《机器学习实战》个人学习分享:朴素贝叶斯
Posted 摩羯青年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《机器学习实战》个人学习分享:朴素贝叶斯相关的知识,希望对你有一定的参考价值。
Python3《机器学习实战》学习笔记(四):朴素贝叶斯基础篇之言论过滤器:https://blog.csdn.net/c406495762/article/details/77341116
Python3《机器学习实战》学习笔记(五):朴素贝叶斯实战篇之新浪新闻分类:https://blog.csdn.net/c406495762/article/details/77500679
【机器学习实战】【python3版本】【代码讲解】:https://www.bilibili.com/video/BV16t411Q7TM

相关的运行平台和环境
运行平台: win10
python: 3.7.6
Anaconda: 4.8.3
IDE: pycharm community
01
前期知识点
贝叶斯概率以18世纪的一位神学家托马斯·贝叶斯(Thomas Bayes)的名字命名。贝叶斯概率引入先验知识和逻辑推理来处理不确定命题。另一种概率解释称为频数概率(frequency probability),它只从数据本身获得结论,并不考虑逻辑推理及先验知识。由于频数概率在实际的问题中不容易获得或者根本无法得到,所以才用到贝叶斯概率。
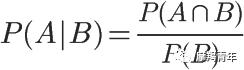
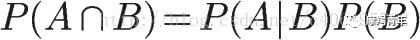
同理可得,
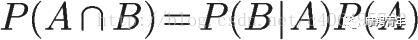
所以,

即
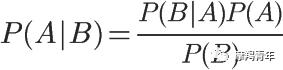
所以B发生条件下A发生的概率可以由上式这样表示。下面介绍全概率公式
全概率公式
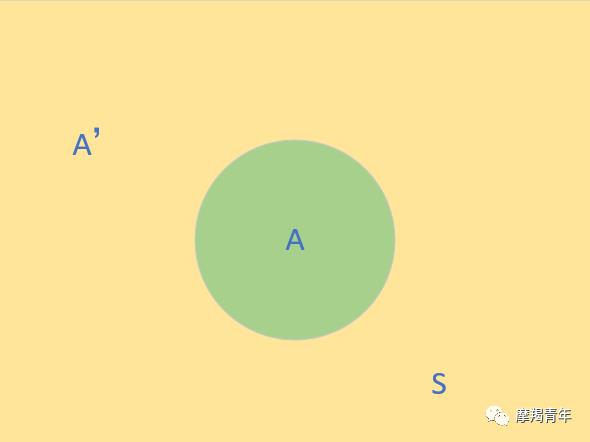
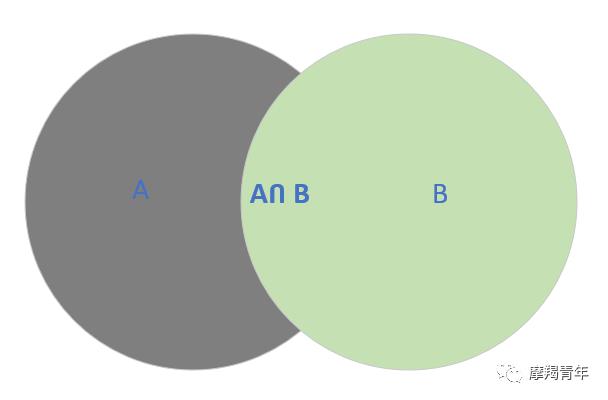
假定样本空间S,是两个事件A与A'的和。A和B有交集。
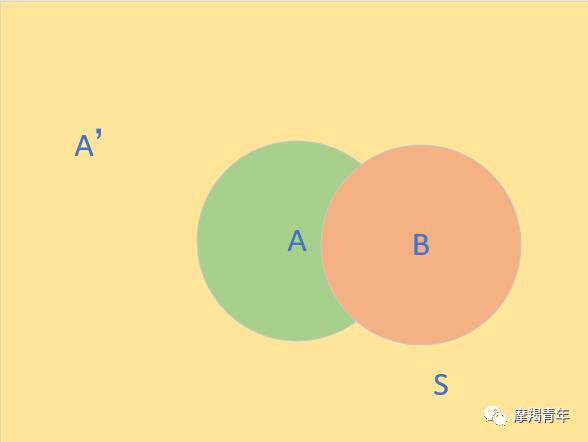
那么B的概率可以两部分来表示,即
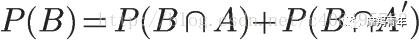
在上面的推导当中,我们已知
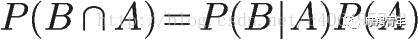
所以,
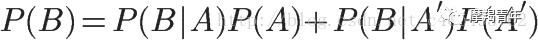
将这个公式代入上一节的条件概率公式,就得到了条件概率的另一种写法:
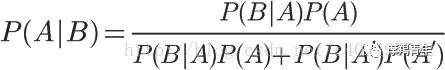
以上就是有关贝叶斯的基础知识点,在这里需要注意的是“朴素”一词的含义有两个方面:
1 特征之间相互独立,这个独立指的是统计学意义上的独立,即一个特征的出现与其他特征没有任何关系,互不影响。
2 每个特征同等重要,即是没有好坏之分,每个特征拥有同样的地位。
02
情感文本分类
第一个是文本情感分析实例,根据数据集,数据集包括带侮辱类的文本和不带侮辱类的文本,然后输入一个文本,判断是否是带有侮辱性的文本。代码如下:
def test():postingList, classVec = loadDataSet()myVocabList = createVocabList(postingList)trainMat = []for postinDoc in postingList:trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) # 将一个一个样本,利用词汇表转换为词向量p0V, p1V, pAb = trainNB0(trainMat, classVec) # 训练-计算条件概率 0-非侮辱类条件概率集 1-侮辱类条件概率集testEntry = ['love', 'my', 'dalmation']thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) # 测试样本向量化if classifyNB(thisDoc, p0V, p1V, pAb):print(testEntry, '属于侮辱类') # 执行分类并打印分类结果else:print(testEntry, '属于非侮辱类') # 执行分类并打印分类结果testEntry = ['stupid', 'garbage'] # 测试样本2thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) # 测试样本向量化if classifyNB(thisDoc, p0V, p1V, pAb):print(testEntry, '属于侮辱类') # 执行分类并打印分类结果else:print(testEntry, '属于非侮辱类') # 执行分类并打印分类结果
第一行是创建数据集,有六个样本,三个侮辱类的和三个非侮辱类的,标签单独处理。
def loadDataSet():postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], # 切分的词条['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],['stop', 'posting', 'stupid', 'worthless', 'garbage'],['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]classVec = [0, 1, 0, 1, 0, 1] # 类别标签向量,1代表侮辱性词汇,0代表不是return postingList, classVec # 返回实验样本切分的词条和类别标签向量
然后是创建词汇表,这是将数据集向量化的第一步
def createVocabList(dataSet):vocabSet = set([]) # 创建一个空的不重复列表for document in dataSet:vocabSet = vocabSet | set(document) # 取并集return list(vocabSet)
方法是逐次遍历然后取并集,由于集合具有元素不重复的特点,所以这个就可以将全部数据集的元素汇成一个集合。集合如下:
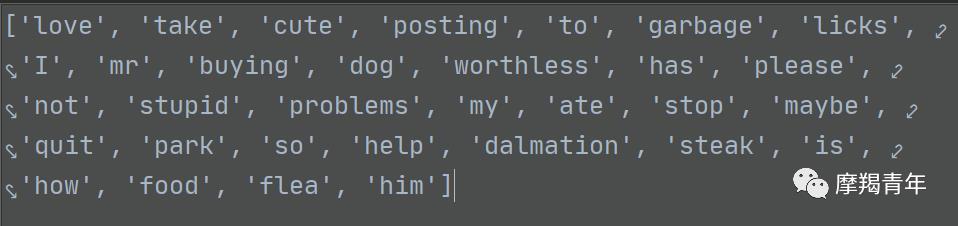
然后是向量化的第二步,其中用到setOfWords2Vec函数,这个函数是将数据集的元素遍历,与集合的比较,出现的元素置1,没出现的置0,然后就把文本向量化,方便后续处理。
def setOfWords2Vec(vocabList, inputSet):returnVec = [0] * len(vocabList) # 创建一个其中所含元素都为0的向量for word in inputSet: # 遍历每个词条if word in vocabList: # 如果词条存在于词汇表中,则置1returnVec[vocabList.index(word)] = 1else:print("the word: %s is not in my Vocabulary!" % word)return returnVec # 返回文档向量
处理结果如下:
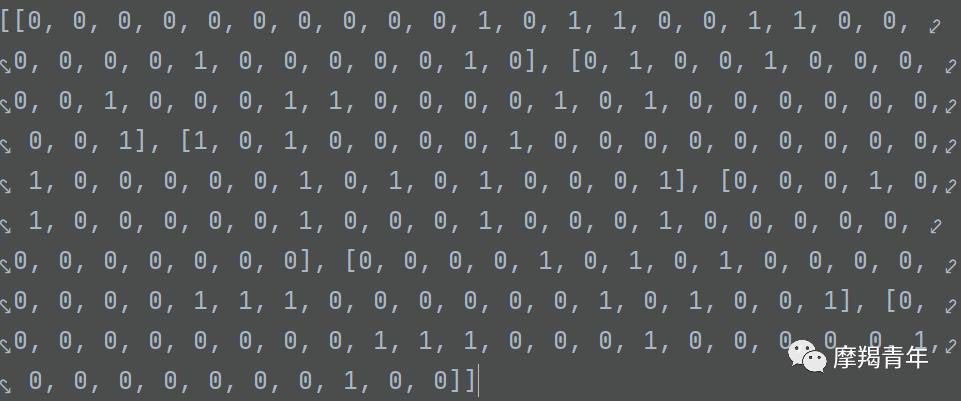
向量化处理后,就可以计算概率了,代码比较简单,贴代码如下:
def trainNB0(trainMatrix, trainCategory):numTrainDocs = len(trainMatrix) # 计算训练的文档数目numWords = len(trainMatrix[0]) # 计算每篇文档的词条数pAbusive = sum(trainCategory) / float(numTrainDocs) # 文档属于侮辱类的概率p0Num = np.ones(numWords)p1Num = np.ones(numWords) # 创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑p0Denom = 2.0p1Denom = 2.0 # 分母初始化为2,拉普拉斯平滑for i in range(numTrainDocs):if trainCategory[i] == 1: # 统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···p1Num += trainMatrix[i]p1Denom += sum(trainMatrix[i])else: # 统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···p0Num += trainMatrix[i]p0Denom += sum(trainMatrix[i])p1Vect = np.log(p1Num / p1Denom) # 取对数,防止下溢出p0Vect = np.log(p0Num / p0Denom)return p0Vect, p1Vect, pAbusive # 返回属于侮辱类的条件概率数组,属于非侮辱类的条件概率数组,文档属于侮辱类的概率
在这里的两个优化,一个是拉普拉斯平滑处理,是为了避免出现概率为0的情况,另一个是条件概率对数化,防止小数相乘下溢出。下面开始跑代码
计算条件概率,就是选择相同标签的放在一起,然后算频数,再除以总数,全部数据向量化处理比较方便,结果如下:
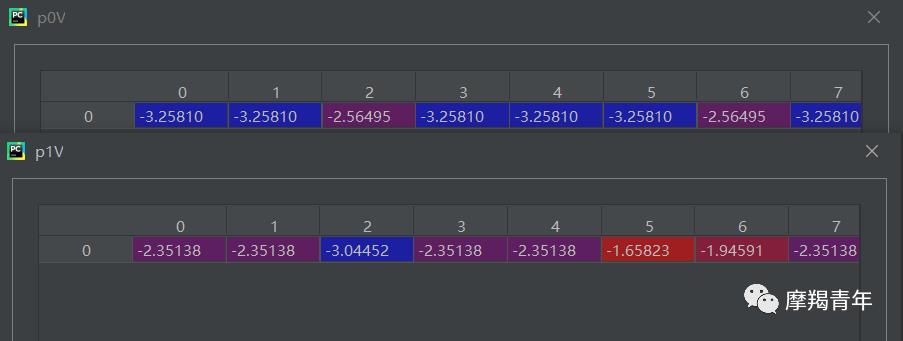
计算好条件概率后,就可以进行测试,将测试文本同样向量化处理然后与计算好的条件概率相乘,取出相应的条件概率,比较概率输出结果:
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) # 对应元素相乘。logA * B = logA + logB,所以这里加上log(pClass1)p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1)if p1 > p0:return 1else:return 0
取两个测试文本,结果:

至此,文本分析的就结束了。
03
电子邮件过滤
第二个是电子邮件过滤,核心基本一样,直接跑代码分析:
def spamTest():docList = []classList = []fullText = []for i in range(1, 26): # 遍历25个txt文件wordList = textParse(open('email/spam/%d.txt' % i, 'r').read()) # 读取每个垃圾邮件,并字符串转换成字符串列表docList.append(wordList)fullText.append(wordList)classList.append(1) # 标记垃圾邮件,1表示垃圾文件wordList = textParse(open('email/ham/%d.txt' % i, 'r').read()) # 读取每个非垃圾邮件,并字符串转换成字符串列表docList.append(wordList)fullText.append(wordList)classList.append(0) # 标记非垃圾邮件,1表示垃圾文件vocabList = createVocabList(docList) # 创建词汇表,不重复trainingSet = list(range(50))testSet = [] # 创建存储训练集的索引值的列表和测试集的索引值的列表for i in range(10): # 从50个邮件中,随机挑选出40个作为训练集,10个做测试集randIndex = int(random.uniform(0, len(trainingSet))) # 随机选取索索引值testSet.append(trainingSet[randIndex]) # 添加测试集的索引值del (trainingSet[randIndex]) # 在训练集列表中删除添加到测试集的索引值trainMat = []trainClasses = [] # 创建训练集矩阵和训练集类别标签系向量for docIndex in trainingSet: # 遍历训练集trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) # 将生成的词集模型添加到训练矩阵中trainClasses.append(classList[docIndex]) # 将类别添加到训练集类别标签系向量中p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) # 训练朴素贝叶斯模型errorCount = 0 # 错误分类计数for docIndex in testSet: # 遍历测试集wordVector = setOfWords2Vec(vocabList, docList[docIndex]) # 测试集的词集模型if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: # 如果分类错误errorCount += 1 # 错误计数加1print("分类错误的测试集:", docList[docIndex])print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))
第一步还是处理数据,遍历50封邮件,其中包括25封垃圾邮件,25封非垃圾邮件,将垃圾邮件和非垃圾邮件进行分类存储,结果如下:

然后是将50封邮件随机分为数据集和测试集,计算错误率,由于基本相同,直接跑结果:
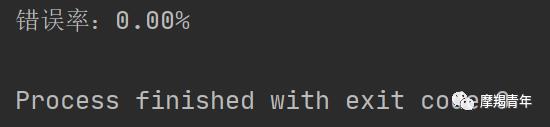
结果还可以。
04
新浪新闻分类
第二个主要实例是用sklearn做有关新浪新闻分类的,先需要安装一个分词组件"jieba"比较简单,安装就用conda就行,在这里贴出相关的教程,有兴趣的可以仔细研究:
Python中文分词组件使用简单:
官方教程:https://github.com/fxsjy/jieba
民间教程:https://www.oschina.net/p/jieba
话不多说,贴代码:
if __name__ == '__main__':# 文本预处理folder_path = './SogouC/Sample' # 训练集存放地址all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path,test_size=0.2)# 生成stopwords_setstopwords_file = './stopwords_cn.txt'stopwords_set = MakeWordsSet(stopwords_file)test_accuracy_list = []# 需要去除一定的高频词原因是:高频词一般是:标点符号、了、好、在、当然、是的等等这些东西,对分类是没有用的,所以应该去除一部分高频词# 但是具体去除多少,是不知道的,所以才有了以下的试验deleteNs = range(0, 1000, 20) # 0 20 40 60 ... 980 每次运行就取出出现次数最高的前20个词语for deleteN in deleteNs:feature_words = words_dict(all_words_list, deleteN, stopwords_set) # 提取特征词train_feature_list, test_feature_list = TextFeatures(train_data_list, test_data_list, feature_words) # 提取特征向量test_accuracy = TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list) # 分类test_accuracy_list.append(test_accuracy) # 多次试验,每次提取不同的特征词# ave = lambda c: sum(c) / len(c)# print(ave(test_accuracy_list))plt.figure()plt.plot(deleteNs, test_accuracy_list)plt.title('Relationship of deleteNs and test_accuracy')plt.xlabel('deleteNs')plt.ylabel('test_accuracy')plt.show()
这是主程序,按照顺序讲解,第一步是文本预处理
def TextProcessing(folder_path, test_size=0.2):folder_list = os.listdir(folder_path) # 查看folder_path下的文件data_list = [] # 数据集数据class_list = [] # 数据集类别# 遍历每个子文件夹for folder in folder_list:new_folder_path = os.path.join(folder_path, folder) # 根据子文件夹,生成新的路径files = os.listdir(new_folder_path) # 存放子文件夹下的txt文件的列表j = 1# 遍历每个txt文件for file in files:if j > 100: # 每类txt样本数最多100个breakwith open(os.path.join(new_folder_path, file), 'r', encoding='utf-8') as f: # 打开txt文件raw = f.read()word_cut = jieba.cut(raw, cut_all=False) # 精简模式,返回一个可迭代的generatorword_list = list(word_cut) # generator转换为listdata_list.append(word_list) # 添加数据集数据class_list.append(folder) # 添加数据集类别j += 1data_class_list = list(zip(data_list, class_list)) # zip压缩合并,将数据与标签对应压缩random.shuffle(data_class_list) # 将data_class_list乱序index = int(len(data_class_list) * test_size) + 1 # 训练集和测试集切分的索引值train_list = data_class_list[index:] # 训练集test_list = data_class_list[:index] # 测试集train_data_list, train_class_list = zip(*train_list) # 训练集解压缩test_data_list, test_class_list = zip(*test_list) # 测试集解压缩all_words_dict = {} # 统计训练集词频for word_list in train_data_list:for word in word_list:if word in all_words_dict.keys():all_words_dict[word] += 1else:all_words_dict[word] = 1# 根据键的值倒序排序--单词出现的次数降序排列,后面选择特征时候有用all_words_tuple_list = sorted(all_words_dict.items(), key=lambda f: f[1], reverse=True)all_words_list, all_words_nums = zip(*all_words_tuple_list) # 解压缩all_words_list = list(all_words_list) # 转换成列表return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list
遍历子文件夹,将路径修改成最新的路径,然后遍历txt文件,将文本切割用list存储,切割用到jieba组件,切割好的如下:
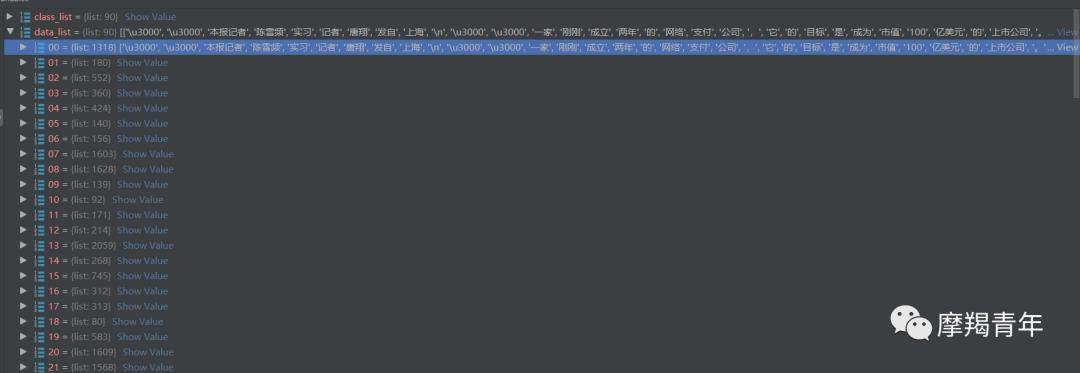

下面就是转换成文本向量,在这之前先将数据和标签压缩,为的是方便划分训练集和测试集,这里以0.2作为比率,划分好的训练集71,测试集19,如下:

然后解压缩,统计词频:
all_words_dict = {} # 统计训练集词频for word_list in train_data_list:for word in word_list:if word in all_words_dict.keys():all_words_dict[word] += 1else:all_words_dict[word] = 1
如果如下:


def MakeWordsSet(words_file):words_set = set() # 创建set集合with open(words_file, 'r', encoding='utf-8') as f: # 打开文件for line in f.readlines(): # 一行一行读取word = line.strip() # 去回车if len(word) > 0: # 有文本,则添加到words_set中words_set.add(word)return words_set # 返回处理结果
提取的停用词如下:
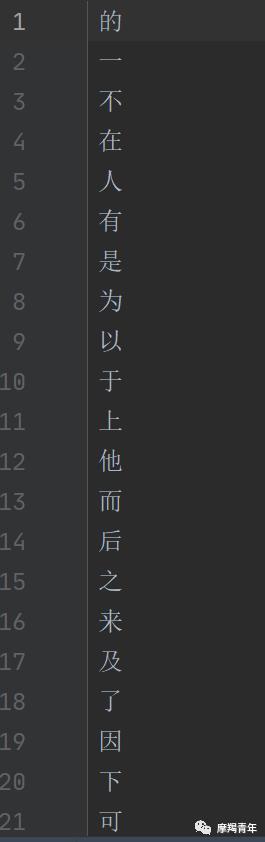
提取特征向量
def TextFeatures(train_data_list, test_data_list, feature_words):def text_features(text, feature_words): # 出现在特征集中,则置1text_words = set(text)features = [1 if word in text_words else 0 for word in feature_words]return featurestrain_feature_list = [text_features(text, feature_words) for text in train_data_list]test_feature_list = [text_features(text, feature_words) for text in test_data_list]return train_feature_list, test_feature_list # 返回结果
提取特征词
def words_dict(all_words_list, deleteN, stopwords_set=set()):feature_words = [] # 特征列表n = 1for t in range(deleteN, len(all_words_list), 1):if n > 1000: # feature_words的维度为1000break# 如果这个词不是数字,并且不是指定的停用语,并且单词长度大于1小于5,那么这个词就可以作为特征词if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:feature_words.append(all_words_list[t])n += 1return feature_words
提取后的特征词如下:

然后利用sklearn进行拟合和模型预测,代码如下:
def TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list):classifier = MultinomialNB().fit(train_feature_list, train_class_list)test_accuracy = classifier.score(test_feature_list, test_class_list)return test_accuracy
然后运行代码:
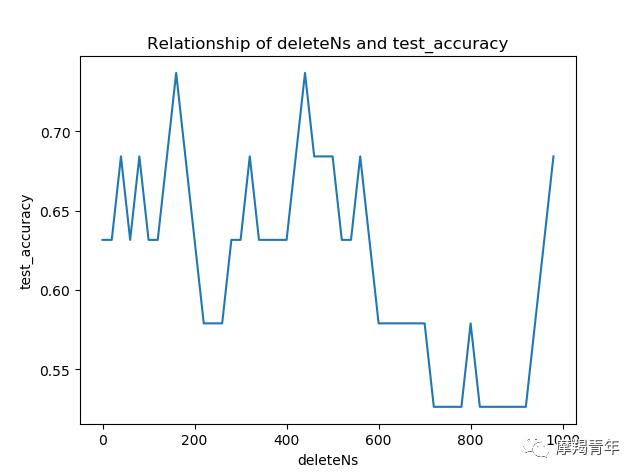
结果如上,可以看出结果并不准确,这个代码也就看看了解原理即可。
05
总结
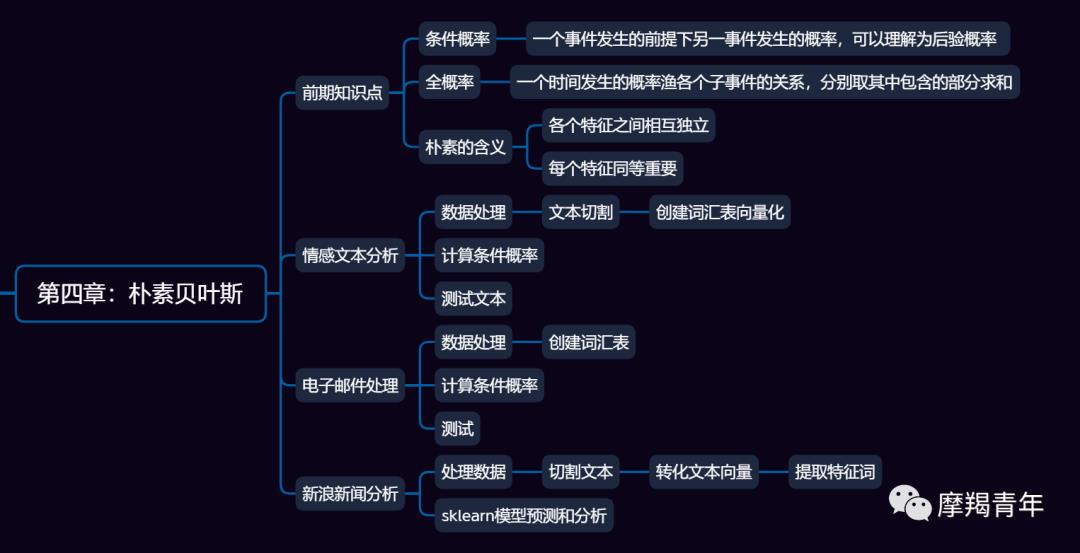
以上是关于《机器学习实战》个人学习分享:朴素贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章