Web缓存 - HTTP协议缓存
Posted 前端布道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Web缓存 - HTTP协议缓存相关的知识,希望对你有一定的参考价值。
为什么要使用 Web 缓存
Web缓存一般分为浏览器缓存、代理服务器缓存以及网关缓存,本文主要讲的是 浏览器缓存,其它两种缓存大家自行去了解下。
Web 缓存游走于服务器和客户端之间。这个服务器可能是源服务器(资源所驻留的服务器),数量可能是1个或多个;这个客户端也可能是1个或多个。Web 缓存就在服务器-客户端之间搞监控,监控请求,并且把请求输出的内容(例如html页面、 图片和文件)(统称为副本)另存一份;然后,如果下一个请求是相同的 URL,则直接请求保存的副本,而不是再次麻烦源服务器。
使用缓存的2个主要原因:
降低延迟:缓存离客户端更近,因此,从缓存请求内容比从源服务器所用时间更少,呈现速度更快,网站就显得更灵敏。
降低网络传输:副本被重复使用,大大降低了用户的带宽使用,其实也是一种变相的省钱(如果流量要付费的话),同时保证了带宽请求在一个低水平上,更容易维护了。
试想现在的大型网站,随便一个页面都是一两百个请求,每天 pv 都是亿级别,如果没有缓存,用户体验会急剧下降(表现在等待请求的时间上)、同时服务器压力和网络带宽都面临严重的考验。
浏览器缓存控制机制
浏览器缓存控制机制有三种:HTML5离线存储和本地缓存、HTML Meta 标签、HTTP 协议缓存。
HTML5离线存储和本地缓存
该种缓存机制是运用 HTMl5 新推出一些支持离线应用的 API 来进行数据的缓存,比如 appcache、sessionStorage、localStorage等等。
appcache 通过定义一个描述文件(manifest file)来列出要下载和缓存的资源,manifest file 示例如下:
CACHE MANIFEST
# Comment
file.js
file.css
然后在 html 中引用:
<html manifest="./xxx.manifest">
sessionStorage、localStorage 的基本用法如下:
// localStorage 用法相似
sessionStorage.set('name', 'laixiangran') // 存储数据
sessionStorage.get('name') // 获取数据 'laixiangran'
本文暂时就不详细介绍,后面我会单独介绍这块的内容。
HTML Meta 标签
使用 HTML Meta 标签,Web 开发者可以在 HTML 页面的 <head> 节点中加入 <meta> 标签,代码如下:
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">
上述代码的作用是告诉浏览器当前页面不被缓存,每次访问都需要去服务器拉取。
使用上很简单,但只有部分浏览器可以支持,而且所有缓存代理服务器都不支持,因为代理不解析 HTML 内容本身。
HTTP 协议缓存
HTTP 协议缓存是我们本文讲解的重点,它是通过 HTTP 头信息来控制缓存的,HTTP 头信息可以让你对浏览器和代理服务器如何处理你的副本进行更多的控制。他们在 HTML 代码中是看不见的,一般由 Web 服务器自动生成。但是,根据你使用的服务器,你可以在某种程度上进行控制。
浏览器请求流程
浏览器第一次请求流程图:
该流程比较简单了,浏览器在第一次请求的时候不存在缓存,直接从浏览器请求,等请求返回结果之后再根据 HTTP 头信息将数据缓存在内存或者硬盘中。
浏览器再次请求时:
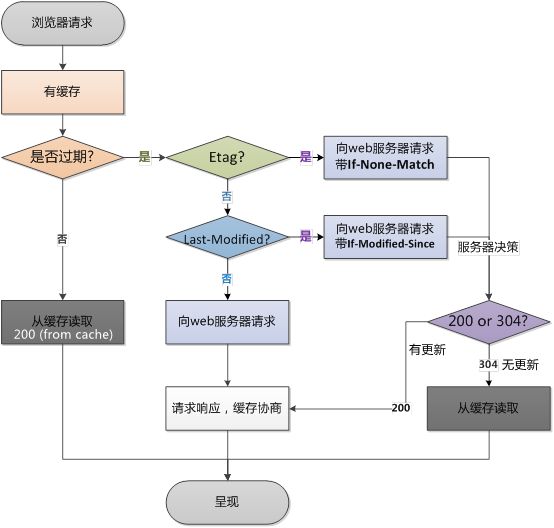
该流程就复杂多了,浏览器需要根据 HTTP 头信息来判断是否直接从缓存读取数据还是交由服务器来判断是否从缓存读取数据。
几种状态码的区别:
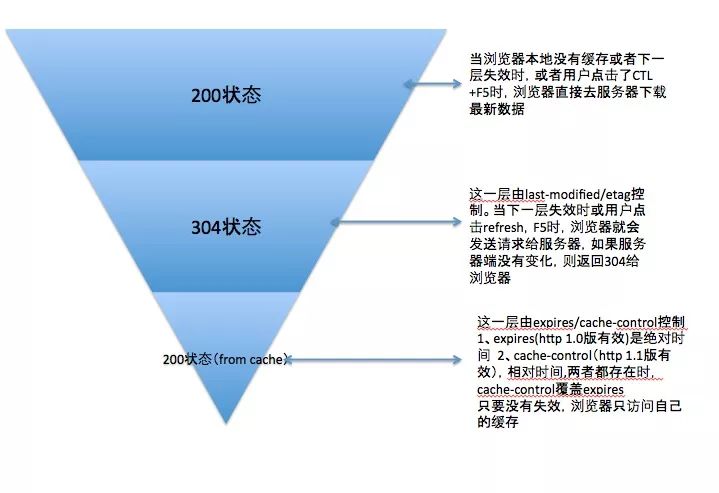
下面我们就从该流程中出现的 HTTP 状态码 200(from cache)和 304 来讲解 HTTP 协议缓存中的 HTTP 头信息。
200(from cache)
这种 HTTP 状态码表示不访问服务器,直接从缓存(内存或者硬盘)读取数据。
看两张图:
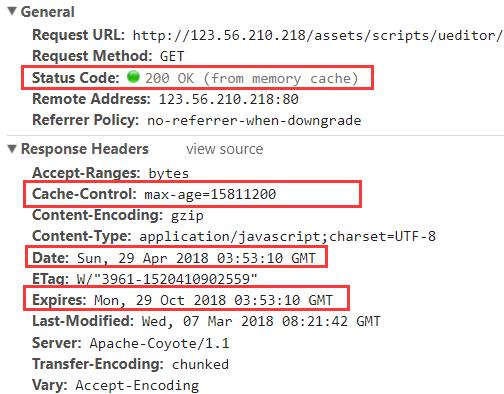
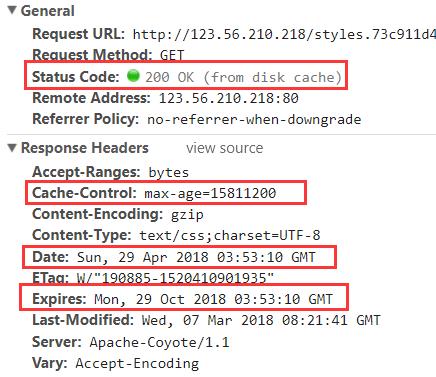
从上面两张图,我们会看到状态码有点不一样,分别是 200(from memory cache) 以及 200(from diks cache),这两个的区别一个是从内存读取数据,一个是从硬盘读取数据,然后它们的先后顺序是先从内存读取,再从硬盘读取。这里我们就统称为 200(from cache)。
出现 200(from cache) 这种情况,我们需要关注 Expires 和 Cache-control 这两种HTTP 头信息字段。
Expires
Expires 的中文意思是“有效期”。显然,就是告诉浏览器缓存的有效期。如果过期,缓存会检查源服务器以确定文件是否改变了。
Expires 头唯一的有效值是 HTTP 时间,其他值无效,不会去缓存的。注意:时间是格林威治时间(GMT),而不是本地时间。如下所示:
Expires: Mon, 29 Oct 2018 03:53:10 GMT
那么看我们上面的两张图中的 Expires,它都是到 2018-10-29 03:53:10 过期,而我们本次请求的时间 Date 是 2018-04-29 03:53:10,因此本次请求直接从缓存读取数据,返回 200(from cache)。
尽管 Expires 头很有用,但它有一定的局限性:
因为牵扯到时间,Web 服务器端的时间必须和缓存的同步,否则很可能实现不了预期的结果 —— 缓存把过期的数据当成最新的数据,把最新的数据当作过期的数据。
你很容易忘记给某内容设置了一个特定时间,如果返回内容的时候没有更新这个过期时间,则每个请求都是上访到服务器,反而增加了负载和响应时间。
最后呢,Expires 是 HTTP 1.0 的东西,现在默认浏览器均默认使用 HTTP 1.1,所以它的作用基本忽略。
Cache-Control
Cache-Control 与 Expires 的作用一致,都是指明当前资源的有效期,控制浏览器是否直接从浏览器缓存读取数据还是重新发请求到服务器读取数据。只不过 Cache-Control 的选择更多,设置更细致,如果同时设置的话,其优先级高于 Expires。
Cache-Control 有用的响应头包括:
max-age=[秒]: 表示在这个时间范围内缓存是新鲜的无需更新。类似 Expires 时间,不过这个时间是相对的,而不是绝对的。也就是某次请求成功后多少秒内缓存是新鲜的。
s-maxage=[秒]: 类似 max-age, 除了仅应用于共享缓存(如代理)。
public: 标记认证的响应才能够被缓存。一般而言,需要认证 HTTP 请求内容会自动私有化(不会被缓存)。
privateN: 允许缓存专门为某一个用户存储响应,比方说在浏览器中;共享缓存一般不会,例如在代理中。
no-cache: 每次在释放缓存副本之前都强制发送请求给源服务器进行验证,这在确保认证有效性上很管用(和 public 结合使用)或者保证内容必须是即时的,不得无视缓存的所有优点,如国内的微博、twitter等的刷新显示。
no-store: 强制缓存在任何情况下都不要保留任何副本。
must-revalidate: 告诉缓存,我给你准备了一些关于新鲜度的信息,在表现的时候要严格遵循。HTTP 允许缓存在某些特定情况下返回过期数据,指定了这个属性,相对于告诉缓存,你必须严格遵循我的规则。
proxy-revalidate: 类似 must-revalidate,除了只能应用于代理缓存。
使用如下所示:
Cache-Control: max-age=15811200
那么看我们上面的两张图中的 Cache-Control,它在当前请求成功后15811200秒内都是有效的,因此本次请求直接从缓存读取数据,返回 200(from cache)。如果从当前请求成功开始,过了15811200秒之后就会重新从服务器请求新数据。
304
当浏览器通过 Expires 或者 Cache-control 判断出缓存已经过期,那么就需要重新发送请求到服务器,让服务器判断当前缓存是否可以继续使用。
当服务器判断该缓存已经失效,那么就会返回新数据,HTTP 状态码为 200;
当浏览器判断该缓存还未失效,那么就会返回 HTTP 状态码为 304 (无需包体,节省流量),告知浏览器继续使用缓存。
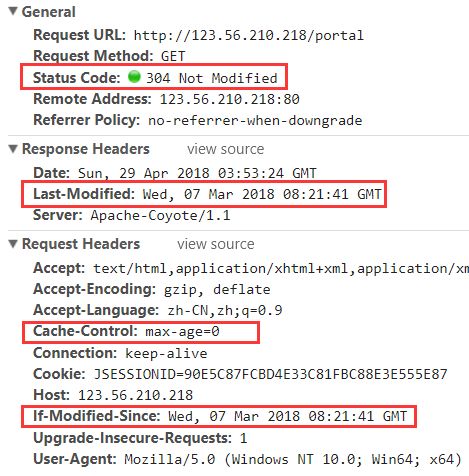
那么通过哪些 HTTP 头信息字段来判断是否返回 200 还是 304 呢?那么我们就请出接下来的主角: Last-Modified/If-Modified-Since 及 Etag/If-None-Match。这两个字段都需要配合 Cache-Control 使用。
Last-Modified/If-Modified-Since
Last-Modified: 标示这个响应资源的最后修改时间。web 服务器在响应请求时,告诉浏览器资源的最后修改时间。
If-Modified-Since: 当资源过期时(使用
Cache-Control标识的max-age),发现资源具有Last-Modified声明,则再次向 web 服务器请求时带上 If-Modified-Since,表示请求时间。web服务器收到请求后发现有 If-Modified-Since 则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说明资源有被改动过,则响应资源内容(写在响应消息包体内),HTTP 200;若最后修改时间较旧,说明资源无新修改,则响应 HTTP 304 (无需包体,节省流量),告知浏览器继续使用缓存。
Etag/If-None-Match
这是在 HTTP 1.1 中引入了一个新的验证器。
Etag: web 服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。Apache 中,ETag 的值,默认是对文件的索引节(INode),大小(Size)和最后修改时间(MTime)进行 Hash 后得到的。
If-None-Match: 当资源过期时(使用
Cache-Control标识的max-age),发现资源具有 Etage 声明,则再次向 web 服务器请求时带上 If-None-Match (Etag 的值)。web 服务器收到请求后发现有 If-None-Match 则与被请求资源的相应校验串进行比对,决定返回 200 或 304。
Etag 优先于 Last-Modified
你可能会觉得使用 Last-Modified 已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要 Etag(实体标识)呢?HTTP1.1 中 Etag 的出现主要是为了解决几个 Last-Modified 比较难解决的问题:
Last-Modified 标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间。
如果某些文件会被定期生成,当有时内容并没有任何变化,但Last-Modified却改变了,导致文件没法使用缓存。
有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形。
Etag 是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符,能够更加准确的控制缓存。Last-Modified 与 ETag 是可以一起使用的,服务器会优先验证 ETag,一致的情况下,才会继续比对 Last-Modified,最后才决定是否返回 304。
创建支持缓存网站的小技巧
通过上面的介绍,我们知道 HTTP 协议缓存的机制,目的就是让你可以更灵活更细致的控制浏览器缓存,从而让你的网站的缓存更加友好,用户体验更完美。
下面这些技巧也可以让你网站的缓存更加友好:
不同地方的图片和其他元素 使用同一库。
对于不经常改变的图片/页面启用缓存,通过将
Cache-Control: max-age头信息的值设大一点。对于定期更新的内容通过指定
max-age或过期时间实现缓存。万不得已不要变动文件: 否则你要设置一个新的
Last-Modified值。另外,当你更新站点的时候,只要上传改动的那些文件,而不要把整个站点都覆盖过去。Cookie能不用就不用: Cookie 难以被缓存,且大多情境下是没有必要的。如果你非得使用 Cookie,建议用在动态页面上。
减少SSL的使用: 因为共享缓存不能存储认证页面,只在必要的时候使用,并且在 SSL 页面上减少图片的使用。
SSL:全称 Secure Socket Layer – 安全套接层,为 Netscape 所研发,用以保障在 Internet 上数据传输之安全,利用数据加密 (Encryption) 技术,可确保数据在网络上的传输过程中不会被截取及窃听。目前一般通用的规格为 40 bit 的安全标准,美国则已推出 128 bit 的更高安全标准,但限制出境。只要 3.0 版本以上的 I.E. 或 Netscape 浏览器即可支持 SSL。
使用 REDbot 检查你的网站: 可以帮助你应用本文所介绍的一些概念。
REDbot:REDbot = RED + robot,是个机器人,检查 HTTP 资源,看他们如何会表现,指出常见的问题,并提出改进建议。虽然它属于 HTTP 一致性测试仪,但却可以找到不少 HTTP 相关问题。
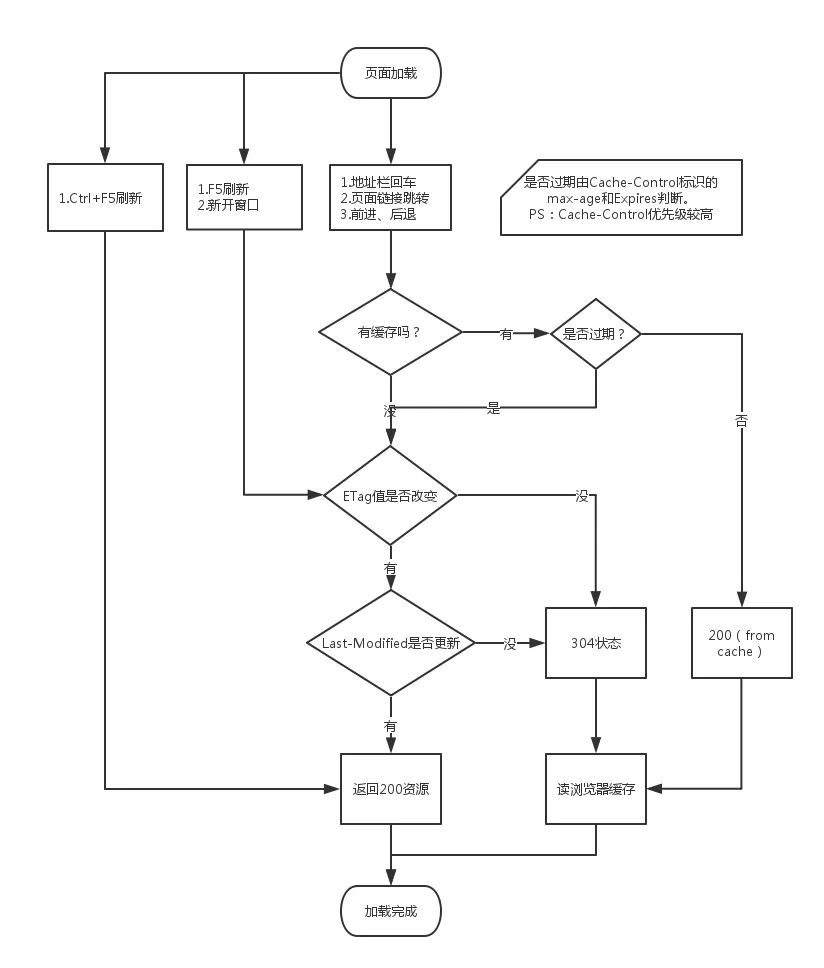
用户行为与缓存
用户的一些行为会影响到浏览器的缓存,具体如下:
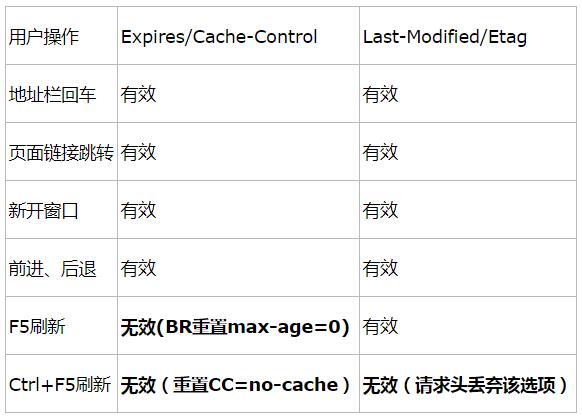
完整流程图
以上是关于Web缓存 - HTTP协议缓存的主要内容,如果未能解决你的问题,请参考以下文章