HDFS 实践 | 京东 HDFS EC 应用解密
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS 实践 | 京东 HDFS EC 应用解密相关的知识,希望对你有一定的参考价值。
为了实现降本增效,京东HDFS 团队在 EC 功能的移植、测试与上线过程中,基于自身现状采取的一些措施并最终实现平滑上线。同时自研了一套数据生命周期管理系统,对热温冷数据进行自动化管理。在研发落地过程中还构建了三维一体的数据校验机制,为 EC 数据的正确性提供了强有力的技术保障。
本文详细介绍在研发一个复杂系统时,如何基于实际情况进行取舍,并确立行动准则。在功能上线过程中,要保持对线上系统的敬畏,确保上线与回滚不会导致元数据损坏。此外,要深刻认识系统的核心职责,对于存储系统务必加强技术保障,确保数据的安全与可靠,不能丢不能错。
数据作为京东数智战略的重要资产,随着业务的持续增长,大数据平台存储的数据量已突破 EB 级别,并且还在以每天将近 PB 的速度持续增长。传统的方法是分析数据的使用频率,把数据分为热温冷三类数据。对于温冷数据,使用压缩率更高的算法,来降低存储成本。但是无法突破三副本存储策略的固有属性:需要存储三份完整的数据块。
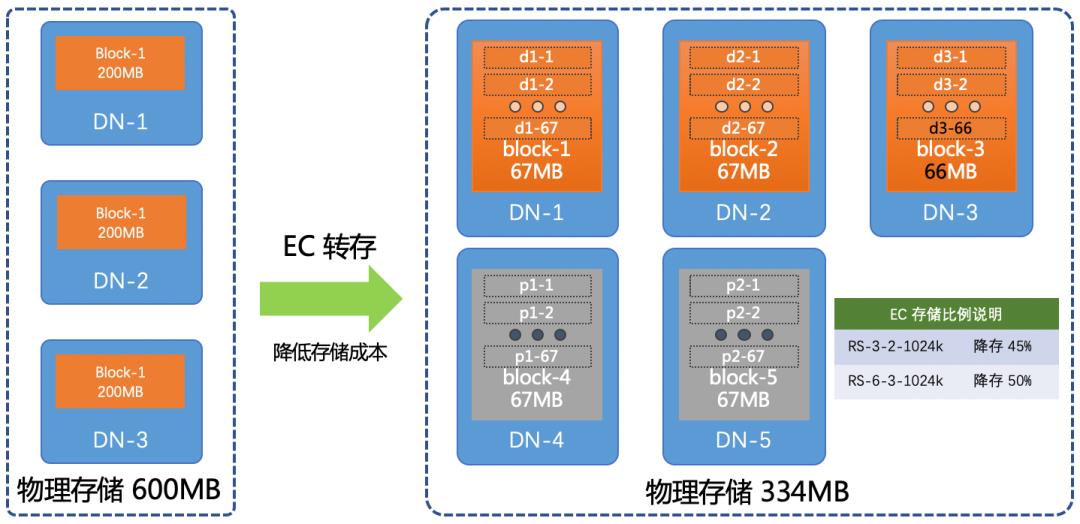
Hadoop 分布式存储引擎(HDFS)在 3.0 版本中发布了 EC inside HDFS 重要特性。该 EC(Erasure Coding) 是一种可通过计算降存储的技术。下面我以 HDFS 支持的一种 EC 存储策略 RS-3-2-1024k 为例简单介绍其原理。对于一个 200MB 的文件,会把数据按 1MB(1024KB) 一个条带(striped)进行切分,每切分出 3 个 1MB 的数据块条带(data striped,记为 d1-1,d2-1,d3-1),就用这 3 个数据块条带计算出两个 1MB 的校验块条带(parity striped,记为 p1-1, p2-1),依次循环处理,最后的 2MB 数据只能构成 2 个数据块条带(d1-67,d2-67),EC 算法会构建一个全零的假数据块(d3-67)计算出最后两个校验块条带(p1-67,p2-67)。实际存储在 DN 上的 5(3 个数据块加 2 个校验块) 个 EC 数据块分别由(d1-1..d1-67, d2-1..d2-67, d3-1..d3-66, p1-1..p1-67, p2-1..p2-67)组合成的数据块。如果丢失其中任意两个数据块,都可以使用剩下的 3 个块算出丢失的两个块。
一个 200MB 的文件按三副本方式存储,需要在不同 DN 上存放 3 份完整的数据块,消耗600MB的存储空间。而 RS-3-2-1024k只需要 334MB的存储空间,就能保证数据的冗余度,并且存储空间降低了 45%。
因此,我们可以借助 EC inside HDFS 技术进一步降低数据存储成本,提高存储效率。
要把 EC 技术应用到生产环境,需要对我们的生产系统进行改造升级。首先,需要让生产代码支持EC 功能,我将在第一部分分析我们采用升级还是移植的权衡,以及遵循的原则。然后,介绍我们在改造过程中,通过哪些方法和技术来保障项目质量的。改造过程中涉及元数据方面的改动,因此上线需要格外注意,否则会导致数据难以恢复,在第三部分我会介绍线上系统的平滑升级方法与回滚的可行性。
我们运用 EC 的目的是存储温冷数据。对于热温冷数据,我们需要一套方案让数据在这三种场景中流转。我会在第四部分解密我们的数据生命周期管理系统。
作为数据存储平台,我们的首要职责是保证数据的安全可靠性,不能把用户的数据弄丢了,也不能把数据存错了。特别是 EC 这种基于计算的存储技术,尤为需要注意数据的完整性。在最后一部分会阐述我们在 EC 数据完整性方面所做的努力。
我们从 2015 年开始基于社区 2.7.1 版本,构建京东大数据生态系统,作为大数据平台的最底层基础系统,服务着成百上千个业务。
HDFS EC 是 3.0 版本正式发布的一个重要特性,为了支持 EC 做了大量的修改,接口也发生了较大变化。此外 3.0+ 版本还在一直迭代,存在不少缺陷,正式上线前还需要解决一些额外的接口兼容问题,会影响项目进度。再加上这几年我们基于 2.7.1 版本,做了大量的功能开发与性能优化,才能支持当前单集群万台规模的存储集群。因此我们采用移植 EC的方案。
社区EC相关的两个父任务:HDFS-7285、HDFS-8031 以及相关的 bugfix,加起来差不多300多个patch。同时,我们的移植目标版本是2.7.1,而patch是相对3.0的。如果围绕patch进行移植,我们要把3.0 相对2.7.1相关的前驱patch先移植过来,而这带来的工作量是巨大并且无法估量的。
面对如此复杂的存储系统,在开始移植前,需要确立一套移植方案和移植原则:
-
-
移植过程中,尽可能的保持社区代码原有样式,以便于后续apply patch。
-
-
-
-
对于目前不移植或者为了简化移植工作而去掉的代码,一定不能影响现有场景的功能,并用TODO标识未来会修改。
参与移植工作的开发人员都是非常有经验的,对HDFS的整体架构比较清楚,才能保证移植的效率。经过一个多月的努力,完成了移植工作并跑通所有HDFS相关测试用例。
这么庞大的工程,如果仅靠单元测试来验证,显然大家是不放心的,所以在启动 EC 项目时,QA 团队就参加进来,展开了自动化集成测试工作,主要目的是保证:
-
移植工作不能改变原有接口和命令行语义,甚至接口和命令行的返回信息也要确保与 2.7.1 版本一致。
-
一般的集群运维操作能够正常进行,比如 DN 节点上下线,NN 升级与回退。
-
在破坏性测试中,集群的健壮性不受影响,比如磁盘故障,网络异常,数据损坏。
-
验证集群兼容性,NN/DN/JN 逐步升级和回退不能影响集群的服务能力。
-
校验数据正确性,在测试过程中要保证 EC 数据没有被损坏,丢块后重建的数据是正确的。
-
性能对比测试,引入 EC 功能后,通过压测对比,确保集群,特别是 NN,性能不受影响。
为了适应千变万化的测试需求,我们定制了一套自动化测试系统。运用 ansible 编写了集群搭建系统,实现组件(NN/DN/JN),操作(安装、卸载、启动、停止、配置、切换、初始化),安装包,主机,配置修改等的参数化。测试人员能够灵活组合各种参数操作测试集群,实现测试目的。
在功能冒烟测试和回归测试中,使用 pytest 编写了 HDFS 测试框架和接口用例,以及数据校验用例等。方便构建测试数据集,按需执行测试用例,搜集测试用例的输出并对比历史数据,获取集群 JMX 指标验证正确性。
通过集成 Jenkins/Docker/makefile 等工具,贯通从开发人员提交代码,到自动化编译,到部署测试集群,再到冒烟测试并返回测试结果,一套完整的自动化测试流程。
完成功能开发,测试也做的差不多之后,接下来就该上线了。但是上线不是换个包重启下就完事了,否则集群很可能由于一些故障和兼容性问题,导致数据损坏。因此上线要支持回退,还要在升级YARN、客户端等生态系统后,能写EC文件,同时集群还能像以前一样工作,尽可能不影响用户的使用习惯。下面我详细介绍一下 NameNode(NN) 和 DataNode(DN) 的升级过程。
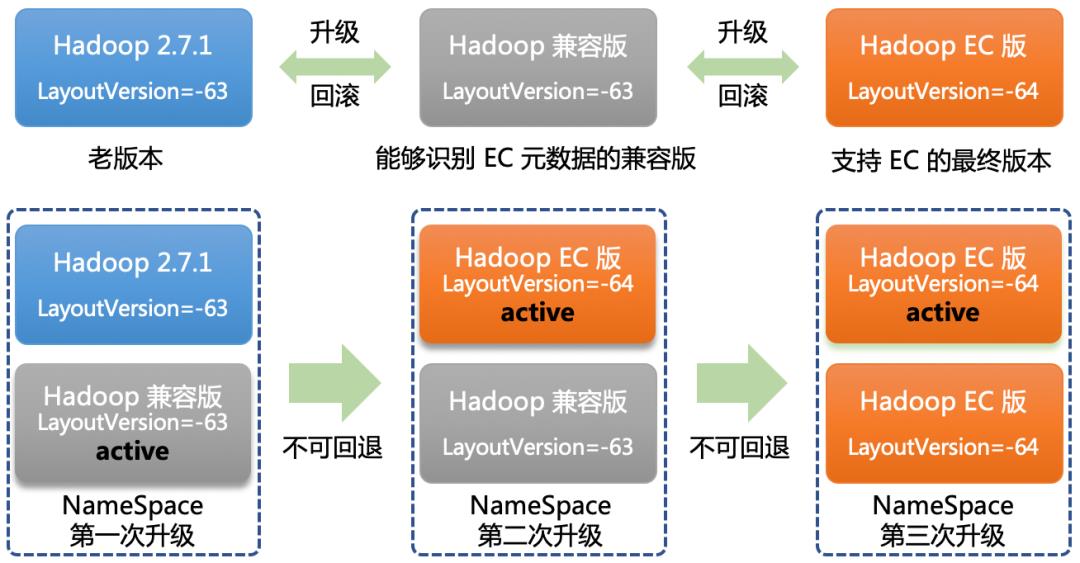
为了支撑不停服务升级,就需要依赖 HDFS 集群的高可用(HA)特性。在两台 NN(Active/Standby) 滚动升级或回滚过程中,首先需要识别出 Active/Standby间的元数据兼容问题,然后逐个进行兼容性改造。
如 Editlog文件和 AddCloseOp方法中为表示当前版本支持 EC, LayoutVersion 被设置为 -64。如果使用 -64 写 Editlog会导致 NN回滚后不认识 -64 而起不来。我们的处理办法是在升级完成前,把LayoutVersion设置为老版本-63,但是内部代码可以识别 EC 元数据。还有 FsImage 文件中新增了ErasureCodingSection,需要先改造原有的老版本,保证老版本能处理新版本回传的 FsImage 文件,否则会导致 NPE 异常。
INode整体格式没有太大变化,只是重新定义了表示 replication的12bit字段。replication字段的高位为1时后边的11位表示EcPolicyId。而高位为0,后续的11位表示副本。这个变化其实没有修改布局,因此无需特殊处理。
通过一些兼容性改造,我们发布了一个过渡性质的兼容性版本,可以识别 EC 相关元数据,但是不支持读写 EC 文件。这样可以确保每次上线都是可以回滚到前一个版本,但不要求能回滚到之前的历史版本。具体升级流程:
1. 第一次使用兼容版本升级一台standby状态的NN(LayoutVersion=-63), 并切换为active,测试运行一段时间,验证该节点服务正常。如果服务有预料之外的问题,或者性能有所下降,都可以随时进行 Active/Standby切换,并将Standby 节点回滚为老版本。
2. 第二次直接将standby节点的老版本升级到支持EC功能的新版(LayoutVersion=-64,也就是支持写EC文件),并切换为active。如果出现问题,都可以随时进行 Active/Standby切换,使用到第 1步中已经稳定运行一段时间的 NN(LayoutVersion=-63) 作为 Active 节点。
3. 第三次使用支持EC功能的新版替换第 1 步中升级的 NN。
至此,线上的服务就平滑由2.7.1升级为支持EC的HDFS了。整个过程经历3次升级,对外没有中止服务,外界无感知,并且整个过程是支持逐步回退。因此这个升级过程可以应用到生产环境。
说完NN上线,接下来再讨论一下DN滚动上线。首先,解释下为什么要滚动升级DN(支持读写 EC块, 记为 DN(EC))。第一个很显然的原因是为了保证 HDFS的可用性,不影响用户读写副本文件;另外一个很重要的原因是想在线上验证 EC 功能的同时限制 EC 的故障域。
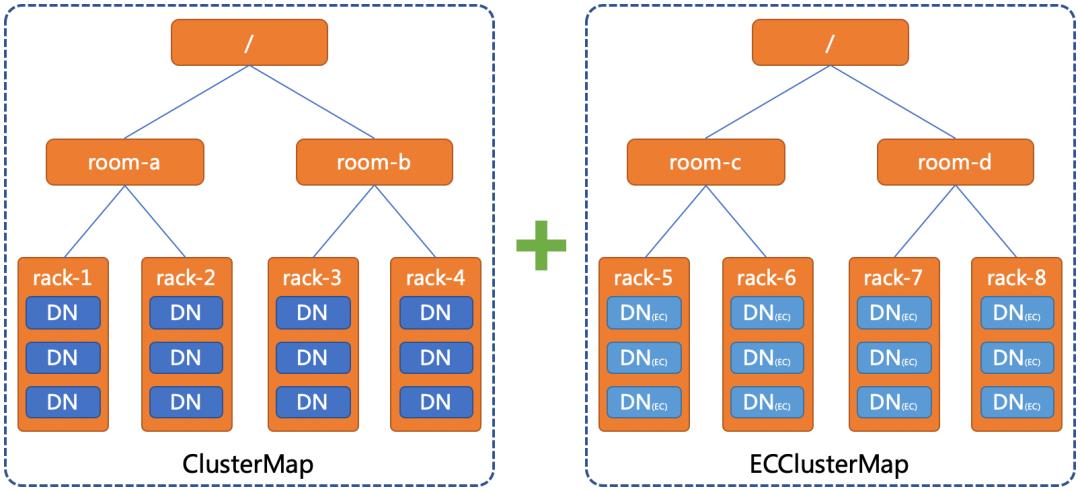
客户端调用addBlock选择DN去写块时,现有的选块策略无法给用户返回DN(EC),因此会出现写失败。通过在NN上新增ECClusterMap,构建一棵
由 DN(EC) 组成的拓扑树。
经过改造后,当客户端想要写 EC 文件,选块策略会从ECClusterMap中选取目标节点,就可以解决DN滚动升级过程中不支持 EC 写入的兼容性问题,同时也可以在线上环境中小范围验证 DN 中 EC 功能的稳定性。
业界使用 DistCp或用 Hive 创建新表的方式把数据转换为 EC 存储。这个方案需要分别运维一套 YARN 集群和任务调度系统,并存在一些不足:
-
在不修改 NN的前提下,任务调度系统无法实时转换新增数据。
-
-
-
如果把转换后的数据移到源目录时,没法进行原子交换,用户程序会在此间隙抛出找不到文件的异常。
-
此外,HDFS 为目录和文件设置了用户组权限以及时间戳,对所有数据进行拷贝时,需要给拷贝程序赋超级权限,会引入一定的安全风险,现有方案也不能保证转换后的文件和原始文件属性保持一致。
我们实现了一套基于数据生命周期的温冷数据转存管理系统, 来解决现有方案的不足。在 NN 内部启动一个数据转换管理器,周期扫描待转换文件, 把转换任务封装成 FileConvertCommand,然后借助转换任务均衡器(ConvertTaskBalancer)选择一个 DN, 把FileConvertCommand加入到这个 DN 的待转换队列中。当 DN心跳过来时,会从待转换队列中领取一定数量的任务回去处理。详见下图。
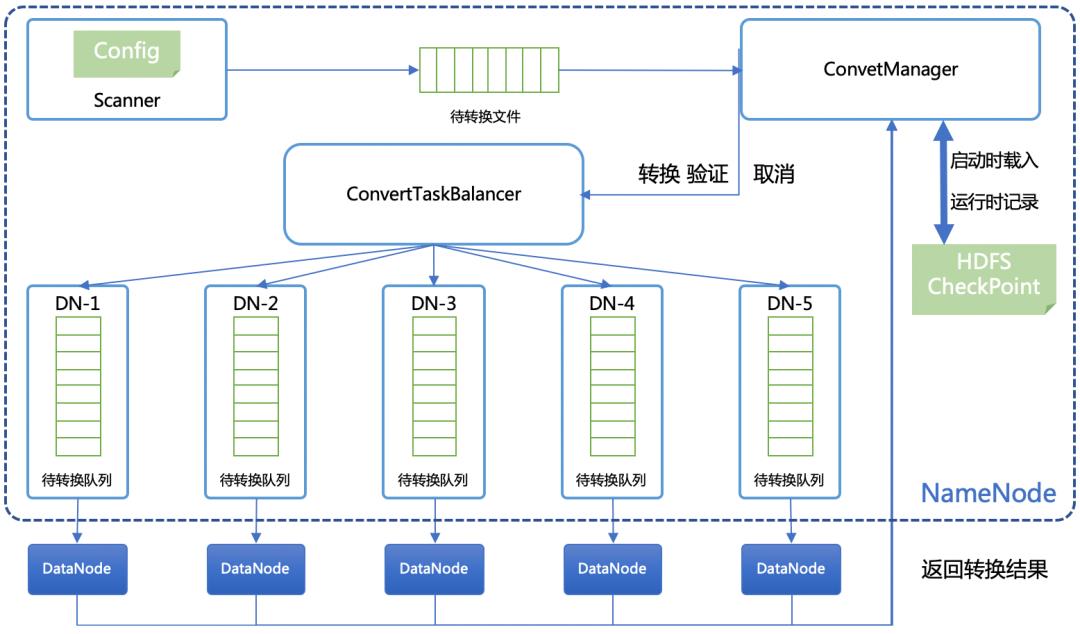
无论转换任务是否成功,DN都会通过心跳告知 NN 处理结果。当收到文件转换成功的响应,NN 读取原始文件的属性,包括用户组、时间戳、扩展属性等,设置转换后的 EC 文件。然后借助一个临时目录,对原始副本文件加读锁,并移动到临时目录,然后再把转换后的 EC 文件移动到原副本文件目录,实现副本文件和 EC 文件的原子性交换。如果这个过程没有异常发生,会在 checkpoint 中加一条操作日志。如果发生异常,把原始副本文件移回原目录,然后把该任务加入到待转换队列进行重做。
在转换执行过程中,允许人为中断。在转换功能异常的情况下,要确保文件不能被损坏, 服务不能中断。NN 侧通过 checkpoint记录操作日志,并存放在 HDFS 系统中,确保转换过程的幂等性。通过转换任务均衡器把转换任务均匀的分布到不同的 DN,避免热节点导致集群性能下降。DN 侧通过超时机制快速终止异常转换任务,释放资源处理下一个转换任务。
通过以上手段,我们可以让 HDFS 集群不依赖任何其它系统独立完成数据转换,并能对新增数据进行实时转换,利用容错机制确保数据不会被重复转换或漏转,提供了丰富的策略对待转换数据进行过滤,使用原子性操作为用户提供不间断服务,不修改转后的文件属性确保转换对于用户是透明的。
后来,我们对这套数据生命周期管理系统进行了抽象扩展,相当于在 HDFS 内部构建了一套调度系统。除了可以支持温冷数据转换,还可以对数据进行比对校验,甚至连数据清理工作也可以由这套系统进行调度。
HDFS-14768, HDFS-15186 还有 HDFS-15240是同行和我们在使用 EC 过程中发现导致数据损坏的情况,可见使用新兴的 EC 存在极大的数据损坏风险。正因如此,我们设计了文件级别和数据块级别的多重校验机制。
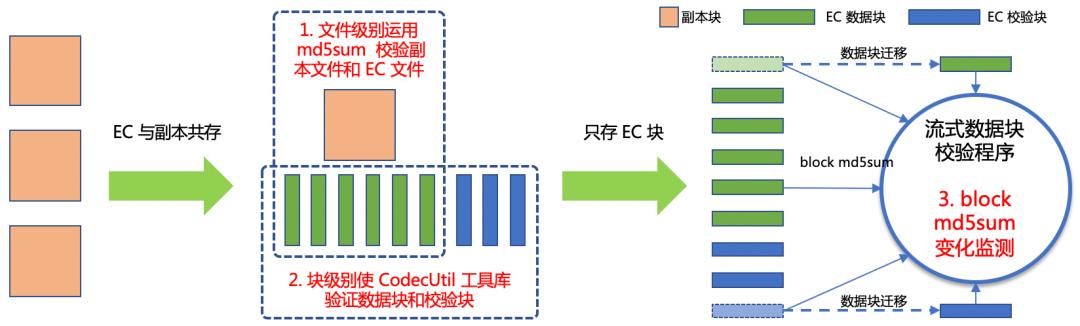
对于文件,在转换初期,我们使用 EC 与副本混合存储的策略,周期性的比对并恢复数据块,保障数据的完整性。通过在数据生命周期管理服务中,扩充 FileConvertCommand,支持数据验证模式。在上文提到的数据转换过程中,把副本文件转换为 EC 存储后,会立即使用 md5sum比对副本和 EC 文件内容,确保转换的正确性。
EC 文件的数据块组分为数据块与校验块两部分。客户端读取 EC 文件时,一般情况下只需要读取数据块部分。因此,在比对副本文件与 EC文件时,无法校验 EC 文件的校验块部分。为此,我们在文件内容比对过程中,还加入了数据块级别的验证。调用 BlockReaderFactory 获取 EC(RS-6-3-1024k) 块组中的数据块(d1-d6)与校验块(p1-p3)内容,再使用 EC 工具库中的 CodecUtil.createRawDecoder 随机选取 EC 块组中(d1,d2,d4,d5,p1,p3)计算其它块(d3’,d6’,p2’),再与前面读取到的(d3,d6,p2)块内容比对。
经过以上两轮比对,数据转换的结果可以保证完全无误。但是这种数据校验成本很高,我们不可能在很短的周期内,重新校验所有的数据文件。另外,副本文件不可能一直存留在集群中,否则使用EC 降存的意义也就不存在了。
为此,我们基于流式计算构建了一套实时的数据块级别的检测机制。具体流程是检测到数据块在节点间发生迁移(块重建,复制或是 balancer 都会导致块在节点间迁移),会计算新数据块的 md5sum, 并与旧数据块 md5sum 进行比对,当数据块 md5sum 发生变化后,通知集群维护人员进行处理。这套实时数据检测机制减少了数据校验成本,同时提高了时效性。
在这三维一体的数据校验与检测机制的保驾护航下,我们的 EC 功能成功上线到生产环境。经历了机房迁移、数据节点升级、618 和双十一的考验。到目前为止运用 EC 存储了上百PB 温冷数据,为公司节省上千台服务器成本。
在如此庞大的生产系统改造工程中,我们踩了不少坑。例如,HDFS 命令行输出发生变更,导致用户程序无法识别新增内容报错;修改Hadoop版本号后,一些 Hive 应用使用正则表达式解析 Hadoop版本号报错;由于接口变化导致 TeraSort 无法运行;要先改造老版本 NN,增加 BlockReportLeaseManager,否则新版本的 DN 无法向老版本的 NN 进行全量块汇报。这是我们趟过的比较典型的坑,主要是代码兼容,Hadoop 生态兼容的一些事项。
在实践过程中,我们还有一些很好的经验总结和大家分享下。移植代码时,一定要移植单元测试用例,可以帮助我们避免在移植过程中的疏忽导致代码少移漏移;另外,为了与社区代码的兼容,尽量使用一些设计模式,如装饰器、工厂模式、组合模式,进行代码的改造,方便日后引入社区新功能;还有一点非常重要,在改造 RPC 接口时,务必要保证 ProtoBuf 协议的兼容性,我们在新增自定义的字段时,会预留一部分坑位应对社区代码的扩展;对于存储系统,最重要的事情莫过于数据的完整性,大家可以参考上面第五部分内容,结合自己的场景进行优化。
Hadoop 社区为我们创造了优秀的存储系统。本着人人为我,我为人人的开源精神,在项目改造过程中,
我们向社区回馈了数十个 patch。比较典型的改进如下:
-
-
HDFS-14353, 修复 xmitsInProgress 指标异常。
-
HDFS-14523, 去除 NetworkTopology 多余锁。
-
HDFS-14849, DN 下线导致 EC 块无限复制。
-
HDFS-15240, 修复脏缓存导致数据重建错误。
接下来,为了让 EC 突破温冷数据的使用场景。我们准备在生产环境使用 native 方法加速 EC 数据的编解码效率,验证功能的稳定性,并向社区回馈我们的改造。目前的 EC inside HDFS 功能已经比较稳定了,但是问题还是存在的,我们将与社区一起努力建设更加稳定的 HDFS 存储系统。
以上是关于HDFS 实践 | 京东 HDFS EC 应用解密的主要内容,如果未能解决你的问题,请参考以下文章