搜索系统19:lucene索引的五个关键知识点
Posted 中中
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索系统19:lucene索引的五个关键知识点相关的知识,希望对你有一定的参考价值。
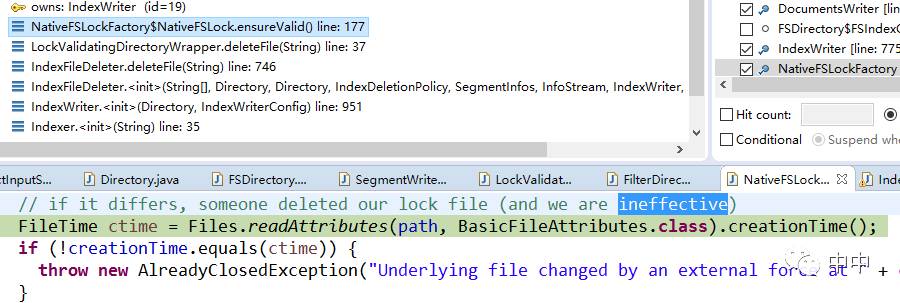
1.文件锁是怎么实现的?
org.apache.lucene.store.NativeFSLockFactory
这个write.lock一直为0字节。那它有什么用,怎么判断这个Lock文件就是lucene里定义的锁?如下,判断文件的创建时间是否与之前创建时的时间一致:
代码:org.apache.lucene.store.NativeFSLockFactory.NativeFSLock
2.lucene文件怎么存放int值。
我开始想到的是应该用ObjectOuputStream,深入代码,发现不是这样的。是把int转为4个字节,再存的。
org.apache.lucene.store.DataOutput.writeInt,下面是Java里int与2进制的关系:
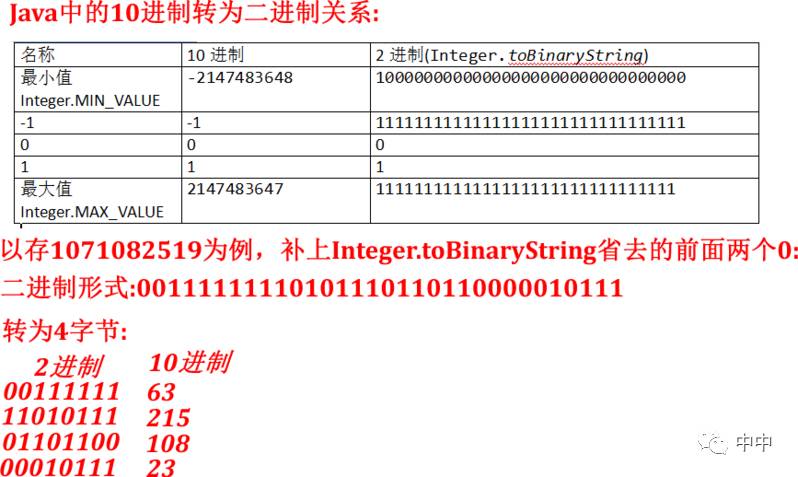
所以写int到文件就是写4个字节,如下图。但lucene还有另一种压缩存储方式,这种方式比较特殊,它会把int保存1到5个字节,低位的第一个位都为1。

3.lucene文件怎么存String。
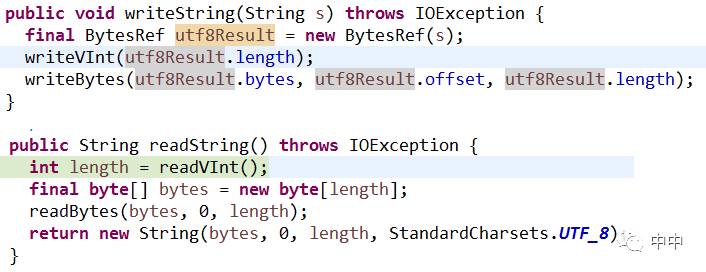
这个设计比较妙,写String时先写个长度再把字符串写进去,这样读String的时候就可以先读出这个长度,就知道下一步要读多长的字节了。
4.索引文件的共有内容。
如上图的多文件结构,每个document都会生成一组文件。除了write.lock文件外,其它文件都有的内容就是header与footer,这两个的格式可以查看org.apache.lucene.codecs.CodecUtil类的writeHeader方法与writeFooter方法,writeFooter方法的最后都是一个CRC(循环冗余校验码)。
5.共有的写文件方法。
索引文件里有各种数据格式,如Int,Long,String。但最终它们都转换成了字节保存,写字节的地方就是org.apache.lucene.store.OutputStreamIndexOutput,其中有两个方法:writeByte与writeBytes,写任何数据都要经过这两个方法。既然这样,我就可以通过分析调用这两个方法的代码,就可以知道整个lucene索引是怎么构建的了。
以上是关于搜索系统19:lucene索引的五个关键知识点的主要内容,如果未能解决你的问题,请参考以下文章