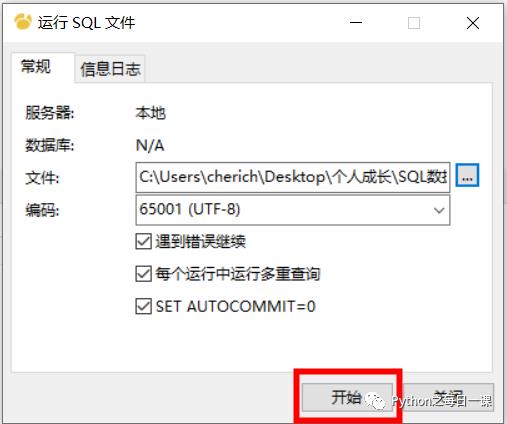
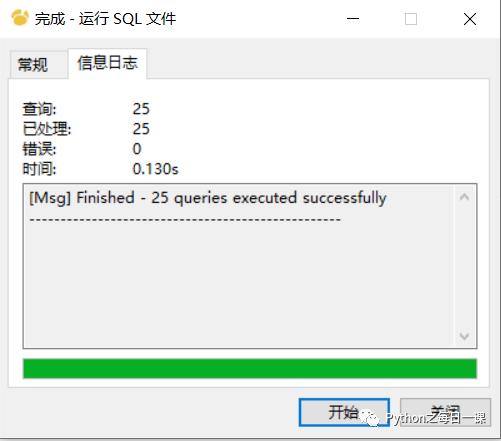
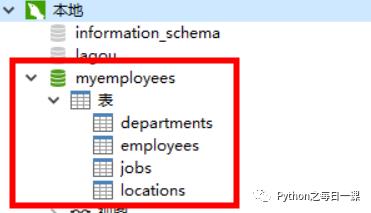
4、选中库—>右键刷新—>完成!
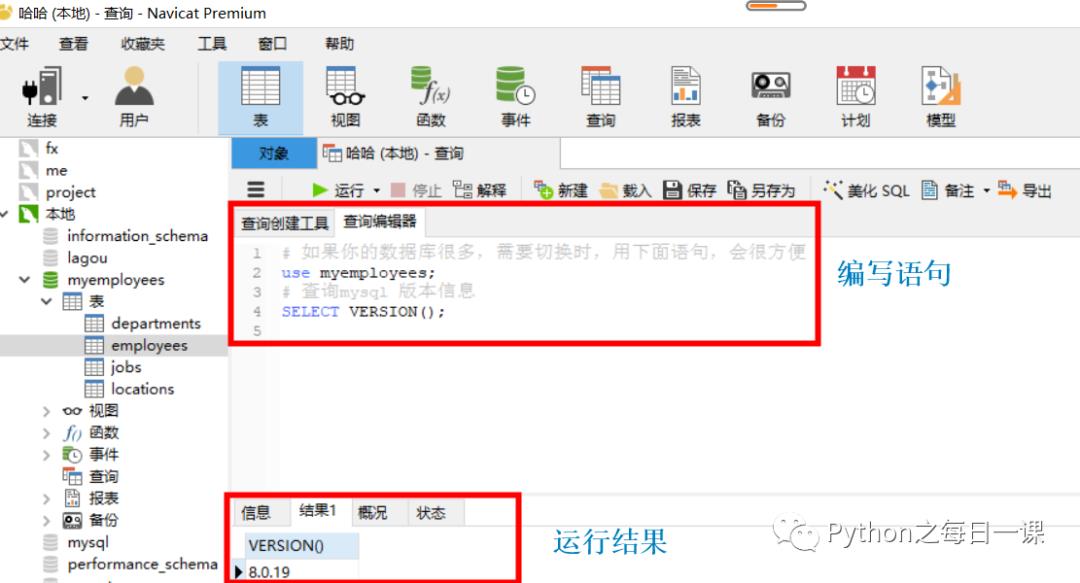
DQL语言的学习
1、 基础查询
1)语法
select 要查询的东西 【from 表名】
2)特点
类似于Python中 :print(要打印的东西)
①通过select查询完的结果 ,是一个虚拟的表格,不是真实存在
② 要查询的东西 可以是常量值、表达式、字段、也可以是函数
3)举栗
# 查询常量SELECT 100;# 查询表达式SELECT 100 * 2# 查询单个字段SELECT last_name FROM employees;# 查询多个字段SELECT last_name,email FROM employees;# 查询所有字段SELECT * FROM employees;# 查询表的记录总数(函数)SELECT COUNT(*) FROM employees;# 查询员工表中的部门编号并去重(字段前加关键字)SELECT DISTINCT department_id FROM employees;
补充:可以给字段起别名,好处是提高可读性,更方便理解;多表连接时,区分字段。用AS 或 空格来实现。如下:
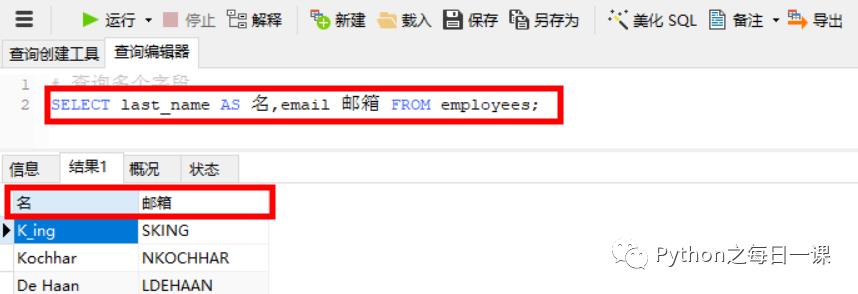
2、 条件查询
条件查询:根据条件过滤原始表的数据,查询到想要的数据
1)语法
select 要查询的字段|表达式|常量值|函数
from 表
where 条件;2)分类
①条件表达式
示例:salary>10000条件运算符:> < >= <= = != <>
②逻辑表达式
示例:salary>10000 && salary<20000逻辑运算符:and(&&):两个条件如果同时成立,结果为true,否则为falseor(||):两个条件只要有一个成立,结果为true,否则为falsenot(!):如果条件成立,则not后为false,否则为true
③模糊查询
# 常用关键字likebetween andin|existsis|is not null
3)举栗
# 查询工资大于12000的员工信息SELECT * FROM employees where salary >12000;# 查询工资大于10000同时小于2000的员工信息SELECT * FROM employees WHERE salary>10000 AND salary<20000;# 查询员工名中以字符a开头的员工信息# %代表任意多个字符,如果需求为包含a的员工信息 就写为 %a%SELECT * FROM employees WHERE last_name LIKE 'a%';# 查询员工编号在100到120之间的员工信息(between and)# 写法一 逻辑表达式 andSELECT*FROMemployeesWHEREemployee_id >= 100AND employee_id <= 120;# 写法二 between and# 特点:1、简洁 2、包含临界值SELECT*FROMemployeesWHEREemployee_id BETWEEN 100AND 120;
⭐ 注意:where 一定要放到 from 后面。NULL 不是假,也不是真,而是"空";任何运算符,判断符碰到NULL,都得NULL;NULL的判断只能用is null,is not null;NULL 影响查询速度,一般避免使值为NULL。exists查询可以与in型子查询互换,它们之间区别以后语句优化时会详细讲解。
3、 排序查询
1)语法
select
要查询的东西
from
表名
where
条件
order by 排序的字段|表达式|函数|别名 【asc|desc】2)举栗
# 查询员工信息,要求工资从高到低排序SELECT*FROMemployeesORDER BY salary DESC;
⭐ 注意:order by 一定要放到 语句最后(limit前面)
4、分组查询
1)语法
select 分组函数(字段),字段[要求出现在group by后面的字段]
from 表名
group by 分组的字段2)特点
①可以按单个字段分组
②和分组函数一同查询的字段最好是分组后的字段
③分组筛选(where 和 having区别)
|
|
|
|
|
| where | 原始表 | group by前面 | 分组前筛选 |
| having | 分组后结果集 | group by后面 | 分组后筛选 |
④可以按多个字段分组,字段之间用逗号隔开
⑤可以支持排序
⑥having后可以支持别名
3)举栗
# 简单分组:查询每个部门的平均薪资SELECTAVG(salary),department_idFROMemployeesGROUP BYdepartment_id;# 添加筛选条件:查询2000(包含2000)年以前入职的各部门平均工资SELECTdepartment_id,AVG(salary)FROMemployeesWHERE hiredate <= '2000-01-01'GROUP BYdepartment_id;# 添加复杂筛选条件:查询哪个部门的员工个数大于5,并按降序排列,取前两个# 思路1、先按部门分组,查询每个部门的员工个数 2、根据1、的结果进行筛选SELECTdepartment_id,COUNT(*) as numFROMemployeesGROUP BYdepartment_idHAVING num >=5ORDER BY num DESCLIMIT 2;
⭐ 注意:关键字顺序是where —>group by—>having—>order by—>limit
(having不能单独使用,需结合group by ,表示对分组后的结果进行筛选;
而group by 必须结合分组聚合函数一起使用,比如:count()、max()等)
5、 常见函数
1)单行函数
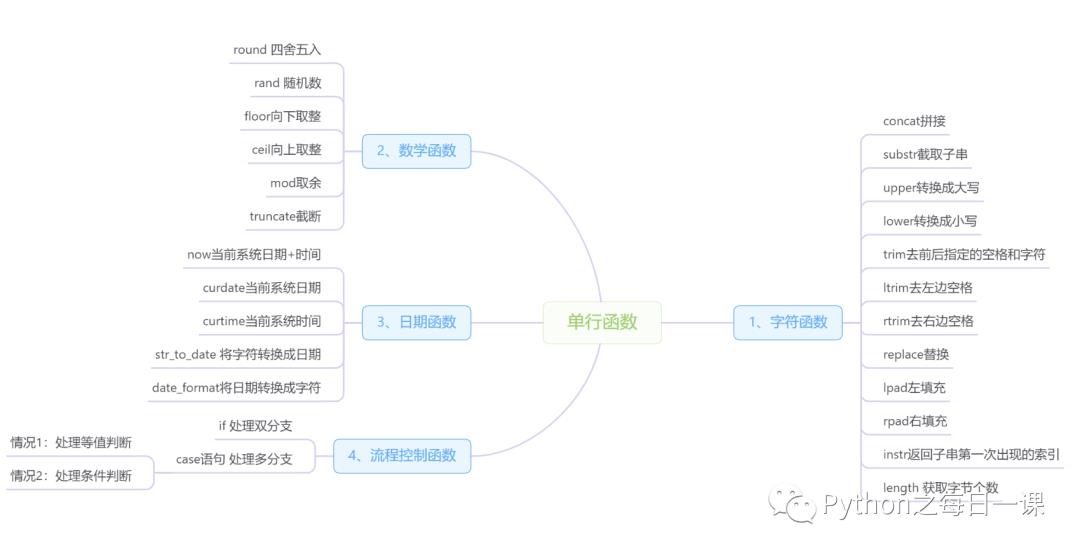
2)分组函数
sum() 求和max() 最大值min() 最小值avg() 平均值count() 计数
3)分组函数特点
①以上五个分组函数都忽略null值,除了count(*)
②sum和avg一般处理数值型,max、min、count可以处理任何数据类型
③都可以搭配distinct使用,用于统计去重后的结果
④count的参数可以支持:字段、*、常量值,一般放1
6、连接查询(多表查询)
单个表不能满足需求时,需要结合多张表,去除有关联的数据。这时就需要用连接查询,连接查询有三种,通常join使用的最多。
1)连接方式一 :等值连接(连接条件有等号)——非等值连接(相反)
①等值连接的结果 = 多个表的交集
②多个表不分主次,没有顺序要求
③一般为表起别名,提高阅读性和性能
# 等值连接:查询所有员工的姓名、工种ID、工种名称SELECTa.last_name,a.job_id,b.job_titleFROMemployees a ,jobs bWHERE a.job_id = b.job_id;
2)连接方式二:通过join关键字实现连接
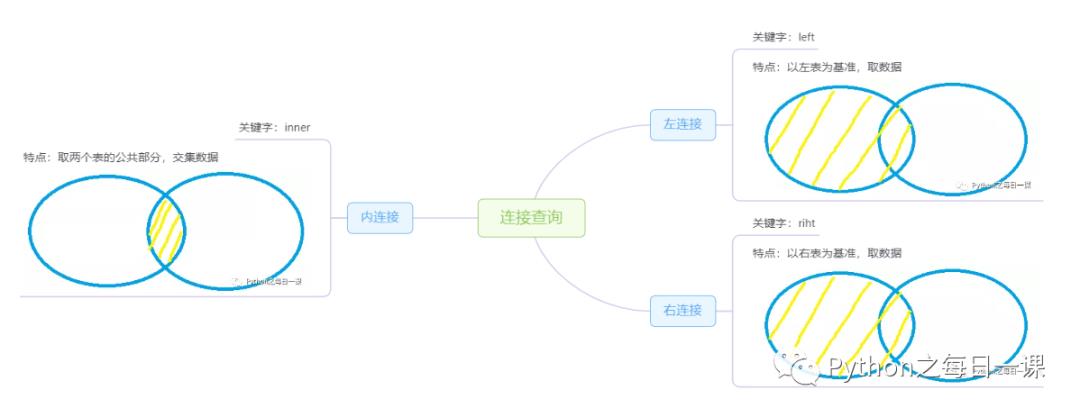
①语法
select 字段名,……
from 表1
【inner|left|right】join 表2 on 连接条件
【where 筛选条件】
【group by 分组字段】
【having 分组后的筛选条件】
【order by 排序的字段或表达式】②好处
语句上,连接条件和筛选条件实现了分离,简洁。
⭐ 注意:左右连接可互换 A left join B 等价于B right join A;内连接是左
右连接的交集;mysql没有外连接。
# 用内连接 实现查询所有员工的姓名、工种ID、工种名称SELECTa.last_name,a.job_id,b.job_titleFROMemployees aINNER JOIN jobs b ON a.job_id = b.job_id;
3)连接方式三:自连接
自连接相当于等值连接,但是等值连接涉及多个表,而自连接仅仅是它自己。如下:在员工信息表里,查询员工名和直接上级的名。
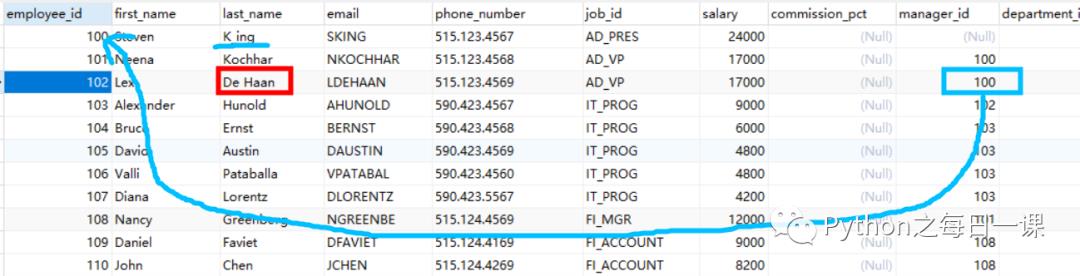
# 自连接:查询员工名和直接上级的名SELECT e.last_name,m.last_nameFROM employees eJOIN employees m ON e.`manager_id`=m.`employee_id`;
# 等值连接方式SELECT e.last_name,m.last_nameFROM employees e,employees mWHERE e.`manager_id`=m.`employee_id`;
7、子查询
一条查询语句中又嵌套了另一条完整的select语句,其中被嵌套的select语句,称为子查询或内查询。在外面的查询语句,称为主查询或外查询。
1)特点
①子查询都放在小括号内
②子查询可以放在from后面、select后面、where后面、having后面,但一般放在条件的右侧
③子查询优先于主查询执行,主查询使用了子查询的执行结果
④子查询根据查询结果的行数不同分为以下两类:
⭐单行子查询结果集只有一行一般搭配单行操作符使用:> < = <> >= <=非法使用子查询的情况:a、子查询的结果为一组值b、子查询的结果为空⭐多行子查询结果集有多行一般搭配多行操作符使用:any、all、in、not inin:属于子查询结果中的任意一个就行any和all往往可以用其他查询代替
2)举栗
# 查询位置ID是1700的所有部门人员信息SELECTfirst_nameFROMemployeesWHEREdepartment_id IN (SELECTdepartment_idFROMdepartmentsWHERElocation_id = 1700)
8、分页查询 (可选)
实际web开发中,当显示的数据,一页显示不完时,需要分页提交sql请求。
1)语法
select 字段|表达式,...
from 表名
【where 条件】
【group by 分组字段】var2=value2
【having 条件】
【order by 排序的字段】
limit 【起始的索引,显示个数】;2)特点
①起始条目索引默认从0开始
②limit子句放在查询语句的最后
③公式:select * from 表 limit (page-1)*sizePerPage,
sizePerPage:每页显示条目数page:要显示的页数
3)举栗
# 查询 员工信息前5条(0可以省略)SELECT*FROMemployeesLIMIT 0,5;# 查询 员工信息前5-10条SELECT*FROMemployeesLIMIT 5,5;
9、union联合查询
union用于把涉及多个表的SELECT语句的结果组合到一个结果集合中。适用于查
询条件较多,多个表之间没有连接关系的场景。
1)语法
select 字段|常量|表达式|函数 【from 表】 【where 条件】 union 【all】
select 字段|常量|表达式|函数 【from 表】 【where 条件】 union 【all】
.....
select 字段|常量|表达式|函数 【from 表】 【where 条件】2)特点
①多条查询语句的查询的列数必须是一致的
②多条查询语句的查询的列的类型几乎相同
③union 代表去重,union all 代表不去重
3)举栗
# 执行下面语句,创建测试数据# 学生表CREATE TABLE `student` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(10) DEFAULT NULL,`age` tinyint(4) DEFAULT NULL,`classId` int(11) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;INSERT INTO `student` VALUES ('1', 's1', '20', '1'), ('2', 's2', '22', '1'),('3', 's3', '22', '2'), ('4', 's4', '25', '2');
# 教师表CREATE TABLE `teacher` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(10) DEFAULT NULL,`age` tinyint(4) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;INSERT INTO `teacher` VALUES ('1', 't1', '36'), ('2', 't2', '33'), ('3', 's3', '22');
# 查询所有学生和教师的id,姓名,年龄# UNIONSELECT id, name, age FROM studentUNIONSELECT id, name, age FROM teacher;# UNION ALLSELECT id, name, age FROM studentUNION ALLSELECT id, name, age FROM teacher;
UNION 和 UNION ALL 运行结果的区别如下:
⭐ 注意:在多个 SELECT 语句中,第一个 SELECT 语句中被使用的字段名
称将被用于结果的字段名称。当使用 UNION 时,MySQL 会把结果集中重复
的记录删掉,而使用 UNION ALL ,MySQL 会把所有的记录返回,且效率高
于 UNION。
以上是关于数据库基础篇—— SQL之数据查询的主要内容,如果未能解决你的问题,请参考以下文章