lucene5.3.1的排序是怎么实现的?
Posted 中中
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lucene5.3.1的排序是怎么实现的?相关的知识,希望对你有一定的参考价值。
排序有两种方式,在只有一个排序字段的情况下,分别看下这两种方式的实现方式。
1.在索引阶段生成排序索引(dvm,dvd):
在添加正常的字段后再添加一个该字段的SortedDocValuesField到document,即可按这个字段排序。
SortedDocValuesField pathField = new SortedDocValuesField("path", new BytesRef(f.getName().getBytes()));
doc.add(pathField);
TextField tf=new TextField("path", f.getName(), Field.Store.YES);
doc.add(tf);
生成索引后,可以发现多了两个文件_0_Lucene50_0.dvd与_0_Lucene50_0.dvm,这两就是就是排序相关文件了。然后查询时用普通的IndexReader ir = DirectoryReader.open方式。再到下图的地方打断点,可以看到,在加载索引文件时候就执行了readSortedField方法,读出的数据就是排序后的doc集合了。
dvm是dvd文件的元数据,所以变量名叫meta。从这个文件可以找到在dvd文件中存docId的下标为119,如下图:
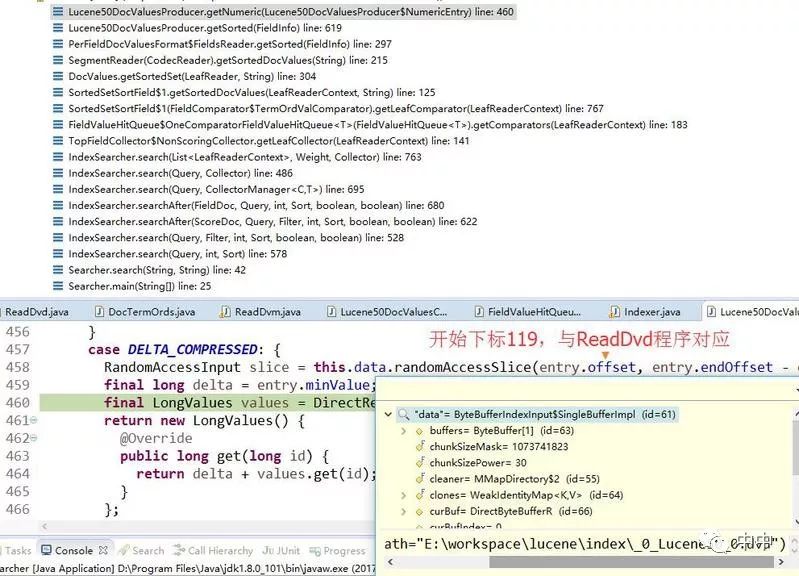
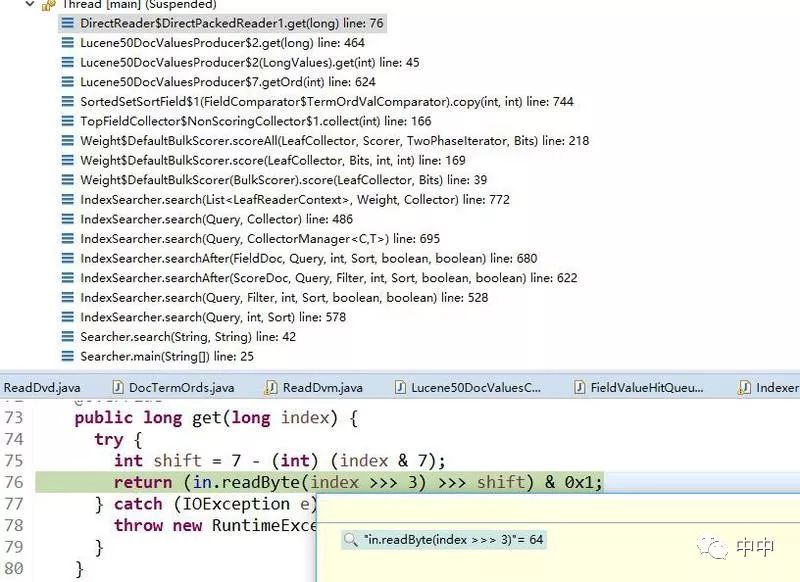
我用程序在119这个位置只发现了一个字节值为64,这个怎么表示两个docId呢?虽然我还看懂算法,但我找到了位置,如下:
2.在查询阶段排序(uninvert):
读取数据的时候用UninvertingReader包装一下,这样在查询时就会先把字段及其terms,terms对应的doc列表读取来,而terms已经是排序好的,就按这个再排一下doc列表即可。
DirectoryReader ir = UninvertingReader.wrap(DirectoryReader.open(FSDirectory.open(new File(indexDir).toPath())), Collections.singletonMap("path", Type.SORTED_SET_BINARY));
如下图:
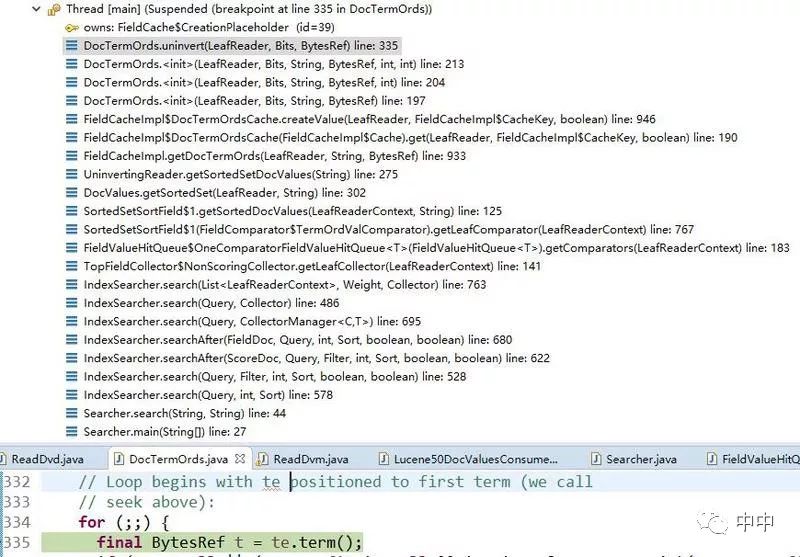
在这个DocTermOrds.uninvert方法中,解析原索引文件后存到了如下结构:

reader.maxDoc()是从si文件中读出maxDoc值,就是最大doc编号。DocTermOrds.index存的是id的code。uninvert过程如下:

在查询时根据tim中的terms知道了有那些doc,但还不知道这些doc的顺序,所以依次执行如下函数得到顺序。
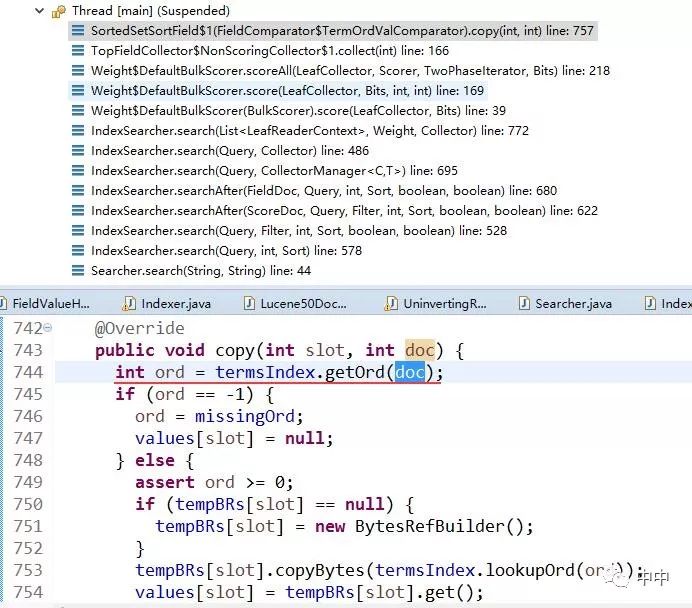
在termsIndex的getOrd方法中,先得到当前doc的code,就是前面uninvert生成的DocTermOrds.index,这个code在下图的read方法中会填充buffer。
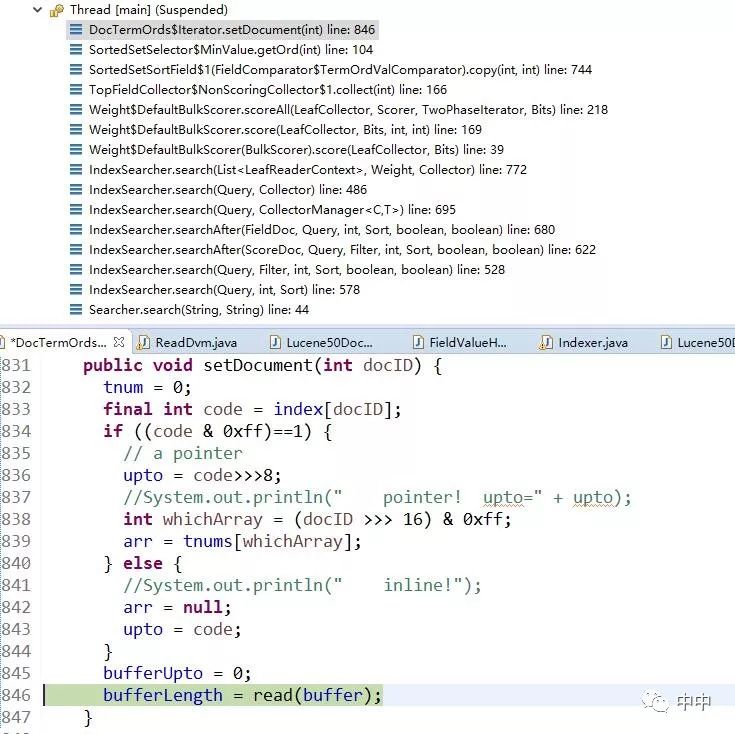
再通过DocTermOrds$Iterator.nextOrd方法取出刚填充的code就是doc的顺序了。
而我调试solr源码时发现,solr5.3.1用的是第二种方式(uninvert),这可能会影响一点查询效率。由于solr的索引文件用了复合模式,我暂不知道里面有没有dvm,dvd文件。测试发现,如果索引用了dvd/dvm文件,即使查询代码用了UninvertingReader,也不会执行uninvert,而是在初始化时就加载了排序的dvd/dvm文件。
以上是关于lucene5.3.1的排序是怎么实现的?的主要内容,如果未能解决你的问题,请参考以下文章