复旦大学自然语言处理实验室发布模型鲁棒性评测平台TextFlint
Posted 机器学习算法与自然语言处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了复旦大学自然语言处理实验室发布模型鲁棒性评测平台TextFlint相关的知识,希望对你有一定的参考价值。
转载自 | PaperWeekly
https://github.com/textflint
官方网站:
http://textflint.io/
论文链接:
https://arxiv.org/pdf/2103.11441.pdf (点击阅读原文获取)

引言
近年来,随着自然语言处理技术的不断突破,深度学习模型在各项 NLP 任务中的表现正在稳步攀升。2018 年 1 月,在斯坦福大学发起的 SQuAD 阅读理解评测任务中,来自微软亚洲研究院的自然语言计算组所提出的算法率先赶超了人类。短短三年后,微软的 DeBERTa 和谷歌的 T5+Meena 模型在包含了多种自然语言处理任务的综合评测集合 SuperGLUE 上再次超越了人类。近日 IBM 号称“首个能在复杂话题上与人类辩论的 AI 系统”的 Project Debater 登上了 Nature 杂志的封面,该系统在 78 类辩题中获得了接近人类专业辩手的平均评分。我们不禁要问,人类真的被打败了吗?
事实上,纵使这些 NLP 模型在实验数据集上的表现十分惊人,在实际应用中我们却很难感知到自然语言处理系统“超越人类”的语言理解水平。难倒这些看似“聪明”的模型,只需要一个简单的“逗号”,即便是基于赫赫有名的预训练语言模型 BERT 的算法也不例外。
例如,“汉堡很好吃薯条一般”对汉堡的评价是正面的,但当我们插入“,”时,一些模型就会将“汉堡很好吃,薯条一般”判别为对汉堡的负面评价。一个微小且无关紧要的改动就能使自然语言处理系统失效,诸如此类的例子屡见不鲜。


鲁棒性何为
鲁棒性是机器学习模型的一项重要评价指标,主要用于检验模型在面对输入数据的微小变动时,是否依然能保持判断的准确性,也即模型面对一定变化时的表现是否稳定。鲁棒性的高低直接决定了机器学习模型的泛化能力。在研究领域中,许多模型只能在某一特定的数据集上呈现准确的结果,却不能在其他数据集上复刻同样优异的表现,这就是由于模型对新数据中的不同过于敏感,缺乏鲁棒性。
在现实世界的应用场景中,模型要面对的是更加纷繁复杂的语言应用方式,待处理的数据里包含着更加庞杂的变化。一旦缺乏鲁棒性,模型在现实应用中的性能就会大打折扣。在测试数据集上获得高分是远远不够的,机器学习模型的设计目标是让模型在面对新的外部数据时依然维持精准的判断。因此,为了确保模型的实际应用价值,对模型进行鲁棒性评测是不可或缺的。

方法 & 实验
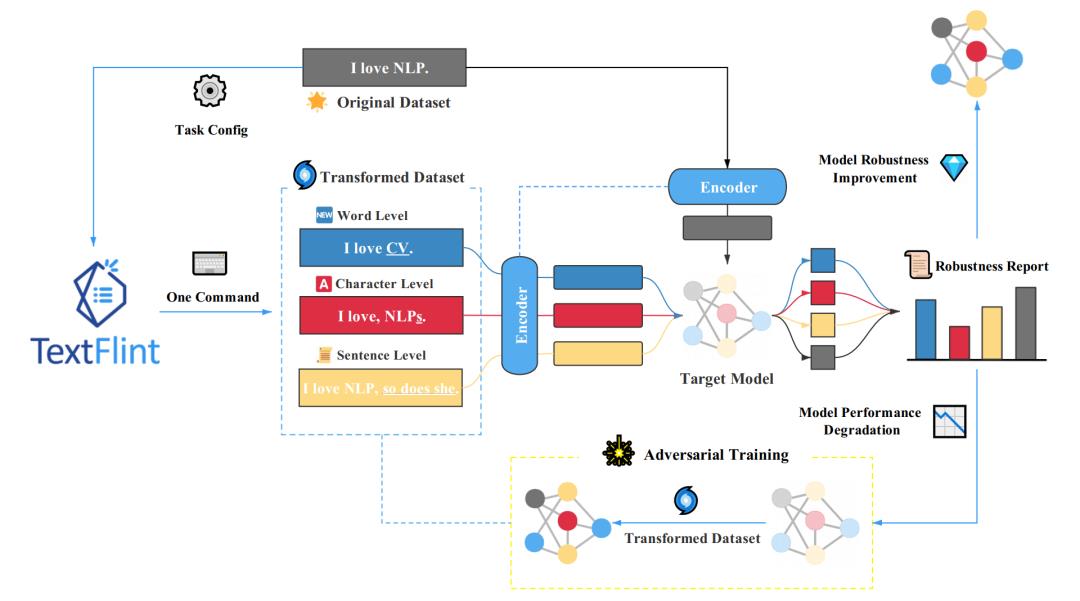
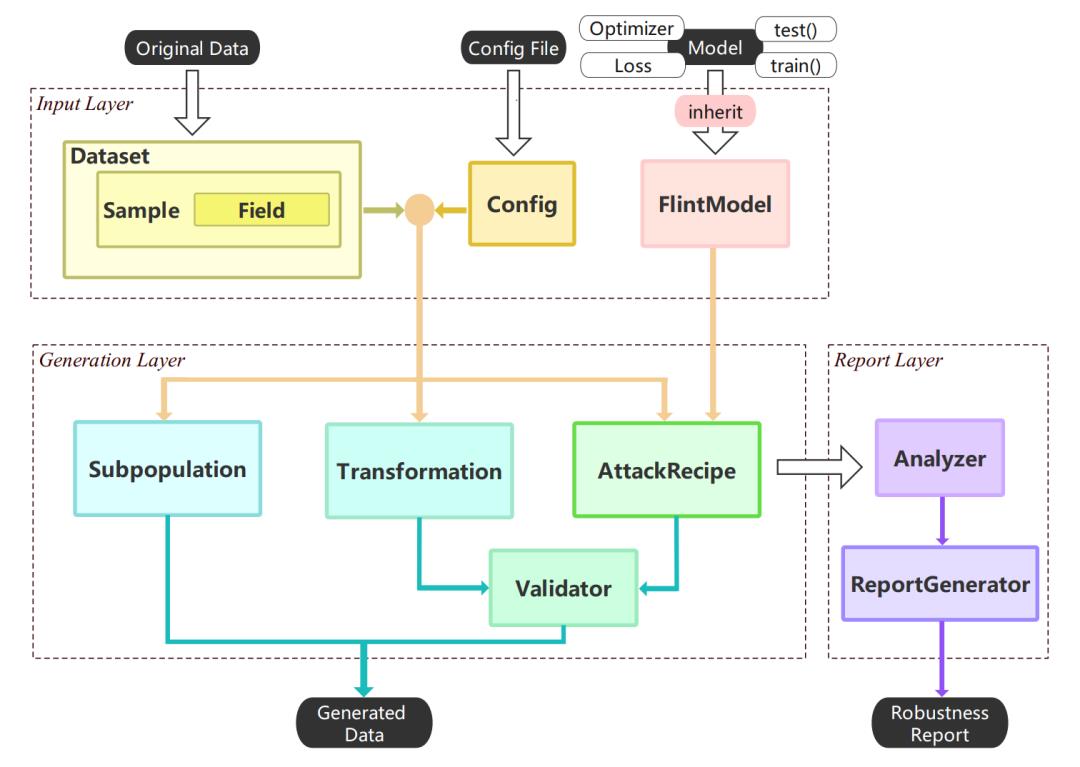
TextFlint 包含针对 12 项 NLP 任务,设计了 80 余种数据变形方法(20 余种任务通用变形、60 余种领域特有变形),涵盖了领域相关黑盒变形、领域无关黑盒变形、白盒变形、分组抽样、分析报告等等一系列功能。为了确保数据变形方法符合语言使用,针对不同任务上的所有变形选取约 10 万条变形后的语料进行了语言合理性(Plausibility)和语法正确性(Grammaticality)人工评测,确保了变形方法的可用性。使用者仅仅需要添加几行代码,就可以完成模型鲁棒性的详细检测。
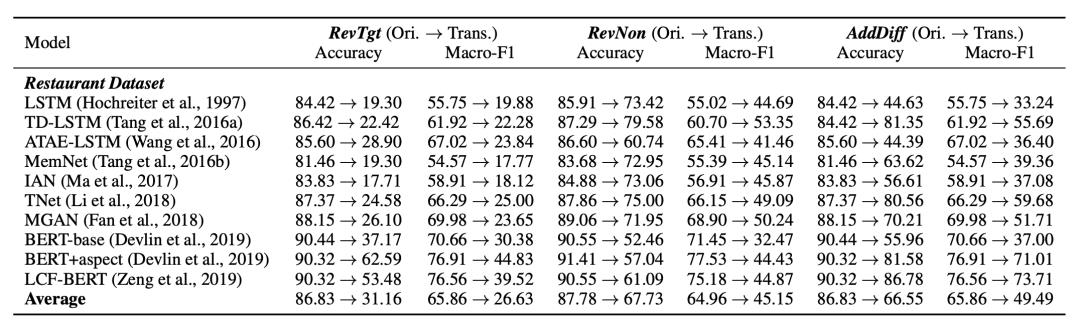
从结果中可以看到,原始测试集上所有模型的精度(Accuracy)和宏平均 F1(Macro-F1)得分都非常高,平均精度接近 86%,平均宏平均 F1 达到 65%。但是,这些指标在变形后的三个新测试集上均有显著下降。转换评论对象倾向性极性变形使得模型的性能下降最多,因为它要求模型更精准地关注目标情感词。原句后增加干扰句变形导致非 BERT 模型的性能下降显著,这表明大多数非预训练模型缺乏将相关方面与无关方面进行区分的能力。

总结
以上是关于复旦大学自然语言处理实验室发布模型鲁棒性评测平台TextFlint的主要内容,如果未能解决你的问题,请参考以下文章