原创Lucene001--介绍和入门
Posted 后端技术驿站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了原创Lucene001--介绍和入门相关的知识,希望对你有一定的参考价值。
一、什么是Lucene
Lucene是apache下的一个开源的全文检索引擎工具包。它为软件开发人员提供一个简单易用的工具包(类库),以方便的在目标系统中实现全文检索的功能。
二、全文检索的应用场景
2.1搜索引擎
搜索引擎.PNG
2.2站内搜索
站内搜索.png
2.3文件系统的搜索

文件系统搜索.png
总结:Lucene和搜索引擎是不同的,Lucene是一套用java或其它语言写的全文检索的工具包。它为应用程序提供了很多个api接口去调用,可以简单理解为是一套实现全文检索的类库。搜索引擎是一个全文检索系统,它是一个单独运行的软件系统。
三、全文检索的定义
全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
四、Lucene实现全文检索的流程
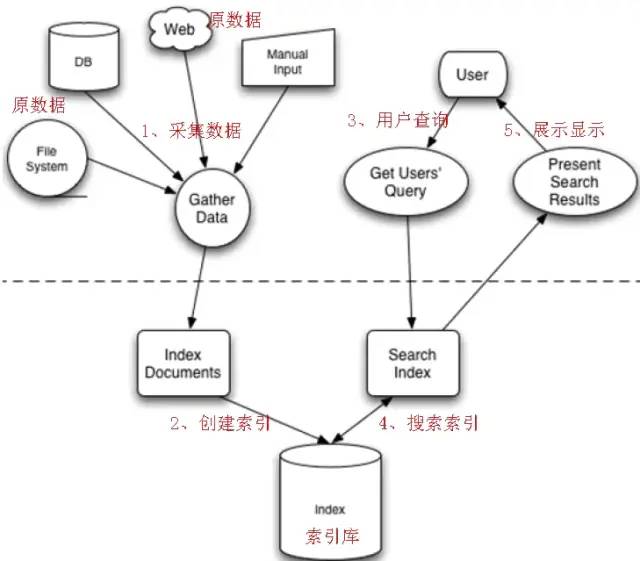
流程.png
全文检索的流程分为两大部分:索引流程、搜索流程:
索引流程:即采集数据-->构建文档对象-->分析文档(分词)-->创建索引。
搜索流程:即用户通过搜索界面-->创建查询-->执行搜索,搜索器从索引库搜索-->渲染搜索结果。
Lucene本身不能进行视图渲染。
五、入门程序
5.1需求
使用lucene完成对数据库中图书信息的索引和搜索功能。
5.2环境
Jdk:1.7及以上
Lucene:4.10(从4.8版本以后,必须使用jdk1.7及以上)
Ide:indigo
数据库:mysql
5.3数据库脚本

数据库脚本.PNG
5.4Lucene下载
Lucene是开发全文检索功能的工具包,使用时从官方网站下载,并解压。
官方网站:http://lucene.apache.org/
目前最新版本:5.4.0
下载地址:http://archive.apache.org/dist/lucene/java/
下载版本:4.10.3
JDK要求:1.7以上(从版本4.8开始,不支持1.7以下)
1.png
2.png
3.png
4.png
5.5工程搭建
所需要的jar包:
mysql5.1驱动包:mysql-connector-java-5.1.7-bin.jar
核心包:lucene-core-4.10.3.jar
分析器通用包:lucene-analyzers-common-4.10.3.jar
查询解析器包:lucene-queryparser-4.10.3.jar
junit包:junit-4.9.jar(非必须)
工程.PNG
5.6实现全文检索
第一步:索引流程
对文档索引的过程,就是将用户要搜索的文档内容进行索引,然后把索引存储在索引库(index)中。
1.为什么要采集数据
全文检索搜索的内容的格式是多种多样的,比如:视频、mp3、图片、文档等等。对于这种格式不同的数据,需要先将他们采集到本地,然后统一封装到lucene的文档对象中,也就是说需要将存储的内容进行统一才能对它进行查询。
2.采集数据的方式
对于互联网中的数据,使用爬虫工具(http工具)将网页爬取到本地
对于数据库中的数据,使用jdbc程序进行数据采集
对于文件系统的数据,使用io流采集
因为目前搜索引擎主要搜索数据的来源是互联网,搜索引擎使用一种爬虫程序抓取网页( 通过http抓取html网页信息),以下是一些爬虫项目:
Solr(http://lucene.apache.org/solr) ,solr是apache的一个子项目,支持从关系数据库、xml文档中提取原始数据。
Nutch(http://lucene.apache.org/nutch), Nutch是apache的一个子项目,包括大规模爬虫工具,能够抓取和分辨web网站数据。
heritrix(http://sourceforge.net/projects/archive-crawler/files/),Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
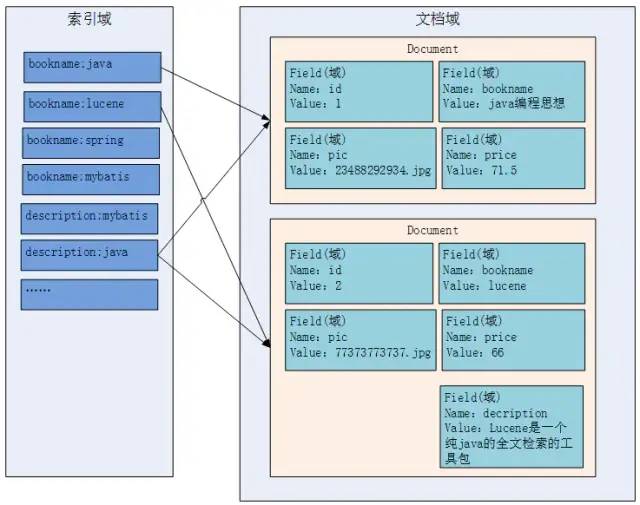
3.索引文件的逻辑结构
索引文件的逻辑结构.PNG
文档域:
文档域存储的信息就是采集到的信息,通过Document对象来存储,具体说是通过Document对象中field域来存储数据。
比如:数据库中一条记录会存储一个一个Document对象,数据库中一列会存储成Document中一个field域。
文档域中,Document对象之间是没有关系的。而且每个Document中的field域也不一定一样。
索引域:
索引域主要是为了搜索使用的。索引域内容是经过lucene分词之后存储的。
倒排索引表
传统方法是先找到文件,如何在文件中找内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大就搜索慢。
倒排索引结构是根据内容(词语)找文档,倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它是在索引中匹配搜索关键字,由于索引内容量有限并且采用固定优化算法搜索速度很快,找到了索引中的词汇,词汇与文档关联,从而最终找到了文档。

十年IT老兵,专注后端技术
以上是关于原创Lucene001--介绍和入门的主要内容,如果未能解决你的问题,请参考以下文章