lucene之filed详解和代码测试
Posted 胡桃七子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lucene之filed详解和代码测试相关的知识,希望对你有一定的参考价值。
1、索引创建和查询过程
文档数据采集,一般是数据库的数据和爬虫获取的数据。而Lucene不提供信息采集的类库,需要自己编写一个爬虫程序实现信息采集,也可以通过一些开源软件实现信息采集,如下:
Solr (http://lucene.apache.org/solr), solr是apache的一个子项目,支持从关系数据库、xml文档中提取原始数据。
Nutch http://lucene.apache.org/nutch) , Nutch是apache的一个子项目,包括大规模爬虫工具,能够抓取和分辨web网站数据。
2、文档和域
2.1、Field属性
性别 男
简介 我是阿里人
座右铭 Write the code, Change the world!
身份证号 43250***********6666
以上面数据为例。
2.1.1、是否分词(Tokenized)
是:对该field的内容进行分词,分词的目的,就是为了索引。
比如:座右铭、简介
否:不分词,但不代表不索引,而是将内容做为一个整体进行索引。
比如:性别、身份证号
2.1.2、是否索引(Indexed)
是:将分好的词进行索引,索引的目的,就是为了搜索。
比如:性别、简介、座右铭、身份证号
否:不索引,也就是不对该field域进行搜索。
2.1.3、是否存储(Stored)
是:将field域中的内容存储到document文档对象中。用于查询结果返回。
比如:性别、座右铭、身份证号
否:不将field域中的内容存储到document文档对象中。
比如:简介,由于简介在搜索页面中不需要显示,再加上简介的内容比较多,所以就不需要进行存储
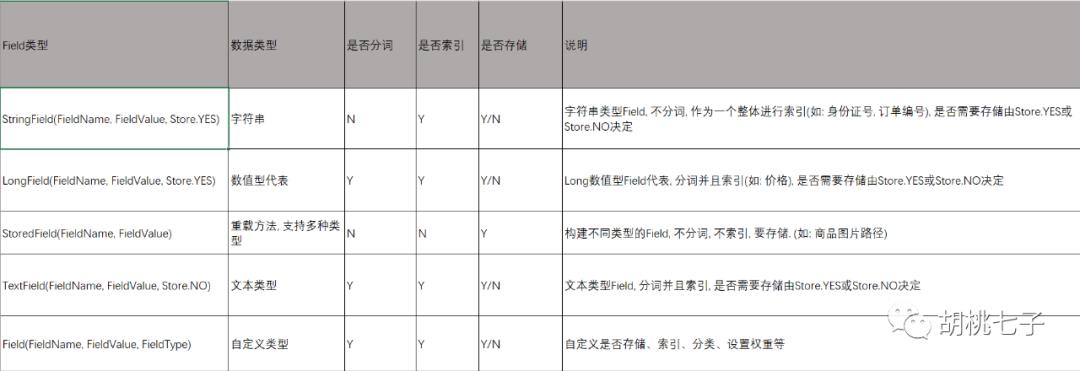
2.2、常用的Field类型
3、创建和查询索引
3.1、引入的包
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
lucene的版本用的是7.7.2
<lucene.version>7.7.2</lucene.version>
3.2、测试代码
3.2.1、创建索引
@Test
public void createIndex() throws Exception {
//1.创建一个Director对象,指定索引库的位置。
//把索引保存在磁盘中
Directory directory = FSDirectory.open(new File("D:\\lucene\\index").toPath());
//2.基于Directory对象来创建一个indexWriter对象
IndexWriter indexWriter = new IndexWriter(directory, new IndexWriterConfig());
//3.读取磁盘上的文件,对应每个文件创建一个文档对象。
File file = new File("D:\\lucene\\DataFiles");
File[] files = file.listFiles();
for (File file1 : files) {
//取文件名
String file1Name = file1.getName();
//文件的路径
String path = file1.getPath();
//文件的内容
String fileContext = FileUtils.readFileToString(file1, "utf-8");
//文件的大小
long size = FileUtils.sizeOf(file1);
//创建Field
//参数1:域的名称,参数2:域的内容,参数3:是否储存
Field fieldName = new TextField("name", file1Name, Field.Store.YES);
Field fieldPath = new TextField("path", path, Field.Store.YES);
Field fieldContext = new TextField("context", fileContext, Field.Store.YES);
Field fieldSize = new TextField("size", size + "", Field.Store.YES);
//创建文档对象
Document document = new Document();
//4.向文档对象中添加域
document.add(fieldName);
document.add(fieldPath);
document.add(fieldContext);
document.add(fieldSize);
//5.把文档对象写入索引库
indexWriter.addDocument(document);
}
//6.关闭indexWriter对象
indexWriter.close();
}
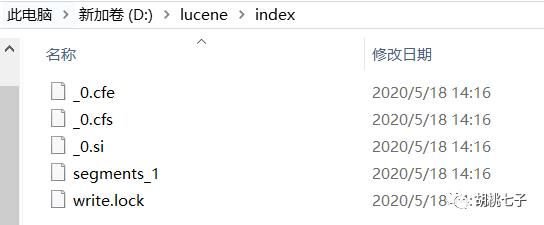
执行代码,索引文件生成如下:
3.2.2、查询索引
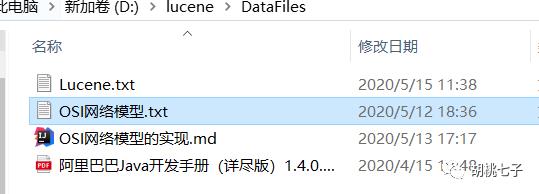
这是我之前用来创建索引文件的数据文件。
@Test
public void testTermQuery() throws Exception {
FSDirectory directory = FSDirectory.open(Paths.get("D:\\lucene\\index"));
IndexSearcher is = new SearcherManager(DirectoryReader.open(directory), new SearcherFactory()).acquire();
// 查询filed为name,文本为java
Term t = new Term("name", "java");
// 为Term构造查询。使用Term,d必为单词,不然查不到
Query query = new TermQuery(t);
TopDocs hits = is.search(query, 10);
// hits.totalHits:命中的总次数。即在几个文档中查到给定单词
System.out.println("匹配 'java',总共查询到" + hits.totalHits + "个文档");
for (ScoreDoc scoreDoc : hits.scoreDocs) {
Document doc = is.doc(scoreDoc.doc);
System.out.println(doc.get("name"));
}
}
执行上述查询代码,输出结果如下:
匹配 'java',总共查询到1个文档 阿里巴巴Java开发手册(详尽版)1.4.0.pdf
这里只介绍了TermQuery的查询方式,后面会更新各种Query的使用方式。
3.3、总结
lucene整体使用上不难,但是用好,以及对细节上的理解和使用,确也不简单。重点对象:Field、Document、IndexWriter、IndexSearcher和Query。
做积极的人,而不是积极废人!
往期文章
点个「在看」!
以上是关于lucene之filed详解和代码测试的主要内容,如果未能解决你的问题,请参考以下文章