分库分表思路&实现(轻量级框架)
Posted 绘空事J
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分库分表思路&实现(轻量级框架)相关的知识,希望对你有一定的参考价值。
随着企业数据库存量数据的逐渐增加,传统的单点数据库逐渐开始无法支撑,通常我们会采用读写分离、分库分表来解决数据库瓶颈问题。这篇文章带你了解企业为什么要分库分表,实现方式和分库分表后常见的问题。
章节一 分库分表是什么?
一、1 为什么要分库分表?什么时候拆分?
单机型的数据库很容易成为整体服务的瓶颈
1.连接数瓶颈
在高并发场景下,单点环境下无法支撑大量SQL连接。
2.磁盘IO、CPU瓶颈
在1000w条数据左右时mysql的B+树基本只需要3-5次磁盘IO就能定位数据,而数据量再增加则会额外增加磁盘IO次数。
3.网络IO瓶颈
在并发场景下,存在大字段查询,容易造成网络IO瓶颈。
一、2 拆分维度?
1.垂直拆分
垂直拆分实际上就是简单的逻辑拆分,如下图所示。
优点:
A.业务解耦,可以用微服务治理。
B.垂直拆分使用多台服务器CPU、IO、内存提升性能。
C.可以实现冷热数据分离。
缺点:
A.业务表间无法join,只能通过聚合,增加开发难度。
B.单库的数据量增大后依旧无法解决问题。
C.分布式事务问题。
2.水平拆分
水平拆分又分库内拆分和分库分表,通常我们使用分库分表。
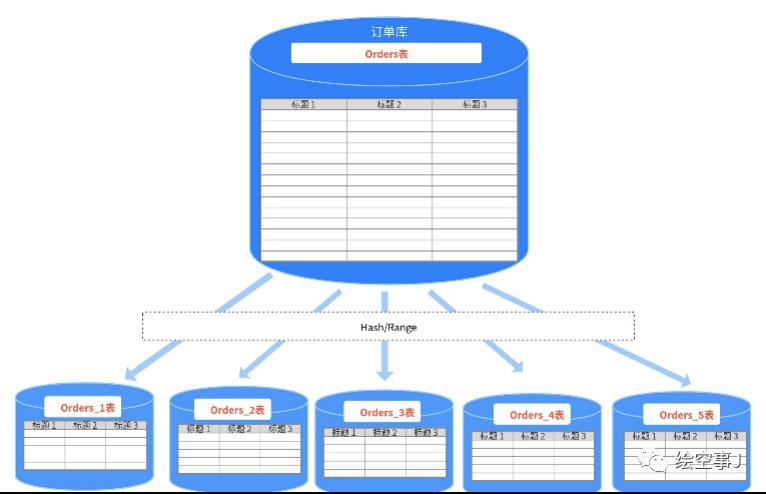
优点:
A.优秀的可扩展性
B.较好的应对高并发,通过分区键打散数据
缺点:
A.需要数据库路由,不带分区键查询会产生广播SQL
B.跨库join性能较差
C.分布式事务问题
一、3 分布式数据库选型?
1.分库分表组件:ShardingSphere,mycat,dble
2.自身自带分布式的数据库:Pgsql、tidb
3.大数据领域:hive、hbase、es
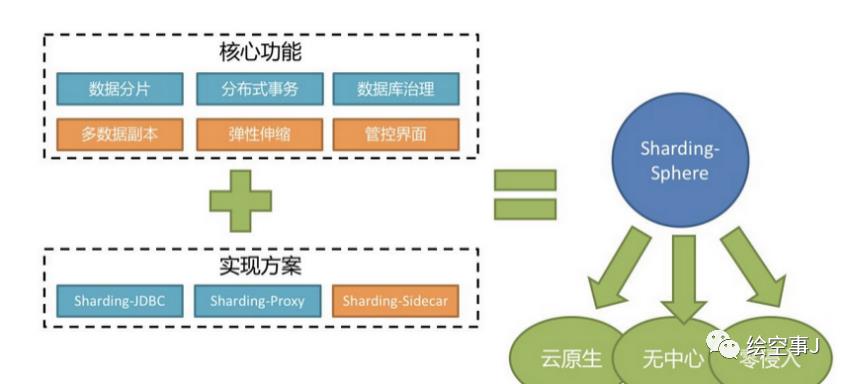
章节二 ShardingSphere分库分表
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库
二、1 客户端拆分Sharding-JDBC
简介:
sharding-jdbc 定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
使用:
通过application.properties配置分库策略、分表策略、分片算法、读写分离来控制。网上有很多介绍的,比如:https://blog.csdn.net/u013982921/article/details/94006668
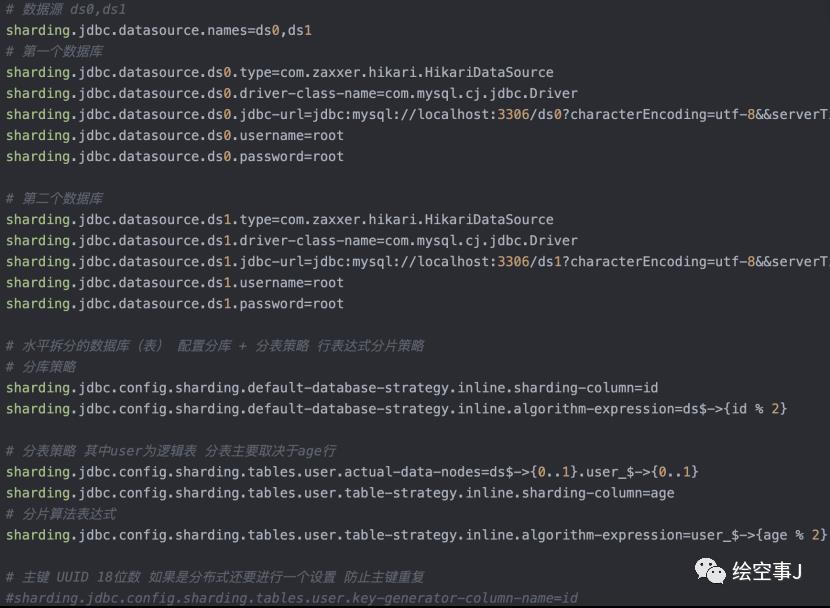
下图规则为
1.分库策略:用id奇偶进行分库,分2个库
2.分表策略:用age奇偶进行分表,分2个表
二、2 服务器拆分Sharding-Proxy
简介:
Sharding-Proxy是一个分布式数据库中间件,定位为透明化的数据库代理端。作为开发人员完全可以把它当成数据库,而它具体的分片规则在Sharding-Proxy中配置。需要独立部署。
使用:
网上有很多介绍的,比如:
https://www.cnblogs.com/boboooo/p/13344928.html
章节三 分库分表后常见问题
1.非分片键查询
抛出问题:
上文介绍,数据库分库分表通常都是基于某个分片键比如通过id、age进行分库分表。那么如果现在需要查询一笔数据基于userName来查询怎么办呢?如果不做特殊处理,sharding-jdbc会通过线程池广播到各个库和表进行数据查询后再聚合数据。执行效率非常不理想。
解决方案:
遇见这种问题通常采用牺牲空间来提高速度,即继续通过userName建立异构索引表。如下图每次查询的时候通过带有分片键的Buver_ID找到自己实际订单数据的表目录。流程如下图所示
优化方案:
阿里有一款精卫平台可以通过抽取Mysql日志binlog作为事件实现异构索引表。
2.跨分片键查询
分库分表后不建议使用跨分片查询,查询效率慢。
通过线程池并发请求到所有符合路由规则的目标分表,然后对所有结果进行归并。需要说明的是,当路由结果只有1个,即不跨分片操作时sharding-sphere不会通过线程池异步执行,而是直接同步执行,这么做的原因是为了减少线程开销,核心源码在ShardingExecuteEngine.java中)。
3.模糊查询
上面提到的都是条件中有sharding column的SQL执行。但是,总有一些查询条件是不包含sharding column的,同时,我们也不可能为了这些请求量并不高的查询,无限制的冗余分库分表。那么这些条件中没有sharding column的SQL怎么处理?
这种条件查询相对于有sharding column的条件查询性能很明显会下降很多。如果有几十个,甚至上百个分库分表,只要某个表的执行由于某些因素变慢,就会导致整个SQL的执行响应变慢,这非常符合木桶理论。
更有甚者,那些运营系统中的模糊条件查询,或者上十个条件筛选。这种情况下,即使单表都不好创建索引,更不要说分库分表的情况下。那么怎么办呢?这个时候大名鼎鼎的elasticsearch,即es就派上用场了。将分库分表所有数据全量冗余到es中,将那些复杂的查询交给es处理。
4.分布式事务
当使用了分库分表以后,程序的数据库连接池会涉及多个数据库,spring提供的@transactional注解无法保证数据的事务一致性。此时就涉及到了分布式事务,常用的分布式事务解决方案有,详细可以看看笔者的另一篇关于分布式事务的文章:
1.基于XA协议的2PC、3PC
2.基于补偿机制的TCC
3.基于rocketmq的事务消息
参考文案:
非分区键查询:
https://blog.csdn.net/sinat_29774479/article/details/107555322
官网:https://shardingsphere.apache.org/
分库分表详解:
https://blog.csdn.net/u013982921/article/details/94006668
分库分表技术演进&最佳实践:
https://mp.weixin.qq.com/s/3ZxGq9ZpgdjQFeD2BIJ1MA
企业IT架构转型之道:阿里巴巴中台战略思想与架构实战
以上是关于分库分表思路&实现(轻量级框架)的主要内容,如果未能解决你的问题,请参考以下文章