云原生时代的 Alinode
Posted Alibaba F2E
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生时代的 Alinode相关的知识,希望对你有一定的参考价值。
Alinode 作为一款强大的 Node.js 性能诊断产品,服务了阿里集团内外很多的 Node.js 开发者,帮助他们定位、解决了大量性能相关问题,有着良好的口碑。随着云原生时代的到来,Serverless 浪潮席卷了整个开发者社区,Node.js 也不例外,Alinode 如何在去发挥更大的价值,是我们在接手 Alinode 品牌后一直在思考的事情,过去的一年,我们给 Alinode 定义了两个发展方向:观测性和调度性,简单给大家分享一下我们围绕这两个方向做的一些事情。
平台
从平台出发,我们将两个产品的能力进行了融合成了新的平台 Alinode Insight,将平台定位由性能平台转向了全方位的应用监控与错误追踪平台,能够协助用户更快地发现、解决问题。
在传统 Node.js 应用场景,开发者对应用本身可掌控的程度比较高,会有很多手段来观测应用状态、排查应用问题,动手能力强的也会根据需求搭建业务所需的平台。相对来说,观测平台作用更多的是辅助开发者的工作,作为一个白屏化操作的工具。
然而,在 Serverless 的模式下,开发者除了代码,能接触到的细节基本被屏蔽,更多的是依赖各种平台提供的服务来管理,所以观测平台的能力越发显得重要起来,要能够给用户提供全面的观测体系,帮助用户剖析代码运行的过程。
我们从一些案例出来,来看下观测平台发挥的作用。
流量状态
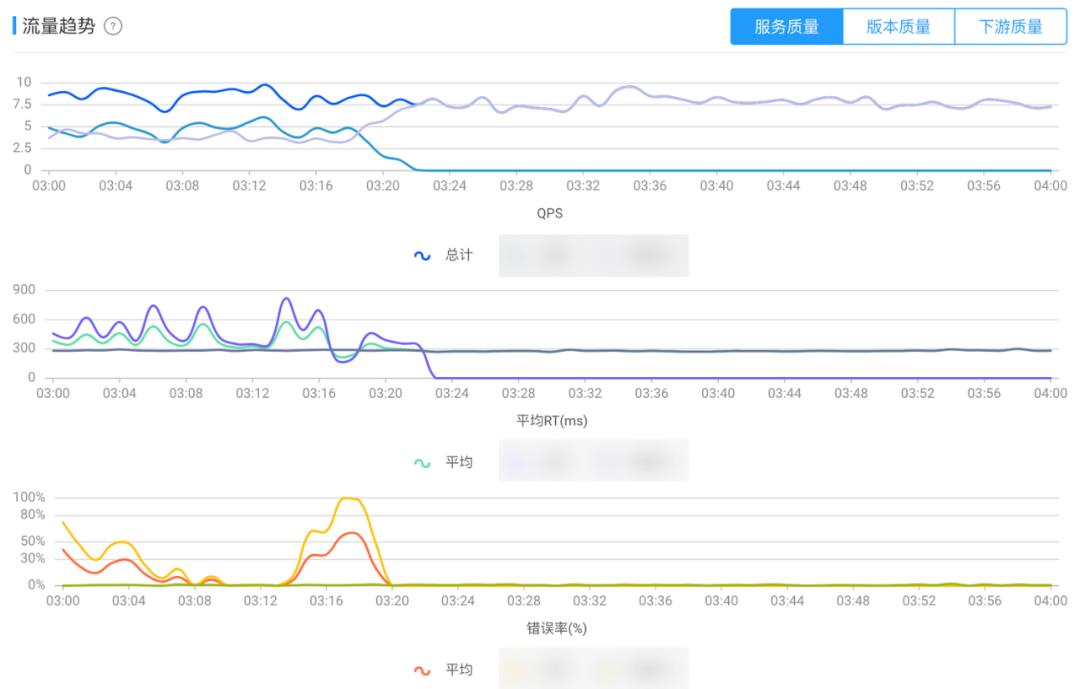
用户收到函数成功率下降报警,通过流量趋势可以看到,在 03:16 分左右,某单元异常率上升,马上根据预案采取措施,将风险屏蔽。
另一个比较常见的情况,函数下游经常会发生抖动,通过链路信息,我们可以快速的发现异常的服务:
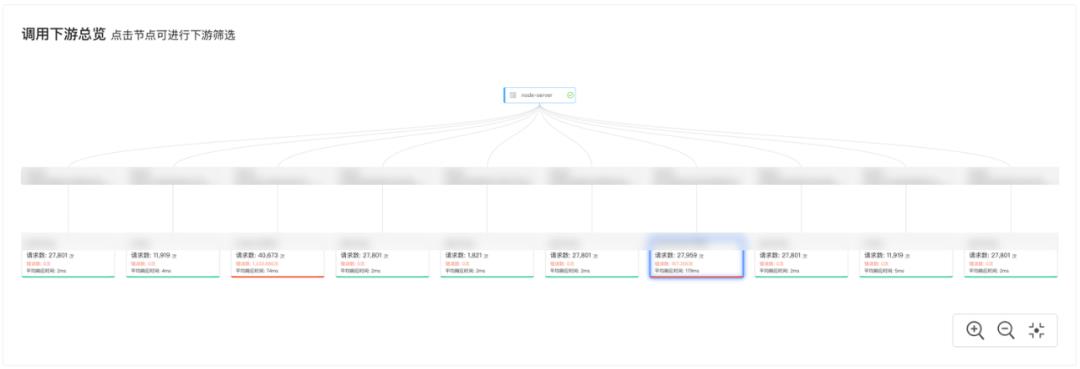

可以看到是某一单元的下游服务发生了异常,从而采取相关的预案来规避风险。
当然,这些数据的展示,都是观测平台的基本能力,下面我们看一些跟函数开发更相关的能力,目前这些能力主要和阿里云函数计算团队合作。
白屏化日志
函数发布后,不能像之前应用一样,登陆到服务器上查看日志,这对用户排查问题造成了很大的困扰。
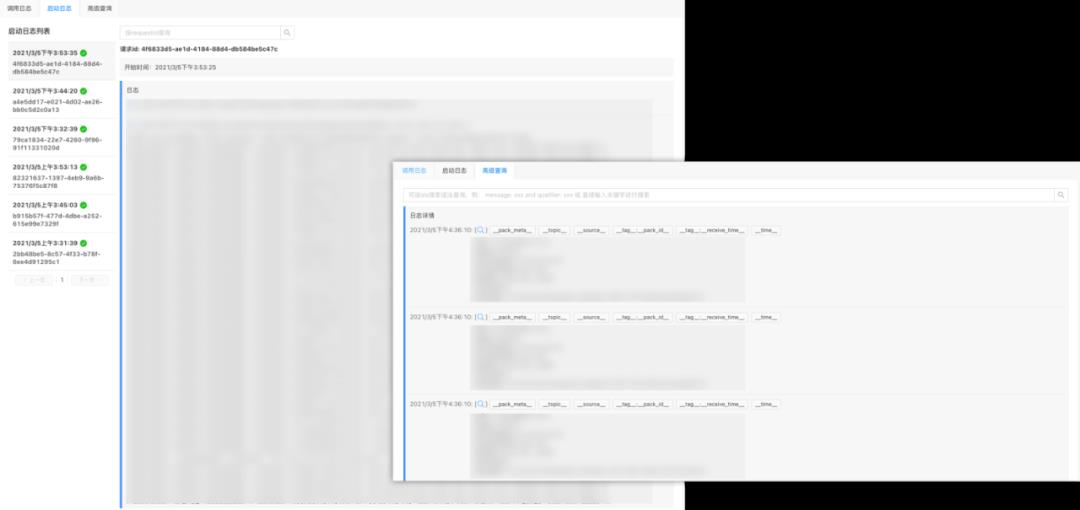
为此,我们提供了函数产生的所有日志的查询能力,可以查看每一次请求所产生的日志,同时在链路、日志、异常间建立了联系,这样能够更方便的定位问题,当然也包括对日志上下文的查询。
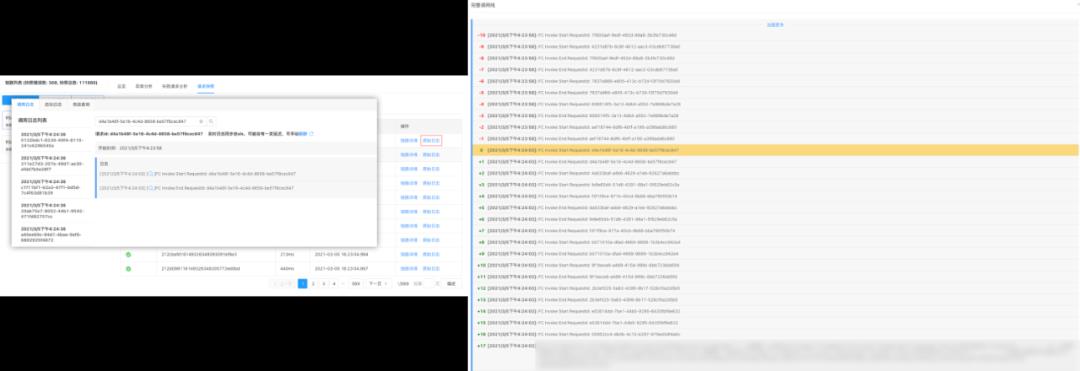
还可以通过启动日志定位函数或者应用迁移后在启动过程中遇到的问题,以及通过 SLS 查询语法,进行高阶查询。
远程调试
如何在运行环境中调试函数,也是用户碰到的一个难点,因为函数计算的特殊运行架构,传统手段难以实施。虽然阿里云函数计算控制台提供了在线编辑、发布、运行的能力,但用户往往会陷入“改代码加日志→发布→访问→查日志”这样的循环,效率比较低。
为了提升排查效率,我们将远程调试能力在阿里云函数计算环境实现了落地,目前在部分区域灰度中,相信大家很快就可以用上了,可以先通过动图感受一下(正式上线 UI 可能略有变化)。
崩溃分析
在使用函数计算的用户,日常比较常遇到的情况就是函数挂掉了,但是不知道为什么挂掉,之前还可以通过 coredump 分析,但现在只能通过日志来获得信息。
我们从 Node.js 本身找到了解决方案,在 Node.js v12 之后集成了 Report API,能够在进程异常退出的时候生成 Diagnostic report,类似 Alinode 之前提供的能力,只不过更加详细。通过这份报告,我们可以查看 javascript 和 native 堆栈信息,堆统计,平台信息,资源使用情况等,为排查工作提供更多数据支持。
目前我们在内部实践验证这个能力,会尽快和函数计算团队配合,开放到公有云中。
以上这些能力,会封装成一个开箱即用的解决方案,在函数计算团队后续的发布会中,开放使用。除了和函数计算团队的合作,我们还和阿里云的 ARMS 团队有良好的合作,在 Node.js 可观测性上发力,后续也能慢慢看到这些能力的开放。
标准化
在平台之下,我们在观测数据标准化上,也做了不少工作。
Alinode 诊断探针
随着 Node.js 应用规模的扩大,社区用户对 Diagnostic 的需求也越来越多,因此 Node.js 专门成立了 Diagnostics Working Group,里面有很多 APM 厂商以及兴趣相投的人,比如我们熟知的 Joyee Cheung。
通过这个工作组,更多的 Diagnostic 能力被整合到了 Node.js 本身,相比于 Alinode,仅在 GC 指标、数据导出、信号量处理上有些差异,完全可以通过 addon 的形式抽离出来,更容易通过 npm 组件分发以及部署,也更符合社区的需求。如果需要特定的 API,也会通过社区提案方式申请开放,减少对原生版本的修改。这跟很多 APM 的思路是类似的,比如像 Easy-Monitor。
推动标准
Pandora.js 作为一个开源产品,可能会面对用户形形色色的已有系统,如何能将数据和平台解耦,让其具有普适性。
我们从云原生体系中找到了答案——OpenTelemetry,它整合了 OpenTracing 和 OpenCensus,已经成为了云原生监控方向上的首要标准,具有良好的普适性,正是我们所需要的,所以我们将 Pandora.js 的数据体系基于 OpenTelemetry 进行了重构,使用标准的 metrics,traces,logs 格式,通过 exporter 实现跨平台能力。同时,这个标准还是在发展中,我们还可以在使用的同时参与到它的建设中,将我们的想法和众多同道中人碰撞,产生更多有意义的内容。
另一个我们在积极推进的就是「Async Context for JavaScript」提案,它影响着目前 Node.js Async Hooks,Async Storage 等能力的性能和接口,对 Node.js 无感知链路追踪的实现有着重大意义,也是很多 Node.js 开发者关注的功能,能为很多场景带来更好的体验。
除了这些,团队还提出了国内第一个 Stage 3 提案「Error Cause」。
Alinode Runtime 诞生之初就是希望能够帮助用户更高效的解决 Node.js 的疑难杂症,从过往来看也不辱使命。现在的云原生时代,仍会有更多新的问题等待着 Alinode Runtime 去突破。在过去的一年,我们主要“成本”和“性能”间寻求平衡。
加载速度优化
众所众知,Serverless 能够有效的优化成本,而“弹性”则是这一过程必不可少的手段。为了更好的实现弹性,启动速度是很关键的一环。因此,上一年,我们一直在探索降低 Node.js FaaS Runtime 的启动时间,取得了不错的效果,但我们重点是在 Runtime 本身的优化,是针对特定、可控的代码优化,不具备普适性,从实际的落地效果来看,整体函数可服务时间里,用户代码加载耗时比重远高于 Runtime 本身,如果能把这部分耗时缩短,那么效果会更加明显。
用户代码加载时间优化主要有两个难点:
依赖多样且复杂,存在大量状态
优化不能让用户有感知
已知最有可能的方案,就是 V8 提供的 Snapshot 能力,将用户的运行后的内存状态存储,然后在需要的时候还原。但实现起来,用户负责的代码状态很难维护,包括 Node.js 本身在 Snapshot 上的使用也进展缓慢,而且也难以随着应用在不同机器间分发。
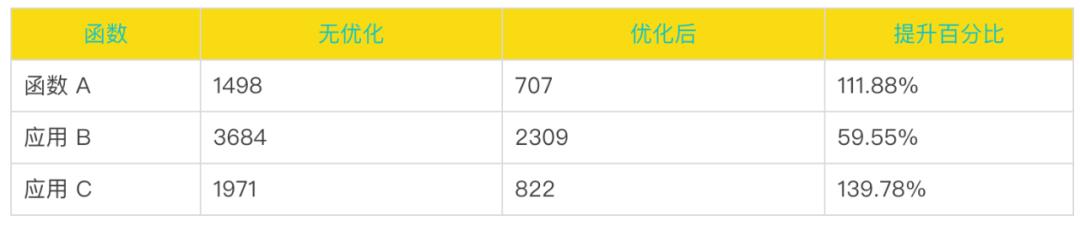
在计算机领域,我们常用的两个优化手段:空间换时间,时间换空间。我们希望在时间上取得收益,就得在空间上有所投入。为此我们设计了一个存储结构,将用户引用的所有内容存储起来,在启动加载时,根据这个结构来加载依赖,能够大幅减少系统调用的开销。这个结构可以在构建或者部署前生成,用一次构建的消耗时间,能够换来在实际生产环境的加载时间大幅缩短,是很值得的。
目前,从我们在业务落地的效果来看,收益还是很可观的,部分数据如下(包含网络开销):
弹性效率优化
在认知上,我们认为 Serverless 应该是毫秒级弹起、亚秒级交付的,是能实现资源高效利用的,但现状远远低于预期。为此,我们也在思考,从 Alinode Runtime 视角,怎么能够优化弹性效率,实现高效资源利用。我们从现状整理了三个问题:
函数容器能否启动的更快
资源成本能否再压榨
函数能否加载的更快
解决这个问题,我们首先想到一个词就是“高密度部署”,通过将多个函数部署在同一个实例中,充分利用实例性能,减少资源浪费。以零弌在 D2 分享中的一张图为例,让函数以更小的资源(0.5C512M)运行在实例(4C8G)中,能够同时运行更多的实例。

另一个比较容易理解的例子,我们最常使用的 Chrome 浏览器。当你打开比较多的页面时,我们可以通过点击右上角“选项”→“更多工具”→“任务管理器”打开一个 Chrome 的任务管理器窗口,可以看到每个打开的 Tab 都对应着一个进程,里面还包括使用的扩展。
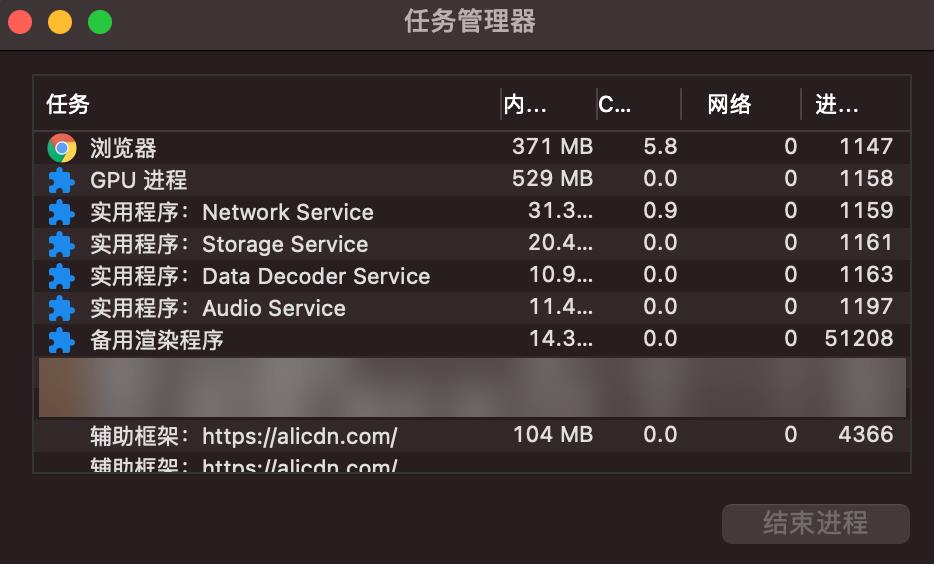
这正是 Chrome 采用的多进程架构,每个选项卡都拥有独立的渲染器进程。如果一个选项卡没有响应,则可以关闭无响应的选项卡,并继续使用,同时保持其他选项卡处于活动状态。如果所有选项卡,都在一个进程上运行,则当一个选项卡无响应时,所有选项卡都不会响应。这样做的另一个好处就是,可以提供安全性和沙盒能力,能够通过对进程权限的限制,比如:限制文件读写权限等。
但是进程多了,资源消耗也会增加,对此,Chrome 会将很多公共能力服务化,在受限的情况下跑在一个进程里,从而节省内存。

如果将这套架构和之前高密度部署结合,就可以在控制函数资源使用的情况下更好的利用资源。
那如何能够让函数启动的更快呢?Cloudflare 给了我们一个很好的思路,通过提供有限的运行时能力,减少进程启动时加载的内容,来让进程启动的更快。有舍必有得,更快的启动速度,让弹性更加具有意义。
综合上面的一些思考,我们实现了 Alinode Cloud Runtime 架构,一套面向 OCI 标准的 Node.js Serverless 基础平台,在内部实际落地中,取得了不错的成本控制效果。
之后,我们会在大促等极限场景更好的进行验证,也希望能够早日对外开放使用,为 Node.js FaaS 提供一种新的想象。
云原生时代,带来了很多契机,Alinode 即是受益者,也是参与者,我们希望:
通过 Alinode Insight,希望能够帮助开发者快速掌握 Serverelss 的研发模式,解决遇到的各种问题;
通过 Alinode Cloud Runtime,实现在 Serverless 时代的转型,由 Runtime 参与者变成定义者。
你可能还喜欢
以上是关于云原生时代的 Alinode的主要内容,如果未能解决你的问题,请参考以下文章