Apache IoTDB分布式架构初探
Posted 程序员789
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache IoTDB分布式架构初探相关的知识,希望对你有一定的参考价值。
Apache IoTDB从2018年11月捐赠给Apache基金会,成为孵化项目,到2020年9月毕业,期间经历了0.8-0.11 4个大的版本,但都是单机版本,社区对Apache IoTDB的分布式版本也呼声越来高。2021年4月,Apache IoTDB 0.12版本的发布,带来了一个期盼已久的好消息:Apache IoTDB 0.12开始支持分布式。今天我们就来看一下Apache IoTDB的分布式架构。
分布式架构
IoTDB采用Share-Nothing的分布式架构(这里指的是数据存本地磁盘的情况下,IoTDB也支持数据存储到HDFS上面,这种情况本文暂且不表),各个节点都是同质的,每个节点主要模块如下图所示:
单机有如下几大模块:分别为Physical Plan Generator、SQL Parser、Single Read/Write Engine以及存储文件TsFile。分布式较单机多了如下几大模块:Data Partition、Distributed Query、Distributed Write以及各个节点之间同步协议Raft Synchronization模块。
IoTDB集群搭建之后,会根据节点的ip和port和当前启动时间生成一个hash值,所有节点按照此hash值排序形成一个圈,hash值最大的节点的后面的节点就是hash值最小的节点,集群会按照配置的副本数N,从hash值最小的节点开始,依次选择N-1个节点组成一个raft组,形成一个data group。所有的meta节点组成一个meta group。
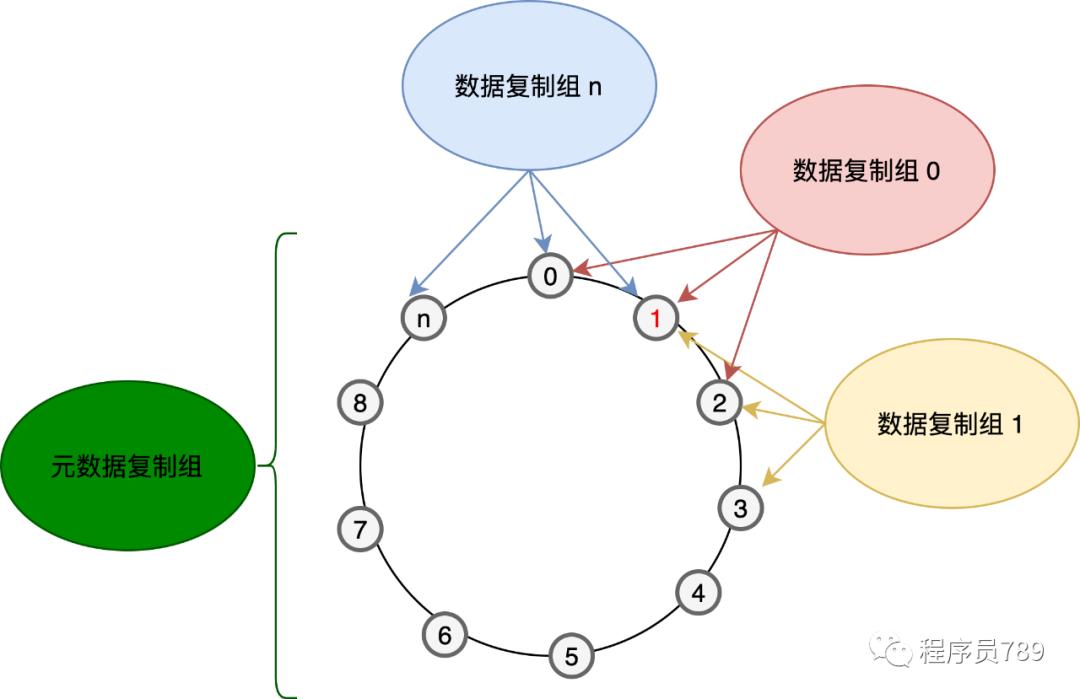
以4节点3副本为例,其会形成如下raft复制组,每个节点上面都会有N+1个复制组,N是副本数,即N个data raft group,1指的是所有节点形成一个meta raft group。
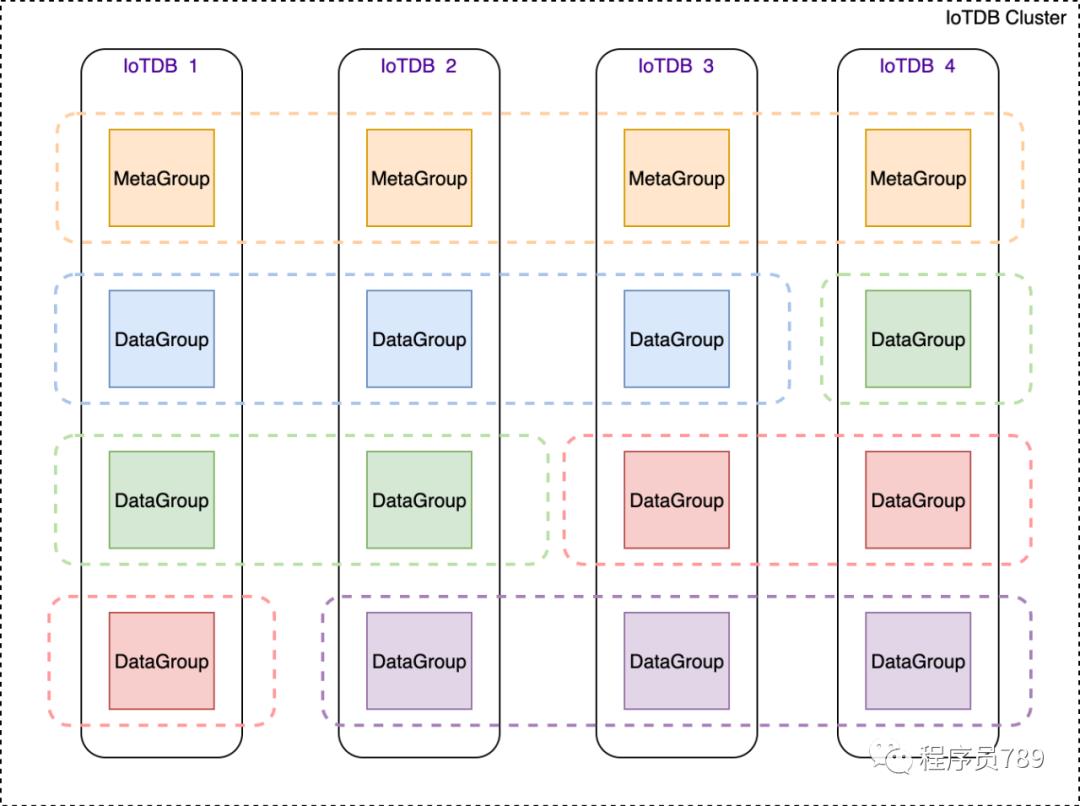
分布式数据存储
当初始化好了raft复制组之后,面临的问题就是数据归属问题,哪些raft复制组处理哪些数据呢?这就需要数据分区这个模块来解决了。
数据分区模块负责元数据、数据分布的计算工作,为了便于表述,本文在此讲述下IoTDB的一些基础概念。
IoTDB基础概念
IoTDB模型是树状结构。如下所示,有存储组、设备、测点等概念。存储组可以理解为传统数据库中的表,在存储的时候,不同的存储组的数据是存储在不同的文件夹中的。下图中有root.sgcc、root.ln两个存储组。叶子节点叫做测点,叶子节点的父节点叫做设备。从父节点root到叶子节点的全路径叫做时序。比如下图中有root.sgcc.wf01.status等4条时序。关于这些概念的详细描述,请参考IoTDB官方网站[1]。
元数据分布
对于分布式IoTDB来说,有两种类型的元数据信息,一种是存储组、另外一种是时序。为什么说两种类型的元数据呢?因为这两种元数据是不同的复制组管理的。存储组是meta raft group管理的。而时序信息是由data raft group管理的。这样做的好处也是因为存储组元数据比较少,可以在各个节点保存;但是时序信息有可能比较大,有可能高达千万级别,如果每个节点都保存有相同的时序信息,每个节点会浪费太多的内存空间。(这里也是内存和时间的trade off,当然每个节点都有时序的元数据信息是最好的,因为写入、查询会用到这些时序元数据信息。这里将在后面的文章中进行分析)。
存储组分布
对于存储组这样的元数据,由于是meta raft group管理的。数据每个节点都会保存,就不存在数据分布的问题了。
时序分布
对于时序和数据的存储,其是分布到多台机器存储的。分布的核心是一个数据分区算法,即如何判定我的(元)数据应该存储在哪台机器上?
IoTDB系统中预先设置了10000个slot,然后会均匀的把这些slot分到集群中各个IoTDB实例中,假设节点数是M,则集群环中的前M-1个节点每个节点分配的slot数是10000/M,最后一个节点是slot数就是10000-10000/M*(M-1)。可能较前M-1个节点会多一些。
比如,在6个节点组成的集群的情况下,第一个节点会分配0-1665共1666个slot;第二个节点会分配1666-3331共1666个slot;第三个节点会分配3332-4997共1666个slot;第四个节点会分配4998-6663共1666个slot;第五个节点会分配6664-8329共1666个slot;而第六个节点就会分配8330-9999共1670个slot。
得到了节点和slot id的关系,剩下的就是如何把数据映射到slot中。
IoTDB采用了如下hash算法:
slot_id = hash(storage_group, time_partition) % total_slot_numstorage_group即存储组的名字,time_partition会根据元数据操作还是数据操作,执行不同的策略。
在计算时序的分布的时候,time_partition永远等于0,即可以理解为同一个存储组的所有时序都是保存在同一个data raft组中的。
数据分布
数据分布与时序元数据分布的计算公式都是一致的,区别在于其time_partition不是0,而是计算出来的。
time_partition = time_stamp % partition_intervalslot_id = hash(storage_group, time_partition )% total_slot_num
time_stamp是数据插入的时间戳,而partition_interval是时间分区,比如一周、一个月等。由于同一个时间分区的数据是保存在一起的,对于查询和过期数据删除都有优势。
参考文献
[1] Apache IoTDB https://iotdb.apache.org/
以上是关于Apache IoTDB分布式架构初探的主要内容,如果未能解决你的问题,请参考以下文章