Lucene 8.0关于DocValues的改进
Posted NoSQL漫谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene 8.0关于DocValues的改进相关的知识,希望对你有一定的参考价值。
IndexedDISI是DocValues核心存储结构之一,主要用于存储DocValues中的DocIdSet数据,它的性能直接关乎DocValues的整体使用体验。DocIdSet是Lucene的DocID集合,它是一个有序整数集合。除了DocIdSet,IndexedDISI中还存储了DocId到Value的映射关系。
在上一篇文章《中详细介绍了DocValues的设计,而且也简单介绍了IndexedDISI。此文将展开IndexedDISI更多的细节,包括Lucene 8.0关于IndexedDISI所做的改进。
IndexedDISI设计
在一个完整的Segment中,DocID当然是有序且连续的,但由于某些文档的DocValues字段都可能存在缺省情况。当某个文档DocValues字段缺省时,在DocValues中自然也不会记录该文档的DocID了,从而造成DocIdSet可能不连续,甚至非常稀疏。
当然,即使DocIdSet的数据分布十分稀疏同样可以使用BitSet来存储(Lucene7.0之前就是这么实现的),但会非常浪费空间,也会影响读写的性能。因此开始着手优化BitSet的底层存储方式,最终Lucene借用Roaring Bitmap的思想设计了IndexedDISI(其中DISI是DocIdSetIterator的缩写)。
下面是7.0改进之后IndexedDISI的结构示意图:
通过NumOfDocs可以容易算得每个Slice的第一个Doc对应的Value在Values的位置(StartDoc),下文我们可以认为StartDoc是直接记录在Slice上的已知参数。
1. 分片规则
IndexedDISI将DocIdSet分片,让每个分片的数据的分布特征更明显,针对每个分片的分布特征进行优化。这是Roaring Bitmap的核心思想,也是一种压缩的手段。
分片的逻辑是将整型数值DocID的高16位作为分片的ID,低16位作为该DocID在分片中的第几个位置(这里暂且就叫Doc)。两部分合起来就是32位,正是一个整型数值的表示范围,也就说将一个Intger对半拆分成两个short,分别表示SliceId和Doc。
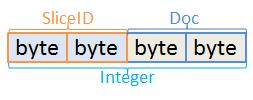
简单说,将一个整型数(DocID)一分为二,左边16个Bits表示分片编码(SliceID),右边的16个Bits表示DocID在分片里的位置(这里就用Doc表示吧)。
2. 数据分布特点
分片是为了让每个数据块的特征更明显,从而针对每个分片设计独特的存储结构。大家都知道16个Bits能表示65536个数值,即0-65535,说明每个分片最多能存储65536个DocID。Lucene按DocID最终落在同某Slice的数量,将Slice分成四种类型,分别是ALL, DENSE,SPARSE和NONE。
1. ALL : 表示该Slice中的每个Doc都存在。
2. NONE : 与ALL相反,表示整个Slice中一个Doc都没有。
3. DENSE : Slice拥有4096个文档,IndexedDISI采用BitSet来存储。
4. SPARSE : 表示Slice拥有的文档数不足4092个,IndexedDISI采用short[]作为底层存储。
ALL/NONE是特殊情况,要么都有,要么都没有,IndexedDISI针对这两种特殊的情况都没有存储对应的DocIdSet。当是ALL类型时,IndexedDISI会写一个标识表示该Slice属于ALL类型。而对于NONE而言,IndexedDISI则直接略过完全记录。
3. DocID与Value对应关系
为了能维系DocValues中DocID与Value的对应关系,Lucene的主要思想是让DocID存储在IndexedDISI的位置通过简单计算就能得到它对应Value在Values的位置index(后面都用index来表示DocID对应的Value在Values的位置)。换言之,是让DocID与Value之间有相同相对位移。
关于Numeric类型,Values与DocIdSet有相同的顺序,换言之,DocIdSet的第一个DocID对应的Value在Values的第一个位置。其它的类型则通过记录中间变量Address转化,DocIdSet的第一个DocID对应Address的第一个值是DocId对应的Value在Values的指针。所以我们可以简单的理解为DocIDSet与Values同序,DocIdSet中第n个DocID对应的Value在Values中的第n个位置。
在ALL和NONE结构是比较容易能对应的,其计算关系是index=StartDoc+Doc。而对SAPRSE/DENSE可能还有些许差别,下面将展开来讨论。
3.1 ALL/NONE
这两种类型是比较特殊的情况,因为它们都不需要记录DocID。如果是ALL仅会记录是第几个SliceID和Slice的类型(即说是明属于ALL类型)。对于NONE则完全不需要处理,直接略过。因为它们要么都存在,要么都不存在。对于全存在的情况,doc在Slice位置,也是value在Values的相对位置。当然对NONE类型来说,本身就不存在,更不存在Value了。所以两者没有,也就都不需要考虑了。
3.2 SPARSE
SPARSE类型的Slice会直接采用short[]存储Doc,因此它的下标跟Value在Values的下标相差StartDoc的距离,即通过简单的计算便能获取index。实际上跟ALL基本一样,因为它们都是紧凑数据结构,因此SPARSE类型的Slice也可以通过公式index=StartDoc+Doc计算。
3.3 DENSE
DENSE的存储结构是BitSet,它存储不连续的数据集时,BitSet也会是稀疏结构。这样,问题转变为:如何解决不连续的稀疏结构BitSet与紧凑的Values结构之间的数据对齐问题。
BitSet在逻辑上可以理解为是一个bit[],DocIdSet表现在这个bit[]上就是将Doc作为bit[]的下标,其值置为1表示该Doc存在。所以它与Values的关系表示如下:
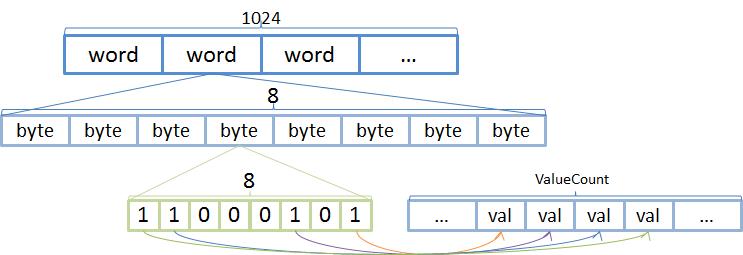
那么问题可以转化为如何统计Doc所有位置之前有多少个1,而1的数量便是Value在Values的相对位置。
已知BitSet的底层存储结构是long[],每个long也称word,有64个位表示能存储64个值。通过对target除于64得到wordNum,表示target在BitSet中的long[]的下标;对target取64的模能得到docInWord,表示target在word的第几个位上。计算公式如下:
wordNum = target / 64;
docInWord = target % 64;
遍历long数组的前wordNum个元素,统计元素含多少个值为1的位并累加,然后再减去word中第docInWord之后出现1的数目即可。
Lucene 8.0所做的改进
通过前面的介绍,对IndexedDISI已经有整体的印象了。知道IndexedDISI在跨Block查找时,需要通过遍历才能找到对应的Block;其次是在DENSE结构的查找问题,同样需要在BitSet的所有word,并将统计所有有值doc个数(即1的个数)。
LUCENE-8585是Toke提出来的,意在优化IndexedDISI的读性能的问题。这个ISSUE主要针对上面提及的两个遍历的情况进行优化,通过在索引时构建IndexedDIS的同样多建一份索引。这是典型的以空间换时间的做法,将搜索时间的下推至构建索引过程。
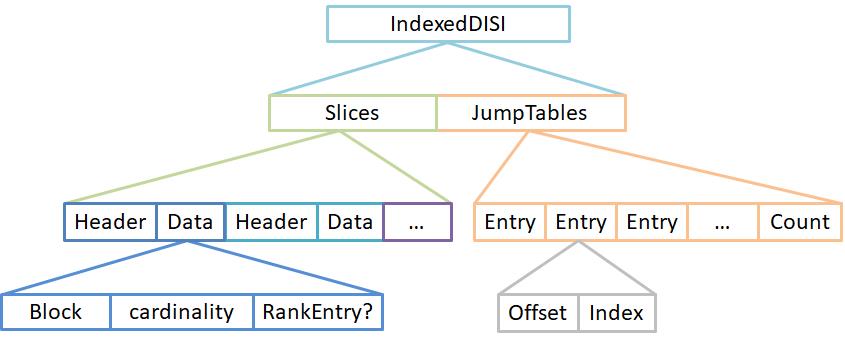
经LUCENE-8585改进之后IndexedDISI的结构也有比较大改进,它除了原本IndexedDISI部分数据,后面多加了JumpTable。在Slice内部也多一个RankEntry,它是在DENSE类型的Slice内部的索引。
1. Jump Table
Jump Table是一个long[],记录每个Slice的起始位置的索引,避免在查找过程中需要遍历Slices从而加速Slice定位。Jump Table将原来Slice查找的时间杂度O(n)下降为O(1)。实际上这种做法在Lucene构建索引过程处处可见,在《一文中介绍Term's Index的时候就有类似的做法。
虽然JumpEntry只是一个原子类型long,但实际上它代表两个参数,分别是Slice的文件指针,到此前Jump/Slice共出现多少个DocID。由于long高32位表示Slice的文件指针,低32位表示DocID的个数(Lucene规则每个Segment的文档数目不能超过32位,也就一个Integer的长度)。
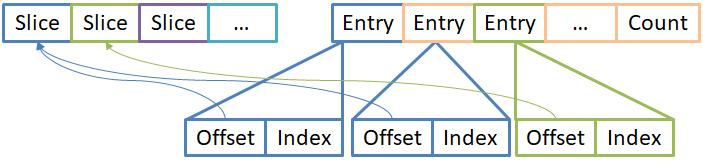
JumpTable是Slices的索引,但与之不同的是Slices中的Slice并不是连续,即当Slice没有DocID存在的时候(NONE类型),Slices并不记录。但是JumpTable会记录它,为的是能够通过SliceID作为JumpTable的下标,拥有访机访问的能力。
2. Rank Table
IndexedDISI提供两个功能,一是验证DocID存在与否,二是找到其值的位置(即Index)。对于验证DocID是否存在是BitSet非常擅长的,效率也极高。关于后面则有些费劲,需遍历long[],计算Long的64位中几个1。这复杂过程就留下可优化的空间了。
Rank Table是避免DENSE结构下Index计算的时候需要遍历long[]而性能消耗而设计的结构,JumpTable是Slice的索引,而Rank Table则是在一个Slice内的索引。
我们知道DENSE类型的存储结构是BitSet,所以实际在BitSet查找的时间复杂度本来就是O(1),并没有优化的空间。但我们前面介绍过找到DocID之后,还需要计算DocID对应Value在Values中的位置,这就是Rank Entry优化方向。
Slice拥有固定长度的BitSet,它由1024个long的数组组成,转换成bit就有65536个bits,这也是BitSet的容量。如果为BitSet的每个Bit都创建一个索引来存储其值的Index的话,需要存储的代价很高。因此Lucene是为每8个long/word创建一个索引,这是性能和存储的折中方案。
第一个RankEntry记录前8个word的所有DocID个数,也统计前8个word出现1的个数。第二个RankEntry记录前16个word的DocID个数,如此类推。为此IndexedDISI需要额外花费256个Bytes(每个RankEntry需要2个Bytes才能够表示)存储DocID的索引。可以看出来,RankEntry的实现思路与DocValues的TermsIndex有些类似。
结论
此文先详细讲解了IndexedDISI的设计,而后介绍了Lucene 8.0关于IndexedDISI的改进,主要围绕LUCENE-8585这个Issue展开。Lucene 8.0的改进,共涉及两个方面:一是给每个block加索引,二是优化稠密结构的Slice的Index计算。两者都是为了提高DocValues随机访问的性能。
关于"NoSQL漫谈"
NoSQL主要泛指一些分布式的非关系型数据存储技术,这其实是一个非常广泛的定义,可以说涉及到分布式系统技术的方方面面。随着人工智能、物联网、大数据、云计算以及区块链技术的不断普及,NoSQL技术将会发挥越来越大的价值。
更多NoSQL技术分享,敬请期待!
以上是关于Lucene 8.0关于DocValues的改进的主要内容,如果未能解决你的问题,请参考以下文章