聊聊缓存回收策略跟缓存更新策略
Posted 心灵震撼ya
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊缓存回收策略跟缓存更新策略相关的知识,希望对你有一定的参考价值。
互联网时代的飞速发展,用户的体验度是判断一个软件好坏的重要原因,所以缓存就是必不可少的一个神器。缓存的种类有很多,需要根据不同的应用场景来需要选择不同的cache,比如分布式缓存如redis跟本地缓存如Caffeine。今天简单聊聊缓存的回收策略跟更新策略。由于笔者自身水平有限,如果有不对或者任何建议欢迎批评和指正~
回收策略
1 基于空间:
即设置缓存的【存储空间】,如设置为10MB,当达到存储空间时,按照一定的策略移除数据。
2 基于容量:
指缓存设置了最大大小,当缓存的条目超过最大大小时,按照一定的策略移除数据。如Caffeine Cache可以通过 maximumSize 参数设置缓存容量,当超出 maximumSize 时,按照算法进行缓存回收。
public static void maximumSizeTest() {Cache<String, String> maximumSizeCaffeineCache = Caffeine.newBuilder().maximumSize(1).build();maximumSizeCaffeineCache.put("A", "A");String value1 = maximumSizeCaffeineCache.getIfPresent("A");System.out.println("key:key1" + " value:" + value1);maximumSizeCaffeineCache.put("B", "B");String value1AfterExpired = maximumSizeCaffeineCache.getIfPresent("A");//输出nullSystem.out.println("key:key1" + " value:" + value1AfterExpired);String value2 = maximumSizeCaffeineCache.getIfPresent("B");//输出BSystem.out.println("key:key2" + " value:" + value2);}
3 基于时间
TTL(Time To Live):存活期,即缓存数据从创建开始直到到期的一个时间段(不管在这个时间段内有没有被访问,缓存数据都将过期)。
TTI(Time To Idle):空闲期,即缓存数据多久没被访问后移除缓存的时间。
如Caffeine Cache可以通过 expireAfterWrite跟expireAfterAccess参数设置过期时间。
public static void ttiTest() {Cache<String, String> ttiCaffeineCache = Caffeine.newBuilder().maximumSize(100).expireAfterAccess(1, TimeUnit.SECONDS).build();ttiCaffeineCache.put("A", "A");//输出ASystem.out.println(ttiCaffeineCache.getIfPresent("A"));try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}//输出nullSystem.out.println(ttiCaffeineCache.getIfPresent("A"));}
回收算法
1 FIFO: 先进先出算法,即先放入缓存的先被移除。
流程:
优点: 最简单、最公平的一种数据淘汰算法,逻辑简单清晰,易于实现
缺点: 这种算法逻辑设计所实现的缓存的命中率是比较低的,因为没有任何额外逻辑能够尽可能的保证常用数据不被淘汰掉
2 LRU
流程:
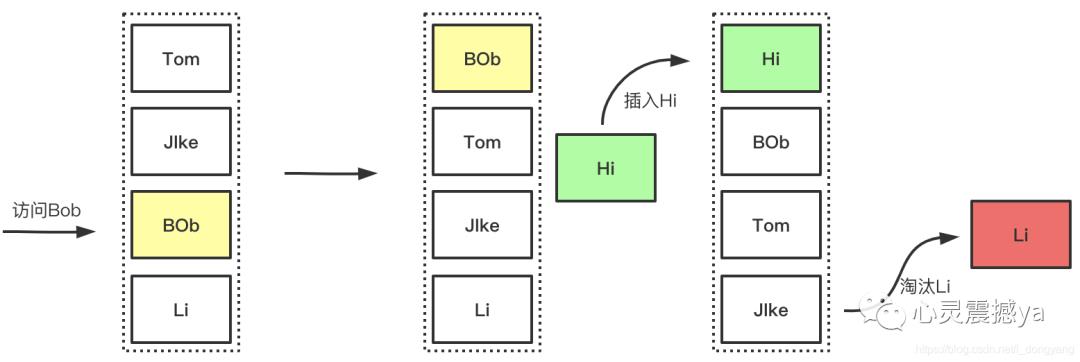
优点: LRU可以有效的对访问比较频繁的数据进行保护,也就是针对热点数据的命中率提高有明显的效果。
缺点: 对于周期性、偶发性的访问数据,有大概率可能造成缓存污染,也就是置换出去了热点数据,把这些偶发性数据留下了,从而导致LRU的数据命中率急剧下降。
3 LFU
流程:
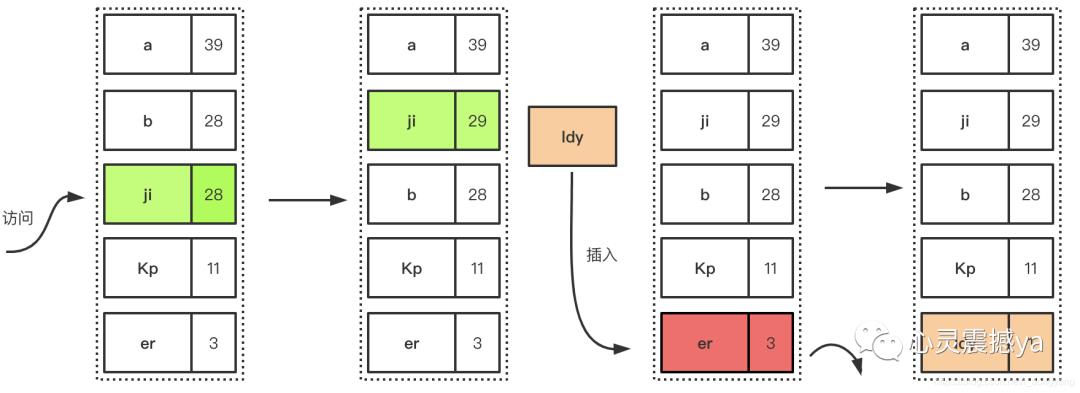
优点: LFU也可以有效的保护缓存,相对场景来讲,比LRU有更好的缓存命中率。因为是以次数为基准,所以更加准确,自然能有效的保证和提高命中率
缺点: 因为LFU需要记录数据的访问频率,因此需要额外的空间;当访问模式改变的时候,算法命中率会急剧下降,这也是他最大弊端。
4 W-TinyLFU
流程:
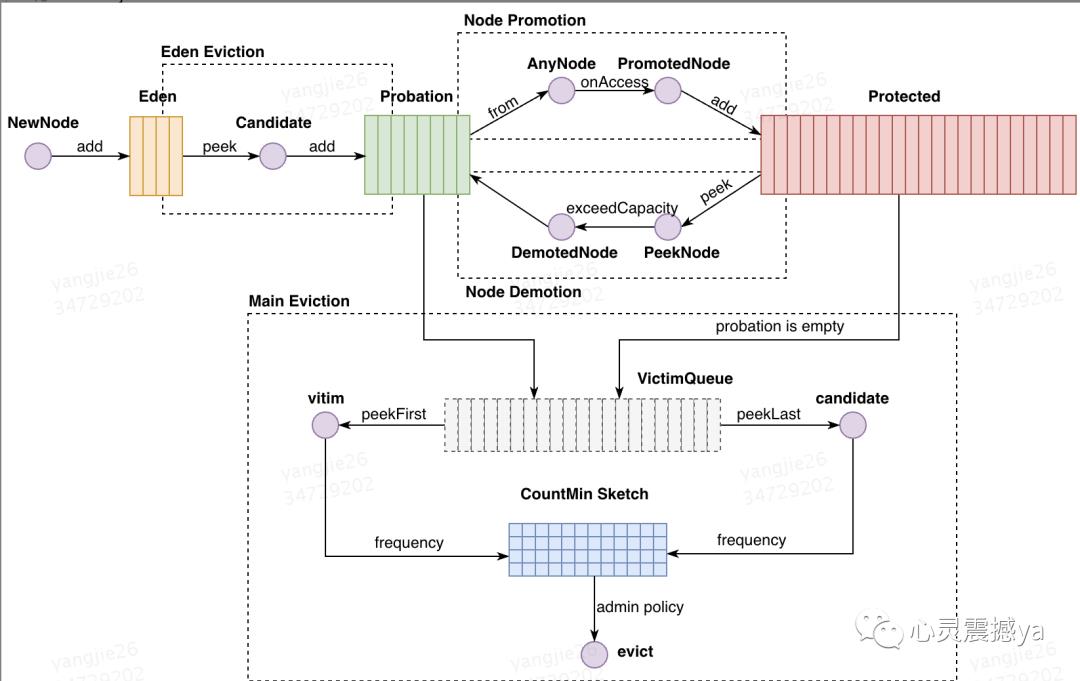
优点: 使用Count-Min Sketch算法存储访问频率,极大的节省空间;定期衰减操作,应对访问模式变化;并且使用window-lru机制能够尽可能避免缓存污染的发生,在过滤器内部会进行筛选处理,避免低频数据置换高频数据。
缺点:暂未发现
Cache-Aside
1 什么是Cache Aside Pattern
旁路缓存方案的经验实践,这个实践又分读实践,写实践。该模式对缓存的关注点主要在于业务代码,即缓存的更新,删除与数据库的操作,以及他们之间的先后顺序在业务代码中实现。
读操作:
先读缓存,缓存命中,则直接返回
缓存未命中,则回源到数据库获取源数据
将数据重新放入缓存,下次即可从缓存中获取数据
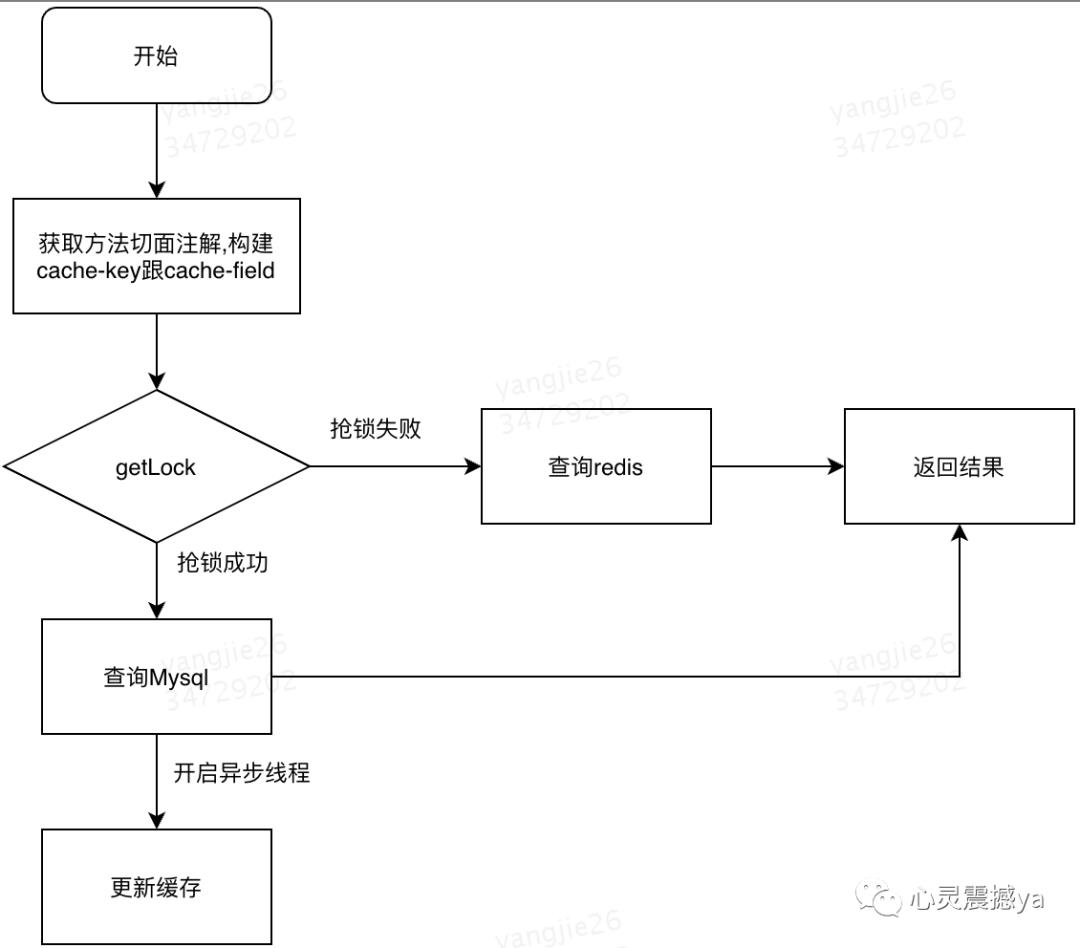
写操作:
淘汰缓存,而不是更新缓存
先操作数据库,再淘汰缓存
2 Cache Aside 为什么建议淘汰缓存而不是更新缓存
如下图所示在1和2两个并发写发生时,由于无法保证时序,此时不管先操作缓存还是先操作数据库,都可能出现:
(1)请求1先操作数据库,请求2后操作数据库
(2)请求2先set了缓存,请求1后set了缓存
3 Cache Aside 经典缓存处理切面
缓存切面抽象类
/*** @Author: yangjie* @Date: 2019-05-21 16:43* @Description:*/@Componentpublic abstract class RedisCacheAbstractAspect {protected static final String PREFIX = "AOP:";protected static final String EL_PATTERN = "#\\{([$?\\w\\.]+?)\\}";protected static final String EL_REPLACE_PATTERN = "[#\\{\\}]";@ResourceRedisUtil redisUtil;/*** 公用获取锁方法,使用setnx对key进行赋值,过期时间seconds** @return true加锁成功,false锁已存在*/protected boolean getLock(String key, int seconds) {return redisUtil.setNx(getLockKey(key), "1", seconds);}/*** 释放key对应额锁** @param keys*/protected void releaseLock(String... keys) {redisUtil.del(this.getLockKey(keys));}/*** 获取锁的key,如果以冒号结尾,添加“LOCK”,否则末尾添加“:LOCK”** @param key* @return*/protected String getLockKey(String key) {return key.endsWith(RedisConstants.REDIS_SEPARATE) ? key + "LOCK" : key + ":LOCK";}protected String[] getLockKey(String... keys) {if (keys == null || keys.length < 1) {return new String[0];} else {String[] result = new String[keys.length];for (int i = 0; i < keys.length; i++) {result[i] = this.getLockKey(keys[i]);}return result;}}/*** 通过ProceedingJoinPoint获取方法的包名*/protected String getPackageName(ProceedingJoinPoint pjp) {return pjp.getTarget().getClass().getName();}/*** 根据包名+ 类名 + 方法名 + 参数(多个) 生成Key(String存储使用)** @Param fullKey 值为true时,不使用md5压缩包名*/protected String getCacheKey(ProceedingJoinPoint pjp, String cacheField, boolean fullKey) {// 取到方法名StringBuffer function = new StringBuffer().append(pjp.getTarget().getClass().getName()).append(".").append(pjp.getSignature().getName());// 取到参数字符串StringBuffer args = new StringBuffer().append(cacheField);StringBuffer key = new StringBuffer();if (!fullKey) {key.append(DigestUtils.md5DigestAsHex(function.toString().getBytes()));key.append(":").append(args);} else {key.append(function).append(":").append(args);}return PREFIX + key.toString();}/*** 根据【包名+ 类名 + 方法名 + 参数(多个) 】生成Key(Hash存储使用)** @param pjp* @param fullKey* @return*/protected String getHashCacheKey(ProceedingJoinPoint pjp, boolean fullKey) {// 取到方法名StringBuffer function = new StringBuffer().append(pjp.getTarget().getClass().getName()).append(".").append(pjp.getSignature().getName());StringBuffer key = new StringBuffer();if (!fullKey) {key.append(DigestUtils.md5DigestAsHex(function.toString().getBytes()));} else {key.append(":").append(JSON.toJSONString(pjp.getArgs()));}return PREFIX + key.toString();}/*** 判断字符串是否为EL表达式*/protected boolean isEl(String elStr) {return !StringUtils.isEmpty(elStr) && elStr.matches(EL_PATTERN);}/*** 根据EL表达式从obj中取值** @param obj 从该实体中取值* @param name #{obj.ooo.ooo}* @param isRoot 当前是否为顶节点,为true时可以使用“#{param}”取非封装的obj值* @return* @throws InvocationTargetException* @throws IllegalAccessException*/protected static Object getterMethod(Object obj, String name, boolean isRoot) throws InvocationTargetException, IllegalAccessException {String thisField;String nextField = null;int pointIndex = name.indexOf(".");// 如果是顶层,切掉第一节 #{obj.oooo.oooo}if (isRoot && pointIndex < 0) {return obj;} else {name = name.substring(pointIndex + 1);pointIndex = name.indexOf(".");}if (pointIndex <= 0) {thisField = name;} else {// thisField = xxxthisField = name.substring(0, pointIndex);// nextField = ooo.ooonextField = name.substring(pointIndex + 1);}Class clazz = obj.getClass();Object returnValue = null;String getMethodName = "get" + thisField.substring(0, 1).toUpperCase() + thisField.substring(1);Method[] methods = clazz.getDeclaredMethods();for (Method method : methods) {if (getMethodName.equals(method.getName())) {returnValue = method.invoke(obj, null);}}if (StringUtils.isEmpty(nextField)) {return returnValue;} else {return getterMethod(returnValue, nextField, false);}}}
读切面
/*** @Author: yangjie* @Date: 2019-10-12 15:18* @Description:*/@Slf4j@Aspect@Component@Order(2)public class RedisCacheAspect extends RedisCacheAbstractAspect {/*** 配置redis 切面环绕方法** @param point* @param redisCache* @return* @throws Throwable*/@Around("@annotation(redisCache)")public Object doAround(ProceedingJoinPoint point, RedisCache redisCache)throws Throwable {////获得切面当中方法签名MethodSignature methodSignature = (MethodSignature) point.getSignature();Method method = methodSignature.getMethod();// 所有参数的值Object[] params = point.getArgs();// 所有参数的名字String[] paramNames = methodSignature.getParameterNames();// 缓存个性化字段String cacheField = redisCache.field();String cacheKey = redisCache.key();// 缓存个性化字段的EL值String fieldName = cacheField.replaceAll(EL_REPLACE_PATTERN, "");List<String> keyElList = new ArrayList<>();Pattern p = Pattern.compile(EL_PATTERN);Matcher m = p.matcher(redisCache.key());while (m.find()) {keyElList.add(m.group());}// 循环所有的参数名,为EL动态取值的属性赋值for (int i = 0; i < paramNames.length; i++) {String name = paramNames[i];// 替换field里的el表达式的值if (isEl(cacheField) && name.equals(fieldName.split("\\.")[0])) {cacheField = String.valueOf(getterMethod(params[i], fieldName, true));} else {cacheField = redisCache.field();}// 替换key里的el表达式的值for (String keyEl : keyElList) {String elStr = keyEl.replaceAll(EL_REPLACE_PATTERN, "");if (!name.equals(elStr.split("\\.")[0])) {continue;}cacheKey = cacheKey.replace(keyEl, getterMethod(params[i], elStr, true) + "");}}// 根据需要的类型进行处理try {if (RedisDataType.STRING == redisCache.redisDataType()) {// Redis数据结构是String类型的逻辑return handleString(point, method, redisCache, cacheField, cacheKey);} else if (RedisDataType.HASH == redisCache.redisDataType()) {// Redis数据结构是Hash类型的逻辑return handleHash(point, method, redisCache, cacheField, cacheKey);}} catch (Exception e) {log.error("【redis aop handler error】", e);return point.proceed();}return point.proceed();}/*** handler string** @param point* @param method* @param redisCache* @param cacheField* @param cacheKey* @return* @throws Throwable*/private Object handleString(ProceedingJoinPoint point, Method method, RedisCache redisCache,String cacheField, String cacheKey) throws Throwable {Object result;String key = StringUtils.isEmpty(cacheKey)? getCacheKey(point, cacheField, redisCache.fullKey()): cacheKey + (StringUtils.isEmpty(cacheField) ? "" : RedisConstants.REDIS_SEPARATE + cacheField);if (getLock(key, redisCache.refreshTime())) {// 抢到锁更新缓存数据result = point.proceed();if (result == null) {return result;}// 放入缓存String data = encodeObject(result);log.info(MessageFormat.format("【redis key miss,key->{0},data->{1}】 ", key, data));// -1 不过期if (redisCache.expire() == -1) {redisUtil.set(key, data);} else if (redisCache.expire() >= 0) {SetParams setParams = SetParams.setParams().ex(redisCache.expire());redisUtil.set(key, data, setParams);}return result;} else {return decodeObject(redisUtil.get(key), method, redisCache);}}private Object handleHash(ProceedingJoinPoint point, Method method, RedisCache redisCache,String cacheField, String cacheKey) throws Throwable {Object result;String key = StringUtils.isEmpty(cacheKey)? getHashCacheKey(point, redisCache.fullKey()): cacheKey;String field = cacheField;String lockTargetKey = key + RedisConstants.REDIS_SEPARATE + field;if (getLock(lockTargetKey, redisCache.refreshTime())) {// 抢到锁更新缓存数据// 后端查询数据result = point.proceed();if (result == null) {return result;}// 将list作为Hash存储String data = encodeObject(result);redisUtil.hset(key, field, data);// -1 不过期if (redisCache.expire() != -1) {redisUtil.expire(key, redisCache.expire());}return result;} else {// 加锁失败后String value = redisUtil.hget(key, field);return decodeObject(value, method, redisCache);}}private String encodeObject(Object result) {return JSON.toJSONString(result);}private Object decodeObject(String result, Method method, RedisCache redisCache) {if (result == null) {return null;}if (!(result instanceof String)) {return result;} else if (redisCache.clazz() == String.class) {return result;}return decodeObject(result, redisCache.clazz(), method.getGenericReturnType());}private Object decodeObject(String result, Class clazz, Type type) {if (String.valueOf(result).startsWith("[")) {// "[" 开头为列表,使用JSONArray反序列化return JSONArray.parseArray(result, clazz);} else {// 不以"[" 开头为实体,使用JSONObject反序列化if (clazz != null) {return JSONObject.parseObject(result, clazz);} else {return JSONObject.parseObject(result, type);}}}}
更新缓存切面
(1)public class RedisCacheRefreshAspect extends RedisCacheAbstractAspect {("@annotation(redisCacheRefresh)")public Object doAround(ProceedingJoinPoint point, RedisCacheRefresh redisCacheRefresh)throws Throwable {Object result = null;try {result = point.proceed();// 获取签名和方法MethodSignature methodSignature = (MethodSignature) point.getSignature();// 所有参数的值Object[] params = point.getArgs();// 所有参数的名字String[] paramNames = methodSignature.getParameterNames();// 缓存个性化字段String[] cacheFields = redisCacheRefresh.fields();String[] cacheKeys = redisCacheRefresh.keys();if (redisCacheRefresh.keys().length != cacheFields.length) {log.error("【切面缓存】清除锁keys与fields长度不一致");return result;}// 循环所有的keys,为EL动态取值的属性赋值for (int j = 0; j < cacheFields.length; j++) {String cacheField = cacheFields[j];String cacheKey = cacheKeys[j];// 缓存个性化字段的EL值String fieldName = cacheField.replaceAll(EL_REPLACE_PATTERN, "");for (int i = 0; i < paramNames.length; i++) {String name = paramNames[i];if (name.equals(fieldName.split("\\.")[0])) {if (super.isEl(cacheField)) {cacheFields[j] = getterMethod(params[i], fieldName, true) + "";} else {cacheFields[j] = redisCacheRefresh.fields()[j];}// 从keys里筛选El表达式列表List<String> keyElList = new ArrayList<>();Pattern p = Pattern.compile(EL_PATTERN);Matcher m = p.matcher(cacheKey);while (m.find()) {keyElList.add(m.group());}// keys中若配置多个EL全部处理for (String keyEl : keyElList) {String elStr = keyEl.replaceAll(EL_REPLACE_PATTERN, "");if (!name.equals(elStr.split("\\.")[0])) {continue;}cacheKeys[j] = cacheKeys[j].replace(keyEl, getterMethod(params[i], elStr, true) + "");}}}}// 循环所有的fields值,根据keys-fields对应值拼装需要清除的锁,并清除,for (int i = 0; i < cacheKeys.length; i++) {String key = cacheKeys[i];String clearKey = key + (StringUtils.isEmpty(cacheFields[i]) ? "" : RedisConstants.REDIS_SEPARATE + cacheFields[i]);super.releaseLock(clearKey);}} catch (Exception e) {log.error("【redis aop handler error】", e);return result;}return result;}}
Cache-As-SoR
1 Read-Through:
public static void readThroughTest() {LoadingCache<String, String> loadingCache = Caffeine.newBuilder().expireAfterWrite(2, TimeUnit.SECONDS).build(new CacheLoader<String, String>() {public String load( String o) throws Exception {return getFrommysql(o);}});System.out.println(loadingCache.get("A"));System.out.println(loadingCache.get("A"));}
2 Write-Through:
3 Write-Behind:
以上是关于聊聊缓存回收策略跟缓存更新策略的主要内容,如果未能解决你的问题,请参考以下文章