数据结构与算法练习一
Posted 什么你又懂了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法练习一相关的知识,希望对你有一定的参考价值。
很多人(包括我)第一次看到数据结构与算法这个名字时可能会懵,在想这好深奥的感觉噢,为什么”我“要去了解或者学习呢?其实不然,他并不只与计算机这门专业有关,而是涉及了几乎所有的学科领域,还有我们日常的生活。
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合,算法是指解题方案的准确而完整的描述,代表着用系统的方法描述解决问题的策略机制。数据结构+算法=程序。(以我的理解)通俗地讲,数据结构是一系列相关联的事物,算法是使用这些数据解决不同问题的途径。例如,从惠州出发到达深圳校区有许多不同的路线(汽车、火车、大巴...),这些路线的集合就可以看作是一种数据结构(称之为“图”),我们该如何选择算法呢,是坐汽车直接从自家楼下到达学校门口这种时间更少但难预约花费高的方法,还是坐火车这种花费一般较小但是需要转车的方法,还是坐大巴这种方便的方法呢?当然,需要根据具体的情况选择最优的方法,而不是随缘乱选,亦或是抛开数据空谈算法。算法是和数据紧密相关的!
上面那个简单的例子就是我们经常碰到的例子之一,其他的在这也不一一列举了。下面就是我的龟速刷题和总结啦,可能题目偏理论,我的某些解法也不是最好的,但我会试着尽量用我自己的简洁的语言描述出思路和解题方法,希望大家能理解就算一丢丢,最后po出我那又臭又长的代码哈哈~
在这之前,还需要搞懂两个简单而又非常重要的概念,空间复杂度和时间复杂度,他们会贯穿我们接下来的一切学习。简单来说空间复杂度指储存数据使用的空间,时间复杂度指算法进行需要消耗的时间数量级。好的算法在空间复杂度和时间复杂度上都要最小。一般空间复杂度难以计算,时间复杂度的计算准则为:假设需要花费常量时间例如1,2,3,4...秒这样,时间复杂度就是O(1),当需要花费1/2*n^2+1/2*n+1这样的带幂次的时间时,我们只看最高幂次n^2,并省略其系数(因为一般情况下操作量或数据量n越大,n的平方自然远大于后面加的数,时间复杂度为O(n^2)。当为(n-1)^2这种情况时,也看成n^2。还有时间复杂度为O(logn)等情况,讨论类似,去掉前面的系数和其他影响较小的时间,用占比最大的时间情况表示。
一般讨论时间复杂度以最坏情况下的时间复杂度为主,偶尔出现平均时间复杂度。
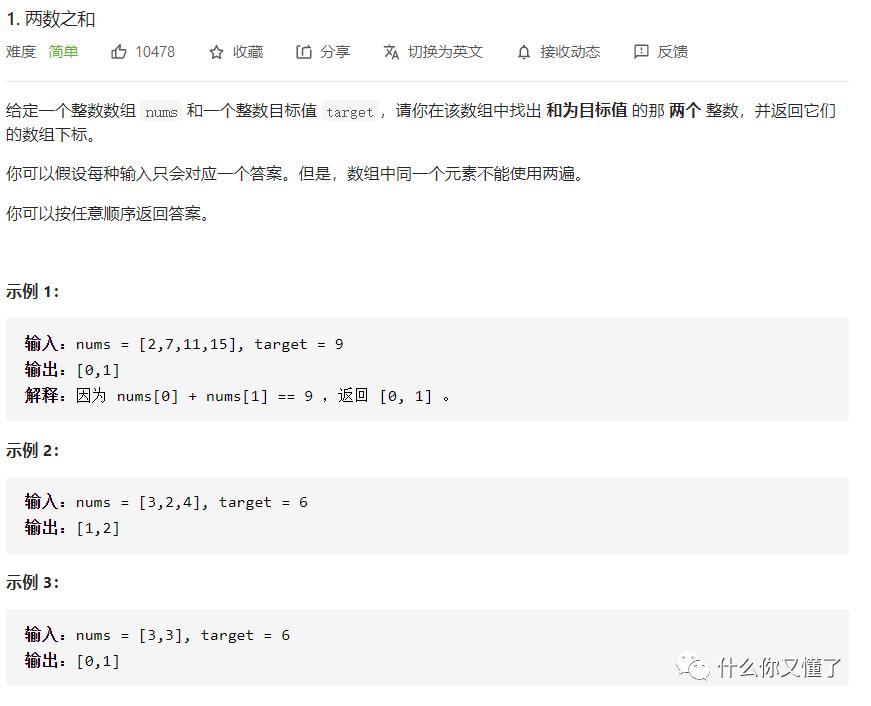
第一题是一道难度简单的题目,求两数之和的位置(下标)。数据结构是一组数组(数列),我们的任务就是找出数列中需要的两个数分别是数列的第几个,他们之和已由问题给出。(一个位置上的数只能使用一次)。
一般编程语言的数组下标从0开始。观察上图示例一,名叫nums的数列中含有四个元素2,7,11,15,与之对应的下标为0,1,2,3。题目中给出的target和为9。用肉眼都可看出2+7=9。于是返回2和7的下标0和1。其他实例分析类似。
第一次通过使用的是暴力法迭代,简单理解就是第一次循环固定第一个数2,然后从下一个数7开始,一一判定两者相加是否为目标9,若不是,则2依然不动,选择7的下一个数11判断,直至到数组末尾。第二次循环则是固定第二个数7,从7的下一个数11开始,判断7+11是否为9,若不是,依次类推固定7,选择11的下一个数15...重复上述过程,当找到两数之和为9时,输出下标即可。
我的代码如下

时间复杂度上,假设数组有n个元素。每次循环选取固定一个元素,并从该元素的下一个元素找起,直至数组末尾。讨论最坏情况下的时间复杂度,假设每次操作(判断是否相等)花费时间复杂度O(1),当最后找到时,需要的时间为(n-1)+(n-2)+...+1=O(n^2)。时间复杂度较大,一般不用那么暴力的方法哈哈。
于是想到能不能用字典的方法查找,字典也是一种数据结构。从字面意思理解字典即可。在平常查字典中,使用拼音即可查到想要的字词,于是一个拼音对应一个字词(不考虑一对多的映射关系,只考虑一对一)。于是字典的元素表示为key:value。键值key和对应的数值value。查找key可以得到它所对应的value。(举例,每个同学分别有个自己的成绩,小明:90分,小方:87分,查找小明,可以得到他的分数90分,他们是一一对应的)。

于是此题中将key值指代元素的值,value指代下标。一一将字典元素放进字典集合map中。查找a+b=9,即当a在集合中时查找b=9-a是否也在集合中,若在,即可得到元素a和b的下标,输出即可。时间复杂度在理论上为将元素和对应下标表示为字典的O(n)(n个元素,每次操作为放进一个字典元素,时间复杂度O(1))。查找元素时间复杂度O(n),因为可能从头找到尾最后才找到。总时间复杂度为O(n)+O(n)=O(n)记得去掉前面的系数2噢。
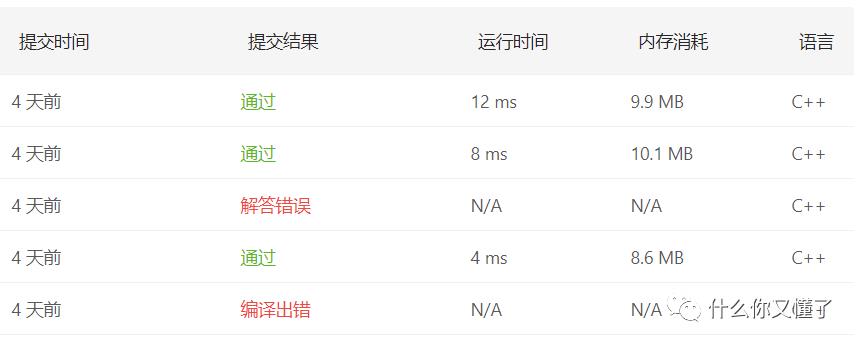
但是看通过的图示,为什么较好方法时间复杂度反而高呢。前者为4ms,后者为8ms。在此留下个疑问?我初步的理解是,可能在这数据量较小的情况下,插入insert,查找find的操作需要的时间更多。(举个例子1/2*n^2+n+100,当n很大时,n^2占主要时间,但当n很小为1时,常数100远大于前面的二次方项了。)为此可能是这个原因(我不一定对蛤!!!)还需要我去找找为什么,问下老师,再来告诉大家~
如图所示测试数据为53个,还算小的。
下面是第四题吼!(按照他的题目顺序给出)
困难级别,一看就很难的样子(不是)
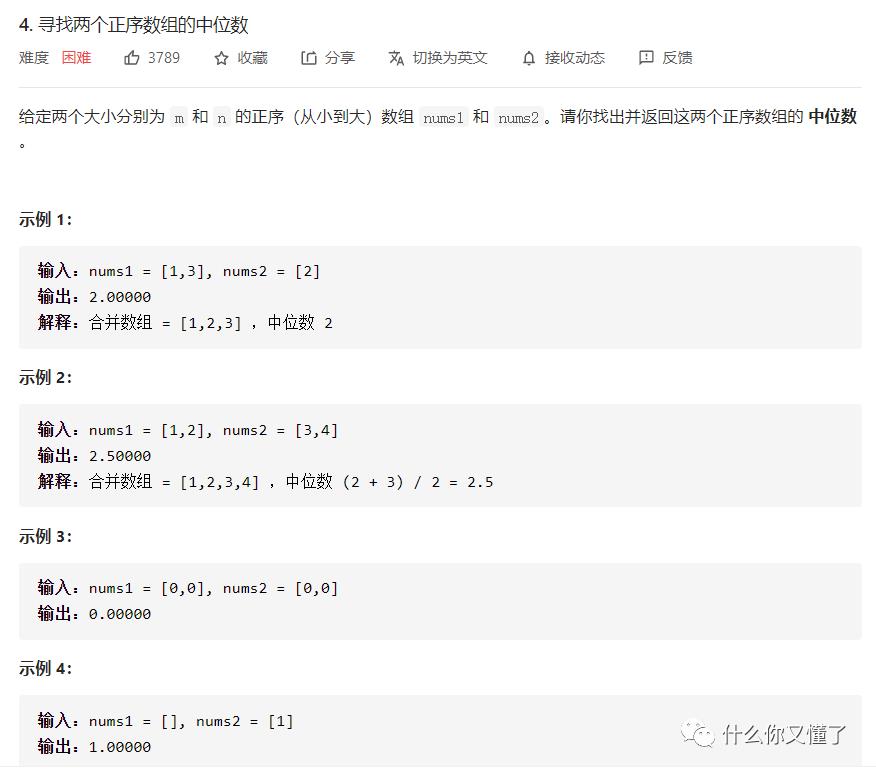
就是两个数组nums1和nums2都是从小到大正序排列的数组,将他们合在一起,找出中位数即可。

第一种方法是,直接将第二个数组插入到第一个数组末尾,使用函数insert。然后将第一个数组排正序(第一个数组此时已经由原先的两个数组组合而成),再找出中位数即可,十分简单。
时间复杂度由排序的方法决定,一般情况下默认快速排序,时间复杂度为O(nlogn)。
然后想到一种时间复杂度为O(m+n)的方法,用两个箭头(指针)分别指向两个数组的第一个元素,然后将第二个数组箭头所指元素插入到相应位置,
有四种情况考虑:

当数组2箭头所指元素小于数组1的首个元素,则插入数组1的头部,数组1的其余元素均向右移动一位。数组2箭头所指的元素向右移动一位(原来的已插入不用管)
当数组2所指元素大于等于数组1箭头所指元素,小于等于数组1箭头所指元素的下一个元素,即可将其插入数组1两个元素之间。数组1和数组2箭头所指元素向右移动一位。
当数组2箭头所指元素大于数组1箭头所指元素,也大于数组1箭头所指元素的下一位元素,则将数组1箭头向右移动一位,继续比较。
当数组2箭头所指元素大于数组1最后一个元素,因为数组2呈升序排列,则将数组2箭头所指元素及后面的元素全部插入数组1的末尾即可。
这样得到的数组1即已经是呈升序排列的,不用再排序,直接找出中位数即可。时间复杂度上,两个箭头依次遍历两个数组,因为数组大小为m和n,故时间复杂度(最坏)为O(m+n)。
测试例子很多,有2094个哈哈,通过的情况如下
第二个方法毕竟是自己实现的(没使用内置插入insert函数和排序sort函数那些),所以可能相对工程师所写的函数来说时间复杂度上稍微多了那么一点,4毫秒左右。可以理解哈哈
更好的方法是时间复杂度为O(log(m+n))的,使用二分查找的思想,这个以后再补充啦,应该还是能写出来的吧哈哈。
第一次写正式推送,其实写了几道题的,但是解释起来还真是没那么简单,毕竟当初自己每道题也写了好久好久。所以最终呈现的只有两道题先。想了想,数据结构与算法我目前主要偏刷题,可能有些枯燥,于是乎打算以分析介绍有意思的题或难题为主,其他题就直接附上代码和少许解释,大家可能比较好接受,主要看个思想嘛。我这不是偷懒!
机器学习部分可能比较有意思,其中的内容更有吸引力,在这就可能偏向科普和具体的实现和应用啦,至少没数据结构与算法那么恐怖哈哈哈!像什么车牌识别啊等等等等。希望能用我浅薄的知识帮助大家能了解一点是一点,对于我而言就是更好的理解和使用了。
可能推送中存在错误,大家可以大胆的指出来,这记录的就是我的一个学习过程,难免会走错路嘛,大家看的角度毕竟比我广很多。有更好的方法或感兴趣的平常也可以一起讨论!
谢谢大家阅读(如果有看到这的哈哈,下次见!
以上是关于数据结构与算法练习一的主要内容,如果未能解决你的问题,请参考以下文章