JAVA集合之ArrayList源码分析
Posted 黎明大大
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA集合之ArrayList源码分析相关的知识,希望对你有一定的参考价值。
ArrayList的数据结构
那么ArrayList的数据结构如下图:

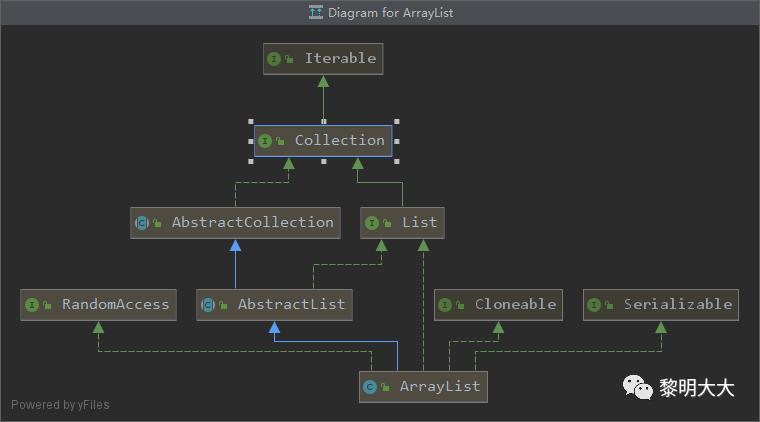

List<E>接口:
RandomAccess接口:
Cloneable接口:
Serializable接口:
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable{// 版本号private static final long serialVersionUID = 8683452581122892189L;// 默认初始容量private static final int DEFAULT_CAPACITY = 10;// 空对象数组private static final Object[] EMPTY_ELEMENTDATA = {};// 默认空对象数组private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};// 元素数组transient Object[] elementData;// 实际元素大小,默认为0private int size;// 最大数组容量private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;}
构造方法分析
/*** Constructs an empty list with an initial capacity of ten.*/public ArrayList() {//DEFAULTCAPACITY_EMPTY_ELEMENTDATA:是个空的Object[], 将elementData初始化,elementData也是个Object[]类型。this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}
public ArrayList(Collection<? extends E> c) {//将集合转为数组elementData = c.toArray();//将elementData.length 赋值给 size,如果size的长度为0,则进行初始化为一个空数组if ((size = elementData.length) != 0) {//每个集合的toArray()的实现方法不一样,所以需要判断一下,如果不是Object[].class类型,那么就需要使用ArrayList中的方法去改造一下。if (elementData.getClass() != Object[].class)elementData = Arrays.copyOf(elementData, size, Object[].class);} else {// 替换为空数组this.elementData = EMPTY_ELEMENTDATA;}}
/*** @param initialCapacity 用户自定义初始化容量*/public ArrayList(int initialCapacity) {if (initialCapacity > 0) {//如果用户定义的初始化容量大于0,则直接将数组容量扩容到用户定义的容量this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {//如果用户定义的初始化容量等于0,则直接构造一个空的数组this.elementData = EMPTY_ELEMENTDATA;} else {//如果用户定义的初始化容量小于0,则直接抛出异常throw new IllegalArgumentException("Illegal Capacity: " +initialCapacity);}}
核心方法分析

/*** 最为常用的添加方法** @param e 添加元素* @return*/public boolean add(E e) {//确定内部容量是否够了,size是全局变量,该变量就是数组中数据的个数,因为要添加一个元素,所以size+1,ensureCapacityInternal(size + 1);//在数组中正确的位置上放上元素e,并且size++ (ps:个人认为size++和size+1可以做成一个变量然后通用,而不是分两步进行操作,其实在这个地方也可以看的出线程不安全)elementData[size++] = e;return true;}
/*** 确定内部容量的方法** @param minCapacity 最小容量数*/private void ensureCapacityInternal(int minCapacity) {//ensureExplicitCapacity:判断是否需要进行扩容//calculateCapacity:确认首次扩容大小ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));}
/*** 确认首次扩容大小** @param elementData 元素数组* @param minCapacity 需要最小容量* @return*/private static int calculateCapacity(Object[] elementData, int minCapacity) {//初次扩容判断元素数组是否为空,如果为空则首次扩容长度为10if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {//Math.max API作用:比较两个值,返回最大的值//DEFAULT_CAPACITY:默认值为10//minCapacity:首次进来这里就是1啦//最后返回10出去,不过这里还没有实现真正扩容哦return Math.max(DEFAULT_CAPACITY, minCapacity);}return minCapacity;}
/*** 判断是否需要进行扩容** @param minCapacity 需要最小扩容数*/private void ensureExplicitCapacity(int minCapacity) {//该处的作用:就是一个安全机制,记录修改次数的,相当于版本号,关于Fail-Fast机制,后面详谈modCount++;//minCapacity如果大于了实际elementData的长度,那么就说明elementData数组的长度不够用,不够用那么就要增加elementData的length。 if (minCapacity - elementData.length > 0) {//那就交给grow方法扩张容量去吧。 grow(minCapacity);}}
/*** 扩容核心方法** @param minCapacity*/private void grow(int minCapacity) {//原来的元素数组容量int oldCapacity = elementData.length;//newCapacity容量是oldCapacity的1.5倍容量 或者说 newCapacity的容量是基于oldCapacity扩容50%容量 (在初始化的时候这里是没有任何元素的哦)int newCapacity = oldCapacity + (oldCapacity >> 1);//前面的初始化容量10就是为这个判断进行准备的,所以这里就是真正初始化elementData的大小了if (newCapacity - minCapacity < 0) {newCapacity = minCapacity;}//如果newCapacity超过了最大的容量限制,就调用hugeCapacity,也就是将能给的最大值给newCapacityif (newCapacity - MAX_ARRAY_SIZE > 0) {newCapacity = hugeCapacity(minCapacity);}//实际进行数组扩容啦elementData = Arrays.copyOf(elementData, newCapacity);}
/*** 这个就是上面用到的方法,很简单,就是用来赋最大值** @param minCapacity* @return*/private static int hugeCapacity(int minCapacity) {if (minCapacity < 0) {throw new OutOfMemoryError();}//如果minCapacity都大于MAX_ARRAY_SIZE,那么就Integer.MAX_VALUE返回,反之将MAX_ARRAY_SIZE返回。 //Integer.MAX_VALUE:2147483647 MAX_ARRAY_SIZE:2147483639 也就是说最大也就能给到第一个数值。还是超过了这个限制,就要溢出了。相当于arraylist给了两层防护。 return (minCapacity > MAX_ARRAY_SIZE) ?Integer.MAX_VALUE :MAX_ARRAY_SIZE;}
/*** 添加元素到指定下标位置中** @param index* @param element*/public void add(int index, E element) {//验证index的合法性rangeCheckForAdd(index);//跟上面分析的一样,具体看上面如何分析的ensureCapacityInternal(size + 1);//这个方法就是用来在插入元素之后,要将index之后的元素都往后移一位System.arraycopy(elementData, index, elementData, index + 1,size - index);//在目标位置上存放元素elementData[index] = element;//size增加1size++;}
/*** 验证Index下标是否越界* @param index*/private void rangeCheckForAdd(int index) {//如果index超过实际数组大小 || 下标小于0 直接返回下标越界异常if (index > size || index < 0) {throw new IndexOutOfBoundsException(outOfBoundsMsg(index));}}
/*** 下标越界提示** @param index* @return*/private String outOfBoundsMsg(int index) {return "Index: " + index + ", Size: " + size;}
public boolean addAll(Collection<? extends E> c) {//将集合数据 转为 数组数据Object[] a = c.toArray();//numNew为数组的长度int numNew = a.length;//确认是否扩容,这个方法可以先看add是如何分析的ensureCapacityInternal(size + numNew);/**** 主要用来移动元素的,这也就是为什么arrayList使用增删的时候效率低的原因** 五个参数意思:* Object src:源对象* int srcPos:源对象对象的起始位置* Object dest:目标对象* int destPos:目标对象的起始位置* int length:从起始位置往后复制的长度。 */System.arraycopy(a, 0, elementData, size, numNew);//更新元素数据长度size += numNew;return numNew != 0;}
public E remove(int index) {//检查下标合理性,rangeCheck方法前面分析过了,这里就不分析了。 rangeCheck(index);//这个作用很多,比如用来检测快速失败的一种标志。 modCount++;//根据下标获取数据E oldValue = elementData(index);//计算移动的位数int numMoved = size - index - 1;if (numMoved > 0) {//主要用来移动元素的System.arraycopy(elementData, index + 1, elementData, index,numMoved);}//将--size上的位置赋值为null,让gc(垃圾回收机制)更快的回收它。 elementData[--size] = null;//返回删除的元素。 return oldValue;}
//感觉这个不怎么要分析吧,都看得懂,就是通过元素来删除该元素,就依次遍历,如果有这个元素,就将该元素的索引传给fastRemobe(index),使用这个方法来删除该元素,//fastRemove(index)方法的内部跟remove(index)的实现几乎一样,这里最主要是知道arrayList可以存储null值public boolean remove(Object o) {if (o == null) {for (int index = 0; index < size; index++)if (elementData[index] == null) {fastRemove(index);return true;}} else {for (int index = 0; index < size; index++)if (o.equals(elementData[index])) {fastRemove(index);return true;}}return false;}
public boolean removeAll(Collection<?> c) {//判断传入的元素是否为nullObjects.requireNonNull(c);//批量删除return batchRemove(c, false);}
//该方法用于其他两个方法中,一个removeAll():它只清楚指定集合中的元素,retainAll()用来测试两个集合是否有交集。private boolean batchRemove(Collection<?> c, boolean complement) {//将原数组数据 赋值给 elementData 变量final Object[] elementData = this.elementData;//定义两个临时变量 r用来控制循环,w是记录有多少个交集int r = 0, w = 0;boolean modified = false;try {//循环size长度的次数for (; r < size; r++)//参数中的集合C一次检测集合A中的元素是否有//判断参数中的集合C是否包含//判断elementData[r]下标的数据在参数C集合中是否存在,如果存在就将elementData[r]下标的值存放到elementData[w++]数组下标位置中if (c.contains(elementData[r]) == complement)elementData[w++] = elementData[r];} finally {// Preserve behavioral compatibility with AbstractCollection,// even if c.contains() throws.//如果contains方法使用过程报异常if (r != size) {//将剩下的元素都赋值给集合ASystem.arraycopy(elementData, r,elementData, w,size - r);w += size - r;}if (w != size) {// clear to let GC do its work//这里有两个用途,//在removeAll()时,w一直为0,就直接跟clear一样,全是为null。 //retainAll():没有一个交集返回true,有交集但不全交也返回true,而两个集合相等的时候,返回false,//所以不能根据返回值来确认两个集合是否有交集,而是通过原集合的大小是否发生改变来判断,如果原集合中还有元素,则代表有交集,而元集合没有元素了,说明两个集合没有交集。 for (int i = w; i < size; i++)elementData[i] = null;modCount += size - w;size = w;modified = true;}}return modified;}
//清除集合中所有的数据public void clear() {//这里就是一种安全机制,下面会分析它modCount++;//这里就是遍历集合的所有数据,将他们的下标值全部置为NULL,等待GC回收掉内存for (int i = 0; i < size; i++)elementData[i] = null;size = 0;}
//该方法的作用在于,将指定下标的值进行替换public E set(int index, E element) {//上方有分析到,该方法就是检查下标的合法性的rangeCheck(index);//从元素数组中获取数据E oldValue = elementData(index);//将数据替换到指定下标中elementData[index] = element;return oldValue;}
//该方法的作用在于,从元素数组中查找数据的下标位置(其实就是查找数据是否存在啦)public int indexOf(Object o) {//查找元素为Nullif (o == null) {// 遍历数组,找到第一个为空的元素,返回下标for (int i = 0; i < size; i++)if (elementData[i]==null)return i;} else {//查找元素不是为NUllfor (int i = 0; i < size; i++)// 遍历数组,找到第一个和指定元素相等的元素,返回下标if (o.equals(elementData[i]))return i;}//没有找到直接返回-1啦return -1;}
public E get(int index) {//检查index的合法性rangeCheck(index);//从元素数组下标中获取数据return elementData(index);}
public E get(int index) {rangeCheck(index);return elementData(index);}
最后来聊聊fail-fast快速失败机制和modcount
fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
FastFailTest中通过 new ThreadOne().start() 和 new ThreadTwo().start() 同时启动两个线程去操作list。
ThreadOne线程:向list中依次添加0,1,2,3,4,5。每添加一个数之后,就遍历整个list。
ThreadTwo线程:向list中依次添加10,11,12,13,14,15。每添加一个数之后,就遍历整个list。
当某一个线程遍历list的过程中,list的内容被另外一个线程所改变了;就会抛出ConcurrentModificationException异常,产生fail-fast事件。
modCount:其实就是一种安全机制 每add 或 remove的时候就会进行加1,其实简单理解,可以认为这个就是乐观锁(版本号机制啦),当多个线程操作集合数据的时候, 一个线程在查询数据,一个线程在修改数据,就导致数据不一致的发生,当出现这种情况就会触发 fail-fast机制
总结
1.ArrayList集合是允许存放NULL值的
2.ArrayList集合本质上就是一个元素数组
3.ArrayList集合与数组的区别在于ArrayList可以自动进行扩容
4.ArrayList集合实现了RandomAccess接口,也就意味着使用for循环效率会更高
5.ArrayList集合底层是采用的数组进行存储数据,那么它的查询速度会很快,但是添加或删除数据,性能则会下降很多。
本文参考:https://www.cnblogs.com/zhangyinhua/p/7687377.html
我是黎明大大,我知道我没有惊世的才华,也没有超于凡人的能力,但毕竟我还有一个不屈服,敢于选择向命运冲锋的灵魂,和一个就是伤痕累累也要义无反顾走下去的心。
如果您觉得本文对您有帮助,还请关注点赞一波,后期将不间断更新更多技术文章

●
●
●
●
●
●
●
以上是关于JAVA集合之ArrayList源码分析的主要内容,如果未能解决你的问题,请参考以下文章