lucene之分词器和Luke工具介绍
Posted 胡桃七子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lucene之分词器和Luke工具介绍相关的知识,希望对你有一定的参考价值。
做积极的人,而不是积极废人!
1、分词器
在搜索时,我们通常通过词来搜索目标文本,所以我们在创建索引的时候要对文本进行分词处理。在lucene中有个Analyzer类,他是一个abstract class,他的主要实现是createComponents(String fieldName);的抽象方法,所以其分词的具体规则由子类实现。从而实现一个分词器只要Override这个方法就可以了。
本文介绍一下常用的分词器:
标准分词器:也叫单字分词,将中文一个字一个字的分词。
简单分词器:根据标点符号进行分词。
二分法分词器:两个字两个字进行分词。索引文件大且耗时比较
空格分词器:根据空格进行分词
IK中文分词器:采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和智能分词两种切分模式。
详细介绍一下IK中文分词器(GoogleCode 官网介绍):
IK Analyzer 是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。
2.Luke
2.1、介绍
Luke是用于反应Lucene / Solr / Elasticsearch索引的GUI工具。它允许:
浏览您的文档,索引词和过帐列表
搜索索引
执行索引维护:索引运行状况检查,索引优化(运行此文件之前先备份!)
测试您的自定义Lucene分词器(Tokenizer / CharFilter / TokenFilter)
Luke在lucene 8.1后,Luke将做为lucene的一个模块,可以下载lucene的二进制包获取Luke工具。
2.2、使用
启动下载文件中的
文件。然后选择你的索引文件目录
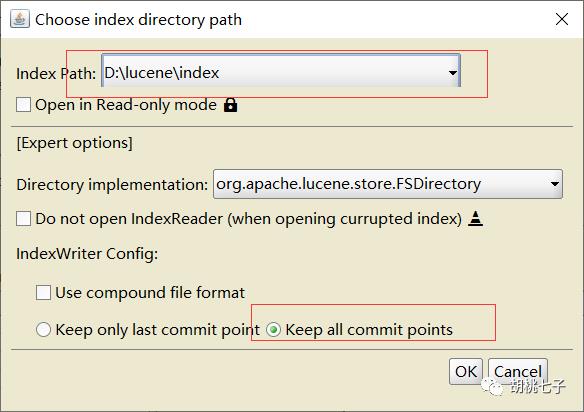
3、StandardAnalyzer
我们先用标准分词器,创建一下索引,使用之前的测试案例代码。
@Test
public void createIndex() throws Exception {
//1.创建一个Director对象,指定索引库的位置。
//把索引保存在磁盘中
Directory directory = FSDirectory.open(new File("D:\\lucene\\index").toPath());
Analyzer analyzer = new StandardAnalyzer() ; //标准分词器
// Analyzer analyzer = new SimpleAnalyzer() ; //简单分词器
// Analyzer analyzer = new StopAnalyzer() ; //停用词分词器
// Analyzer analyzer = new WhitespaceAnalyzer() ; //空格分词器
// Analyzer analyzer = new CJKAnalyzer();//二分法分词器
// Analyzer analyzer = new IKAnalyzer(); //中文分词器
IndexWriterConfig config = new IndexWriterConfig(a);
//2.基于Directory对象来创建一个indexWriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
//3.读取磁盘上的文件,对应每个文件创建一个文档对象。
File file = new File("D:\\lucene\\DataFiles");
File[] files = file.listFiles();
for (File file1 : files) {
//文件名
String file1Name = file1.getName();
//文件路径
String path = file1.getPath();
//文件内容
String fileContext = FileUtils.readFileToString(file1, "utf-8");
//文件大小
long size = FileUtils.sizeOf(file1);
//创建Field 参数1:域的名称,参数2:域的内容,参数3:是否储存
Field fieldName = new TextField("name", file1Name, Field.Store.YES);
Field fieldPath = new TextField("path", path, Field.Store.YES);
Field fieldContext = new TextField("context", fileContext, Field.Store.YES);
Field fieldSize = new TextField("size", size + "", Field.Store.YES);
//创建文档对象
Document document = new Document();
//4.向文档对象中添加域
document.add(fieldName);
document.add(fieldPath);
document.add(fieldContext);
document.add(fieldSize);
//5.把文档对象写入索引库
indexWriter.addDocument(document);
}
//6.关闭indexWriter对象
indexWriter.close();
}
使用Luke工具查看
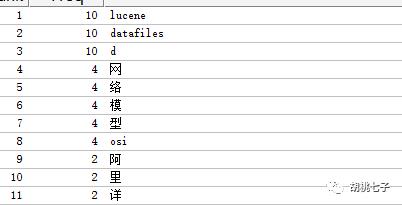
可以看出英文可以很好的分词,而中文每个字都被分成了一个词。
4、IKAnalyzer
4.1、默认词典分词
其它分词器,就不介绍了。介绍下国内用得最多的IKAnalyzer分词器。因为它是第三方的包,所以需要引入一下jar包:
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>7.0.0</version>
</dependency>
使用IKAnalyzer创建下索引,然后使用Luke工具查看。
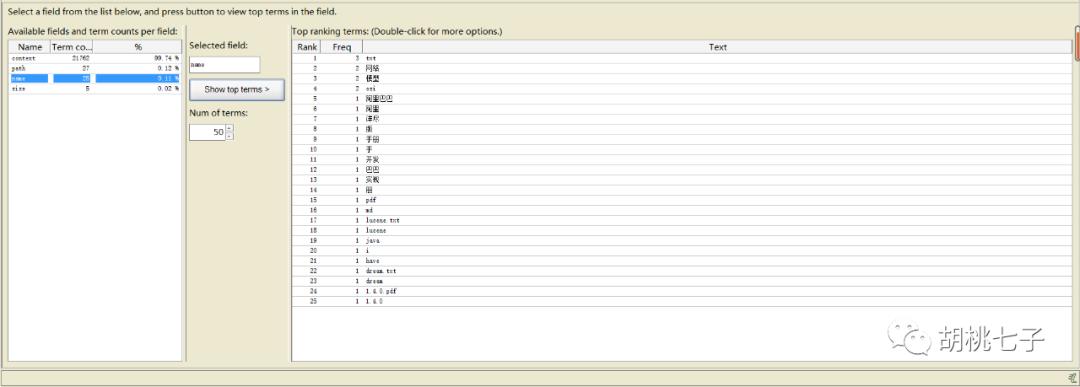
可以发现对中文分词很友好。不像其它分词器的规则比较死,不灵活。
4.2、扩展词典
我们可以看得上面“网络模型”不是一个词,现在我们扩展词典,在sources目录下,添加ext.dic文件,
注意:一行代表一个词
重新生成索引,使用Luke工具查看。
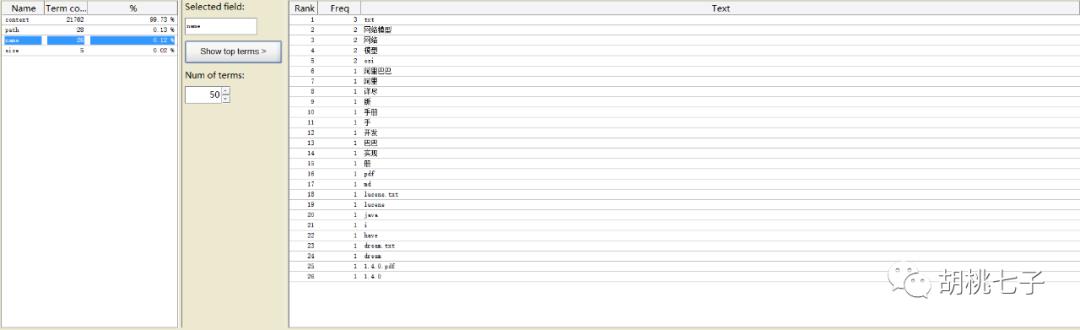
”网络模型“被成功分词。
5、总结
对比之后,更加推荐使用IKAnalyzer分词器,不仅对中文比较友好,还可以自定义词典。
往期文章
点个「在看」!
以上是关于lucene之分词器和Luke工具介绍的主要内容,如果未能解决你的问题,请参考以下文章