机器学习理论大会战——朴素贝叶斯(基础知识)
Posted AI雄霸天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习理论大会战——朴素贝叶斯(基础知识)相关的知识,希望对你有一定的参考价值。
机器学习中的概率思想简述
在前面介绍的两种监督型机器学习算法——k近邻以及线性模型中,我们都是通过一定的数学公式最终计算出一个值,这个值或作为回归预测结果;或提供类别判定依据。不管是哪一种作用,该值总是一个确定的结果。但事实上,当我们并不知晓一批数据的内在数学关系时(也就是说我们在事先不知道一个精确的数学公式可以准确描述这批数据时),我们所做的全部工作仅仅是在找到一个与真实值最为接近的预测值而已。而这个预测值有多大程度能够代表真实值呢?不好说。
因此,我们有了另一种完成回归预测或者分类预测的法子:以概率来表达我们所作出的结论对于真实结论之间的一个差距。换句话说就是:如果我们得出来的这个概率大过50%或者更好的一个阈值,我们认为我们得到的这个概率背后所反映的结论就是可信的,也就可以在很大程度上代表着真实结论。
这也比较符合我们日常生活中的处事原则:在不彻底掌握事物发展规律的前提下,我们通常都会采用诸如“很大可能”、“大概率下”等之类的字眼来表达我们对事物的把握程度。
在机器学习、深度学习领域,这种基于概率的算法更是比比皆是。从客观角度来分析,这样做很有必要:因为谁也不是万能的,无法做出百分百的决策,算法也是如此。它必然也在认识上存在一定的误差,因此得出的结论断然不能百分百准确,只可能尽量准确。而这与概率的本质就不谋而合。
朴素贝叶斯理论概述
弄清楚机器学习中的概率本质后,我们现在就来看一种基于概率论的监督型机器学习算法——朴素贝叶斯算法。
朴素贝叶斯算法贝叶斯算法家族中的一个家庭成员。它的核心思想是基于相关概率已知的前提下,利用“误判损失”来选择最优的类别。所谓的相关概率已知,指的是我们可以利用已知的数据项来算出诸如各个类别的概率(等于某个类的数量在所有类的数量中的占比);算出当前类别下,第i项特征为m时的概率(等于第i项特征中取值为m的特征数在本项特征的全部取值数中的占比)等。
而“误判损失”,则指的是本来应当是被判别为A类却又被错误判别为B时所造成的损失。用数学公式表示就是:
(1)
其中λij是将一个真实标记为Cj的样本误判为Ci所产生的损失,P(cj|x)则表示为在数据样本为x时被判定是类别Cj的概率,也被称之为后验概率。N则表示类别的总数。
这里有三个名词需要稍作解释:
先验概率:根据过往经验分析得到的概率,比如有一堆样本,这对样本份属不同的类别中,那么某个类别出现的概率可以用这个类别出现的次数除以所有类别的数目总和来表示,这就是所谓的先验概率的一个形象解释。
后验概率:事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小。通俗地讲,就是如果一个样本已经被判别成了某个类,那么究竟是因为这个样本的哪个特征值而导致自己被判定成当前的类别呢?有点“秋后算账”的味道。
PS:不论是先验概率还是后验概率,通常都会基于一对数据样本进行一个估算,实际上一个类别发生的真实概率是多少,不可知;一个因素导致被判定为类别A的概率又是多少,仍然不可知。因此这里说的先验概率与后验概率,通常说的是一种估计值。后续分享中,若无特殊说明,一律如此理解。
联合概率:联合概率指的是包含多个条件且所有条件同时成立的概率,记作P(X=a,Y=b)或P(a,b)。
我们要做的就是如何使得这个R(cj|x)取得一个最小的值,也就是损失达到最低。现在我们来看一下,在以最小化分类错误率为目标时,通常λ的取值是怎么样的:
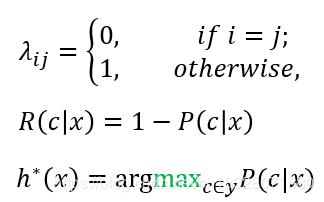 (2)
(2)
y为所有的类的集合,c为其中的某个类别。如公式2所示,我们最小化错误分类率就变成了寻找一个能使得后验概率P(c|x)最大的一个类别作为样本x的类别标记。
获得后验概率P(c∣x),在现实任务中通常难以直接获得.所要实现的是基于有限的训练样本集尽可能准确地估计出后验概率P(c│x)。
如何计算这里的后验概率,通常我们有两种策略:
一、直接建模P(c∣x)来预测c,称之为“判别式模型”;
二、对联合概率分布P(x,c)建模,然后再由此获得P(c|x),称之为“生成式模型”。
朴素贝叶斯通常选择的是生成式模型,利用联合概率分布来计算P(c|x)。它有一个通俗易懂的假设:数据样本中各个特征之间都是互相独立的。
现在我们基于贝叶斯定理,来计算这个后验概率P(c|x):
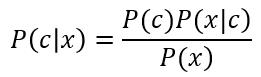 (3)
(3)
公式3中,P(c)代表类别C出现的概率,为先验概率,可以通过对数据样本的类别统计而得出。P(x)则表示特征值为x的先验概率,同样也能通过对数据样本的特征统计进行得出,但它与类别的标记并无关联。
而P(x|c)则表示当样本被判别为c类别时,是因为特征值x的概率是多少,这属于后验概率。我们现在要计算的就是这个后验概率。
因此,我们就可以这么理解,公式3实际上就是要我们去求P(x|c)的最大值。而P(x|c)又可以表示为:P(xi,x2,...,xi,...,xn|c)。意思是样本x被判定为类别c时,该样本中的特征就是xi,x2,...,xi,...,xn的概率是多少。
根据上头的那个朴素贝叶斯假设,我们也可以这样来计算P(x|c):
P(x|c)=P(x1|c)P(x2|c)...P(xi|c)...P(xn|c),通俗地理解为样本x被判定为类别c时,样本中刚好出现了特征xi的概率的乘积(i=1,2,...,n),n为样本的特征数量。
这样,公式3就改变成了如下公式:
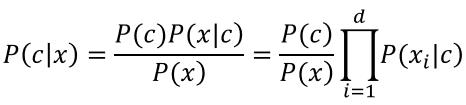 (4)
(4)
现在的目的就变成了求一个各个特征之下的后验概率的乘积。这就有点难办了。d为样本中特征的个数。
我们知道P(x)是一个与类别无关的先验概率,因此依照公式2和公式4,我们就得出了朴素贝叶斯的分类依据:
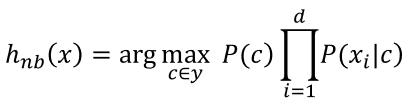 (5)
(5)
现在我们做两个假设:
一、样本中的类别总数为D,类别c所占的样本数为Dc,则P(c)=Dc/D;
二、样本中类别为c的数据集内,其特征为xi的样本数为Dc,xi,那么,P(xi|c)=Dc,xi/Dc。
但上述两个假设有时也存在一定的局限性:当数据样本被判别为c类别时,我们要计算一个“未知”属性的后验概率时,往往出现0的判定结果,此时就可能会最终的判定结果产生不可估量的错误后果。(注意:这里将的未知属性,并非是给数据样本临时添加一个新属性,而是说在被判定为类别c的样本中,某一项的特征取值中,没有取到的一个特征值。比如说:一个西瓜的好坏,如果说要从西瓜的敲声来说有清脆、沉闷两种,而通常我们都认为敲声沉闷的大概率是好西瓜,此时若我们计算一个西瓜被判定为好瓜的前提下,其敲声为清脆的后验概率,从样本中进行估值计算的话就是0。因为所有的好瓜中,其敲声都被标记为沉闷,并无清脆一说)。
正是有了这样一个缺陷,我们在计算后验概率时应当考虑平滑处理。比较常用到的平滑处理就是“拉普拉斯修正”:
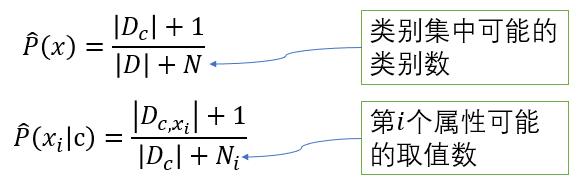
(6)
以上就是有关朴素贝叶斯的一些基本数学原理。另外,如果说数据的属性取值是一个连续值的话,让面的公式3最终可以演变成如下公式:
(7)
要求:每个属性值xi的后验概率P(xi|c)服从N(μc,i,σc,i2),其中,μc,i,σc,i2分别是第c类样本在第i个属性上取值的均值和方差。
朴素贝叶斯的Scikit-learn实现
介绍完基本的朴素贝叶斯理论后,我们接下来看一下基于这个理论所开发出来的三个经典的算法实现:
GaussianNB、BernoulliNB和MultinomialNB。GaussianNB(高斯贝叶斯分类器)可应用于任意连续数据,而BernoulliNB(伯努利贝叶斯分类器)假定输入数据为二分类数据,MultinomialNB(多项式贝叶斯分类器)假定输入数据为计数数据(即每个特征代表某个对象的整数计数,比如一个单词在句子里出现的次数)。BernoulliNB和MultinomialNB主要用于文本数据分类。
BernoulliNB分类器计算每个类别中每个特征不为0的元素个数。MultinomialNB计算每个类别中每个特征的平均值,而GaussianNB会保存每个类别中每个特征的平均值和标准差。
要想做出预测,需要将数据点与每个类别的统计数据进行比较,并将最匹配的类别作为预测结果。有趣的是,MultinomialNB和BernoulliNB预测公式的形式都与线性模型完全相同。只不过朴素贝叶斯模型coef_的含义与线性模型稍有不同,因为coef_不同于w。
总结
这一节的主要目标就是熟悉熟悉朴素贝叶斯的基本工作原理。在这个原理中,最重要的是要理解朴素贝叶斯的那个通俗的假设:样本特征之间的独立性。尤其要结合实际来理解。比如我们在判定一封邮件是否为垃圾邮件时,可能会从邮件中提取出多个关键字,一般情况下,这些关键字之间并不会有太多的关联,可以认定它们是彼此独立的。只是不知道这些关键字的存在对于一封邮件被判定为垃圾邮件的重要性有多少。
再有一点需要说明一下的是:朴素贝叶斯虽然天然是一个分类器,但并不是说它就不能被用于做回归预测。事实上是,在线性模型这个监督型机器学习算法中,就由岭回归与贝叶斯相结合,产生了一个称之为贝叶斯岭回归的算法,它就是用于开展回归预测的。
只不过目前我所接触到的一些技术文章以及各种权威定义中,都会将朴素贝叶斯定义为一个分类器。因此,在这里我也就不标新立异了。但后面我们在视频形式的知识分享中,应当还是要看一看所谓的贝叶斯岭回归对于回归预测的一些效果。
OK,本节的知识就为大家分享到这,下一节,我们将就朴素贝叶斯的三个典型的机器学习算法展开一些实例的介绍。谢谢大家。
以上是关于机器学习理论大会战——朴素贝叶斯(基础知识)的主要内容,如果未能解决你的问题,请参考以下文章