Neo4j之全文检索
Posted Neo4j权威指南
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Neo4j之全文检索相关的知识,希望对你有一定的参考价值。
本篇文章我们开始谈谈Neo4j的全文检索功能,Neo4j的全文索引是基于Lucene实现的,但是Lucene默认情况下只提供了基于英文的分词器,下篇文章我们在讨论中文分词器(IK)的引用,本篇默认基于英文分词来做。我们前边文章就举例说明过,比如我要搜索苹果公司?首先我们要做的第一步在各个词条上创建全文索引,第二步我们根据苹果公司进行全文检索,把匹配度高的按顺序输出。下边我们一步步讲解怎么做。
首先看看这两个词的用方法。CALL语句用于调用数据库中的过程(Procedure),YIELD子句用于显示的选择返回结果集中的哪些部分并绑定到一个变量以供后续查询引用。简单说就是用call来调用函数,用yield来接收函数返回的结果。我们举个例子
call db.labels() yield labelreturn count(label) as num
这里是调用数据库中内嵌的过程db.labels()计算数据库中的总标签数。返回结果
在Neo4j中,有两种不同的索引类型:B-树和全文索引
可以使用Cypher创建和删除B-树索引。用户通常不必知道索引就可以使用它,因为Cypher的查询计划器会决定在哪种情况下使用哪个索引。B-树索引擅长于对所有类型的值进行精确查找,以及范围扫描,完整扫描和前缀搜索。比如(=,>,start with,contains)等
全文索引与B-树索引不同,它们针对索引和搜索文本进行了优化。它们用于需要理解语言的查询,并且仅索引字符串数据。还必须通过过程明确查询它们。全文索引需要手动去创建
它,查询的时候也是手动去调用。
在理解了索引的两种概念后,我们着手看看全文索引怎么创建。
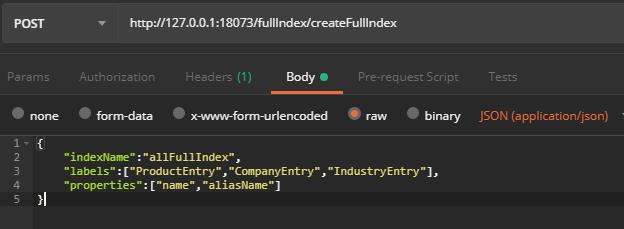
在第一节中用到了db.labels()的过程,那有没有内置创建全文索引的过程呢。答案当然是有了。会发现有db.index.fulltext.createNodeIndex(),那就用这个过程来开始创建一个全文索引。在Dao层代码如下,其中创建索引的名称,标签和字段通过动态传参传过去的,比如在公司,产品上创建公司名称,产品名称的全文索引名称为allFullIndex
@Repositorypublic interface FullIndexRepository extends Neo4jRepository<CompanyEntryNode, String> { @Query("call db.index.fulltext.createNodeIndex({indexName},{labels},{properties})") void createFullIndex(String indexName, String[] labels, String[] properties);
@Query("call db.index.fulltext.drop({indexName})") void deleteFullIndexByName(String indexName);}
service层和controller层就不写了,直接调用我们创建的过程,就成功创建了一个名称为allFullIndex的全文索引。
四、查询索引
同样的有创建索引的过程,也有查询全文索引的过程
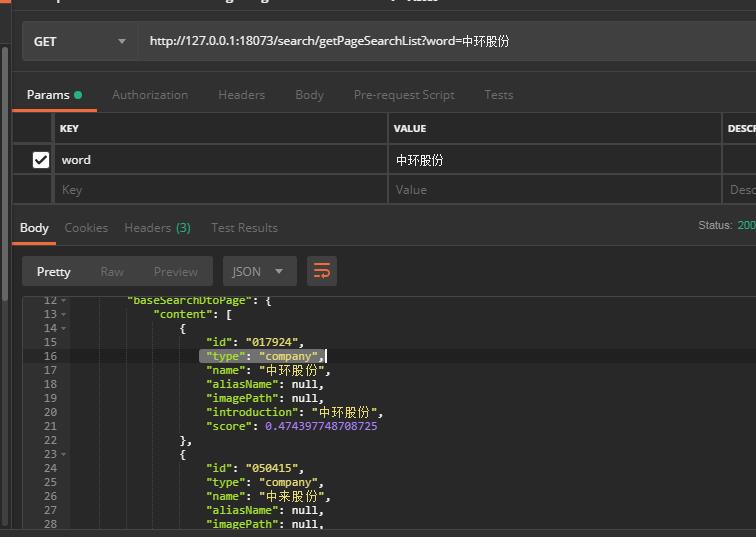
db.index.fulltext.queryNodes(),那我们在dao层做如下定义。这里结果中返回了node和score。score就是按照相似度给出的一个分值,分词器会影响这个分值,node就是创建索引的节点信息。结果默认是按照score数值从高到低返回。
@Repositorypublic interface BaseSearchRepository extends Neo4jRepository<CompanyEntryNode, String> {
@Query("call db.index.fulltext.queryNodes('allFullIndex',{searchWord}) yield node,score " + "return node.name as name,score") List<BaseSearchDto> fullTextSearch( String searchWord); }
描述 |
删除指定的索引。 |
用法 |
db.index.fulltext.drop(indexName :: STRING?) :: VOID
|
db.index.fulltext.createNodeIndex()
描述 |
为给定的标签和属性创建节点全文索引。 可选的“ config”映射参数可用于为索引提供设置。支持的设置是“分析器”,用于指定在建立索引和查询时要使用的分析器。使用以下db.index.fulltext.listAvailableAnalyzers步骤查看可用的选项。可以将'eventually_consistent'设置为'true',以使该索引最终保持一致,从而将来自提交事务的更新应用于后台线程。 |
语法 |
db.index.fulltext.createNodeIndex(indexName :: STRING?, labels :: LIST? OF STRING?, properties :: LIST? OF STRING?, config = {} :: MAP?) :: VOID
|
db.index.fulltext.createRelationshipIndex()
描述 |
查询给定的全文索引。 返回匹配关系及其Lucene查询分数,按分数排序。 选项映射的有效键是:'skip'跳过前N个结果;'limit'限制返回的结果数。 |
用法 |
db.index.fulltext.queryRelationships(indexName :: STRING?, queryString :: STRING?, options = {} :: MAP?) :: (relationship :: RELATIONSHIP?, score :: FLOAT?)
|
db.index.fulltext.queryRelationships()
描述 |
为给定的关系类型和属性创建一个关系全文本索引。 可选的“ config”映射参数可用于为索引提供设置。支持的设置是“分析器”,用于指定在建立索引和查询时要使用的分析器。使用以下db.index.fulltext.listAvailableAnalyzers步骤查看可用的选项。可以将'eventually_consistent'设置为'true',以使该索引最终保持一致,从而将来自提交事务的更新应用于后台线程。 |
用法 |
db.index.fulltext.createRelationshipIndex(indexName :: STRING?, relationshipTypes :: LIST? OF STRING?, properties :: LIST? OF STRING?, config = {} :: MAP?) :: VOID
|
db.index.fulltext.queryNodes()
描述 |
查询给定的全文索引。 返回匹配的节点及其Lucene查询分数,按分数排序。 选项映射的有效键是:'skip'跳过前N个结果;'limit'限制返回的结果数。 |
用法 |
db.index.fulltext.queryNodes(indexName :: STRING?, queryString :: STRING?, options = {} :: MAP?) :: (node :: NODE?, score :: FLOAT?)
|
db.index.fulltext.listAvailableAnalyzers()
描述 |
列出可以配置全文本索引的可用分析器。 |
用法 |
db.index.fulltext.listAvailableAnalyzers() :: (analyzer :: STRING?, description :: STRING?, stopwords :: LIST? OF STRING?)
|
这其中我们有两个问题,第一个是我们的分词器不是中文分词器,对查询结果是有影响的。第二个是我们除了内置的过程,还有没有其他的过程呢,比如别人封装好的,这个当然有。那就是APOC。基于上述两个问题我们后期文章会详细说明。
- 本期完 -
有疑问请点赞哈 ,我会及时回复。由于微信限制了公众号留言功能,有问题你可以直接发公众号聊天,我会在下期文章末尾解答你的问题。
,我会及时回复。由于微信限制了公众号留言功能,有问题你可以直接发公众号聊天,我会在下期文章末尾解答你的问题。
为方便看最新内容,记得关注哦 !
!
以上是关于Neo4j之全文检索的主要内容,如果未能解决你的问题,请参考以下文章