K8S节点网络故障排除过程
Posted 技术爱好者家园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8S节点网络故障排除过程相关的知识,希望对你有一定的参考价值。
一、环境介绍
K8S 集群有四个节点,主机列表如下
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
由于特殊原因,需要将之前K8S 集群铲掉重新部署,新旧k8s版本都是19.4,网络CNI插件使用flannel。。新集群部署完成后查看node状态都已处于正常状态。
由于特殊需要,要将K8S集群内存监控系统页面(grafana)映射到出来让办公网络能够访问(之前测试ping pod IP 能够正常ping通所以认为是网络正常),所以在非k8s节点通过nginx代理访问,配置好Nginx后并reload生效,在办公环境通过Nginx代理访问非常慢,有时候直接访问出错。
在Nginx主机ping grafana IP发现居然无法ping通,通过交换机可以ping通grafana IP(说明grafana本身没有问题),随后在Nginx主机使用tracepath 测试grafana IP 获取路由信息,发现路由到172.18.1.12 将无法进行下去,说172.18.1.12这台主机与grafana pod网络不同,但是这台主机是k8s中的一个节点,正常情况下可以访问pod网络,随后登录到172.18.1.12状态主机ping grafana IP其实无法ping通,而其它k8s节点可以ping通,问题基本可以确定是172.18.1.12这台主机网络插件出现flannel异常,查看flannel插件日志并没有发现错误信息
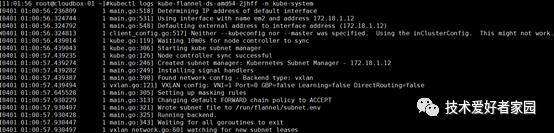
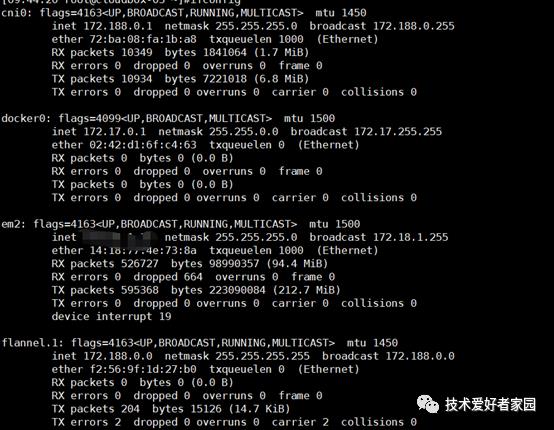

基于这个想法,修改172.18.1.12节点的flannel配置文件更换pod网段。
① 修改/run/flannel/subnet.env文件将172.188.0.0/24 更该172.188.4.0/24(不要和已分配网段冲突)
② 删除现有网桥
Ip link del 网桥名称
③ 重启docker服务 systemctl restart docker
重启后查看新建网桥的IP网段都已改变,但是其它节点并没有添加新的网段路由。
重新查看/run/flannel/subnet.env配置文件,发现配置还原了,分析应该是flannel读取etcd保存的配置文件并覆盖,而新的网络配置并没有写到到etcd所有其它节点没有感知到网络变更。
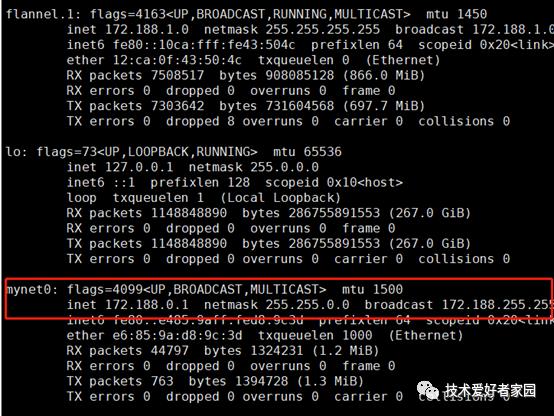
到这里我想只要更新etcd中的数据才能真正修改,修改网络并通知所有节点,但是如果新加入节点,原有的172.188.0.0网络还是有可能被分配。我了彻底解决这个问题,这个问题的根源是由于每个节点都有一个mynet0的网桥,这个网桥目前不确定有什么作用,由于是测试环境,所以尝试在所有节点删除这个网桥。
删除后重复之前②③步骤,重新ping 其它节点cni0IP 能够正常ping通。
登录到非k8s节点ping grafana 也能够正常通讯,查看所有节点路由表发现172.188.0.0/16的路由条目消失,增加172.188.0.0/24路由表
1、经过分析可能是由于之前k8s集群没有清理干净,特别是etcd内保存的各个模块的配置文件,没有清理导致问题发生。
2、如果在生产环境不能删除未经确认的网桥,有可能会导致更大的故障
3、部署k8s集群最好是使用干净的操作系统进行部署,防止发生类似的异常故障。
以上是关于K8S节点网络故障排除过程的主要内容,如果未能解决你的问题,请参考以下文章
教程篇(5.0) 10. 故障排除 ❀ FortiEDR ❀ Fortinet 网络安全专家 NSE 5