牛气的即时编译JIT,让PostgreSQL复杂查询性能小幅提升
Posted 励志成为PostgreSQL大神
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了牛气的即时编译JIT,让PostgreSQL复杂查询性能小幅提升相关的知识,希望对你有一定的参考价值。
JIT基本原理
大家好,我叫JIT编译,我马上要被DBA运行起来了。我是在PostgreSQL 11出现的,使用我有一个前提条件就是需要安装LLVM,然后在编译PostgreSQL的时候使用LLVM编译选项。
我的英文名叫just in time,也叫做实时编译,也就是程序在运行的过程中进行动态编译,编译之后就少了中间代码。怎么理解呢?我们来看一个重磅Speeding up query execution in PostgreSQL using LLVM JIT compiler文章对我的介绍。
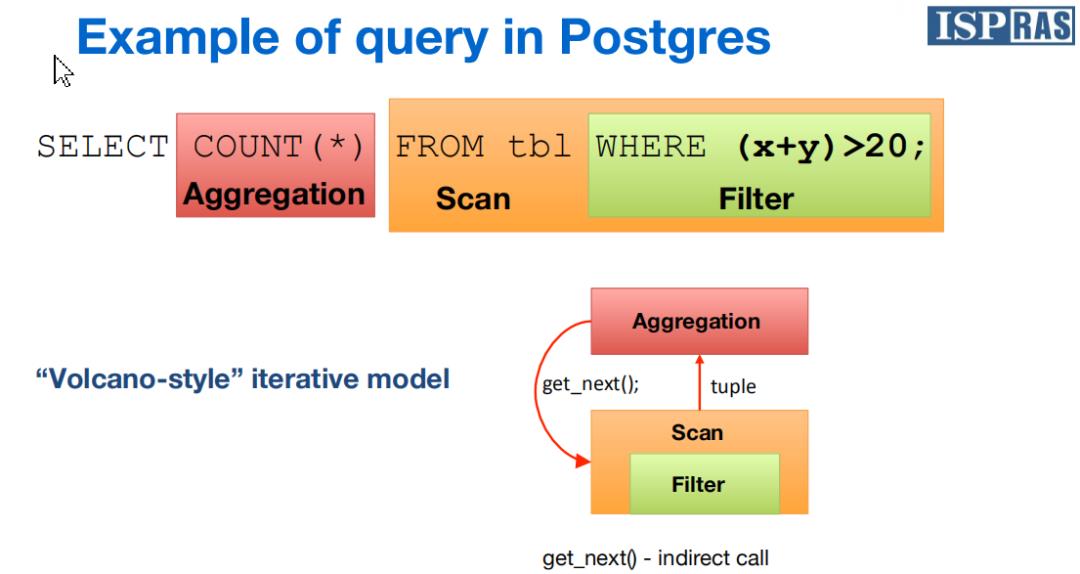
从这个图我们可以看出,首先需要对tb1所在的元组进行扫描,然后执行条件filter,也就是(x+y)>20这个条件,如果符合的话就进行Aggregation计算。计算完继续扫描下一个,以此类推,直到整个表全部扫描完成。
这个执行的模型叫火山模型(Volcano-style),属于最早的查询执行引擎,它还有个学名叫迭代模型 (iterator model)。
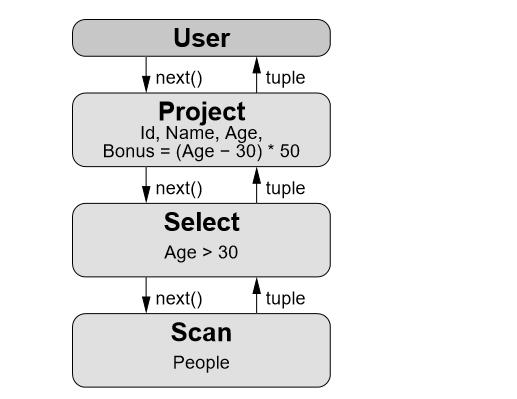
火山模型的主要缺点是昂贵的解释开销 (interpretation overhead) 和低下的 CPU Cache 命中率。在编译器中,虚函数调用需要查找虚函数表, 并且虚函数调用是一个非直接跳转 (indirect jump), 会导致一次错误的CPU分支预测 (brance misprediction), 一次错误的分支预测需要十几个周期的开销。火山模型为了返回一个元组,需要调用多次next()方法,导致昂贵的函数调用开销。
所以为了解决这个问题人们开发了我。
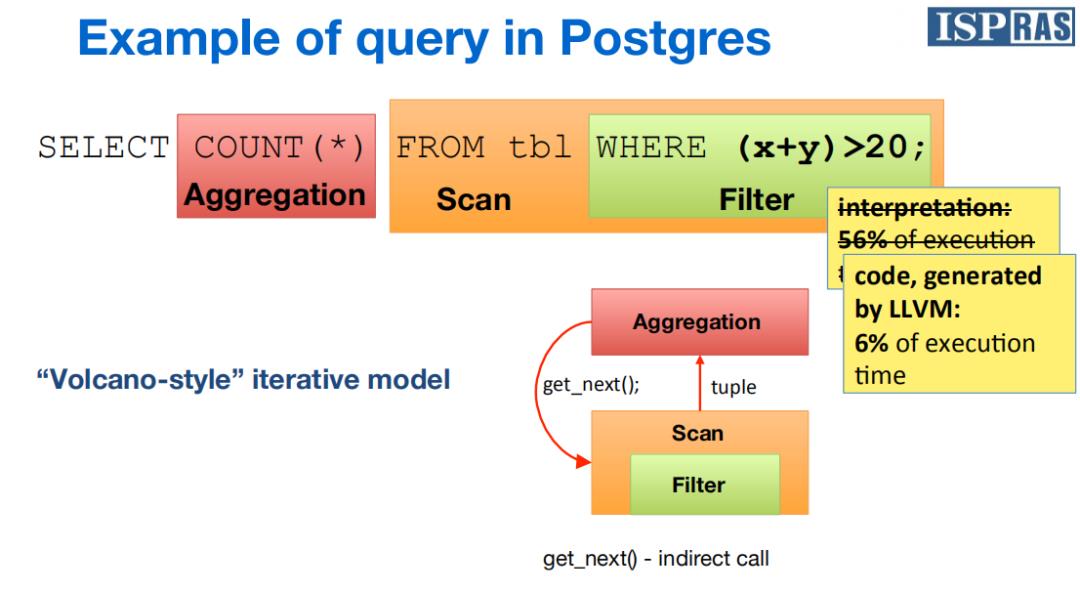
虽然还是火山模型,但是执行了实时编译,减少了冗余的逻辑操作和虚拟函数调用,使执行时间变短。
我有两种加速操作,一种是表达式计算,另外一种是元组拆解。表达式计算被用来计算WHERE子句、目标列表、聚集以及投影。通过为每一种情况生成专门的代码来实现加速。元组拆解是把一个磁盘上的元组转换成其在内存中表示的过程。通过创建一个专门针对该表布局和要被抽取的列数的函数来实现加速。当然官方文档中还介绍了一种方式叫内联,J可以把小函数的函数体内联到使用它们的表达式中。
编译和安装JIT
在介绍了我的基本原理和作用之后,现在让我实战告诉你我的使用方法。
首先安装的时候要安装LLVM包。以centos 7为例,需要安装llvm-toolset软件包。
sudo yum install llvm-toolset-7 llvm-toolset-7-llvm-devel.x86_64
在编译安装PostgreSQL的时候使用选项--with-llvm LLVM_CONFIG。
export PGHOME=/app/pg/
export SEGSIZE=2
export BLOCKSIZE=8
./configure --prefix=${PGHOME} \
--bindir=${PGHOME}/bin \
--libdir=${PGHOME}/lib \
--with-libraries=/usr/local/lib \
--with-includes=/usr/local/include \
--sysconfdir=${PGHOME}/etc \
--includedir=${PGHOME}/include \
--datarootdir=${PGHOME}/share \
--datadir=${PGHOME}/share \
--with-pgport=5432 \
--with-perl \
--with-python \
--with-openssl \
--with-pam \
--with-ldap \
--with-libxml \
--with-libxslt \
--with-segsize=${SEGSIZE} \
--with-blocksize=${BLOCKSIZE} \
--with-llvm LLVM_CONFIG='/opt/rh/llvm-toolset-7/root/usr/bin/llvm-config'
make world && make install-world
这里一般会编译报错。需要修改一下源码。
[root@localhost postgresql-13.2]# vi src/Makefile.global.in
COMPILE.c.bc = $(CLANG) -Wno-ignored-attributes $(BITCODE_CFLAGS) $(CPPFLAGS) -flto=thin -emit-llvm -c
COMPILE.cxx.bc = $(CLANG) -xc++ -Wno-ignored-attributes $(BITCODE_CXXFLAGS) $(CPPFLAGS) -flto=thin -emit-llvm -c
这里出现问题的主要原因是clang编译器太旧了,无法理解新的参数。把-flto=thin这个参数删除。然后重新编译。
具体此错误的描述可以参考邮件组:https://www.postgresql.org/message-id/flat/CAEepm%3D3SJRpO63dMvKNp2u5eodFrK1hSQouANta70AxGwPe-Dg%40mail.gmail.com#CAEepm=3SJRpO63dMvKNp2u5eodFrK1hSQouANta70AxGwPe-Dg@mail.gmail.com
如果是centos 8,参考官网的配置:https://www.postgresql.org/about/news/llvm-issues-with-postgresql-yum-repository-on-centos-8-2115/
使用jit
在PostgreSQL 13版的数据库上,我默认是打开的。通过jit参数可以看到我当前的状态。
[postgres@localhost ~]$ psql
psql (13.2)
Type "help" for help.
postgres=# show jit;
jit
-----
on
(1 row)
我们直接来测试一下。
create table t1 (id1 int,id2 int,id3 int,id4 int,id5 int,id6 int);
INSERT INTO t1 SELECT i/10000,i,i,i,i,i FROM generate_series (1,10000000) s(i);
EXPLAIN ANALYZE SELECT
SUM(id2) ,
SUM(id2* 5) ,
MIN(id3* 0.1) ,
MAX(id4* 0.6) ,
SUM(id5* 0.2 * 0.002)
FROM t1 where id2+id3>200
GROUP BY id1;
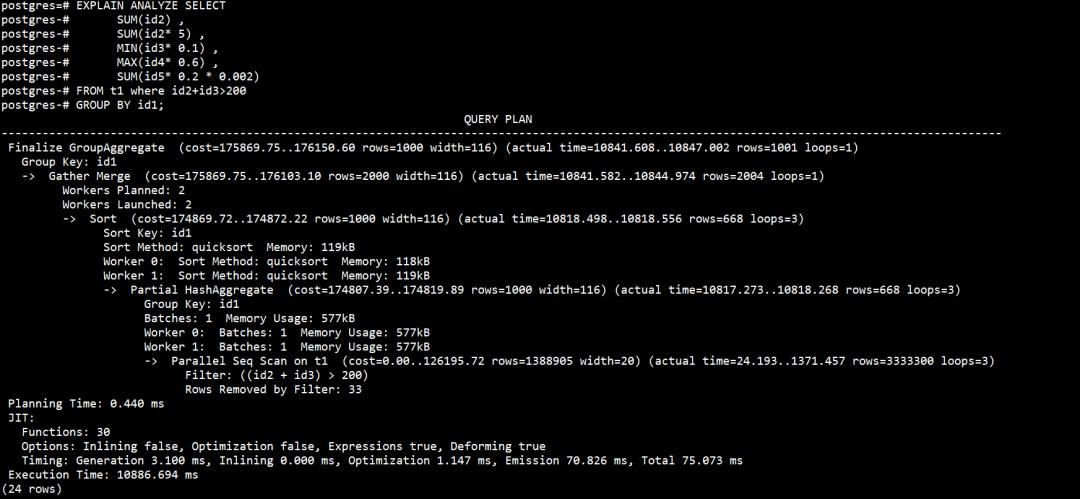
多次执行后,可以看到使用我JIT执行的时长大概是10886ms,而相关的表达式优化已经打开。
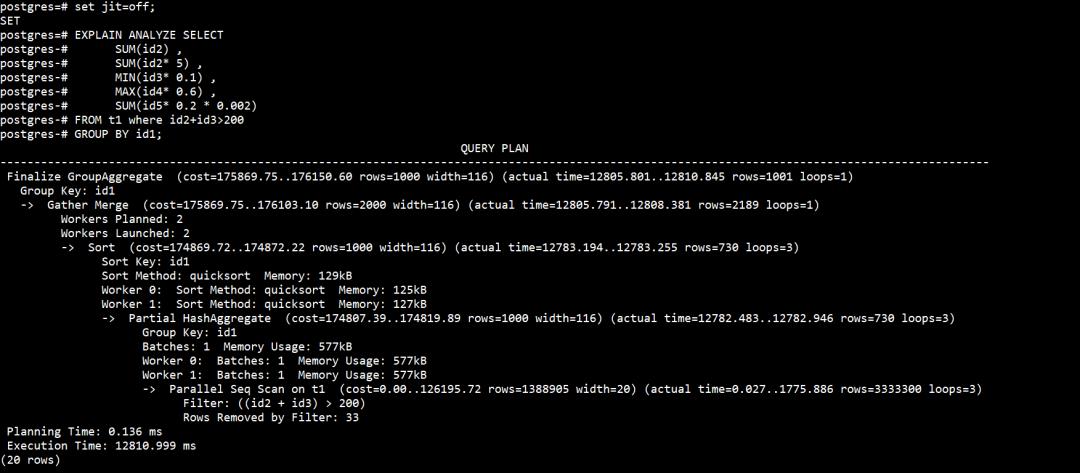
此时如果dba把我关闭。执行的时长就会变成12810ms。执行时间提升15%左右。
postgres=# show jit_above_cost;
jit_above_cost
----------------
100000
(1 row)
postgres=# show jit_inline_above_cost;
jit_inline_above_cost
-----------------------
500000
(1 row)
postgres=# show jit_optimize_above_cost;
jit_optimize_above_cost
-------------------------
500000
(1 row)
postgres=# show jit_provider;
jit_provider
--------------
llvmjit
(1 row)
有4个重要的参数,前面三个参数的作用是是否要为一个查询语句执行实时编译,以及在执行中需要花费多大的努力。而最后一个参数jit_provider决定使用哪种JIT实现,我们一般不改这个配置。
后记
安装和配置JIT非常的简单。一般JIT使用场景还是在OLAP那些较大型复杂的查询上面收益会比较高。
参考链接:
1.https://www.percona.com/blog/2018/11/19/installing-and-configuring-jit-in-postgresql-11/
2.https://llvm.org/devmtg/2016-09/slides/Melnik-PostgreSQLLLVM.pdf
3.https://blog.csdn.net/weixin_44233163/article/details/86157350
4.https://www.postgresql.org/message-id/flat/CAEepm%3D3SJRpO63dMvKNp2u5eodFrK1hSQouANta70AxGwPe-Dg%40mail.gmail.com#CAEepm=3SJRpO63dMvKNp2u5eodFrK1hSQouANta70AxGwPe-Dg@mail.gmail.com
5.https://www.postgresql.org/about/news/llvm-issues-with-postgresql-yum-repository-on-centos-8-2115/
励志成为PostgreSQL大神
长按关注吧
以上是关于牛气的即时编译JIT,让PostgreSQL复杂查询性能小幅提升的主要内容,如果未能解决你的问题,请参考以下文章